
系统:windows 10
elasticsearch版本:5.6.9
es分词的选择
- 使用es是考虑服务的性能调优,通过读写分离的方式降低频繁访问数据库的压力,至于分词的选择考虑主要是根据目前比较流行的分词模式,根据参考文档自己搭建测试。
es配置目录结构
- 在此先贴出es下plugins的目录结构,避免安装时一脸茫然(出自本人配置目录,可根据自身需要进行调整):
- es插件目录结构:

- ik压缩包内文件列表:
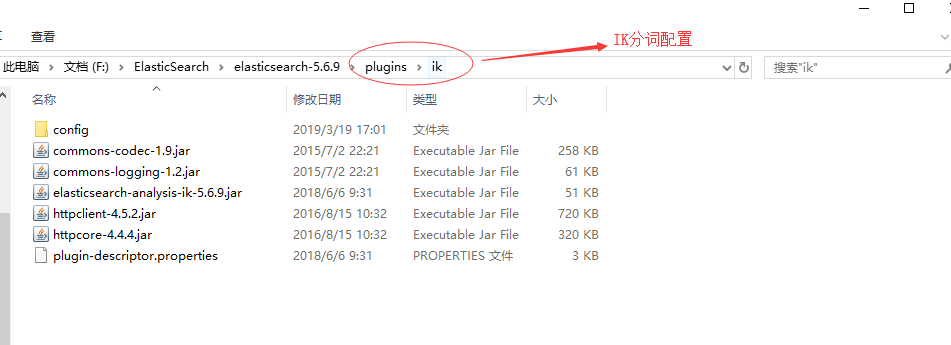
- pinyin压缩包内文件目录:

IK 分词器
- IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v5.6.11
- 进入链接,选择对应版本编译好的压缩包,点击即可下载。如下图:
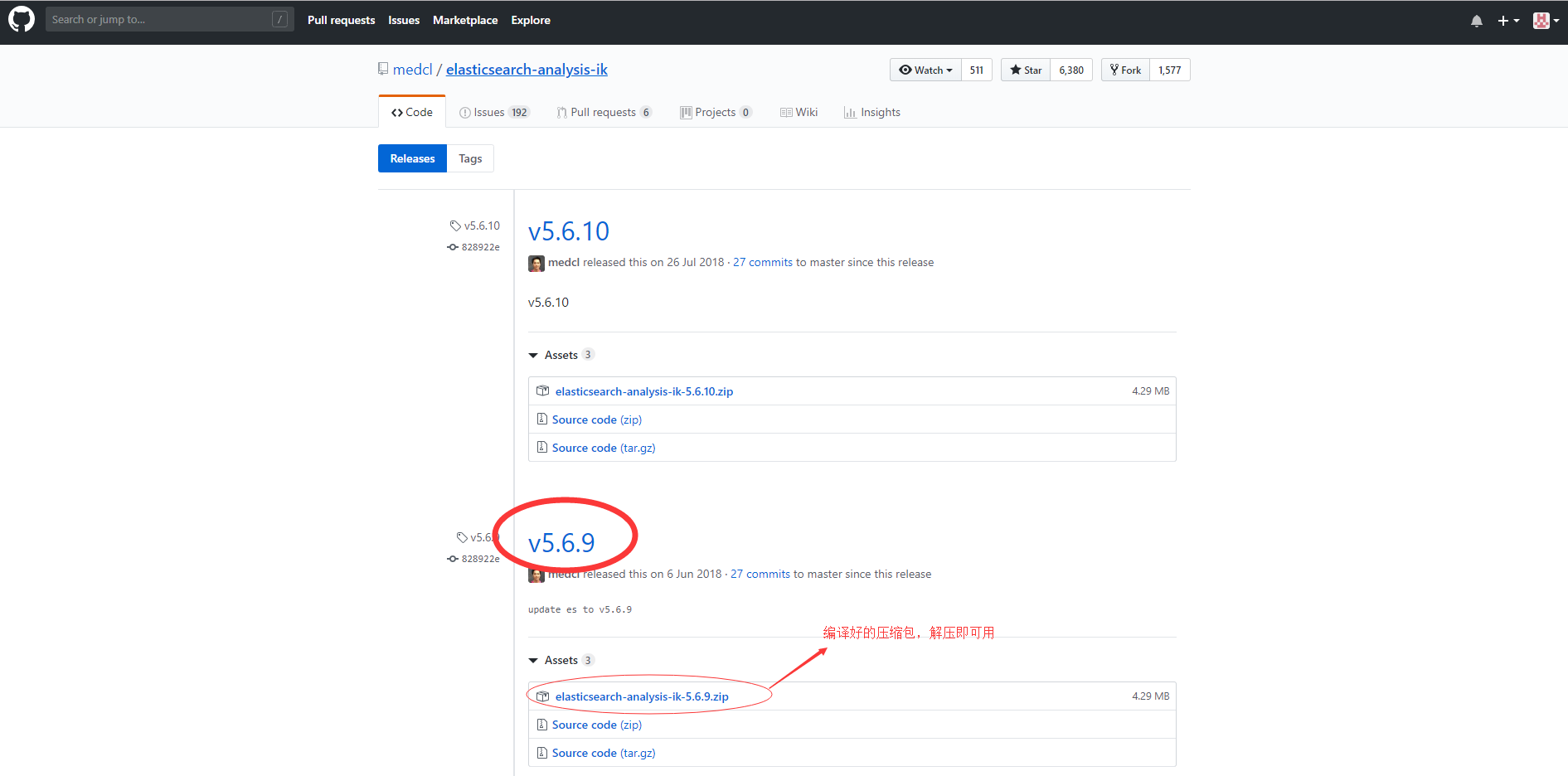 、
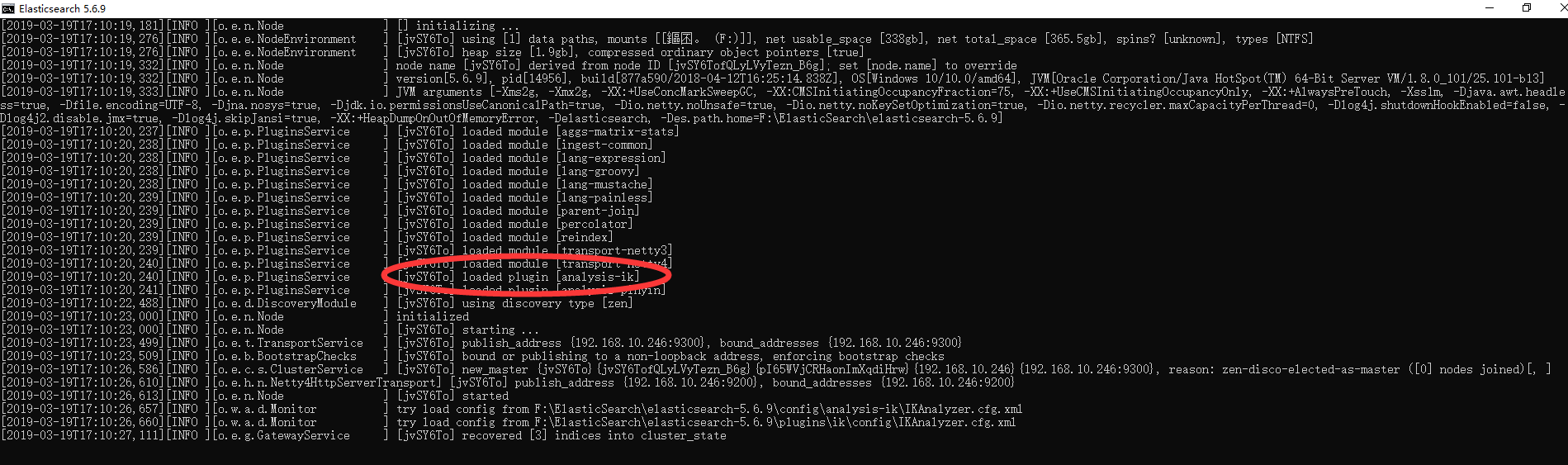
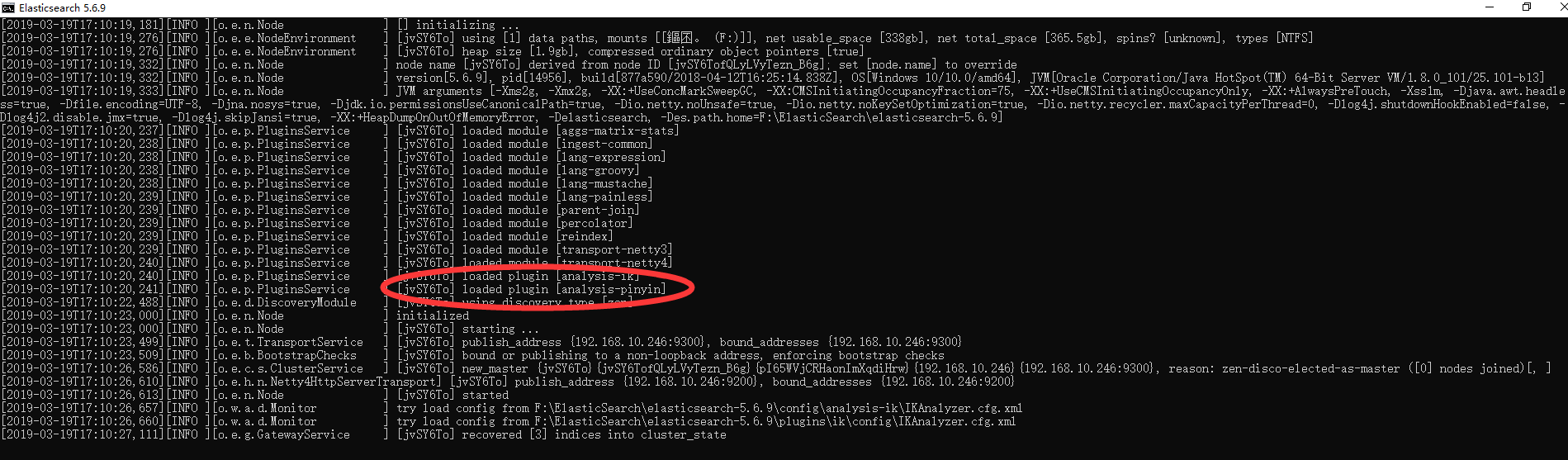
、 - 上述步骤下载后,解压文件到至elasticsearch5.6.9pluginsik目录下(如无ik目录,手动创建即可),重新启动es服务,即可看到控制台输出的插件信息,表示配置成功。如下图:
pinyin分词器
- 拼音分词器下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin/releases?after=v5.6.11
- 拼音分词的配置类似于ik分词,进入链接,选择对应版本编译好的压缩包,点击即可下载。如下图:
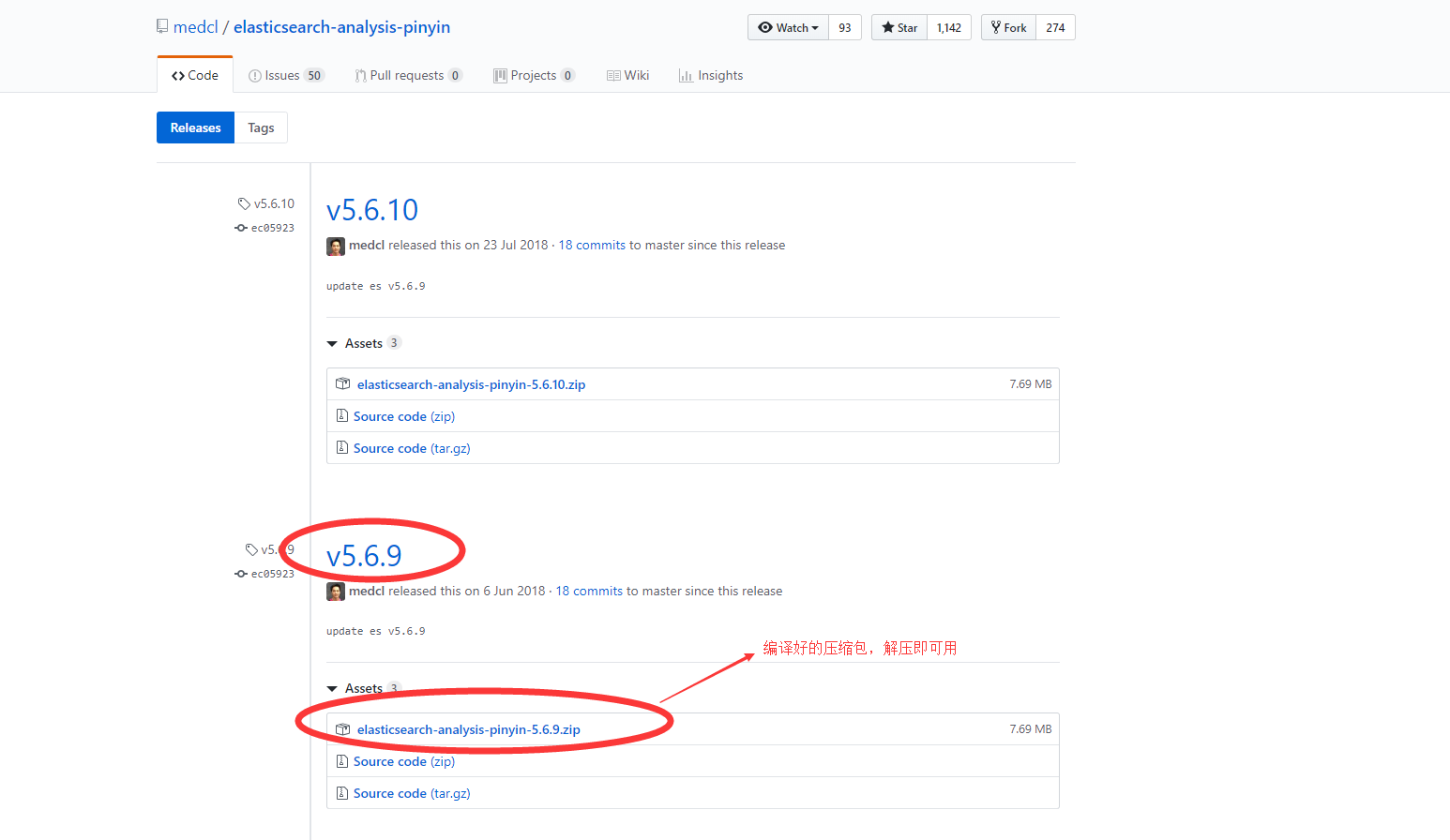
- 上述步骤下载后,解压文件到至elasticsearch5.6.9pluginspinyin目录下(如无pinyin目录,手动创建即可),重新启动es服务,即可看到控制台输出的插件信息,表示配置成功。如下图:
分词器的测试案例
- IK分词,主要强调两种分词模式:ik_smart和ik_max_word
- ik_smart是将文本做了正确的拆分,如下图:
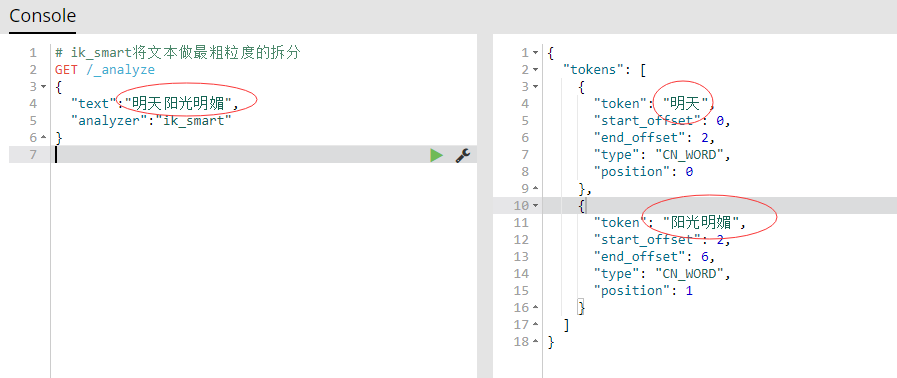
- 看到结果发现ik_smart分词模式拆分的不够细,“阳光明媚”并没有拆分开,所以接下来就该另一种分词出场了 ---- ik_max_word,直接上结果,如下图:
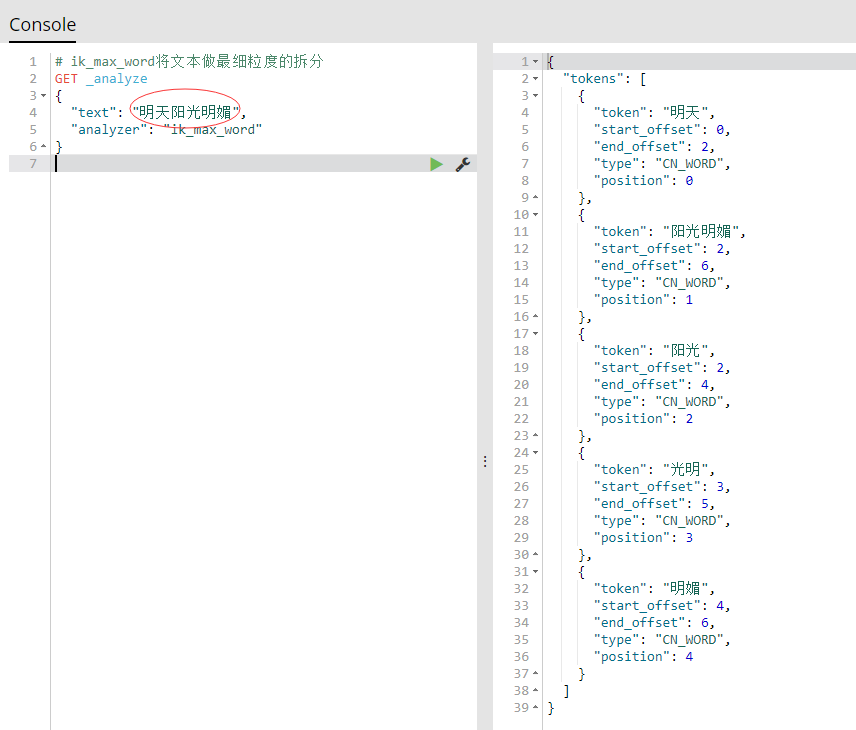
- 这种更加详细的拆分才是我想要的,这回不用担心高级搜索了····
- ik_smart是将文本做了正确的拆分,如下图:
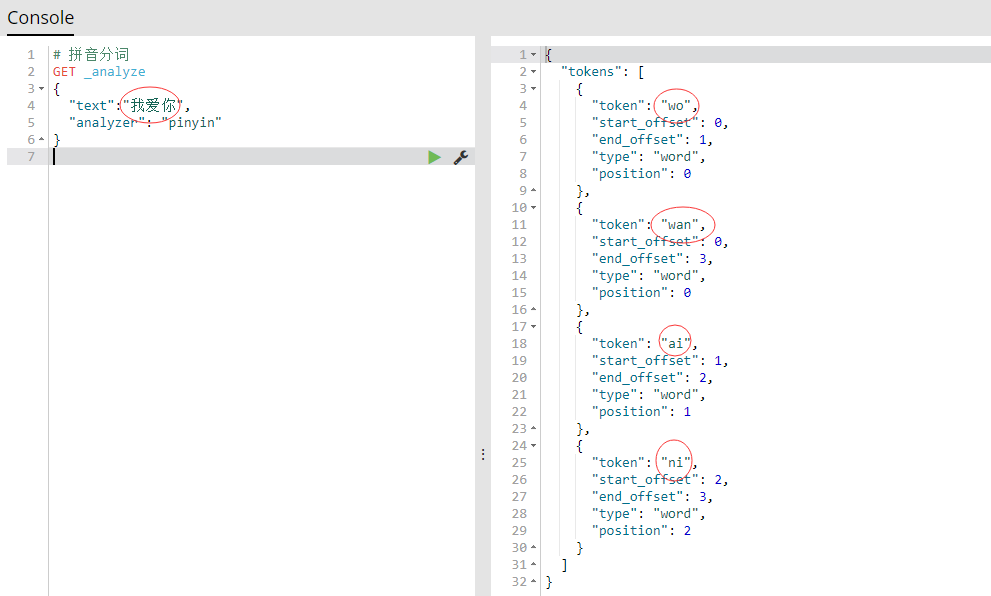
- 拼音分词,简言之就是将文本拆分成更加详细拼音,图解如下:
- ik与pinyin的结合使用(注:当使用分词搜索数据的时候,必须是通过分词器分析的数据才能搜索出来,否则无法搜索出数据)
- 创建索引时可以自定义分词器配置,通过映射可以指定自定义的分词器,配置如下图:
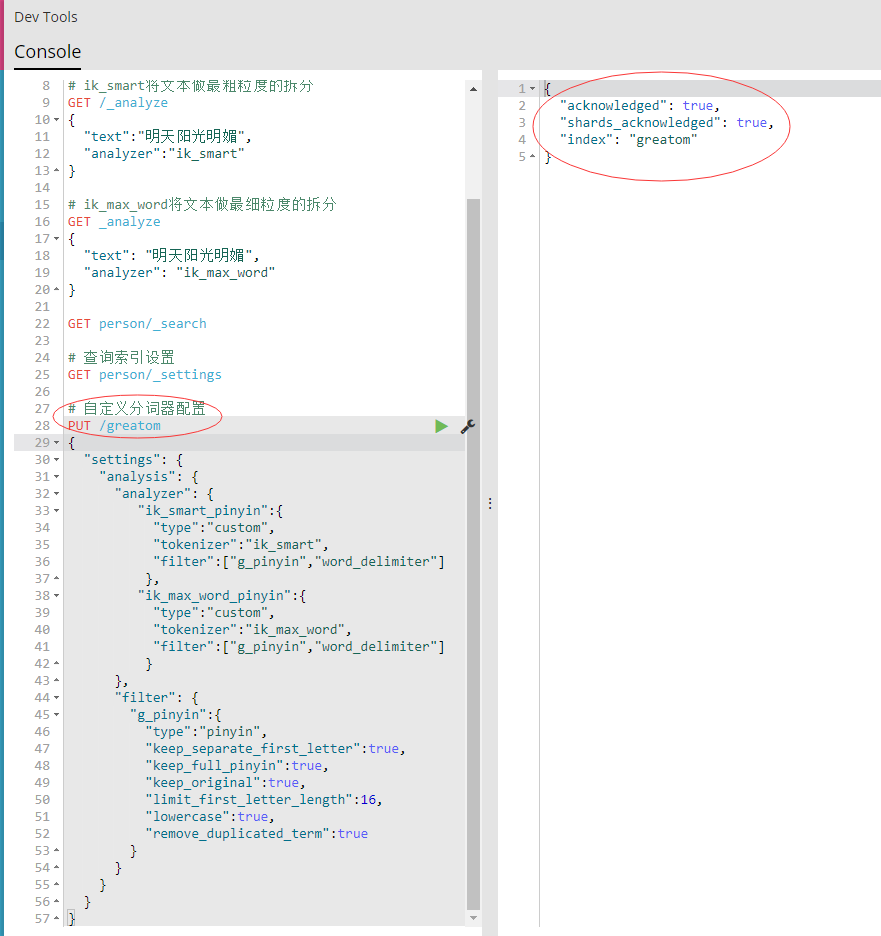
- 创建名称为“greatom”的索引,自定义“ik_smart_pinyin”和“ik_max_word_pinyin”的分词器,过滤设置为“g_pinyin”,如上图右侧提示则表示设置成功,可以通过“GET greatom/settings”查询配置信息。
- 创建type时,需要在字段的解析属性(analyzer)中设置自定义名称的映射,如下图:

- 如上图右侧提示则表示创建成功,接下来增加点数据,以便后续测试。
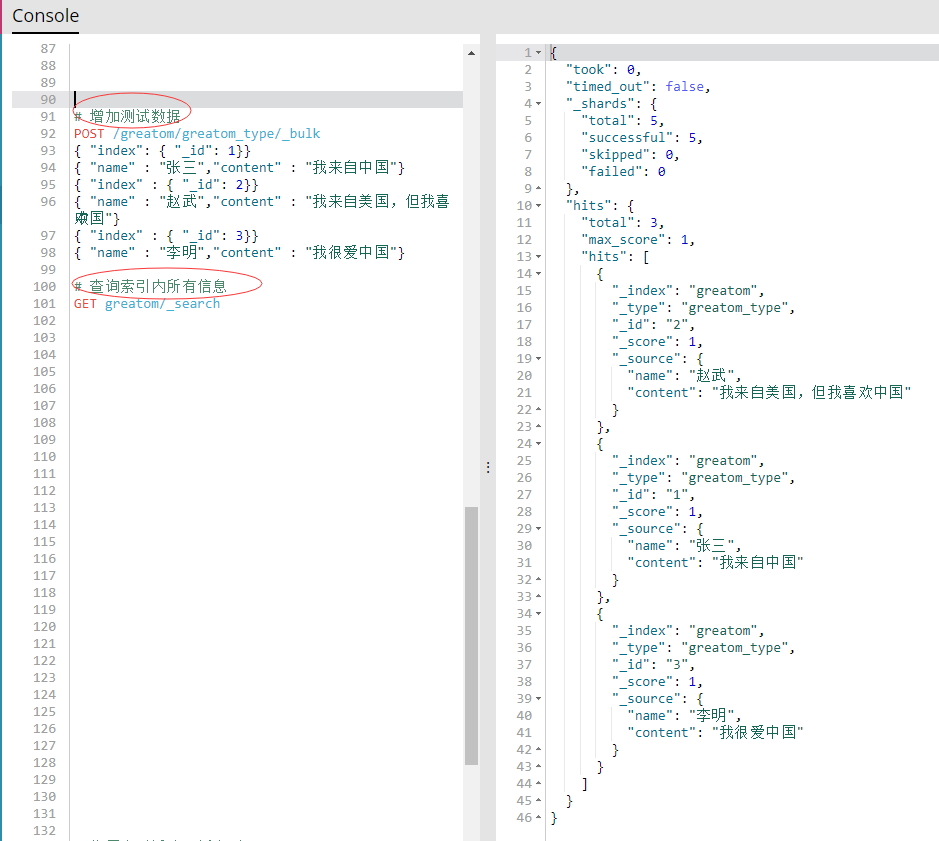
- 测试数据按照上图方式即可进行批量新增,也可对索引数据进行查询。接下来就开始正式的分词查询。
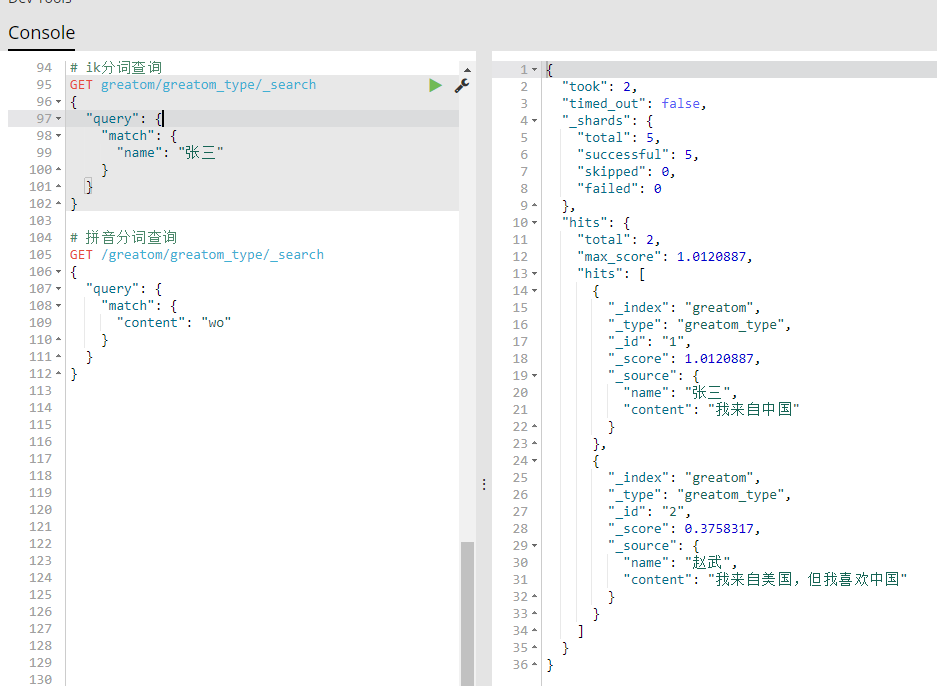
- 上图表示两种分词的查询格式,可以联想搜索出相关的所有数据,感觉比较智能了。
- 创建索引时可以自定义分词器配置,通过映射可以指定自定义的分词器,配置如下图:
结尾
- 通过对es分词的了解和使用,发现选择的两种分词模式已经满足自己项目的使用,还未进行更深入的了解,后续会继续了解底层及分词原理,如有瑕疵或更好的见解,希望可以交流学习。
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


