
PaddleSpeech提供了MDTC模型(paper: The NPU System for the 2020 Personalized Voice Trigger Challenge)在Hey Snips数据集上的语音唤醒(KWS)的实现。这篇论文是用空洞时间卷积网络(dilated temporal convolution network, DTCN)的方法来做的,曾获the 2020 personalized voice trigger challenge (PVTC2020)的第二名,可见这个方案是比较优秀的。想看看到底是怎么做的,于是我对其做了一番初探。
1,模型理解
论文是用空洞时间卷积网络(DTCN)的方法来实现的。为了减少参数量,用了depthwise & pointwise 一维卷积。一维卷积以及BatchNormal、relu等组成1个DTCNBlock, 4个DTCNBlock组成一个DTCNStack。实现的模型跟论文里的有一些差异。论文里的模型具体见论文,实现的模型框图见下图:
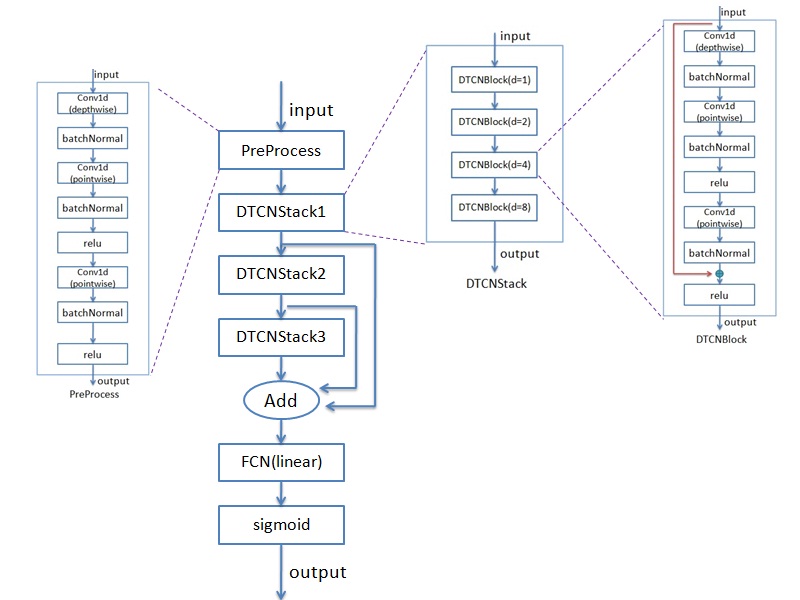
模型有PreProcess、DTCNStack(3个, DTCN:空洞时间卷积网络)、FCN(全连接网络)、sigmoid这些模块。PreProcess是做前处理,主要是由3个一维卷积(1个depthwise和两个pointwise)组成。每个DTCNStack由4个DTCNBlock组成,DTCNBlock跟preprocess模块相似,唯一的区别是多了残差模块(图中画红线的)。
这个模型的参数个数不到37K,见下图:

参数个数是比较少的,相对论文里的也少了不少。刚开始我不太相信,后来我对网络中的模型每层都算了参数个数,的确是这么多。想了一下,对比paper里的模型,参数变少主要有两点:一是少了一些模块,二是FCN由linear替代(linear替代FCN会少不少参数)。
模型用的特征是80维的mel-filter bank,即每帧的特征是一个80维的数据。把一个utterance的这些帧的特征作为模型的输入,输出是每一帧的后验概率,如果有一帧的后验概率大于threshold,就认为这一utterance是关键词,从而唤醒设备。举例来说,一个utterance有158帧,模型的输入就是158*80的矩阵(158是帧数,80是特征的维度),输出是158*1的矩阵,即158个后验概率。假设threshold设为0.8,这158个后验概率中只要有一个达到0.8,这个utterance就认为是关键词。
2,环境搭建
PaddleSpeech相关的文档里讲了如何搭建环境(Ubuntu下的),这里简述一下:
1)创建conda环境以及激活这个conda环境等:
conda create --name paddletry python=3.7
conda activate paddletry
2)安装 paddelpaddle (paddlespeech 是基于paddelpaddle的)
pip install paddlepaddle
3)clone 以及编译paddlespeech 代码
git clone https://github.com/PaddlePaddle/PaddleSpeech.git
pip install .
3,数据集准备
数据集用的是sonos公司的”hey snips”。我几天内用三个不同的邮箱去注册申请,均没给下载链接,难道是跟目前在科技领域紧张的中美关系有关?后来联系到了这篇paper的作者, 他愿意分享数据集。在此谢谢他,真是个热心人!他用百度网盘分享了两次数据集,下载后均是tar包解压出错,估计是传输过程中出了问题。在走投无路的情况下尝试去修复坏的tar包。找到了tar包修复工具gzrt,运气不错,能修复大部分,关键是定义train/dev/test集的json文件能修复出来。如果自己写json文件太耗时耗力了。Json中一个wav文件数据格式大致如下:
{
"duration": 4.86,
"worker_id": "0007cc59899fa13a8e0af4ed4b8046c6",
"audio_file_path": "audio_files/41dac4fb-3e69-4fd0-a8fc-9590d30e84b4.wav",
"id": "41dac4fb-3e69-4fd0-a8fc-9590d30e84b4",
"is_hotword": 0
},
数据集中原有wav文件96396个,修复了81401个。写python把在json中出现的但是audio_files目录中没有的去掉,形成新的json文件。原始的以及新的数据集中train/dev/test wav数如下:

从上表可以看出新的数据集在train/dev/test上基本都是原先的84%左右。
4,训练和评估
在PaddleSpeech/examples/hey_snips/kws0下做训练。训练前要把这个目录下conf/mdtc.yaml里的数据集的路径改成自己放数据集的地方。由于我用CPU训练,相应的命令就是./run.sh conf/mdtc.yaml 。 训练50个epoch(默认配置)后,在验证集下的准确率为99.79%(见下图),还是不错的,就没再训练下去。

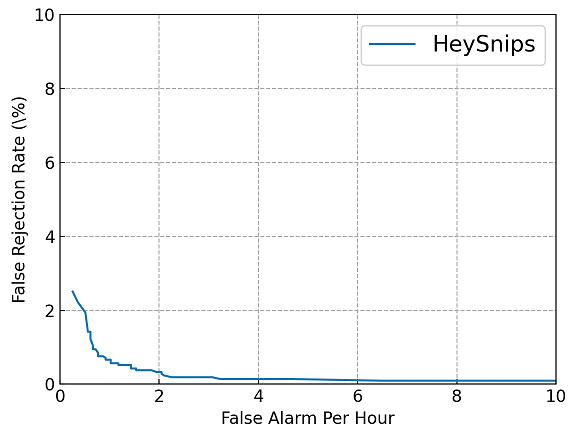
评估出的DET图如下:
Paddlespeech也提供了KWS推理命令: paddlespeech kws。需要研究一下这个命令是怎么用的,看相关代码。--input 后面既可以是一个具体的wav文件(这时只能评估一个文件),也可以是一个txt文件,把要评估的文件名都写在里面,具体格式如下图:

--ckpt_path是模型的路径,--config是设置配置文件,也就是mdtc.yaml。因为要对整个测试集做评估,所以--input要写成txt的形式。Hey Snips数据集wav文件都在audio_files目录下,需要写脚本把测试集的wav文件取出来放在一个目录下(我的是heytest), 还要写脚本把这次测试文件的文件名以及路径写到上图所示的txt文件里。同时还要在paddlespeech 里加些代码看推理出的值是否跟期望值一致,做些统计。把这些都弄好后就开始做运行了,具体命令如下图:

最终测试集下的结果,见下图:

共19442个文件,跟期望一致的(图中correct的)是19410个,准确率为99.84%。与验证集下的大体相当。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


