
一、内容协同过滤之物品协同过滤
协同过滤算法是指:利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息。
物品协同过滤是指协同过滤算法在进行筛选的时候是以物品之间的相似度作为衡量,如图1:
|
电影名 |
R |
Toy |
RxToy |
Jumanji |
RxJumanji |
Grumpier |
RxGrumpier |
|
Waiting |
4.7 |
0.171 |
0.808 |
0.212 |
0.996 |
0.077 |
0.362 |
|
Father |
2.7 |
0.009 |
0.024 |
0.102 |
0.275 |
0.085 |
0.230 |
|
Heat |
1.0 |
0.165 |
0.165 |
0.7 |
0.7 |
0.203 |
0.023 |
|
总计 |
|
0.345 |
0.997 |
1.014 |
1.971 |
0.365 |
0.615 |
|
归一化 |
|
|
2.890 |
|
1.944 |
|
1.685 |
图1
第二、三、四行每一列的意思分别为:电影名字《Waiting》、某用户给《Waiting》的打分、《Waiting》与《Toy》之间的相似度(计算方法见第四节)、《Waiting》的打分乘以《Waiting》与《Toy》之间的相似度…以此类推。
第四行给出了相似度累计值和Rx电影名的累计值。
第五行使用Rx电影名的累计值除以相似度累计值。
根据第五行的计算,我们基于推荐影片的评分分别为Toy:2.890,Jumanji:1.944,Grumpier:1.685。由此可见,《Toy》应该优先推荐给该用户。
二、皮尔逊相关度
皮尔逊相关系数广泛用于度量两个变量之间的相关程度,其值介于-1与1之间。
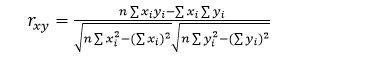 公式1
公式1
三、欧几里得距离
欧几里得距离或欧几里得度量是欧几里得空间中两点间“普通”(即直线)距离。
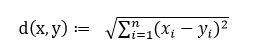 公式2
公式2
四、相似度矩阵
衡量物品之间的相似度,这里我们使用用户打分维度作为相似度特征,如图2:
|
电影名 |
用户1打分 |
用户2打分 |
用户3打分 |
|
Waiting |
1 |
2 |
3 |
|
Father |
3 |
2 |
1 |
|
Heat |
1 |
2.5 |
3 |
图2
可以使用皮尔逊相关度或者欧几里得距离计算:《Waiting》与《Heat》属于同一类型,与《Father》属于不同类型。
五、系统构造基本流程
1、 构造用户打分数据,例如:ID为87的用户给部分电影的打分如下;
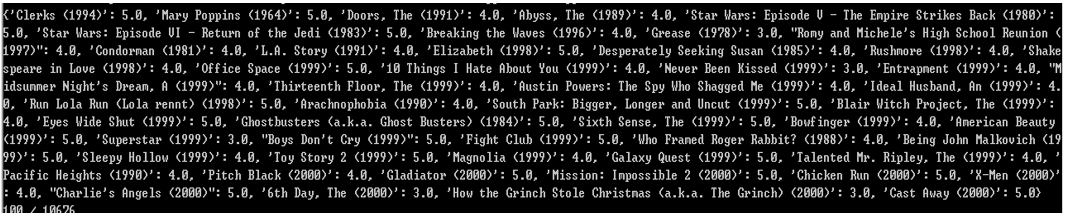
2、 根据用户打分数据构造物品相似度矩阵;根据相似度矩阵构造用户推荐列表,例如给ID为87的用户推荐的影片如下:

六、测试代码、测试数据、参考资料
https://github.com/dongguadan/recommender-system/tree/master/Item-Based-Filter
《集体智慧编程》
- 还没有人评论,欢迎说说您的想法!



 客服
客服


