
论文题目《Spatial-Spectral T ransformer for Hyperspectral Image Classification》
论文作者:Xin He 1 , Yushi Chen 1,* and Zhouhan Lin 2
论文发表年份:2021
模型简称:SST
发表期刊:Remote Sensing
Motivation
基于cnn的方法具有空间特征提取的优点,但它们难以处理带有序列的数据,且不善于建模远程依赖关系。而HSI的光谱是一种序列数据,通常包含数百个波段。因此,cnn很难很好地处理HSI。另一方面,基于注意机制的Transformer模型已经证明了它在处理顺序数据方面的优势。为了解决在长距离捕获HSI中序列光谱关系的问题,本研究采用Transformer对HSI进行分类。具体而言,本研究提出了一种新的HSI分类框架——空间-光谱转换器(SST)。
Contribution
(1)提出了一种改进的DenseTransformer,它利用密集连接来解决Transformer中的梯度消失问题。
(2)将CNN、DenseTransformer和多层感知器(MLP)相结合,提出了一种新的HSI分类框架,即spatial-spectral Transformer (SST)。在该SST中,利用精心设计的CNN提取HSI的空间特征,利用DenseTransformer捕获HSI的序列光谱关系,利用MLP完成分类任务。
(3)进一步提出了动态特征增强(feature augmentation)方法,以缓解过拟合问题,从而更好地推广模型,并将其加入到SST中,形成一种新的HSI分类方法(即SST- FA)。
(4)提出了一种新的分类框架,即transferring spatial-spectral Transformer(T-SST),以进一步提高HSI分类的性能。提出的T-SST使用预先训练的大型数据集上的类VGG模型作为SST中使用的CNN的初始化。因此,在有限训练样本的情况下,提高了HSI分类精度。
(5)最后,为了缓解过拟合问题,提高分类精度,将标签平滑引入到基于Transformer的分类中。将标签平滑与T-SST相结合,形成了一种新的HSI分类方法T-SST-L。
Method
(1)Spatial-Spectral Transformer(SST)

①VGG部分:本文使用改进的VGGNet(2D-CNN)分别提取每个波段的特征(主要提取空间特征),并将提取的特征输入到Transformer中去学习长程依赖。在进入Transformer之前首先要对最后一层CNN提取的特征做位置编码,以捕获不同波段的位置信息。
②Transformer部分:Transformer编码器共包含d个编码器块,每个编码器块由一个多头注意和一个MLP层组成,并加上层归一化和残差连接。Transformer编码器的目的是通过根据全局上下文信息对每个波段进行编码来捕获所有n个HSI波段之间的相互作用。注意力的输出定义如下:
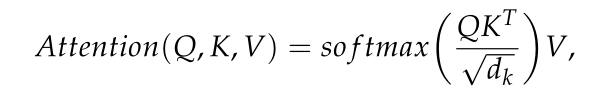 Note: d_k:防止未来求softmax梯度消失。
Note: d_k:防止未来求softmax梯度消失。
下图是为缓解梯度消失问题和增进特征传播改进的Transformer示意图(DenseTransformer)
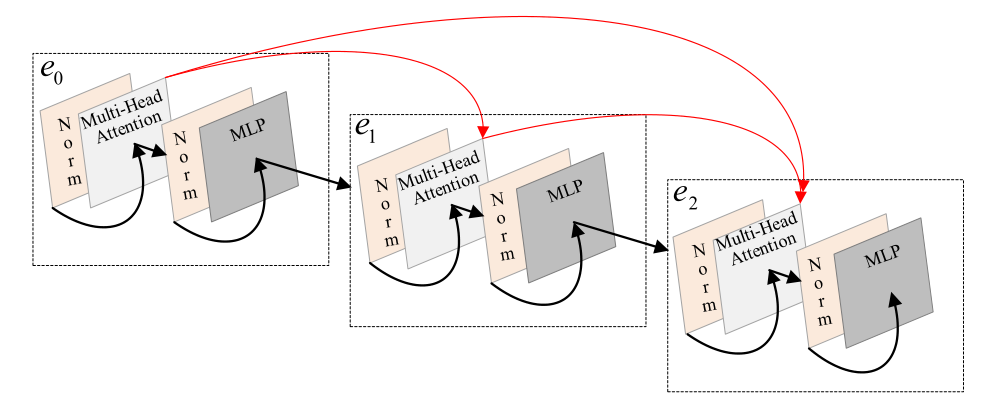
Note: 此处改进与DenseNet 特征复用类似。
③MLP部分:MLP的体系结构包括两个具有GELU操作的完全连接层,其中最后一个完全连接层(即softmax层)旨在生成HSI分类的最终结果。对于一个输入向量R,输入属于i类的概率可以估计如下:
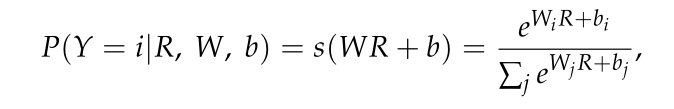
(2)SST-FA(SST+Feature Augmentation)
动态特征增强(正则化方法):由于VGG提取的空间特征维数较高(即512维),容易对Transformer模型进行过拟合。提出SST-FA 利用mask来避免过拟合问题。首先在特征中随机选择一个坐标,然后在坐标周围放置一个掩码,它决定将多少特征设置为零。注意,坐标在训练期间动态地改变w.r.t. epoch,这确保Transformer模型接收到不同的特征。
(3)Transferring Spatial-Spectral Transformer(T-SST)
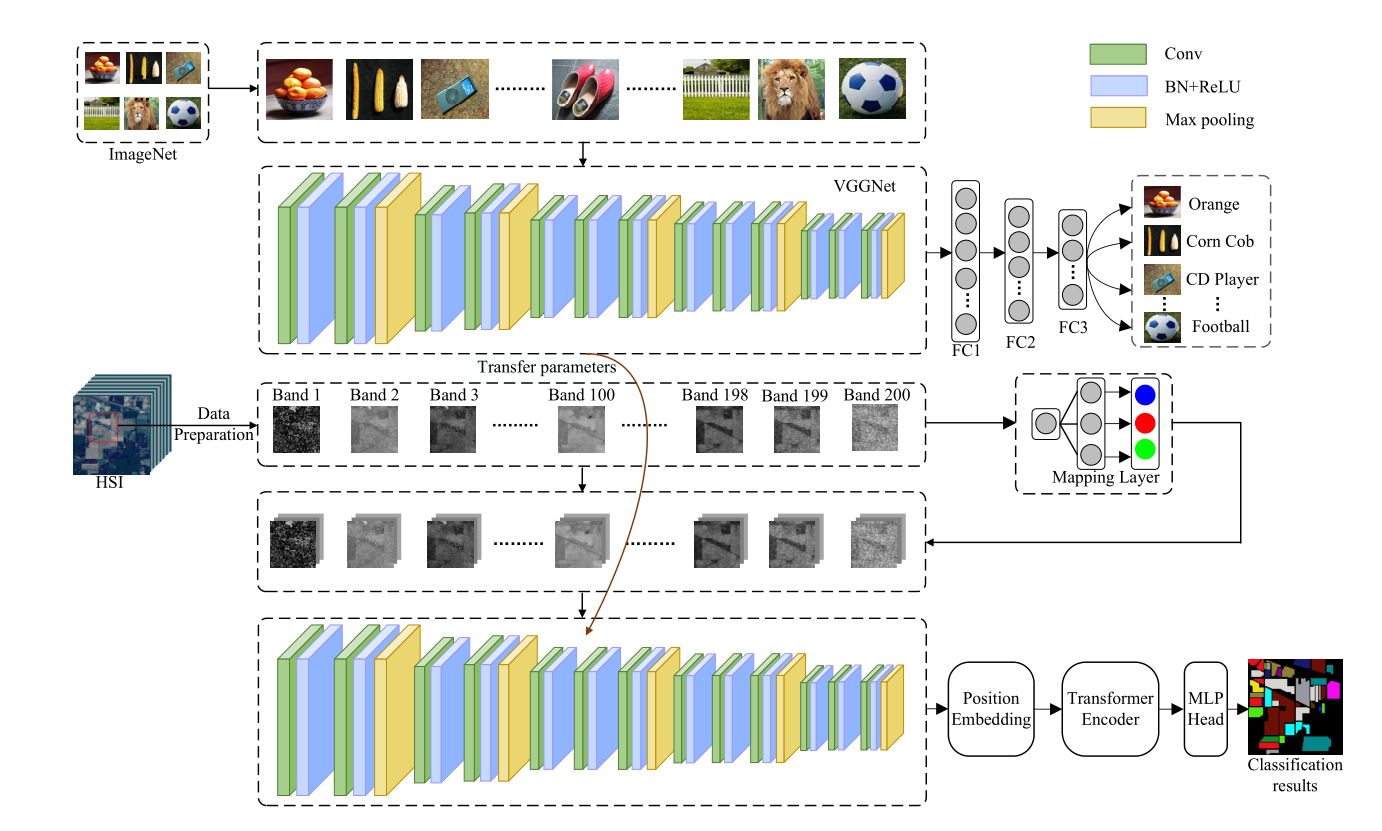
为了解决训练样本有限的问题,将迁移学习与SST相结合(原VGG模型经过预训练后再进行HSI特征提取),以提高目标任务的分类性能。 分类过程分为基于迁移CNN的空间特征提取、基于Transformer的空间光谱特征提取和基于MLP的分类。就是利用VGGNet在ImageNet数据集上学到的权重初始化HSI分类的网络,然后对HSI分类任务上的权重进行微调,因为前几层通常提取底层特征(即斑点、角和边缘),而底层特征通常在图像分类任务中是常见的。

两个数据集的异构问题:因为大规模数据集(即源数据集)有三个通道,而HSI(即目标数据集)包含数百个通道。为了解决异构迁移学习带来的问题,使用映射层来处理两个数据集的通道数(即波段数)不同的问题。VGG的输入则由原来ImageNet的RGB三通道图片转变为HSI的单波段patch输入,那么需要把HSI单波段patch通过Mapping Layer映射为类似RGB三通道的patch,这样就与预训练网络的输入结构相同了。具体的映射方式原为只给了一个式子(O∈RW×H、O' ∈ RW×H×3、α ∈ R3×1):O' = O × α
(4)]T-SST-L(T-SST + Label Smoothing)
为了解决T-SST中的过拟合问题,引入了标签平滑。ex:在分类中,每个训练样本x都有对应的标签y∈{1,2,…C}。C是类的数量,δk,y表示离散的狄拉克函数,当k = y时等于1,否则为0。
yk = δk,y
如果我们将所有的真实标签都指定为“硬标签”(即δk,y),则模型将努力将标签的预测分布推向硬标签。此外,如果适当地平滑标记,即在δk,y的零点上分配微小的概率质量,就可以有效地缓解这种情况。直观地说,这是因为模型对其预测过于自信。因此,标签平滑的机制就是来使模型不那么自信,从而获得更好的性能。标签平滑使原标签yk变为y'k,定义如下:ε是平滑因子,
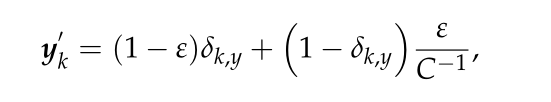
标签平滑机制通过简化模型来学习每个训练样本的全概率标签,可以以简单的形式缓解过拟合问题,提高模型的泛化能力。
Experimental Result
实验首先介绍了对VGGNet改进的细节参数及网络结构,随后对多头注意力头数、模型深度、标签平滑因子参数做了实验,当分别设置2、2、0.9时,效果最好。
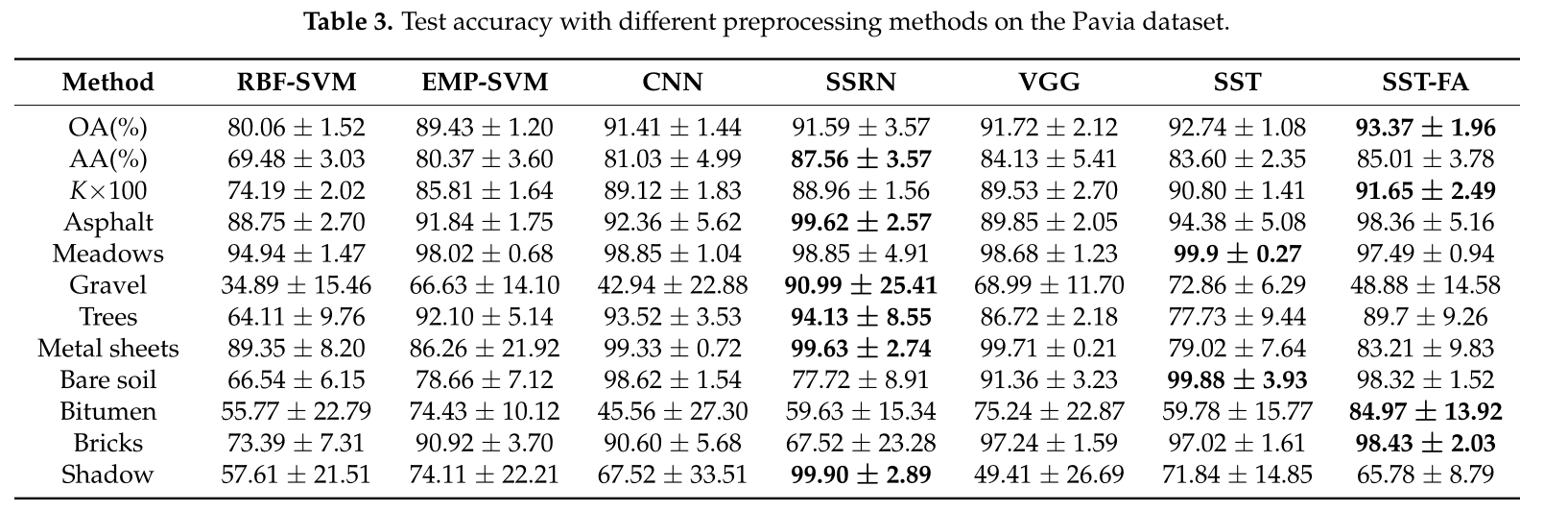
SST与SST-FA及其它网络做对比(Pavia):
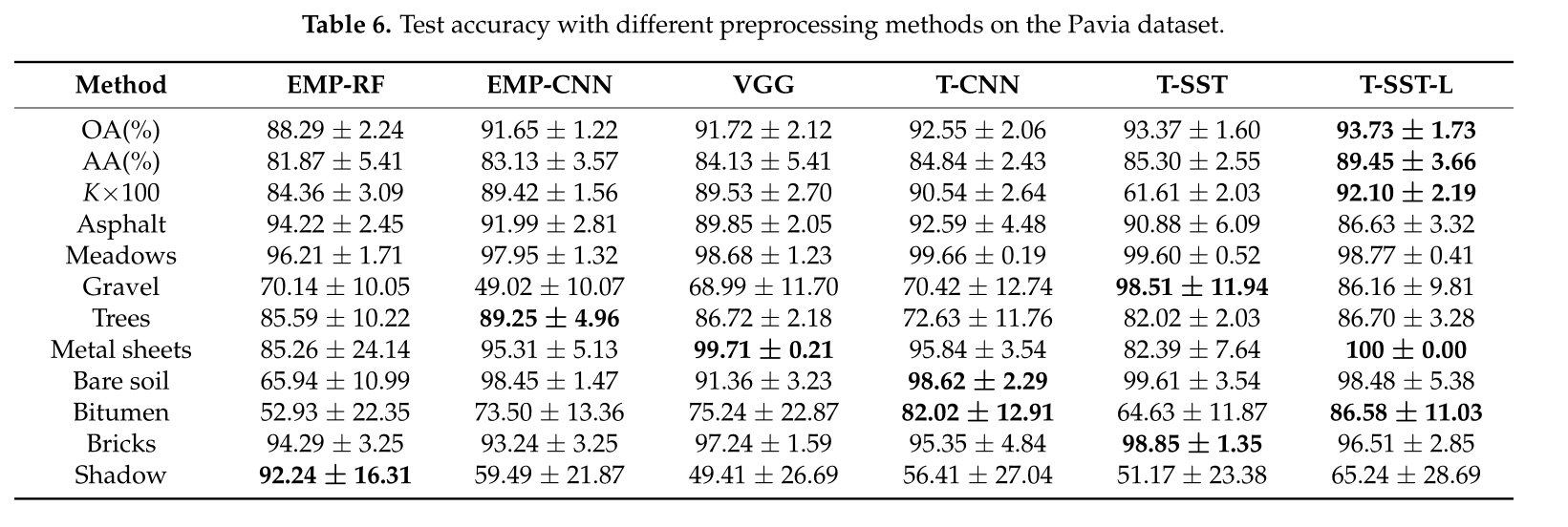
T-SST与T-SST-L及其它网络做对比(Pavia):
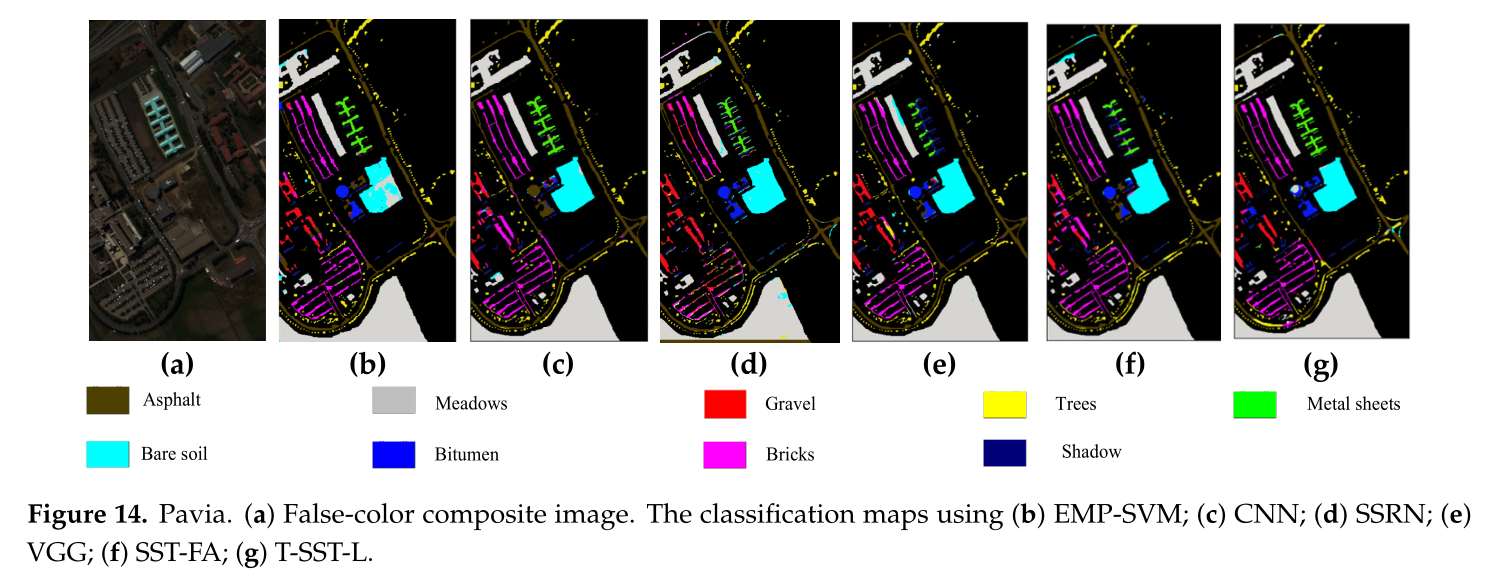
可视化类图比较(Pavia):
运行时间比较:

Conclusion
提出了DenseTransformer,该方法利用密集连接来缓解Transformer训练中的梯度消失问题。本文提出的基于SST的HSI分类方法,充分利用CNN获取二维patch的空间特征,并充分利用DenseTransformer获取谱域的长距离关系。此外,为了解决过拟合问题,提出了SST-FA,以Mask部分特征的形式训练。提出的T-SST结合了迁移学习和SST,进一步提高了分类性能。为了在ImageNet数据集上使用预训练的模型,设计了一个异构映射层,用于将模型从源域(即ImageNet数据集)映射到目标域(即HSI)。在基于Transformer的HSI分类中,标签平滑是一种有效的正则化方法。与SST、SST- FA、T-SST等方法相比,提出的T-SST-L具有更高的性能。基于Transformer的HSI分类还处于早期阶段。在今后的工作中,我们可以利用Transformer的各种改进,为HSI的精确分类开辟新的窗口。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


