
学习资料:吴恩达机器学习课程
一. K-means算法
1. 算法思想
- K-均值算法是无监督学习中聚类算法中的一个

- 初始化k个聚类中心
- 循环:
- 将每个训练样本归类到最近的聚类中心组成一个个聚类
- 移动聚类中心到本身聚类的中心(平均值)
2. 目标优化

3. 随机初始化
K-均值的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。
-
解决方法:通常需要多次运行(50-1000次)K-均值算法,每一次都重新进行随机初始化,最后再比较多次运行K-均值的结果,选择代价函数最小的结果。
初始化时随机选择训练样本作为聚类中心 -
这种方法在较小的时候(K)较小时(2-10)还是可行的,但是(K)如果较大,就没有必要多次随机初始化了。
4. 选择聚类的数目K
- 根据“肘部法则”
- 根据聚类算法分类后的目的来决定数量
二. 主成分分析PCA
1. Dimensionality reduction降维
- 主成分分析是降维的一种方法,将高纬数据压缩成较低维度数据。比如将两个维度的压缩成一个维度时:就是指将两个特征压缩成一个新的特征。
- 降纬的作用:
- 压缩数据,减少数据存储空间;
- 加快学习算法速度;
- 可视化数据:降到2D、3D可以可视化数据。
2. PCA步骤
首先进行数据预处理,均值标准化
n维度(X^{[i]}) 降到k维度$Z^{[i]} $,PCA算法找到k维度:能够最小化投影距离的平方
SVD 奇异值分解


3. 压缩重构
压缩后的维度K重新变回之前的维度n
之前是 (Z = U_{reduce} ^T*X) 矩阵维度分析: kn * n1 = k*1
现在可以用 (X = U_{reduce}*Z) 变回之前的维度 矩阵维度分析: nk * k1 = n*1
4. 选择K的大小
使得平均最小投影距离/平均距离原点的距离<=0.01,即保留99%方差,降维后的数据更接近原数据。


仅仅通过SVD中的S就可以得到k的最优值
5. PCA的误用
- 虽然PCA可以降维,但是PCA不是避免过拟合的方法,过拟合最好还是用正则化。
- 在刚开始进行建立一个学习模型时,不要把PCA作为刚开始就做的步骤。而是要先用$X^{[i]} $ ,只有当确实需要用到时才去用PCA。
三. 异常检测Anomaly detection
- 主要用在非监督学习,但是也可以用在监督学习里。
1. 高斯分布异常检测
参数估计:一些参数分布满足高斯分布的时候,可以求出这些参数的平均值和方差用来表示这些参数的分布情况
- 选择需要进行异常检测的特征
- 求出这些特征对应高斯分布的平均值和方差
- 所有这些特征的高斯分布累积如果很小(小于一个阈值),就判定为异常

2. Anomaly detection vs supervised learning
-
异常检测大多用于非监督学习。因为无监督学习中特征没有label,所以可以根据这些特征的分布情况来建立一个模型,当有新的样本进来时检测样本的这些特征是否符合模型,不符合则代表异常
-
异常检测也可以用于监督学习。这时候异常检测与监督学习算法类似,异常样本有对应的label=0,正常样本对应的label=1。两种算法都是建立模型来区分异常和正常样本。
-
两种算法的应用情况:
- 当异常样本很少时,用异常检测算法:对大量正常样本建立模型,测试样本符合模型则表示正常,不符合则表示异常。
- 当异常样本数量较多时,则可以用监督学习算法:同时对两种样本建立分类模型。
3. 如何选择特征
对于一个样本(无论正常还是异常),有许多特征可以选择来判断是否一个样本是异常。例如:对于电脑是否损坏,有大量正常电脑和很少的异常电脑样本。我们可以选择的特征有CPU load,network traffc等。如下图:

那么如何选择合适的特征:
- 选择的特征应该符合高斯分布,如果不符合对特征进行一些处理转换使其大致符合高斯分布。(比如对于特征:(x)可以用(x*0.5) ,(log(x))试一试)
- 根据误差分析建立设计特征,比如(x_1/x_2)、(x_1^2/x_3)
4. 多元高斯分布
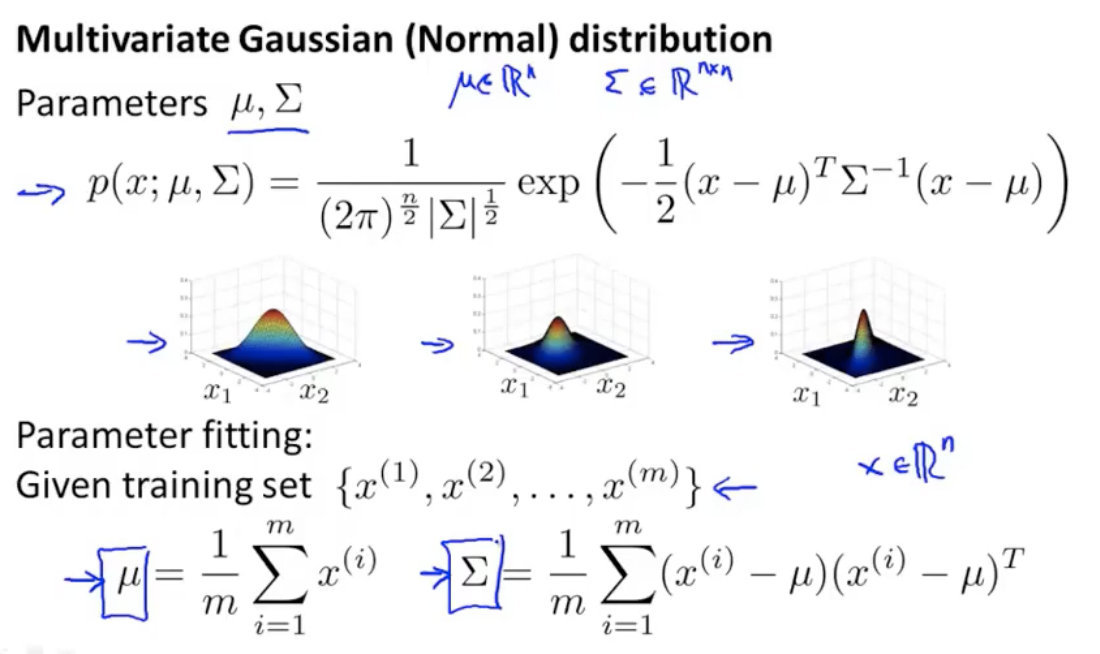

x个特征的高斯分布直接累积有个缺点是不能反映2个特征之间相互关系的影响。
多元高斯分布降特征合在一起建立一个高斯分布模型
5. Original model vs Multivariate Gaussian

-
原始高斯分布和多元高斯分布最大的区别是是否捕捉相关性的特征
-
两种分布在可视化图中的区别是:原始高斯分布得到的椭圆是轴对齐的(轴与x轴或y轴平行),而多元高斯分布椭圆轴可以是任意方向。所以原始高斯分布是多元的一种特殊情况。
-
多元高斯分布优点:可以自动寻找特征间的关系,其实原始高斯分布中手动设计特征就是在找特征之间的关系
-
多元高斯分布缺点:需要训练样本远大于特征值,而且计算要求更高。反之原始高斯分布不需要
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


