
论文:Mask R-CNN
0. 简介
先有请作者自己介绍一下这项工作——摘要:
- 提出一个通用的Object Instance segmentation模型,同时检测+分割,速度5fps。
- 基于Faster-RCNN,与BoundingBox预测分支平行加了一个Mask预测分支(FCN)。
- 能用于其他任务,如人体姿态估计。
- 没有用花里胡哨的Tricks,希望它能成为Instance-Level Recognition研究的"solid baseline"(现在看,何恺明大神确实说到做到了)
MaskRCNN做为双阶段实例分割的代表作,是入门实例分割领域值得或者说必须学习的经典。整体沿用目标检测领域FasterRCNN的思想,在最后的Head部分加入与边框分类及回归平行的另外一个分支来预测此框内的Mask。
接下来:
- 首先简单回顾FasterRCNN模型结构
- MaskRCNN模型结构
- ROI Align(来源于ROI pooling的mis-alignment问题)
- Mask预测及分类的解耦(LossFunction)
- 实验
1.Faster RCNN

双阶段目标检测算法,如上图所示整体流程:
- 首先用ResNet-FPN做BackBone提取特征
- 然后RPN(Region Proposal Network)得到FeatureMap中的ROI
- 使用RIO pooling处理RIO变成固定尺寸
- Head部分做边框的分类与回归
ResNet-FPN
因为FasterRCNN和MaskRCNN采用的都是ResNet-FPN主干网络,所以这里先介绍,在熟悉ResNet的基础上看一下ResNet-FPN:
FPN(Feature Pyramid Network)是一种旨在解决多尺度问题而提出的算法,下图(a)(c)(d)展示了三种典型的多尺度问题处理方式:(a)将图片缩放为不同size,(c)使用不同层次的FeatureMap,(d)特征金字塔网络。

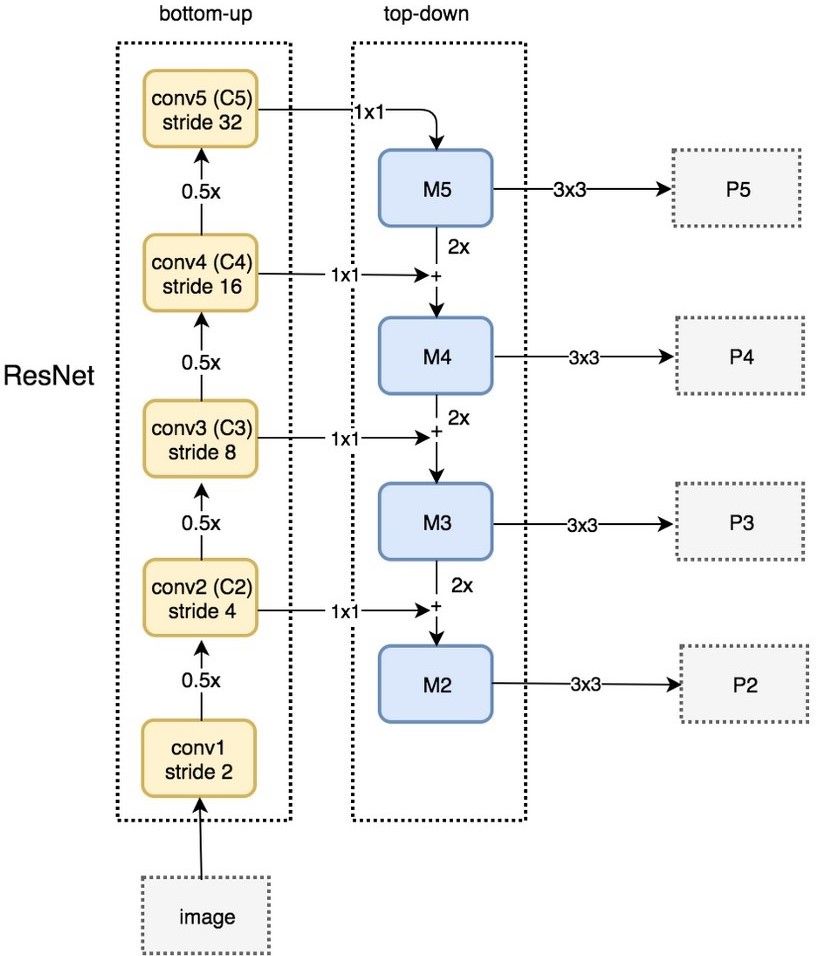
FPN结构中包括自下而上,自上而下和横向连接三种,如下图所示。这种结构可以将各个层级的特征进行融合,使其同时具有强语义信息和强空间信息。

FPN是一种通用结构,可以结合各种backbone使用,下图及为ResNet-FPNd的整体结构。最终产生的是特征金字塔[P2, P3, P4, P5](其实还有P6,图中缺少了)。那么其后的RPN网络在哪张特征图上产生ROI呢?FPN会利用一个公式选择最合适尺度的FeatureMap来切ROI,详情请见FPN的论文。
2.Mask RCNN

正如作者自己在论文中所说”Mask R-CNN is simple to implement and train given the Faster R-CNN framework“,确实只需要在FasterRCNN中的ROI Pooling(实际是改进后的ROI Align)后加入一个Mask分支——FCN(Fully Convolutional Networks)对每个ROI预测MasK即可,在这之前都与FasterRCNN相同。可以看出,MaskRCNN算法对于FasterRCNN有两个重点:ROI Align、Mask预测分支,下面两节详细介绍:
3.ROI Align
ROI pooling & 缺陷
ROI pooling方法:在一张feature map中截取ROI,并将此ROI池化为规定大小。简单的例子就能明白:假设现在有一个8x8大小的feature map,我们要在这个feature map上得到ROI,并且进行ROI pooling到2x2大小的输出。假设ROI的bounding box为[x1, y1, x2, y2] = [0, 3, 7, 8]。将它划分为2x2的网格,因为ROI的长宽除以2是不能整除的,所以会出现每个格子大小不一样的情况。进行max pooling的最终输入2×2的结果。

但ROI pooling方法存在不对齐(mis-alignment)问题,在目标检测领域还好,但对于分割这一像素级任务就会有致命性问题。mis-alignment主要来源于两次取整操作:
-
x,y,w,h的取整。(上述例子中我们给的ROI位置为整数,但实际通过RPN得到的区域并不是整数的)
-
划分小格时除不尽取整。(正如上面例子ROI宽为7,要分成2小格,不能整除,须取整)

ROI Align
ROI Align为了解决不对齐问题,将以上两次取整操作全部保留本来的浮点数,重新设计了算法。为了保留浮点数,采用了双线性插值,关于双线性插值看下图就可明白,计算公式可以自行百度,简而概之关键,普通线性插值确定一点的值需要两个点,双线性插值需要四个点。


ROI Align操作。如下图,虚线部分表示feature map,实线表示ROI,假设期望输出ROI为2×2。若采样点数是4,那我们首先将每个单元格子均分成四个小方格(如红色线所示),每个小方格中心就是采样点。这些采样点的坐标通常是浮点数,所以需要对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了。然后对每个单元格内的四个采样点进行maxpooling,就可以得到最终的ROIAlign的结果。

使用ROI Align代替ROI pooling后,效果有十分显著提升,实际效果:

4.Mask解耦(LossFunction)
MaskRCNN的总体损失函数为:
其中前两项为框分类与回归损失,与FasterRCNN一样,这里不再展开。 最后一项为Mask分割损失,是一个per-pixel sigmoid,假设一共有K个类别,则mask分割分支的输出维度是 , 对于
中的每个点,都会输出K个二值Mask(每个类别使用sigmoid输出)。需要注意的是,计算loss的时候,并不是每个类别的sigmoid输出都计算二值交叉熵损失,而是该像素属于哪个类,哪个类的sigmoid输出才要计算损失(如图红色方形所示)。并且在测试的时候,我们是通过分类分支预测的类别来选择相应的mask预测。这样,mask预测和分类预测就彻底解耦了。
这与FCN方法是不同,FCN是对每个像素进行多类别softmax分类,然后计算交叉熵损失,我们知道softmax输出所有项之和等于1,每项数值可以认为是概率,这样会造成类间竞争,而每个类别使用sigmoid输出并计算二值损失,可以避免类间竞争。实验表明,通过这种方法,可以较好地提升性能。

Sigmoid与Softmax对比实际提升效果:

5.代码 实验
学习过程中阅读了代码(pytorch)来理解算法,也进行了简单的验证实验。
- 代码学习推荐:pytorch-mask-rcnn
算法实现清晰明了,没有多余的东西,学习成本低,但使用的是pytorch0.4需要cuda9版本,我们的环境为cuda10不兼容,所以实际验证实验选择在Fackbook官方框架实现的Detectron2中进行。(大概目前多数人都已经不使用cuda9版本了吧,如果只有单一cuda10环境但想要使用此代码可以整一个容器环境,安装cuda9即可)。
- 使用官方框架Detectron2进行验证实验:Detectron2
使用官方训练好的ResNet101-FPN参数直接在COCO上运行:Mask的AP为38.629,与文章38.2基本符合甚至略高。
自己在COCO上训练所得结果:Mask的AP为36.823,略低于官方数据,应该是训练时由于显卡显存限制,我把batch_size由16改为4,影响了BN的效果所致。
参考及引图:
https://openaccess.thecvf.com/content_iccv_2017/html/He_Mask_R-CNN_ICCV_2017_paper.html
https://medium.com/@jonathan_hui/image-segmentation-with-mask-r-cnn-ebe6d793272
https://zhuanlan.zhihu.com/p/37998710
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


