
1. 什么是强化学习
强化学习(reinforcement learning, RL)是近年来大家提的非常多的一个概念,那么,什么叫强化学习?
强化学习是机器学习的一个分支,和监督学习,非监督学习并列。
参考文献[1]中给出了定义:
Reinforcement learning is learning what to do ----how to map situations to actions ---- so as to maximize a numerical reward signal.
即强化学习是通过学习将环境状态转化为动作的策略,从而获得一个最大的回报。
举个栗子[2],在flappy bird游戏中,我们想设计一个获得高分的策略,但是却不清楚他的动力学模型等等。这是我们可以通过强化学习,让智能体自己进行游戏,如果撞到柱子,则给负回报,否则给0回报。(也可以给不撞柱子持续给1点回报,撞柱子不给回报)。通过不断的反馈,我们可以获得一只飞行技术高超的小鸟。
通过上面例子,我们可以看到强化学习的几个特性[3]:
- 没有label,只有奖励(reward)
- 奖励信号不一定是实时的,很有可能延后的。
- 当前的行为影响后续接收到的数据
- 时间(序列)是一个重要因素
2. 强化学习的建模
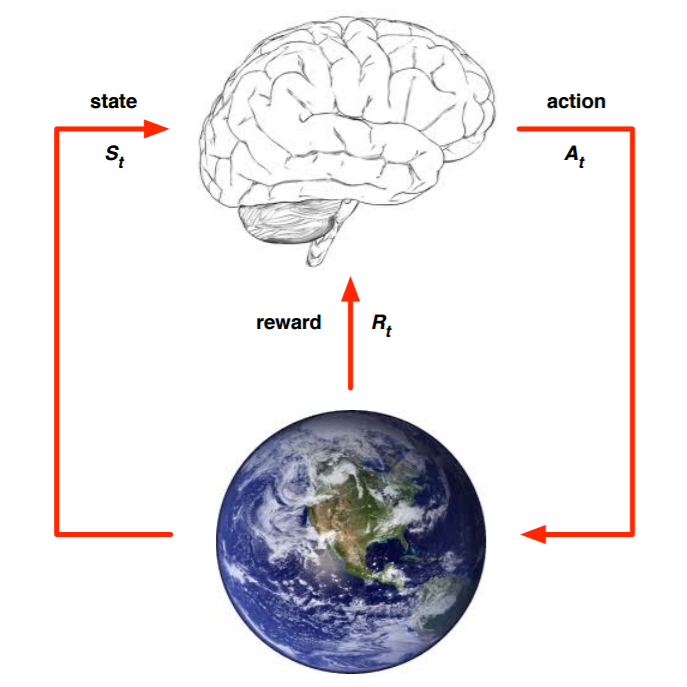
上面的大脑代表我们的智能体,智能体通过选择合适的动作(Action)(A_t),地球代表我们要研究的环境,它拥有自己的状态模型,智能体选择了合适的动作(A_t),环境的状态(S_t)发生改变,变为(S_{t+1}),同时获得我们采取动作(A_t)的延迟奖励(R_t),然后选择下一个合适的动作,环境状态继续改变……这就是强化学习的思路。
在这个强化学习的思路中,整理出如下要素[4]:
(1)环境的状态(S),(t)时刻环境的状态(S_t)是它的环境状态集中的某一个状态;
(2)智能体的动作(A),(t)时刻智能体采取的动作(A_t)是它的动作集中的某一个动作;
(3)环境的奖励(R),(t)时刻智能体在状态(S_t)采取的动作(A_t)对应的奖励(R_{t+1})会在(t+1)时刻得到;
除此之外,还有更多复杂的模型要素:
(4)智能体的策略(pi),它代表了智能体采取动作的依据,即智能体会依据策略(pi)选择动作。最常见的策略表达方式是一个条件概率分布(pi(a|s)),即在状态(s)时采取动作(a)的概率。即(pi(a|s)=P(A_t=a|S_t=s)),概率越大,动作越可能被选择;
(5)智能体在策略(pi)和状态(s)时,采取行动后的价值(v_pi(s))。价值一般是一个期望函数。虽然当前动作会对应一个延迟奖励(R_{t+1}),但是光看这个延迟奖励是不行的,因为当前的延迟奖励高,不代表到(t+1,t+2,dots)时刻的后续奖励也高, 比如下象棋,我们可以某个动作可以吃掉对方的车,这个延时奖励是很高,但是接着后面我们输棋了。此时吃车的动作奖励值高但是价值并不高。因此我们的价值要综合考虑当前的延时奖励和后续的延时奖励。 (v_pi(s))一般表达为:
[
v_pi(s)=E(R_{t+1}+gamma R_{t+2}+gamma^2R_{t+3}+dots|S_t=s)
]
(6)其中(gamma)作为奖励衰减因子,在([0,1])之间,如果为0,则是贪婪法,即价值只有当前延迟奖励决定。如果为1,则所有的后续状态奖励和当前奖励一视同仁。大多数时间选择一个0到1之间的数字
(7) 环境的状态转化模型,可以理解为一个状态概率机,它可以表示为一个概率模型,即在状态(s)下采取动作(a),转到下一个状态(s^{'})的概率,表示为(P_{ss{'}}^{a})
(8)探索率$epsilon (主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率)epsilon $不选择使当前轮迭代价值最大的动作,而选择其他的动作。
3.马尔科夫决策过程(Markov Decision Process ,MDP)
环境的状态转化模型,表示为一个概率模型(P_{ss{'}}^{a}),它可以表示为一个概率模型,即在状态(s)下采取动作(a),转到下一个状态(s^{'})的概率。在真实的环境转化中,转化到下一个状态(s{'})的概率既和上一个状态(s)有关,还和上一个状态,以及上上个状态有关。这样我们的环境转化模型非常非常非常复杂,复杂到难以建模。
因此,我们需要对强化学习的环境转化模型进行简化。简化的方法就是假设状态转化的马尔科夫性:转化到下一个状态(s{'})的概率仅和当前状态(s)有关,与之前状态无关,用公式表示就是:
[
P_{ss'}^{a}=E(S_{t+1}=s'|S_t=s,A_t=a)
]
同时对于第四个要素策略(pi),我们也进行了马尔科夫假设,即在状态(s)下采取动作(a)的概率仅和当前状态(s)有关,和其他要素无关:
[
pi(a|s)=P(A_t=a|S_t=s)
]
价值函数(v_pi(s))的马尔科夫假设:
[ v_pi(s)=E(G_t|S_t=s)=E_pi(R_{t+1}+gamma R_{t+2}+gamma^2R_{t+3}+dots|S_t=s) ]
(G_t)表示收获(return), 是一个MDP中从某一个状态(S_t)开始采样直到终止状态时所有奖励的有衰减的之和。
推导价值函数的递推关系,很容易得到以下公式:
[
v_pi(s)=E_pi(R_{t+1}+gamma v_pi(S_{t+1})|S_t=s)
]
上式一般称之为贝尔曼方程,它表示,一个状态的价值由该状态以及后续状态价值按一定的衰减比例联合组成。
4. 动作价值函数及贝尔曼方程
对于马尔科夫决策过程,我们发现它的价值函数(v_pi(s))没有考虑动作,仅仅代表了当前状态采取某种策略到最终步骤的价值,现在考虑采取的动作带来的影响:
[
q_pi{(s,a)}=E(G_t|S_t=s,A_t=a)=E_pi(R_{t+1}+gamma R_{t+2}+gamma^2R_{t+3}+dots|S_t=s,A_t=a)
]
动作价值函数(q_pi(s,a))的贝尔曼方程:
[
q_pi(s,a)=E_pi(R_{t+1}+gamma q_pi(S_{t+1},A_{t+1})|S_t=s,A_t=a)
]
按照定义,很容易得到动作价值函数(q_pi(s,a))和状态价值函数(v_pi(s))的关系:
[
v_pi(s)=sum_{ain A}pi(a|s)q_pi(s,a)
]
也就是说,状态价值函数是所有动作价值函数基于策略(pi)的期望。
同时,利用贝尔曼方程,我们利用状态价值函数(v_pi(s))表示动作价值函数(q_pi(s,a)),即:
[
q_pi(s,a)=E_pi(R_{t+1}+gamma q_pi(S_{t+1},A_{t+1})|S_t=s,A_t=a)
]
[ =E_pi(R_{t+1}|S_t=s,A_t=a)+gamma E_pi(q_pi(S_{t+1},A_{t+1})|S_t=s,A_t=a) ]
[ =R_s^a+gamma sum_{s'}P_{ss'}^{a}sum_{a'}pi(a'|s')q_pi(s',a') ]
[ =R_s^a+gamma sum_{s'}P_{ss'}^av_pi(s') ]
公式5和公式12总结起来,我们可以得到下面两式:
[
v_pi(s)=sum_{a in A}pi(a|s)(R_s^a+gamma sum_{s'}P_{ss'}^av_pi(s'))
]
[ q_pi(s,a)=R_s^a+gamma sum_{s'}P_{ss'}^av_pi(s') ]
5. 最优价值函数
解决强化学习问题意味着要寻找一个最优的策略让个体在与环境交互过程中获得始终比其它策略都要多的收获,这个最优策略我们可以用 (pi^*)表示。一旦找到这个最优策略 (pi^*),那么我们就解决了这个强化学习问题。一般来说,比较难去找到一个最优策略,但是可以通过比较若干不同策略的优劣来确定一个较好的策略,也就是局部最优解。
如何比较策略优劣?一般通过对应的价值函数进行比较:
[
v_{*}(s)=max _{pi} v_{pi}(s)=max_pi sum_api(a | s) q_{pi}(s, a)=max _{a} q_{*}(s, a)
]
或者最优化动作价值函数:
[
q_{*}(s, a)=max _{pi} q_{pi}(s, a)
]
[ =R_s^a+gamma max_pi v_pi(s') ]
状态价值函数(v)描述了一个状态的长期最优化价值,即在这个状态下考虑到所有可能发生的后续动作,并且都挑选最优动作执行的情况下,这个状态的价值。
动作价值函数(q)描述了处于一个状态,并且执行了某个动作后,所带来的长期最有价值。即在这个状态下执行某一特定动作后,考虑再之后所有可能处于的状态下总是选取最优动作来执行所带来的长期价值。
对于最优的策略,基于动作价值函数我们可以定义为:
[
pi_{*}(a | s)=left{begin{array}{ll}{1} & {text { if } a=arg max _{a in A} q_{*}(s, a)} \ {0} & {text { else }}end{array}right.
]
只要我们找到了最大的状态价值函数或者动作价值函数,那么对应的策略(pi^*)就是我们强化学习问题的解。
6.强化学习的实例
关于强化学习的实例,具体可参见[4]和[5],很强,很棒。
7.思考
在很多人的文章中,将强化学习训练的模型被称之为“智能体”,为什么呢?因为它和我们人类学习的思路很相似:
模型在没有样本的情况下,主动去探索,然后从环境中获取一个(延迟)反馈,然后通过反馈进行反思,优化策略/动作,最终学习成为一个强大的智能体。
当然,强化学习还拥有一些缺点[6]:
样本利用率低,需要用大量样本进行训练。并且有时训练速度还很慢(远远低于人类)。
奖励函数难以设计。大部分的奖励函数都是0,过于稀疏。
容易陷入局部最优。文献[6]中例子指出,一个以速度为奖励函数的马,可以四角朝天的“奔跑”。
对环境的过拟合。往往没办法一个模型用于多个环境。
不稳定性。 不稳定对于一个模型是灾难性的。一个超参数的变化可能引起模型的崩溃。
当然,我们不能一味肯定,也不能一味否定,强化学习在AUTOML,AlphaGO的成功应用也说明了强化学习尽管会有很多困难,但是也是具有一个具有探索性、启发性的方向。
[1] R.Sutton et al. Reinforcement learning: An introduction , 1998
[2] https://www.cnblogs.com/jinxulin/p/3511298.html
[3] https://zhuanlan.zhihu.com/p/28084904
[4] https://www.cnblogs.com/pinard/p/9385570.html
[5] https://www.cnblogs.com/pinard/p/9426283.html
[6] https://www.alexirpan.com/2018/02/14/rl-hard.html
本文由飞剑客原创,如需转载,请联系私信联系知乎:@AndyChanCD
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


