
n-gram模型是自然语言处理里面的一个传统模型。我们来看看他是怎么实现的吧!要了解n-gram模型,我们先来看看什么是语言模型!
一.语言模型
语言模型的定义是:语言模型是一种用来预测下一个单词什么的任务。比如我们有一句话:

the students opened their _______. (其中可以填写books/laptops/exam/minds),那么语言模型就是用来预测这个空当中应该填写什么单词。
语言模型的正式定义为:

也就是我们在知道前面的单词的情况下,计算最后一个单词X(t+1)的概率是多大,最后一个单词X(t+1)可以是词表当中的任意单词,我们可以将词表当中的每一个单词都计算一遍。上面的这个公式其实也很容易理解,它是一个条件概率的公式,表示的是在 X(t),X(t-1),... ,X(1)发生的条件下,X(t+1)发生的概率。
同样的,我们除了得到最后一个单词发生的概率,我们可以得到整段句子所发生的概率,可以使用公式写成下面这种形式:

这样就得到整个句子发生的概率,整个公式在概率论与数理统计里十分常见,也就是简单将具备发生多个事件概率表达式进行展开,方便计算。
我们的语言模型的运用非常常见,在生活当中,比如你使用了你的智能手机进行打字,就会出现这样的场景:
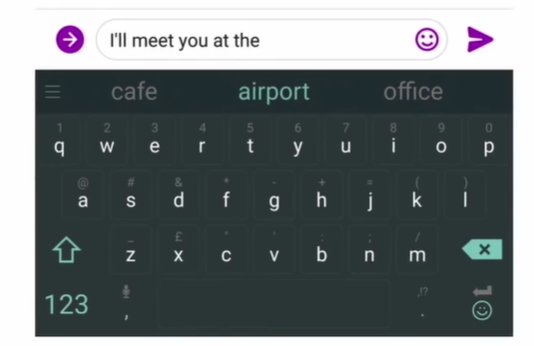
打字的输入法就会预测你打字输出的下一个单词是什么,概率越大的放在最前面。
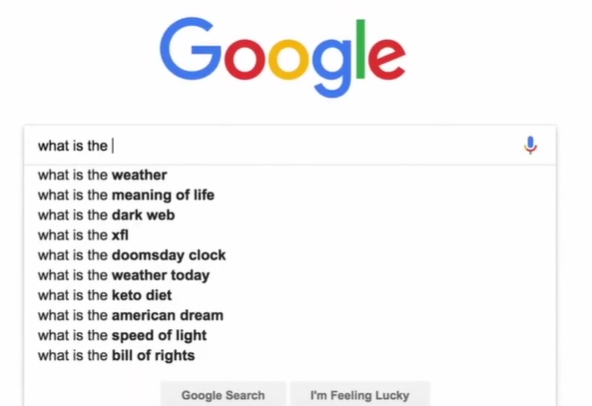
同样的,我们在进行谷歌搜索的时候,谷歌会帮我们将后面的句子进行补全,其实也是用了这个语言模型来预测我们后面的一个单词是什么;
下面我们进入到n-gram模型的部分。
二.n-gram模型
在学习了语言模型之后,你可能就会感到很疑惑,怎么样才能够实现一个语言模型,将语言模型训练出来呢?
答案很简单:那就是训练一个n-gram模型!
下面进入n-gram模型的定义:
n-gram的定义:g-gram就是n个连续的单词串连在一起。
1-gram(只有一个单词):words,I,think
2-gram:I think, ha ha, the students
3-gram: I think so, I think he, I do not think
以此类推
现在我们做出一个简单的假设,假设第 X(t+1)个单词是什么仅仅取决于之前的(n-1)个单词。那么前面的(n-1)个单词正好可以组成一个(n-1)-gram。因此我们可以用前面的(n-1)个单词来计算第 X(t+1)个单词出现的概率。列式如下:
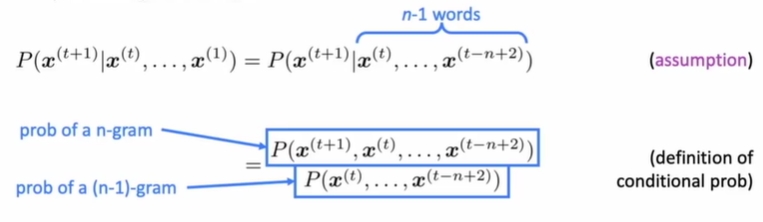
在上面的公式当中,我们将条件概率的公式进行了展开,分子分母分别相除。在上面的公式当中,其实逗号 “,” 就相当于 “∩“ 符号,表示两个事件的交集。那么我们如何计算出这个值呢?很简单,用数数!公式如下:

下面举一个数数的例子:
得解!这样n-gram就可以通过这个公式来计算下一个单词出现的概率了!以上就是n-gram模型实现的整个过程,笔者可能也有一些理解不当之处吗,还请多多指正!
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


