
NAS 简述
本文是神经网络架构搜索( Neural Architecture Search——NAS)的简要综述。由于本人刚开始涉足这个方向,因此本文也可以看做是最近一段根据本人读过的论文做出的总结,并不是很完整,也未必符合综述的格式,会对一些文章有一定展开,有些观点也未必正确,如果有错误的观点欢迎指出。本文也将不断更新。如果想看完整的综述可以参考 AutoML: A Survey of the State-of-the-Art (arxiv.org),写的相当不错。
如果想一起交流NAS或者AutoML方面的知识,欢迎联系我。
1.摘要
NAS是AutoML中的一个重要方向。近年来深度学习在CV和NLP等领域蓬勃发展,为各种任务性能带来了巨大的提升。但是在使用深度学习的过程中需要面临的一个问题是对于每一个问题来说基本都需要设计一个新的深度学习系统,虽然目前已经有了迁移学习等方式让单个神经网络可以在多任务上达到较好的性能,但是从整体情况上来看,针对特定问题还是需要单独设计神经网络,而设计神经网络的过程需要耗费大量的时间和资源,同时在很大程度上需要专业的领域知识,而对于越来越多的深度学习使用者来说,需要的是更简便的流程,因此NAS应运而生。作为AutoML的一个研究方向,NAS的目标就是自动设计出高效的神经网络,在某些任务上达到甚至超过人类专家设计的网络。
NAS的原理是给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估。这一过程如下图所示[1]:
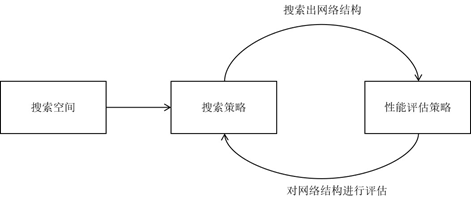
NAS的流程说起来非常简单,就是在搜索空间上,使用搜索策略不断产生网络结构,很多论文中将这些结构称为子网络(child network),子网络在经过性能评估之后对搜索策略进行一定的反馈,根据反馈搜索策略会继续生成更符合要求的网络结构,直到满足停止条件。最终产生的网络结构就是在该任务上搜索出的表现最好的网络。
NAS的目标就是使得最终搜索出的网络结构能在数据及上表现出比较好的性能。而在这个过程中比较重要的点在于搜索空间、搜索策略、性能评估方式。简单来说,搜索空间意味着结果中可以出现什么样的网络(例如可以出现3x3卷积,空洞卷积等结构),划定了解的空间,对于不同的任务需要使用不同的搜索空间。搜索策略表示搜索子网络过程中使用的方式是什么,目前主要的方法有:进化算法、强化学习、可微方法、贝叶斯优化等,这些方法的详细介绍会在下文中给出。而性能评估方式在很大程度上决定了最终的资源和时间的花费情况以及选出的网络的性能如何。简单来说,如果能快速评估出一个网络的性能潜力,那么就能大大缩短搜索需要的时间和资源。
2.任务
针对的任务不同,NAS生成的网络自然不同。本小节中对于NAS中目前常出现的几种任务进行了简单分类。
2.1 分类
最初的NAS和目前最常见的NAS的任务集中在分类问题上,主要涉及的数据集是CIFAR10,CIFAR100,ImageNet,Penn Treebank等数据集。针对这一类任务的NAS目前已经相对较为成熟,也形成了比较模板化的对比实验方式,主要设计的网络结构就是CNN与RNN类型的神经网络,在NAS设计过程中最为常见。这种任务也是本文重点涉及的任务。
2.2 GNN
随着图神经网络的兴起,对于各种GNN的自动搜索也开始出现。相较于CNN和RNN的搜索,GNN需要搜索的组件相对较少,例如AAAI 2020年的一篇针对GCN的搜索中[2]主要针对的就是Embedding Matrix的搜索。而且由于GNN的特点,在实际使用过程中很少会出现很深的网络,因此在网络深度上也不需要搜索的很深,但是由于做GNN的NAS的人相对还比较少,因此实验设计的时候相对来说也比较混乱,也没有出现像分类问题中的NAS-bench-201[3]等比较通用的测试方式。目前的一部分针对GNN的NAS主要是借鉴分类问题中比较成熟的方式,完成一个比较成熟的系统[4]。本文基本不涉及GNN的NAS,后续有机会专门写一篇关于GNN的NAS的文章。
2.3 Transformer
自从Transformer[5]在2017年被提出之后,各种变体在NLP和CV各种任务上大放异彩,因此这一两年针对Transformer的NAS也出现了很多。本文不涉及这一部分,后续会专门写一篇文章介绍。
2.4 特定任务
上述三个任务都是比较大的方向,很显然实际的任务远不止这些,例如CV中还有去噪、图片修复等等很多任务。这些任务与最常见的分类任务等搜索的时候区别主要在于搜索空间和评价方式。例如CVPR2022上一篇针对Deep Image Prior(DIP)问题的NAS[6]就是评估方式不同,使用了DIP任务中一个比较特色的PSD指数来对网络进行早期评估,减少了搜索过程中的耗时。由于这些任务太多,无法逐一介绍,因此本文不涉及。
3.搜索空间
搜索空间定义了NAS算法可以搜索出的子网络的结构,而以何种方式搜索子网的结构也是在搜索空间的时候就确定了。目前大多数文章都将搜索过程定义为一个在有向无环图(DAG)上的搜索问题,图的节点表示神经网络的不同的层,边表示数据的流动。从我个人的角度来看,如果把operation(例如3x3卷积)看成附着在边上的操作,把每一个节点看成对于operation产生结果的输出,那么这样搜索任务就非常清晰了,就是搜索每一条边是否应该存在。以Darts[7]中的一张图为例。
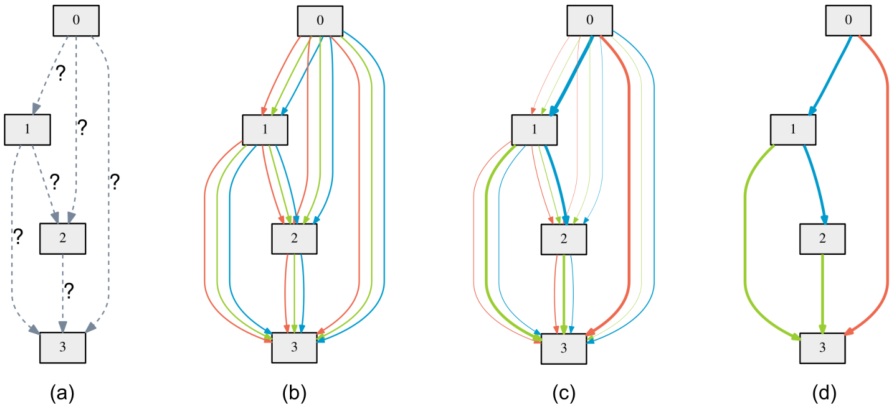
其中每一种颜色的边代表一种操作,例如3x3卷积、空洞卷积、跳跃连接等,而每一个灰色的节点表示对于连接到它的操作的输出的一种操作,一般是concat或者add。这样看起来搜索过程其实就非常明确了。
3.1 子网结构
子网结构可以分为两个部分,一个是子网的拓扑结构,一个是每层的类型和内部结构。拓扑结构指的是网络有多少层,每一层之间的连接关系。比如说每个节点能有多少个前驱,多少个后继,这都是拓扑结构的一部分。再例如ResNet中就出现了跨越多层的连接,这就是在网络拓扑结构上的一个改进从而使得网络性能大幅度上涨。而网络每一层的类型和内部结构指的是这一层使用的是卷积、池化、全连接或者其他各种形式。而内部结构就是指每一种类型的超参数,比如卷积核的大小、步长,池化层的大小等。NAS需要搜索的就是每一层的operation和层与层之间的连接关系。
3.2 搜索方式
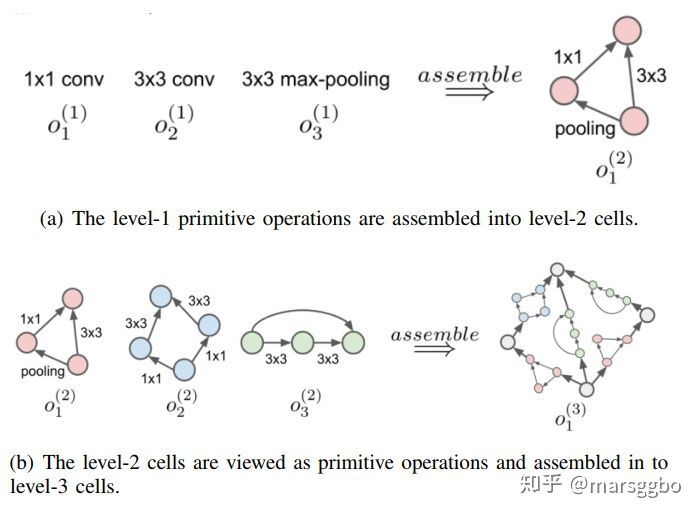
搜索方式可以分为三种:a).直接搜索产生整个网络,b).将网络视为一个一个基本cell的堆叠,c)层次结构搜索。a的思路产生是很显然的,但是a需要的搜索资源一般来说相对于后两种是要大很多的。而b的思路的产生可以参考Inception[8]的操作,其实就是把相同的cell堆叠成整体的网络,最终的性能也相当好。但是需要注意的是将网络视为cell的堆叠来搜索一定是会限制最终搜索出来的网络的性能的,这只是在搜索消耗资源和搜索结果之间的一个trade-off。而c的方式不同于b,前一步骤生成的单元结构作为下一步单元结构的基本组成部件,通过迭代的思想得到最终的网络结构[9],但是个人感觉这种方法在近几年的文章中好像不是很常见。搜索方式参考如下图片[10]:
4.搜索策略
4.1 强化学习
基于强化学习的NAS[11][12]是比较常见的一种方法。其主要的思路就是将NAS问题中的神经网络设计问题转化为一个强化学习问题,得到一个最优的神经网络。由于强化学习一般用来处理离散的action选择问题,而NAS问题如果不进行近似优化的话,其实可以很自然的转化成一个强化学习的任务。强化学习的每个action表示神经网络中的一部分结构,reward则在各种文章中设置不一样,最直接也是最简单的就是搜索出网络之后在训练集上训练之后,在验证集上的性能。这里可以发现最后这个reward的设计对于训练时长和资源的消耗有很大意义,后文会详细介绍。
接下来介绍[11:1]中使用的方法,基本上可以代表基于强化学习的方法的经典方式。
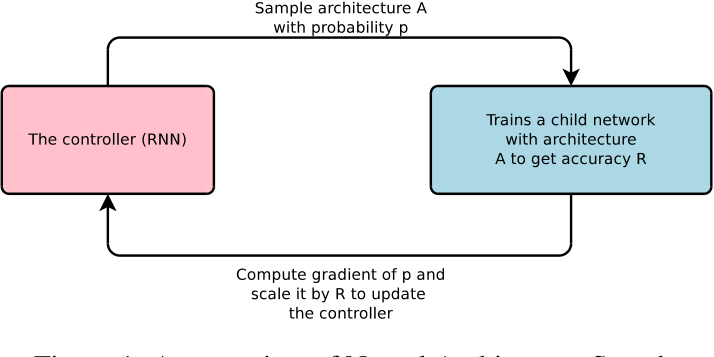
因为神经网络的深度是不确定的,也就是说搜索的时候输出的序列长度是不确定的,因此使用RNN作为一个可以输出可变长网络的一个控制器,后续文章中也有使用LSTM的,其实本质上是一样的。而RNN中的输出就可以看成是网络结构,这个输出的形式映射到网络结构的方式可以自行决定,本文采用的方式是每5个输出值定义一个神经网络的层,这5个值分别是卷积核的高度,卷积核的宽度,卷积操作在水平方向的步长,卷积操作在垂直方向的步长。同时,如果考虑ResNet的话,还可以加入一个skip connection的操作。搜索序列的过程见图4:
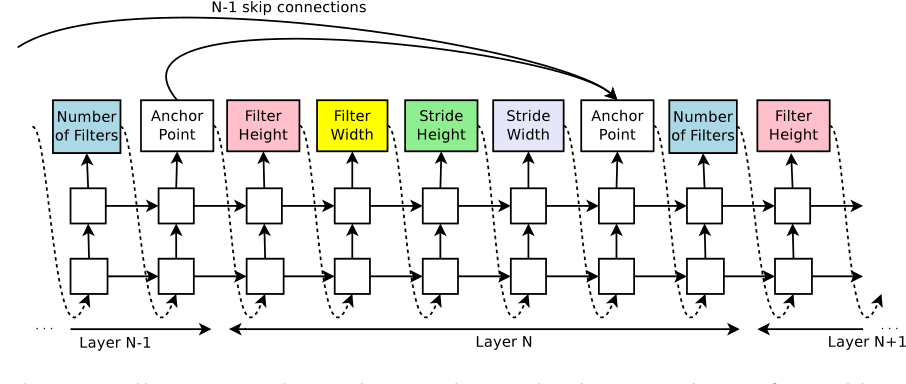
当搜索出神经网络结构之后就在训练集上训练子网络,文章中采用的是强化学习的方式来训练网络参数[13],其实看起来和直接使用梯度下降的区别并不是很大。在训练集上训练结束之后在验证集上测试网络的性能,将这个性能指标作为reward返回给RNN,这样RNN也可以得到训练,从而输出更符合要求的网络结构。
本文可以看做是第一篇正式完整提出NAS的文章,也确实使用强化学习在NAS上取得了不错的效果。但是使用强化学习解决NAS存在的一个问题就是计算量太大 。除了一些大公司,其余研究者很难负担得起这样的计算资源消耗。
因此[14]中提出了NASNet来预测出基本快,在小规模的CIFAR-10上训练,然后将训练得到的网络结构迁移到ImageNet上。控制器预测的是基本两种网络单元,分别称为普通单元(Normal Cell)和约简单元(Reduction Cell)。前者不改变输入图像的尺寸,后者将图像的高度和宽度减半。根据这种设计,搜索整个神经网络结构的任务被简化为搜索最优基本块结构。后续很多文章也都是这么处理的。搜索过程和[11:2]类似,不再赘述。虽然这样处理,但是需要的计算资源仍然大的离谱,大约为 32,400-43,200 GPU hours,大部分研究者仍然难以负担。
而[12:1]中提出的ENAS在一定程度上缓解了这个问题,在ENAS中使用了权重共享的方式,减少了对子网络的训练次数,从而相较于上两种方法提速了大约1000倍,需要的时间大约为0.45GPU hours。这种方法会在下文one-shot方法中详细介绍。
总体来说,强化学习是一个解决NAS问题的良好解法,但是面临的问题就是在较大的搜索空间下需要的计算资源太大。而需要提一下的是与后序的可微方法比,基于强化学习的NAS基本上可以看成是one-stage的,这在实际使用过程中是有一定的优势的,在后文one-stage的部分将会详细介绍。
4.2 进化算法
进化算法在NAS中的出现其实也非常好理解,进化算法很适合处理这一类决策问题。使用进化算法求解NAS的时候,将子网络进行一定的编码,编码成二进制代码传或者其余形式,接着与正常的进化算法的进行方式相同,首先选择一定的初始化种群(即一些子网络),然后训练这些子网络直到收敛,然后计算适应度值(一般是在验证集上的性能),接下来选择一些子网络作为父本,进行交叉、变异产生子代,之后继续训练直至达到结束条件。
使用进化算法的NAS相对来说比较简单,主要问题集中在搜索空间以及编码上。但是使用遗传算法同样面临着计算资源的消耗很大的缺点。最早提出在NAS上使用遗传算法的GeNet[15]使用的方法是在CIFAR10上搜索之后迁移到ImageNet上,需要注意的是这种使用代理数据集的方法在后续的文章中也经常见到。而后续的包括Hierarchical-EAS[16]和AmoebaNet-A[17]需要的计算资源都是相对来说比较大的。详细的数据可以参考表1[18]。
由于上述算法在计算资源上的问题,后续提出了包括GreedyNAS[19],GreedyNASV2[20],Zen-NAS[21]等基于遗传算法的方法,在保持精度基本上不变的基础上能有效提升。以下详细介绍这三种方法。
| 算法 | Top1/Top5 Acc(%) | GPU days | GPU型号 | 搜索数据集 | 论文时间 |
|---|---|---|---|---|---|
| GeNe | 72.13/90.26 | 17 | Titan-X | CIFAR10 | 201703 |
| Hierarchical-EAS | 79.7/94.8 | 300 | P100 | CIFAR10 | 201802 |
| AmoebaNet-A | 83.9/96.6 | 3150 | K40 | CIFAR10 | 201902 |
| GreedyNAS | 77.1/93.3 | <1 | V100 | ImageNet | 202003 |
| Zen-NAS | 83.1%/- | <=0.5 | V100 | ImageNet | 202102 |
| GreedyNASV2-L | 81.1%/95.4% | 9 | V100 | ImageNet | 202111 |
4.2.1 GreedyNAS
GreedyNAS是商汤在CVPR2020上的一篇论文,其是一种one-shot的NAS。主要贡献在于对路径选择进行了贪心操作。在one-shot的模型中,因为supernet只训练一次,在采样过程中不再训练,因此在GreedyNAS之前的很多文章中,都是尽可能让supernet训练时对每个采样都公平一点。简单来说就是supernet中的每一条子网络被采样到训练的概率应该是基本一样的。但是在GreedyNAS中提出这些子网络的潜力本来就是不同的,如果训练了太多的weak的path,可能会影响到最终的supernet的表示。
因此GreedyNAS将supernet表示为如下形式:
而很显然,我们的目标就是选择出(A_{good}),然后只在这一个子集中训练。但是因为supernet是未知的,所以很难把good和weak的部分分开,这里作者提出了一种多路径拒绝式采样的方式,我们定义(q=frac {A_{good}}{|A|}),则从weak中采样的概率就是1-q,那么假设采样m个path,那么至少有k个path来自于(A_{good})的概率就是(sum_{j=k}^{m}C_m^jq^j(1-q)^{m-j})。当q比较大或者k比较小的时候这个概率都是比较大的,因此作者简单地挑选top-k的子网络来训练即可。而由于挑选top-k的过程又涉及在验证集上训练得到acc,这个操作的过程相对来说开销比较大,因此作者使用验证集的一个子集来训练,具体的伪代码如图5所示。

因为我们每次做完 greedy path filtering 后得到一些可能比较好的 path,它们一次训练可能不够充分,有重复训练的必要,所以这里作者也提出了一个 exploration 和 exploitation 的 trade-off,也就是说使用一个候选池来保存可能比较好的path,每次选择的时候从候选池中选一部分,从supernet中再采样一部分。因此GreedyNAS的整体supernet的训练过程如图6所示。

supernet 训练完毕后,使用 NSGA-II 进化算法在超网中搜索符合条件的最优模型,并且使用候选池初始化种群,相较于随机初始化,能有一个更高效的初始值,提升搜索效率及最终的精度能得到更好的模型分布。
4.2.2 GreedyNASV2
GreedyNASV2是商汤在CVPR2022上的一篇论文,看名字就知道是延续了GreedyNAS的思路,进行了一定的提升。整体的思路和GreedyNAS相同,也是把supernet中的path分为good和weak。但是本文中做出一个假设,因为在正常情况下good的path是远远少于weak的path的,因此与其像GreedyNAS一样选择good,不如剔除有较高概率认为是weak的path。
除此之外,为了不在验证集上训练网络,本文中使用一个LSTM网络对网络的潜力进行预测。具体操作方式就是对path进行编码,输入一个LSTM网络,这个网络将会预测path的性能,这样就避免了在验证集上训练网络。
同时本文还对每层中每个操作进行embedding,对这个embedding同样进行训练,如果发现同一层中的两个操作的embedding比较相似,就可以将这两个操作合并,这样就能快速收缩搜索空间。
其余操作和GreedNAS大同小异,不再叙述。
4.2.3 Zen-NAS
本文是阿里在ICCV2021上发表的文章。现有NAS的主要任务分为两个方面的改进,一是architecture generator,二是accuracy predictor。Generator的作用是提供潜在的高性能网络结构,Predictor的作用是为网络计算准确率。构建一个高性能的predictor是非常具有挑战的任务,因为其计算开销通常非常大。因此本文的贡献就是提出了一个评价网络表达能力的标准Zen-Score,其大小和网络的性能成正比。Zen-Score的计算方式见图7。
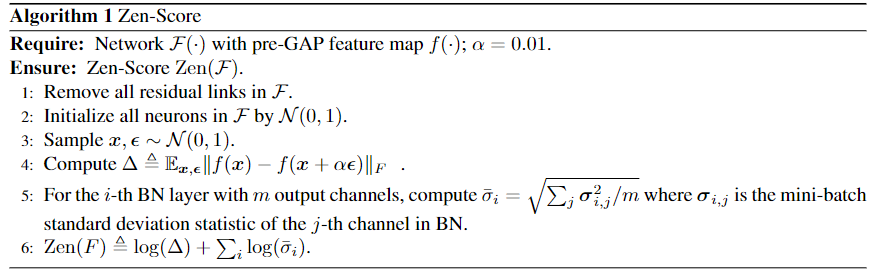
首先把网络中的残差连接全部移除,将网络初始化,随机采样输入,然后计算GAP层前所有层的没参入高斯噪声与参入高斯噪声的feature map的差值的Φ-score,然后将mini-batch中所有channel的方差取平均开根号得到一个均方差,取log后与前面的Φ-score相加就得到了Zen-score。
本文的主要贡献就是提出了Zen-Score,在NAS的搜索上没有什么特点,就是一个普通的遗传算法,NAS搜索方式见图8。

4.3 随机搜索
随机搜索指的就是在搜索空间中随机采样,在采样多个网络之后选择性能最好的一种。其实在AutoML中随机搜索一直不是一种很差的baseline,相反,算法想超过随机搜索其实并不容易。这一部分介绍巴黎综合理工和华为诺亚实验室在ICLR2020上发表的一篇介绍随机搜索的NAS的论文[22]。
作者找了8个有开源代码的 NAS 方法,在 5个不同的数据集上进行对比。这8个 NAS 方法是 DARTS,StacNAS,PDARTS,MANAS,CNAS,NSGANET,ENAS,NAO。这5个数据集是 Cifar 10,Cifar 100,Sport 8,MIT 67,Flowers 102。作者的实验分为三步:1、从这8个方法的搜索空间里面随机得到网络结构,然后在数据集上训练(训练的时候使用相同的随机数种子)。2、使用这8个方法的代码,搜出来8个结构,然后在数据集上训练(搜索时候的随机数种子不同,但训练时随机数种子相同)。3、比较随机采样的结构和搜出来的结构,在测试集上的性能差异。性能表现见图9。
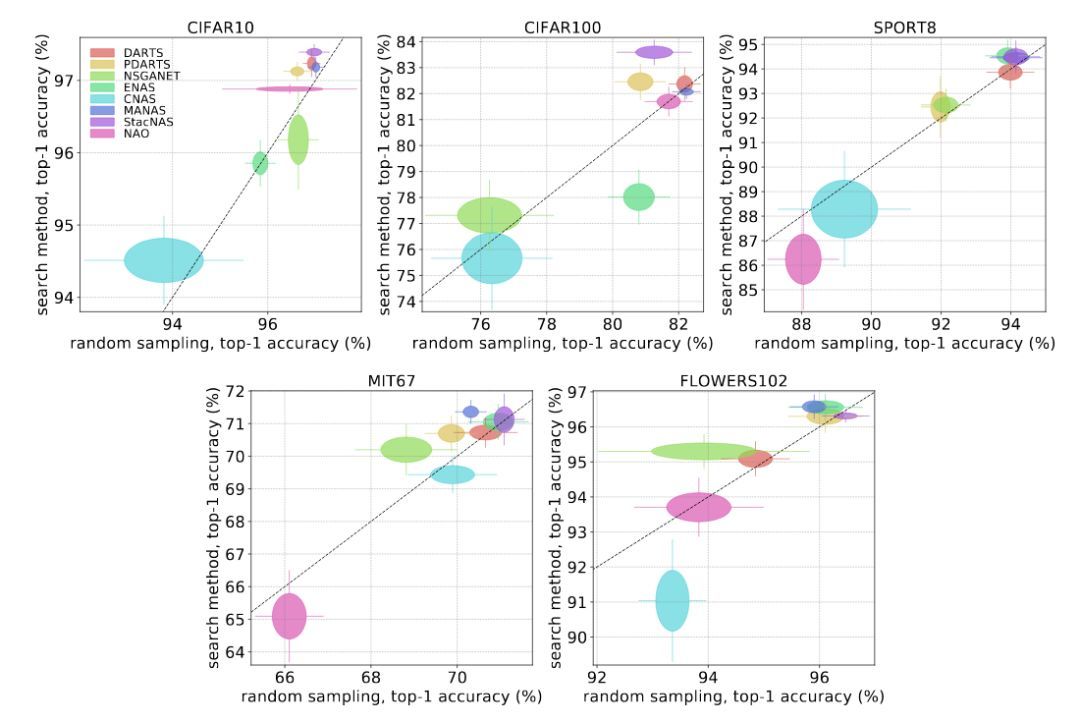
相比与随机搜索的方法,其实精心设计的方法的提升并没有很大。1、各个方法相比于随机采样得到的结果,提升是非常小的。在一些情况下,搜出来的结果甚至比随机采样得到的要差,说明搜索的方法并没有收敛。2、有些方法的准确率变化不大,说明搜索空间就很小,在这个小的搜索空间上面得到的较差的结构也是相对不错的。也就是说好的搜索空间起的作用大,搜索算法起到的作用小。3、在 Cifar 10上,一些方法 (PDARTS, MANAS, DARTS, StacNAS)表现的很接近,都还不错;但是换到其他数据集上,这些方法性能的方差就会很大,说明参数可能是在Cifar 10上面专门调的,泛化性能不好。
经过多种训练,作者得出的结论是:1、一些数据增强,train 更多 epochs 之类的 tricks 会对最终的结果影响很大。因此 paper 在报结果的时候,除了加各种 tricks 提高 performance,还应该报一下不加这些 tricks 的结果; 2、各种 paper 应该对比一下在搜索空间里面随机采样多个结构得到的结果。需要说明的是,这和随机搜索的对照实验是不一样的;3、各种 paper 应该给出在多个数据集上的结果,避免 overfit 某个特定的数据集;4、各种 paper 应该就各种结构上的参数(比如 DARTS 里面 cells 的数量)、训练参数给出严格的对照实验;5、可复现性,各种 paper 除了报一个最好的结果、最好的结构之外,还应该给出使用的种子、代码、详细的参数配置。最好是跑多次实验来验证;6、调参数的代价应该也纳入 NAS 的考虑中。
4.4 可微方法
可微方法最近几年在NAS领域得到了广泛的应用。这里简单将其分为DARTS类[7:1]的方法和其余的可微方法,这主要是因为DARTS类的可微方法在今年的论文中频繁出现,很多论文也致力于修改原始的DARTS算法。以下详细介绍。
4.4.1 DARTS类算法
4.4.1.1 DARTS
首先简单介绍一下DARTS,DARTS的思路其实非常简单,就是把原来离散的结构搜索问题松弛为一个连续问题。从而可以用梯度的方式进行优化。与离散的搜索方式比起来,DARTS需要的搜索时长相当短,但是需要注意的是,作为一种two-stage的算法,其在目标数据集上的retrain时间事实上也应该算上,这一点在后文one-stage部分会详细叙述。DARTS的思路可以见图1。在最初的状态的时候,图是一个有向无环图,并且每个后边的节点都会与前边的节点相连,这里的节点可以理解为特征图;边代表采用的操作,比如卷积、池化等。
引入数学标记:
节点(特征图)为:(x(i)) 代表第i个节点对应的潜在特征表示(特征图)。
边(操作)为: (O(i,j)) 代表从第i个节点到第j个节点采用的操作。
每个节点的输入输出如下面公式表示,每个节点都会和之前的节点相连接,然后将结果通过求和的方式得到第j个节点的特征图。
所有的候选操作为O, 在DARTS中包括了3x3深度可分离卷积、5x5深度可分离卷积、3x3空洞卷积、5x5空洞卷积、3x3最大化池化、3x3平均池化,恒等,直连,共8个操作。
而松弛过程的式子为:
其中(alpha_o^{(i,j)}) 表示 第i个节点到第j个节点之间操作的权重,这也是之后需要搜索的网络结构参数,会影响该操作的概率。搜索的目标就是从所有的边中找到概率最大的边,即以下公式:
在优化过程中一共有两个需要优化的:结构αα和每个结构对应的内部参数权重w。这就导致了一个二层优化问题如图10所示:
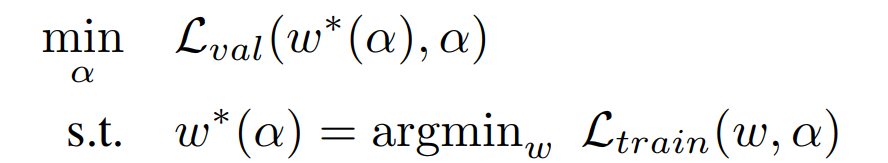
本部分详细数学推导都可以见博客:【论文笔记】DARTS公式推导 - 知乎 (zhihu.com)
由于上述的二层优化比较难进行,因此实际过程中进行如下简化:
对上述式子整理一下可以得到如下式子:
再进行一个有限差分之后可以得到如下估计
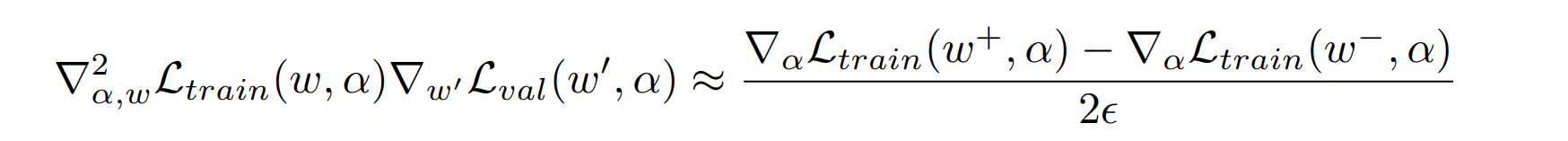
简单来说就是做了一个一阶的泰勒展开。
作者提出可以直接把后面的二阶导数扔掉,但是实验证明估计效果不如不扔。
假设通过之前说的这些流程,架构参数已经训练的挺不错了。那么,接下来就要提取真正的模型了,因为直至目前,架构依然是计算了所有的操作,而所有操作依然是连续组合而不是离散的。 但是,和分类问题一样,我们可以取出每条边上权重最大的 (k) 个操作(在CNN中DARTS取2个最大的操作,并忽略0操作)。
DARTS的优点相当显然,就是将离散问题连续化,大大加速了搜索过程。但是这个搜索过程其实存在相当多的问题:
- 小数据集上训练出的模型可以迁移到大规模数据集(ProxylessNAS[23]解决的是这个问题)
- zero操作没有影响
- 在验证集上效果最好的模型,在测试集上效果也最好
- 每个cell的输出都是中间节点的输出经过操作之后得到。
- (alpha)和每个操作的真实重要性其实关系并不是很大。(很多论文解决的是这个问题)
以下介绍几篇从不同角度对DARTS的优化的论文(有的论文可能不是专门修改DARTS,为了方便归在这一类)
4.4.1.2 ProxylessNAS
ProxylessNAS提出的目的可能未必是为了解决DARTS的问题,但是其方法具有一定的可参考性。
我们知道NAS可以有效设计神经网络,但是在大多数时候,在训练的前期,算法只能在CIFAR-10这种较小的数据集上运行,而如果在ImageNet上直接搜索的话会出现GPU memory和时间消耗太大的问题。前者是因为如果像DARTS一样训练的话,计算图非常大,而在每次训练的时候这个计算图都需要加载到GPU中,如果数据集太大对于GPU压力太大。
那么这样就会出现一个问题,算法在小数据上的搜索出来的模型,可能在 target task 上并不是最优的。而ProxylessNAS的处理方式就两个:1、训练的时候把路径二值化(其实就是一次只训练一个路径)2、剪枝(和DARTS选择方式一样)。
训练的时候将路径二值化其实对比DARTS中每一条路径都训练,区别就是只抽样一条路径训练,概率就是DARTS中的 (alpha)值。这样带来的结果是: the memory requirement of training the over-parameterized network is thus reduced to the same level of training a compact model。
同时作者发现更新的时候仍然需要N倍的memory cost,因此在更新(alpha)的时候从N个路径中取2个,假设只有两条路径,重新设置(alpha)的值,按照梯度下降方式更新,再乘一个系数,这样最终结果就是采样到的两个网络中一个(alpha)增大,一个减小,没被采样到的网络(alpha)不变,这样需要的memory cost就大大下降了。
4.4.1.3 DARTS-[24]
本文是美团,上交,小米,中科院联合发表与ICLR2021的文章,主要解决的问题是DARTS中skip频繁出现导致搜索出来的网络结构的退化问题。
首先文章证明了为什么skip connect会在DARTS搜索中频繁出现。详细的推导过程可以见原文,这里只说结果。假设(beta_{skip})表示skip-connection的重要程度,DARTS中(beta_{skip})的增大可能来自于两个方面:一方面,当超网自动学习以减轻梯度消失时,它将 (beta_{skip}) 推至适当的大值; 另一方面,跳过连接的确是目标网络的重要连接,应在离散化阶段选择该连接。 因此,DARTS中的跳过连接起着双重作用:作为稳定超网训练的辅助连接,以及作为构建最终网络的候选操作。 也就是说在选择过程中是该操作时存在两种不同的作用的。受以上观察和分析的启发,本文建议通过区分跳过连接和处理梯度流的两个作用来稳定搜索过程。因此DARTS-的示意图如图12所示。
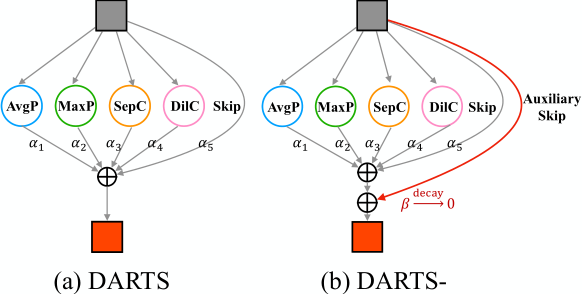
DARTS-的思路其实非常简单,就是直接在一个单元的每两个节点之间引入一个辅助跳过连接,这样即使(beta_{skip})很小,固定的辅助跳过连接也具有稳定超网训练的功能。 另一方面,它也打破了不公平的优势,因为残差块的有利贡献被排除了。这样(beta_{skip})就可以摆脱控制梯度的作用,更加精确的旨在表示skip-connection作为候选操作的重要性。
详细的数学推导可以见原文,经过实验,确实在多个数据集上相较于DARTS确实有性能提升。
4.4.1.4 DARTS+[25]
本文是华为诺亚方舟实验室的工作,针对的也是DARTS中skip-connection富集的问题,但是解决的方式和DARTS-的解决角度不同。其使用的是early-stopping的方式。不仅减小了 DARTS 搜索的时间,而且极大地提升了 DARTS 的性能。而停止的准则有两条:1.当一个 cell 中出现两个及两个以上的 skip-connect 的时候,搜索过程停止。2.当各个可学习算子(比如卷积)的 alpha 排序足够稳定(比如 10 个 epoch 保持不变)的时候,搜索过程停止。
文中指出,准则 1 更便于操作,而当需要更精准的停止或者引入其他的搜索空间的时候,可以用准则 2 来代替。由于early-stopping机制解决了 DARTS 搜索中固有存在的问题,因此,它也可以被用在其它基于 DARTS 的算法中来帮助提高进一步性能。
4.4.1.5 beta-DARTS[26]
本文是复旦大学和百度联合发表于CVPR2022上的文章。解决的也是skip-connection富集的问题。解决方法是在损失函数中中加入一个正则项。需要注意的是,之前的损失函数其实也有正则项,但是本文对正则项的提出的出发点和之前的文章不同,本文的正则项的出发点是通过正则项的约束,使得(beta)的变化不是太大,也就是每次更新的时候对每个操作的重要性的改变不要太大。可以施加约束来保持激活的体系结构参数的值和方差不太大,通过实验,这样会使得skip-connection富集的现象得到缓解。
详细的数学推导可以见原文,最终提出一种正则化方式如图13所示。通过这个正则项可以有效控制(beta)的每次变化幅度。
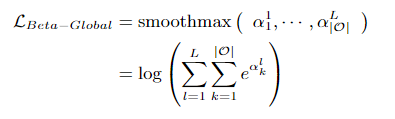
4.4.1.6 Rethinking Architecture Selection in Differentiable NAS[27]
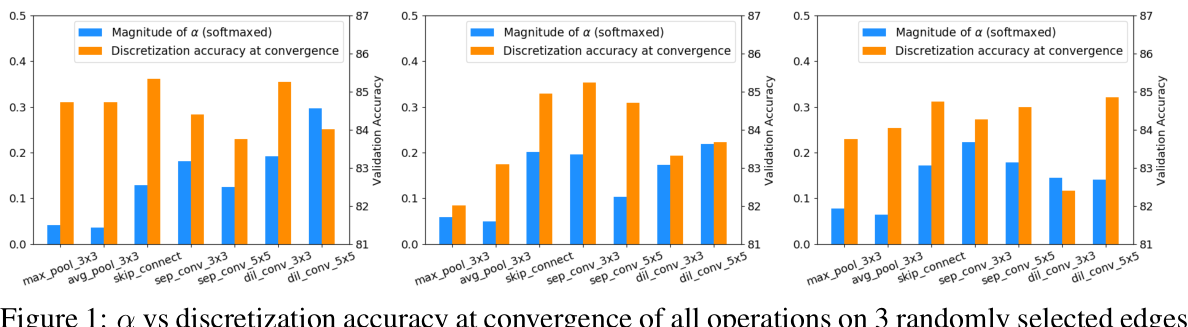
本文是UCLA发表于ICLR2021的工作,主要表明体系结构参数的大小不一定表示操作对超网性能的贡献有多大。提出了另一种基于扰动的架构选择,直接测量每个操作对结果的影响。表明DARTS中观察到的较差的泛化能力可以归因于基于规模的体系结构选择的失败,而不是其超网的完全优化。
DARTS的缺点有1.简单的随机搜索的性能优于原始的DARTS。2.DARTS可能退化为充满无参数操作的网络,例如跳跃连接甚至随机噪声,导致所选架构的性能很差。之前很多研究把这些缺点的原因归结于supernet没有优化好,但是本文指出可能是在多数情况下(alpha)无法很好的反应操作的重要性。如图14所示。同时本文也从理论角度证明了为什么skip-connection在DARTS搜索结果中频繁出现。
基于上述问题,本文提出了根据操作对超网性能的贡献来直接评估操作强度。本文的评估方式是评估存在某条边和不存在的时候,网络在收敛时的精度差异,这个差异表示操作强度。为了减少计算开销,我们考虑了更实际的度量操作强度:对于给定边上的每个操作,我们在保持所有其他操作的同时屏蔽它,并重新评估超网。导致超网验证精度下降最大的一次操作将被视为该边缘最重要的操作。因此本文提出的算法如图15所示。

4.4.1.7 Theory-Inspired Path-Regularized Differential Network Architecture Search[28]
本文详细证明了为什么在DARTS中skip-connection富集:跳过连接越多,网络收敛的越快,从而在搜索的时候会表现出来的性能越好。详细证明过程可以见原文。同时本文提出对于skip和非skip操作分组计算loss,使用两种不同的loss方式,如图16所示。通过loss的不同控制skip-connection出现的次数。
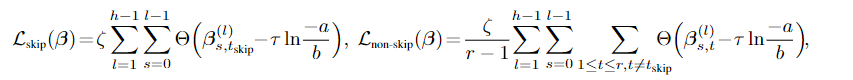
在此简单总结目前针对DARTS修改的文章主要针对的一些点:
- 需要的GPU显存太大
- (beta)无法反应真实的操作强度
- skip操作频繁出现
- 需要在小数据集上先搜索,然后在大数据集上使用
4.4.2 其余可微方法
由于DARTS的松弛直接假设操作重要性和参数之间存在关系,这一点在后续很多文章中证明并非如此,因此一些基于概率论的理论推导的可微方法出现了。这里简单介绍一种。
4.4.2.1 SNAS[29]
本文是商汤发表于ICLR2019的工作。本文从强化学习的角度出发,分析了强化学习在NAS问题上为什么收敛的慢,同时进一步建模NAS问题,与基于强化学习的方法相比,SNAS的搜索优化可微分,搜索效率更高,可以在更少的迭代次数下收敛到更高准确率;与其他可微分的方法相比,SNAS直接优化NAS任务的目标函数,搜索结果偏差更小,可以直接通过一阶优化搜索;同时网络在使用的时候不需要重新训练参数;并在硬件约束上有一定拓展。
首先,强化学习在这种情况下收敛的慢的原因在于NAS是一个确定环境中的完全延迟奖励的任务。简单来说就是NAS的reward要在整个网络设计完之后才能得到,而不是设计一步就能得到一步的reward,这样就导致基于强化学习的方法收敛的慢且会出现震荡的现象。
因此本文使用用损失函数来替代准确率,从而将NAS的总得分转化成了一个可微函数,通过转换之后,可以将神经网络的设计问题转化为一个mask矩阵的设计问题。对这个矩阵Z来说,(Z_{i,j})表示在边(i,j)上的one-hot随机变量。因此在梯度下降的时候只需要学习这个矩阵Z即可。但是由于argmax操作事实上是不可为的,因此使用图17式子进行可微近似。
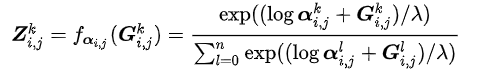
当(lambda)趋近于无穷时此估计趋近于离散分布。简单来说本文提出的这种方法就类似于在DARTS中选择最优可能性的那个操作进行更新。DARTS可以看做SNAS的一个更粗糙的优化,如果网络中只有线性操作的话是可行的,但是由于网络中存在的ReLU、BatchNorm等操作,因此造成了误差。
4.5 贝叶斯优化
此方面阅读的文章暂时还不多,后续阅读多了后补上此部分。
4.6 其他方法
除了上述方法,还存在很多NAS的方法。现在挑选其中的一些来展示如下。
4.6.1 基于NTK的优化
这里主要介绍首尔国立大学发表于CVPR2022的一篇论文[30]的工作。本文证明了基于神经正切核(NTK)的方法由于目前的网络中具有越来越多的非线性因素,因此已经很难简单的使用NTK方式来衡量网络的性能。详细证明可见原文。
本文提出了使用一种 Label-Gradient Alignment(LGA)方式来衡量一个网络的性能如何。计算方式如图18。
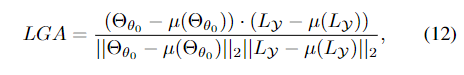
使用这种方式,可以在搜索的网络只训练3个epoch或者5个epoch的时候较快的判断这种网络的性能如何,类似于zero-shot。
4.6.2 基于博弈论的优化
这里主要介绍的是清华大学发表在CVPR2022上的工作[31]。本文的出发点同样是DARTS的参数无法反映操作的重要性,因此在DARTS中引入了博弈论中的一个值:shapley value,用这个值来表示操作的重要程度。同时因为这个值的计算是一个NP-hard的问题,因此只使用蒙特卡洛采样M个网络来计算。计算过程如图19所示。
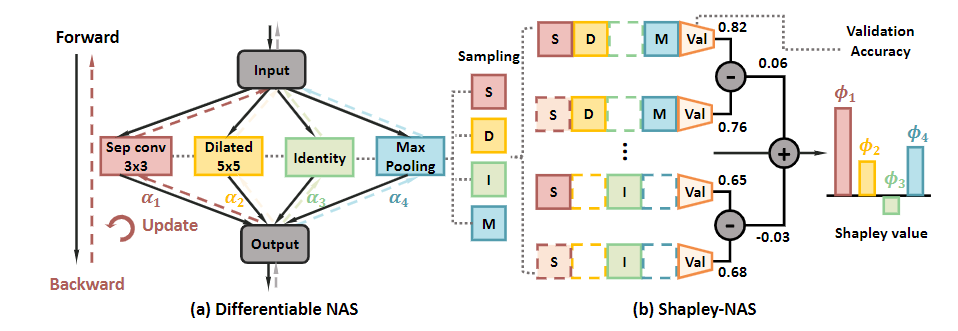
而shapley-value的计算方式如图20所示:
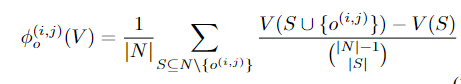
同时因为需要进行蒙特卡洛采样,因此文中进行了一些近似,详细近似可见原文。
一些分类方式
one-shot与其他
简单来说,最原始的NAS就是每次得到一个网络之后从0开始训练神经网络直到收敛之后评价这个网络的性能,之后循环这个过程。很显然从0开始训练这个过程是非常花时间的,那么one-shot方法的提出就是意味着训练一次 Supernet,便可以针对各种不同的constraint,得到多种不同的 network。
One-Shot NAS可以分成两个阶段,分别是 training stage 和 searching stage:
- Training stage:在这个阶段,并不会进行搜索,而是单纯训练 Supernet ,使得 Supernet 收敛至一定的程度。
当 Training stage 结束时, Supernet 中的参数就被训练收敛了,这个时候进入第二阶段。
- Searching stage:从 Supernet 中不断取出 Sub-network,并使用 Supernet 的 weight 给Sub-network赋权重,这样就可以得到不同的Sub-network 的 validation accuracy,直到取得最好且符合 hardware constraint 的 Sub-network。
但是one-shot面临的问题一般有如下:
- 巨大的GPU内存消耗
- alpha 和 weight 相互耦合
- 训练集上最优,验证集上不一定最优
- 小数据集上最优,换个数据集不一定最优
目前大部分方法其实都是one-shot的,或者吸取了one-shot方法的思想。
5.one-stage与two-stage
one-stage和two-stage的区别就是在得到网络之后在数据集上应用的时候还需不需要再训练一次。这其实是一个很关键的问题,例如DARTS就是一个很典型的two-stage的方法,从supernet中采样的子网络在使用的时候是一定需要在目标数据集上重新训练的,这样需要花的时候比较多。而最早的基于强化学习的NAS很多都是one-stage的,产生的神经网络可以直接使用而不需要重新训练。这里简单介绍一种one-stage的方法。
5.1 DSNAS[32]
这是商汤发表于2020年CVPR的工作。文章对现有NAS two-stage pipeline进行了反思,发现在search和evaluation(retrain)阶段优化方式不可避免的不一样,这两种不同的优化方式会导致search和evaluation阶段的相关性变差。如果这两个阶段相关性不好的话,那么就不能根据search阶段的accuracy判断搜索出来的网络的优劣,也不能将search阶段的损失函数作为整个NAS的损失函数
本文是SNAS[29:1]的升级版,本文中直接将SNAS中的(lambda)推广到无穷大,这样Z就可以看成是一个0-1矩阵,每次选择的时候也只会选择一条路径进行优化(其实大部分single-path的优化都可以满足这个条件)。具体数学推导可见原文,本文提出的算法的伪代码如图21所示。
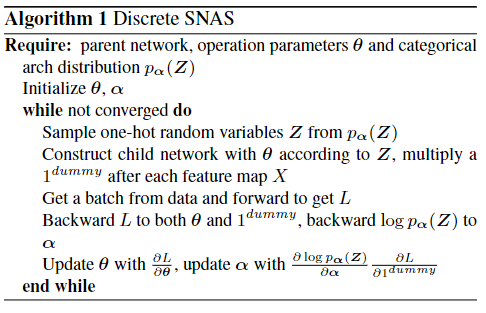
优化
以下部分后续更新
速度优化
硬件优化
引用文献与网址
[NAS(神经结构搜索)综述 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/60414004#:~:text=神经结构搜索(Neural,Architecture Search,简称NAS)是一种自动设计神经网络的技术,可以通过算法根据样本集自动设计出高性能的网络结构,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。) ↩︎
Peng W, Hong X, Chen H, et al. Learning graph convolutional network for skeleton-based human action recognition by neural searching[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020, 34(03): 2669-2676. ↩︎
Dong X, Yang Y. Nas-bench-201: Extending the scope of reproducible neural architecture search[J]. arXiv preprint arXiv:2001.00326, 2020. ↩︎
Zhang W, Shen Y, Lin Z, et al. Pasca: A graph neural architecture search system under the scalable paradigm[C]//Proceedings of the ACM Web Conference 2022. 2022: 1817-1828. ↩︎
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30. ↩︎
Arican M E, Kara O, Bredell G, et al. ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image Prior[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 1960-1968. ↩︎
Liu H, Simonyan K, Yang Y. Darts: Differentiable architecture search[J]. arXiv preprint arXiv:1806.09055, 2018. ↩︎ ↩︎
Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9. ↩︎
Liu H, Simonyan K, Vinyals O, et al. Hierarchical representations for efficient architecture search[J]. arXiv preprint arXiv:1711.00436, 2017. ↩︎
He X, Zhao K, Chu X. AutoML: A survey of the state-of-the-art[J]. Knowledge-Based Systems, 2021, 212: 106622. ↩︎
Zoph B, Le Q V. Neural architecture search with reinforcement learning[J]. arXiv preprint arXiv:1611.01578, 2016. ↩︎ ↩︎ ↩︎
Pham H, Guan M, Zoph B, et al. Efficient neural architecture search via parameters sharing[C]//International conference on machine learning. PMLR, 2018: 4095-4104. ↩︎ ↩︎
Williams R J. Simple statistical gradient-following algorithms for connectionist reinforcement learning[J]. Machine learning, 1992, 8(3): 229-256. ↩︎
Zoph B, Vasudevan V, Shlens J, et al. Learning transferable architectures for scalable image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8697-8710. ↩︎
Xie L, Yuille A. Genetic cnn[C]//Proceedings of the IEEE international conference on computer vision. 2017: 1379-1388. ↩︎
Liu H, Simonyan K, Vinyals O, et al. Hierarchical representations for efficient architecture search[J]. arXiv preprint arXiv:1711.00436, 2017. ↩︎
Real E, Aggarwal A, Huang Y, et al. Regularized evolution for image classifier architecture search[C]//Proceedings of the aaai conference on artificial intelligence. 2019, 33(01): 4780-4789. ↩︎
[神经结构搜索中的遗传算法 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/359542872#:~:text=遗传算法是一种基于基因选择的优化算法,它模拟了自然界中种群优胜略汰的进化过程,是一种全局最优的稳定的优化算法。. 公认的第一个把遗传算法用于NAS的是Google的Large-Scale Evolution of Image,Classifiers [8]。. 在large-scale evolution中,个体的网络结构和部分参数被编码为DNA,worker每次随机选择一对个体,通过tournament selection选择适应性强的个体进行变异,加入种群,适应性差的直接从种群中移除。. 这篇论文证明了遗传算法在NAS的有效性,此后,遗传算法就成了NAS中的研究热点。.) ↩︎
You S, Huang T, Yang M, et al. Greedynas: Towards fast one-shot nas with greedy supernet[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 1999-2008. ↩︎
Huang T, You S, Wang F, et al. Greedynasv2: greedier search with a greedy path filter[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11902-11911. ↩︎
Lin M, Wang P, Sun Z, et al. Zen-nas: A zero-shot nas for high-performance image recognition[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 347-356. ↩︎
Yang A, Esperança P M, Carlucci F M. NAS evaluation is frustratingly hard[J]. arXiv preprint arXiv:1912.12522, 2019. ↩︎
Cai H, Zhu L, Han S. Proxylessnas: Direct neural architecture search on target task and hardware[J]. arXiv preprint arXiv:1812.00332, 2018. ↩︎
Chu X, Wang X, Zhang B, et al. Darts-: robustly stepping out of performance collapse without indicators[J]. arXiv preprint arXiv:2009.01027, 2020. ↩︎
Liang H, Zhang S, Sun J, et al. Darts+: Improved differentiable architecture search with early stopping[J]. arXiv preprint arXiv:1909.06035, 2019. ↩︎
Ye P, Li B, Li Y, et al. $beta $-DARTS: Beta-Decay Regularization for Differentiable Architecture Search[J]. arXiv preprint arXiv:2203.01665, 2022. ↩︎
Wang R, Cheng M, Chen X, et al. Rethinking architecture selection in differentiable NAS[J]. arXiv preprint arXiv:2108.04392, 2021. ↩︎
Zhou P, Xiong C, Socher R, et al. Theory-inspired path-regularized differential network architecture search[J]. Advances in Neural Information Processing Systems, 2020, 33: 8296-8307. ↩︎
Xie S, Zheng H, Liu C, et al. SNAS: stochastic neural architecture search[J]. arXiv preprint arXiv:1812.09926, 2018. ↩︎ ↩︎
Mok J, Na B, Kim J H, et al. Demystifying the Neural Tangent Kernel from a Practical Perspective: Can it be trusted for Neural Architecture Search without training?[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11861-11870. ↩︎
Xiao H, Wang Z, Zhu Z, et al. Shapley-NAS: Discovering Operation Contribution for Neural Architecture Search[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 11892-11901. ↩︎
Hu S, Xie S, Zheng H, et al. Dsnas: Direct neural architecture search without parameter retraining[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 12084-12092. ↩︎
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


