
电影《满江红》上映之后,国师的一段采访视频火了,被无数段子手恶搞做成鬼畜视频,诚然,国师的这段采访文本相当经典,他生动地描述了一个牛逼吹完,大家都信了,结果发现自己没办法完成最后放弃,随后疯狂往回找补的过程。
最离谱的是,他这段采访用极其丰富的细节描述了一个没有发生且没有任何意义的事情,堪比单口相声,形成了一种荒诞的美感,毫无疑问,《满江红》最大的贡献就是这个采访素材了。
往这个文本里套内容并没有什么难度,小学生也可以,但配音是一个瓶颈,也就是说,普通人想染指鬼畜视频还是有一定门槛的,这个领域往往是专业配音演员的天下,但今时非比往日,人工智能AI技术可以让我们基于PaddleSpeech克隆出精致细腻的国师原声,普通人也可以玩转搞笑配音。
数据集准备和清洗
我们的目的是克隆国师的声音,那么就必须要有国师的声音样本,这里的声音样本和使用so-vits-svc4.0克隆歌声一样,需要相对“干净”的素材,所谓干净,即没有背景杂音和空白片段的音频素材,也可以使用国师采访的原视频音轨。
需要注意的是,原视频中女记者的提问音轨需要删除掉,否则会影响模型的推理效果。
随后,将训练集数据进行切分,主要是为了防止爆显存问题,可以手动切为长度在5秒到15秒的音轨切片,也可以使用三方库进行切分:
git clone https://github.com/openvpi/audio-slicer.git
随后编写脚本:
import librosa # Optional. Use any library you like to read audio files.
import soundfile # Optional. Use any library you like to write audio files.
from slicer2 import Slicer
audio, sr = librosa.load('国师采访.wav', sr=None, mono=False) # Load an audio file with librosa.
slicer = Slicer(
sr=sr,
threshold=-40,
min_length=5000,
min_interval=300,
hop_size=10,
max_sil_kept=500
)
chunks = slicer.slice(audio)
for i, chunk in enumerate(chunks):
if len(chunk.shape) > 1:
chunk = chunk.T # Swap axes if the audio is stereo.
soundfile.write(f'master_voice/{i}.wav', chunk, sr) # Save sliced audio files with soundfile.
注意这里min_length的单位是毫秒。
由于原始视频并未有背景音乐,所以分拆之前我们不用拆分前景音和背景音,如果你的素材有背景音乐,可以考虑使用spleeter来进行分离,具体请参照:人工智能AI库Spleeter免费人声和背景音乐分离实践(Python3.10),这里不再赘述。
如果对原视频的存在的杂音不太满意,可以通过noisereduce库进行降噪处理:
from scipy.io import wavfile
import noisereduce as nr
# load data
rate, data = wavfile.read("1.wav")
# perform noise reduction
reduced_noise = nr.reduce_noise(y=data, sr=rate)
wavfile.write("1_reduced_noise.wav", rate, reduced_noise)
训练集数量最好不要低于20个,虽然音频训练更适合小样本,但数量不够也会影响模型质量。
最后我们就得到了一组数据集:
D:workspeechmaster_voice>dir
驱动器 D 中的卷是 新加卷
卷的序列号是 9824-5798
D:workspeechmaster_voice 的目录
2023/06/13 17:05 <DIR> .
2023/06/13 20:42 <DIR> ..
2023/06/13 16:42 909,880 01.wav
2023/06/13 16:43 2,125,880 02.wav
2023/06/13 16:44 1,908,280 03.wav
2023/06/13 16:45 2,113,080 04.wav
2023/06/13 16:47 2,714,680 05.wav
2023/06/13 16:48 1,857,080 06.wav
2023/06/13 16:49 1,729,080 07.wav
2023/06/13 16:50 2,241,080 08.wav
2023/06/13 16:50 1,959,480 09.wav
2023/06/13 16:51 1,921,080 10.wav
2023/06/13 16:52 1,921,080 11.wav
2023/06/13 16:52 1,677,880 12.wav
2023/06/13 17:00 1,754,680 13.wav
2023/06/13 17:01 2,202,680 14.wav
2023/06/13 17:01 2,023,480 15.wav
2023/06/13 17:02 1,793,080 16.wav
2023/06/13 17:03 2,586,680 17.wav
2023/06/13 17:04 2,189,880 18.wav
2023/06/13 17:04 2,573,880 19.wav
2023/06/13 17:05 2,010,680 20.wav
20 个文件 40,213,600 字节
2 个目录 399,953,739,776 可用字节
当然,如果懒得准备训练集,也可以下载我切分好的,大家丰俭由己,各取所需:
链接:https://pan.baidu.com/s/1t5hE1LLktIPoyF70_GsH0Q?pwd=3dc6
提取码:3dc6
至此,数据集就准备好了。
云端训练和推理
数据集准备好了,我们就可以进行训练了,在此之前,需要配置PaddlePaddle框架,但这一次,我们选择在云端直接进行训练,如果想要本地部署,请移步:声音好听,颜值能打,基于PaddleGAN给人工智能AI语音模型配上动态画面(Python3.10)。
首先进入Paddle的云端项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/6384839
随后点击启动环境,注意这里尽量选择显存大一点的算力环境:
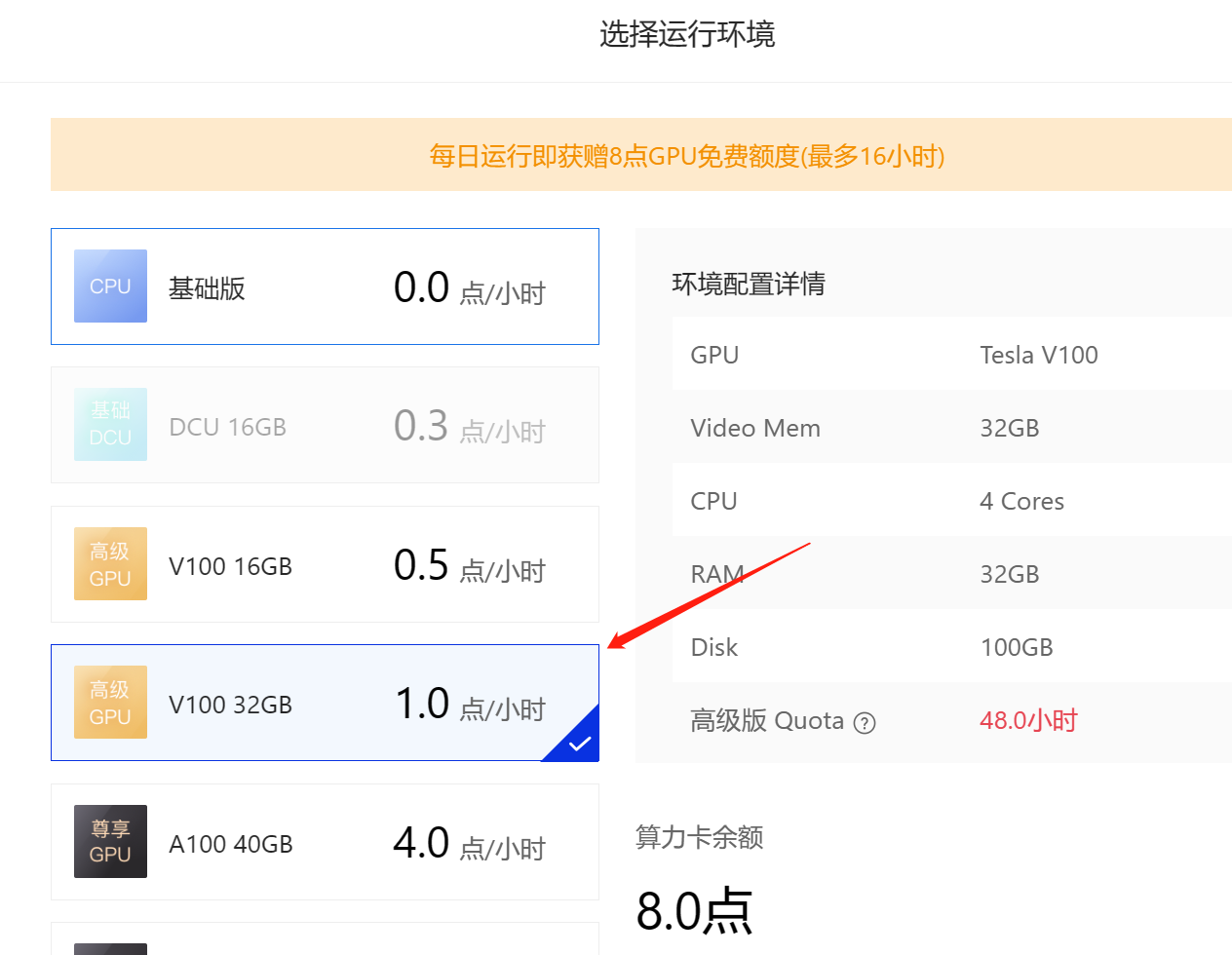
这里的机器有点类似Google的colab,原则上免费,通过消耗算力卡来进行使用。
成功启动环境之后,需要安装依赖:
# 安装实验所需环境
!bash env.sh
!pip install typeguard==2.13
由于机器是共享的,一旦环境关闭,再次进入还需要再次进行安装操作。
安装好paddle依赖后,在左侧找到文件 untitled.streamlit.py ,双击文件开启,随后点击web按钮,进入web页面。
接着在web页面中,点击Browse files按钮,将之前切分好的数据集上传到服务器内部。
接着点击检验数据按钮,进行数据集的校验。
最后输入模型的名称以及训练轮数,然后点击训练即可:
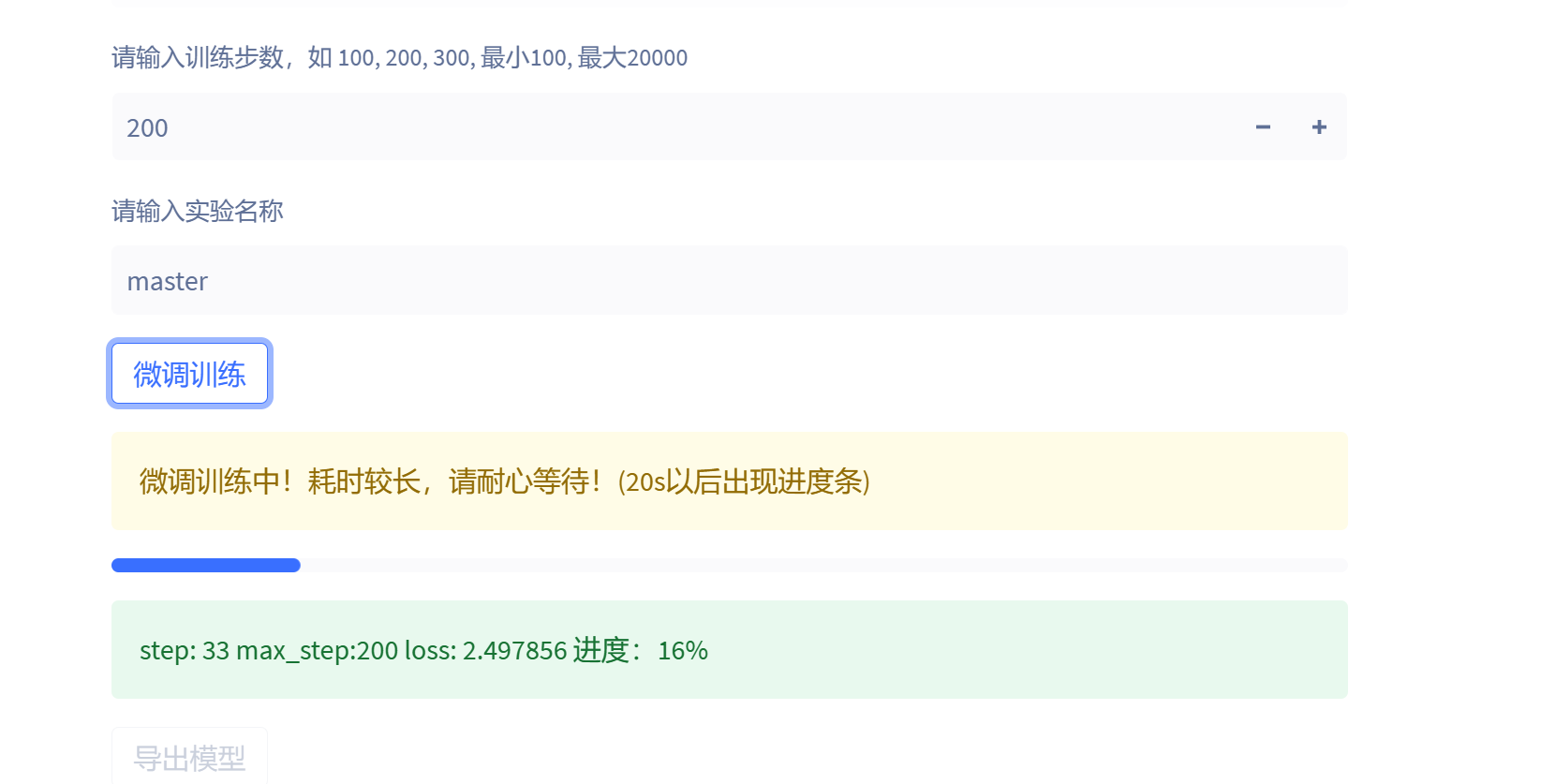
以TeslaV100为例子,20个文件的数据集200轮训练大概只需要五分钟就可以训练完毕。
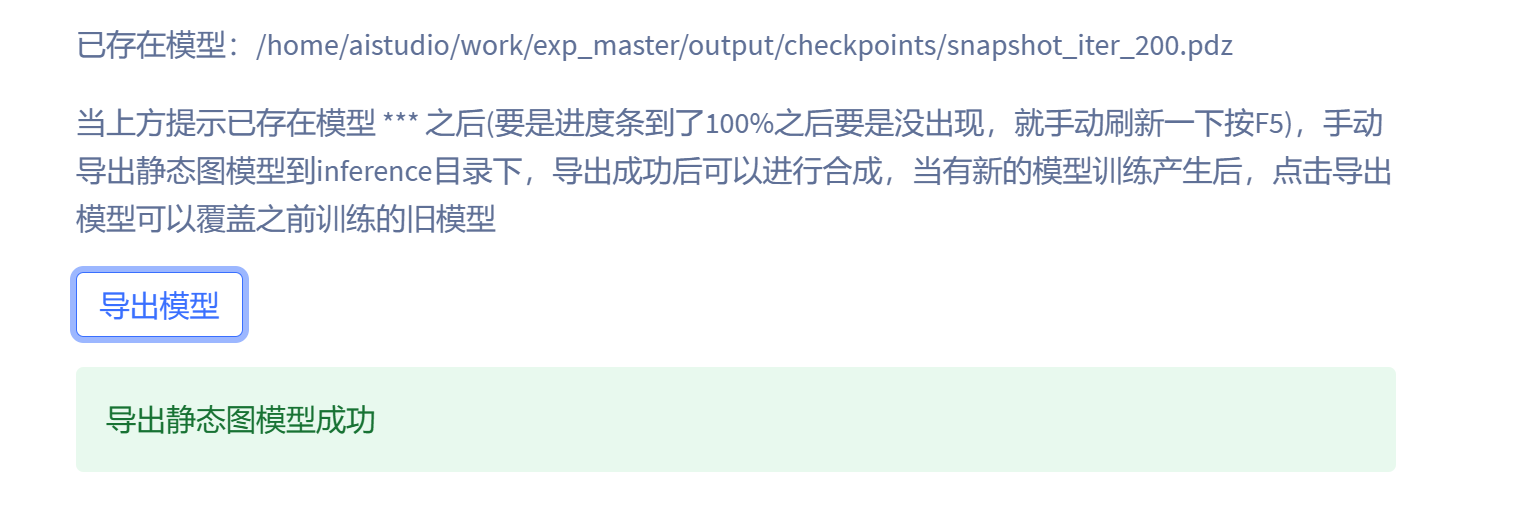
模型默认保存在项目的checkpoints目录中,文件名称为master。
点击导出模型即可覆盖老的模型:
最后就是线上推理:
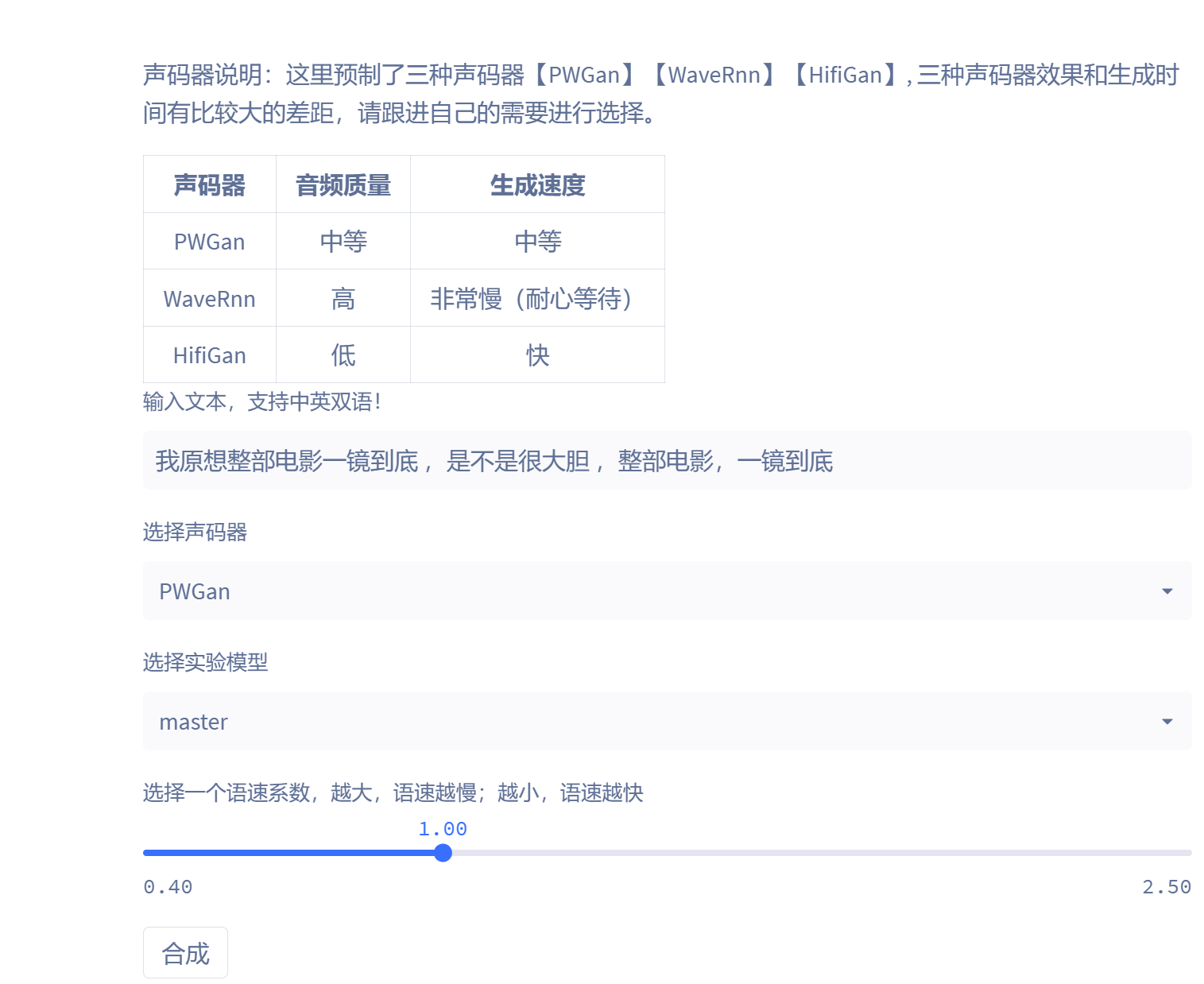
这里预制了三种声码器【PWGan】【WaveRnn】【HifiGan】, 三种声码器效果和生成时间有比较大的差距,这里推荐折中的PWGan声码器,因为毕竟是线上环境,每停留一个小时都会消耗算力点数。
合成完毕后,就可以拿到国师的克隆语音了。
结语
线上环境配置起来相对简单,但要记住,完成克隆语音任务后,需要及时关闭环境,防止算力点数的非必要消耗,最后奉上国师的音色克隆模型,与君共觞:
链接:https://pan.baidu.com/s/1nKOPlI7P_u_a5UGdHX76fA?pwd=ygqp
提取码:ygqp
克隆音色版本的国师鬼畜视频已经上传到Youtube(B站),欢迎诸君品鉴和臻赏。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


