
Popularity Bias in Dynamic Recommendation
Authors: Ziwei Zhu, Yun He, Xing Zhao, James Caverlee
KDD'21 Texas A&M University
论文链接:http://people.tamu.edu/~zhuziwei/pubs/Ziwei_KDD_2021.pdf
本文链接:https://www.cnblogs.com/zihaojun/p/15721359.html
0. 总结
这篇文章通过模拟动态推荐实验,研究了受众人数不平衡、模型偏差、位置偏差、闭环反馈四种因素对推荐系统中流行度偏差的影响,认为受众人数不平衡和模型偏差是造成流行度偏差的主要因素。并提出了两种方法来去除动态场景下的popularity bias。
模拟实验设计比较新颖,但去偏方法稍显粗糙,缺乏真实数据集的实验验证。
1. 问题背景
流行度偏差是推荐系统中长期存在的一种问题,它是指推荐系统更倾向于推荐流行的物品,导致推荐结果中流行物品的占比过高,产生马太效应,不利于推荐结果的个性化和多样化,同时损害用户体验和商家的利益。
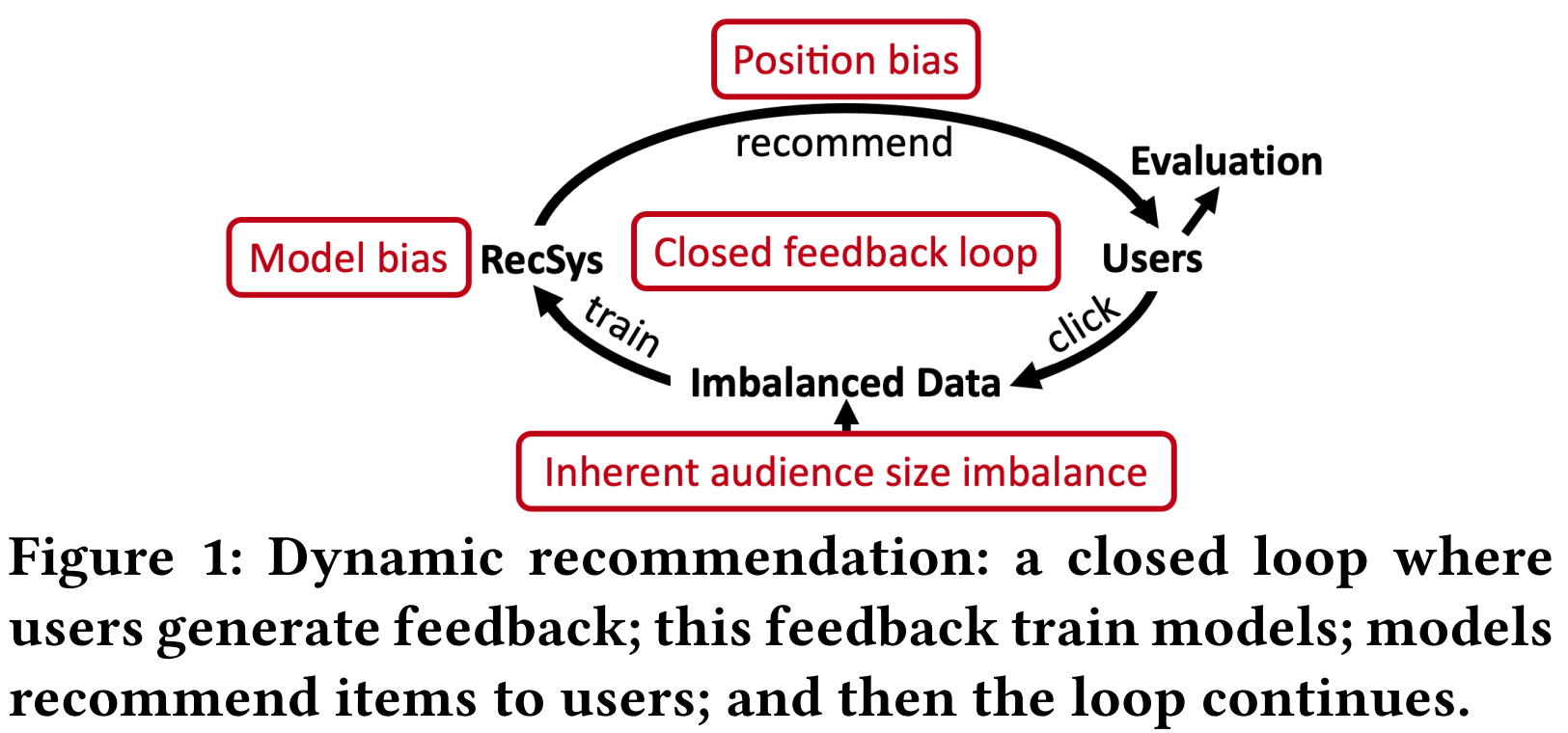
现有关于流行度偏差的工作都将物品的流行度视为静态的,但是物品的流行度是会随着时间发生很大变化的。尤其是在推荐这种闭环场景下,推荐结果会影响用户点击,而用户点击又会作为训练数据影响推荐模型。如图一所示,在这个循环过程中,有以下四个因素影响物品流行度:
- 潜在的用户群体规模:即使推荐结果是完全没有流行度偏差的,用户的点击也肯定不是均匀的,有些物品就是更受欢迎一些,这是物品本身的质量等差异导致的。
- 模型偏差:推荐系统本身会放大这种流行度差异,即推荐结果中,流行物品的比例比训练数据中更高。
- 位置偏差:推荐结果的展示顺序也会影响物品流行度,排在前面的更容易被点击到。(这个仿佛也是推荐系统本身的行为,感觉可以归为模型偏差?)
- 闭环反馈效应:由于用户的点击数据又会作为训练数据参与模型训练,这种流行度差异会不断被放大。
2. 本文贡献点
- 通过模拟实验,研究了流行度的演变情况,发现潜在用户群体数量和模型偏差是导致流行度变化的最重要因素。
- 提出了解决动态流行度偏差的方法,包括将静态流行度偏差方法应用到动态场景和一个模型无关的伪正样本纠正算法,可以被整合进其他debias方法,进一步提高性能。
- 实验证明了本文提出方法的有效性。
3. 问题定义
3.1 动态推荐
动态推荐是指,在一个推荐平台上,每当一个用户登陆上来,都会给出个性化的长度为K的推荐列表,用户会从中选择自己喜欢的物品进行交互。每当收集L个用户的交互之后,推荐系统就会重新训练,以利用最新的交互数据做出更好的推荐结果。
3.2 流行度偏差
通常,衡量推荐结果的流行度偏差是基于推荐次数的,但本文采用流行度-机会偏差的定义,即衡量不同流行度物品得到的点击机会是否平等。这种定义会考虑物品本身质量不同带来的用户潜在群体规模不同,这样不会像传统的定义一样,强行把不同物品的推荐次数拉平,不考虑用户规模不同。
本文用True positive rate(TPR)和audience size之间的基尼系数来衡量推荐系统的popularity bias,其中(TPR_i = C_i^t/A_i),(C_i^t)表示物品i在t时刻被点击的次数,(A_i)表示物品i的潜在用户群体规模。
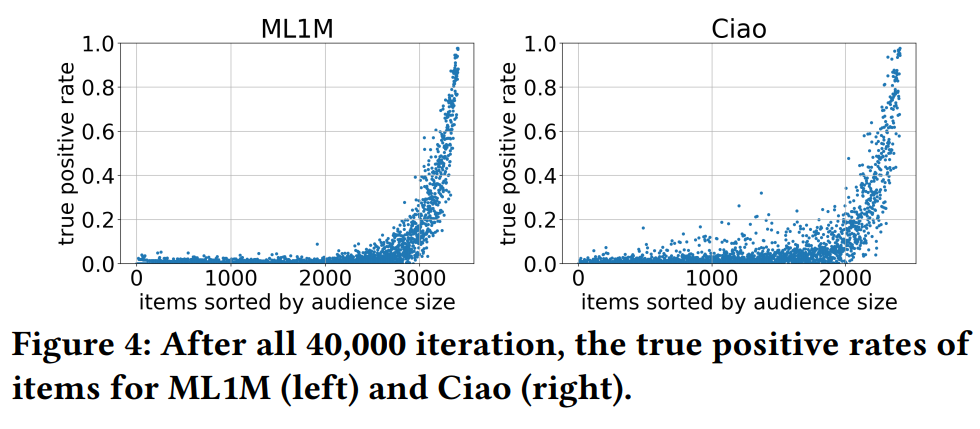
这个TPR可以理解为,喜欢每个物品的用户,被推荐到这个物品的几率是否是一致的。从后文中Figure 4可以看出,喜欢流行物品的用户基本都得到了推荐,而喜欢小众物品的用户很少会得到推荐。也就是说,流行物品店TPR很高,冷门物品的TPR很低,这是不公平的,喜欢小众物品的用户更难获得准确的推荐,商家也难以获得公平的曝光。
基尼系数的取值范围在-1到1之间,越接近1,表示用户规模大的物品获得的点击机会越多,流行度偏差越大。如果基尼系数为0,则表示基本所有物品获得的被点击机会是比较均匀的。
4. 实验分析
为了验证四种因素对流行度偏差的影响,本文设计了仿真实验,探究哪种因素影响比较大,有助于针对性地消除流行度偏差。
4.1 实验设计
在线进行重复实验是不太现实的,本文参照之前的工作,对ML1M和ciao两个数据集的打分矩阵进行了补全,这样,每个物品就有一个明确的潜在受众群体。通过计算潜在受众群体人数的基尼系数,可以看出item之间,受众人数差异还是比较大的(分别达到了0.64和0.44)。
为了研究受众人数差异程度对流行度偏差的影响,本文通过改变生成机制,得到了四种差异程度不同的补全矩阵。
仿真实验设计:
- 通过推荐模型,给当前用户(u_t)推荐K个物品
- 用户在其中点击自己感兴趣的物品,交互记录反馈给系统
- 重复1-2 L步,然后使用点击数据重新训练推荐模型。
- 重复1-3 ,直到推荐T次
实验中,取(K = 20, L = 50, T = 40,000)。负采样是从推荐但未点击的物品中采样的。
为了模拟position bias带来的影响,使用一种降权方法,使得排在前面的被点击的概率较大。
4.2 流行度偏差的变化情况
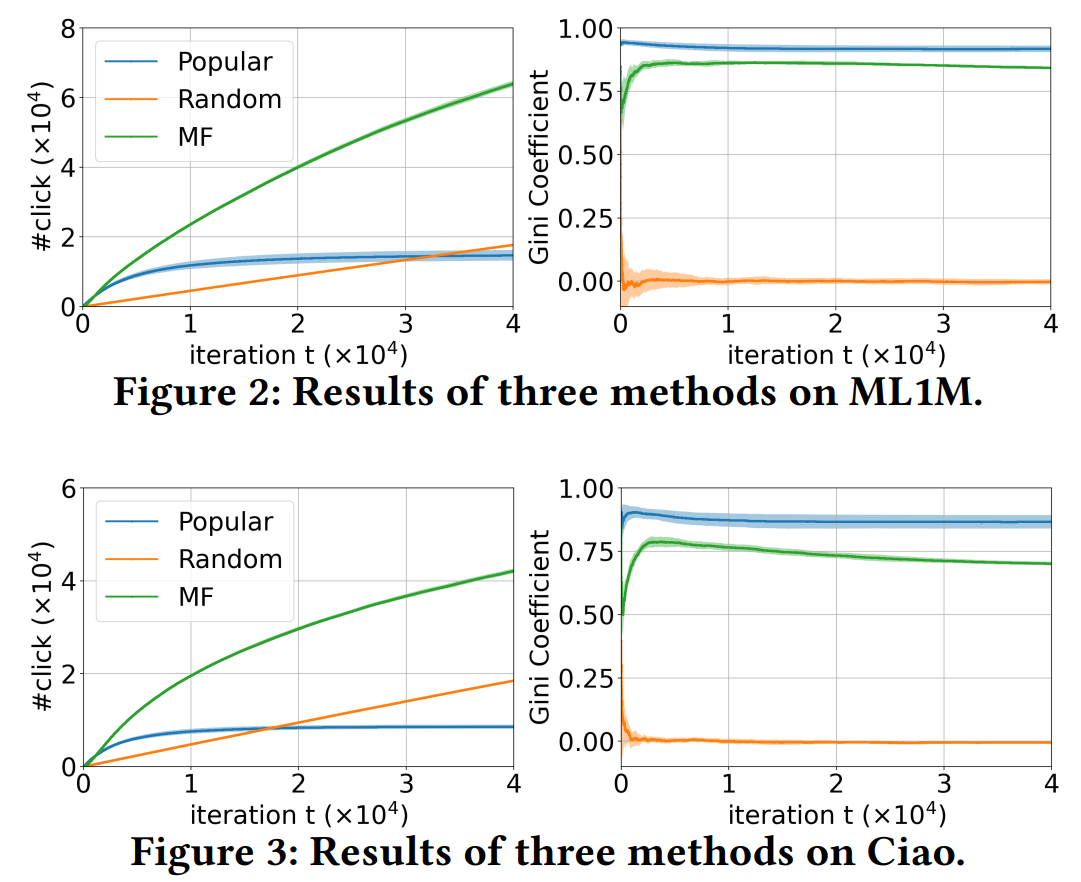
使用MF、popular、random三种策略给出推荐结果,并统计累积点击数量和点击机会的基尼系数。点击数量可以反映推荐的准确度,基尼系数可以反映系统的流行度偏差。
- 可以看出,MF的推荐精度最高,Random得到的点击数量会线性增长,而popular策略产生的点击很快便达到瓶颈,不再提升。
- 基尼系数:
- popular的基尼系数最高,接近1。这是因为只推荐了最流行的物品,不流行的物品几乎没有被点击的机会。
- MF的基尼系数也迅速上升到了很高的水平,比较出乎意料。这说明设计方法来消除推荐系统中的流行度偏差是非常重要的。
- Random的基尼系数基本为0,对流行物品和不流行物品平等对待,大家的机会差不多。
将不同物品的TPR可视化,可以看出,TPR呈现长尾分布,大多数物品很少有机会可以被推荐给喜欢它的用户。
4.3 四种因素对流行度偏差的影响
4.3.1 position bias
通过在MF的训练过程中使用IPS去偏算法,去除position bias对推荐模型带来的影响,实验结果如下:
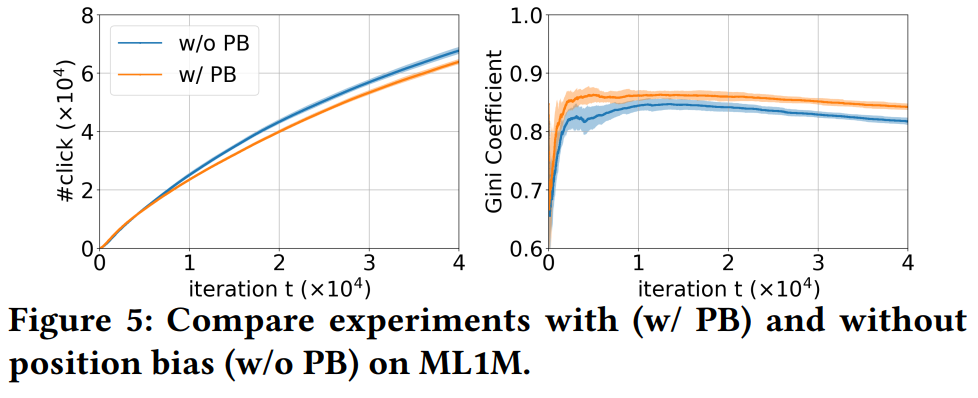
去除position bias之后(蓝色线),点击数量提高了,基尼系数降低了,说明position bias的存在会影响推荐精度,也会加强popularity bias。不过基尼系数只下降了一点点,说明position bias不是造成popularity bias的主要因素。
4.3.2 Closed Feedback Loop(CFL)
反馈闭环是指,当前推荐系统的推荐结果会影响用户点击行为,进而影响未来推荐系统的训练。
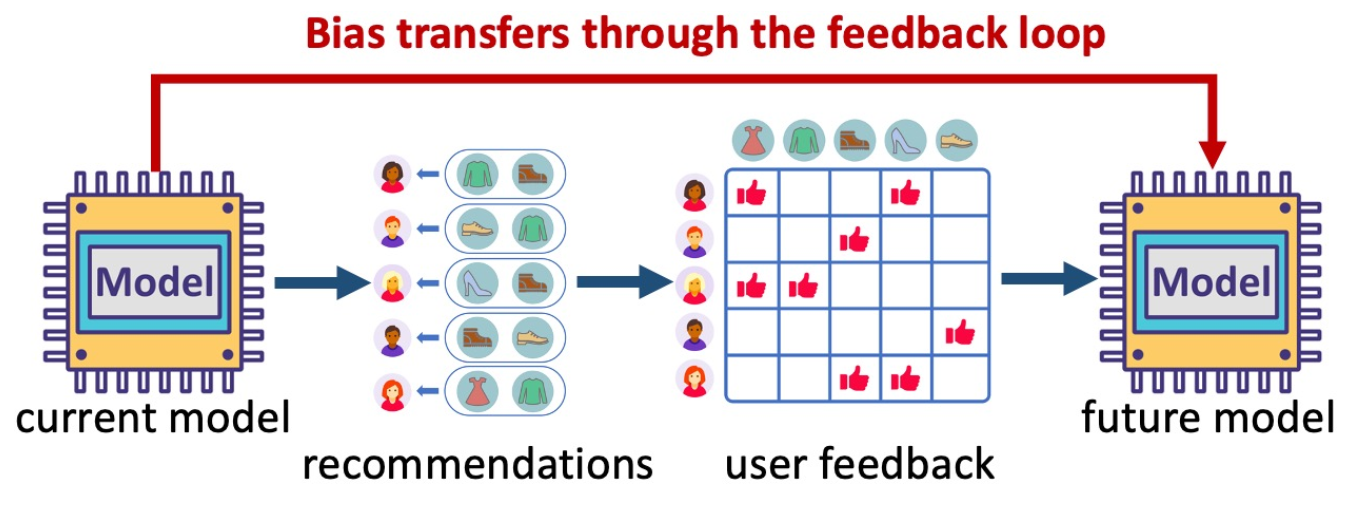
为了打破这个闭环,我们不能用推荐系统给出的推荐列表产生的点击数据作为训练数据,而应该另外给一组随机曝光,并使用随机曝光产生的用户点击数据来训练推荐系统。
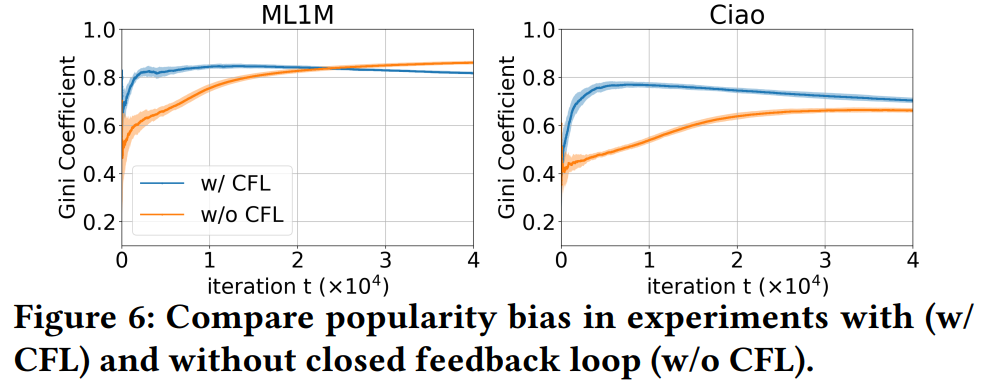
结果表明,去除CFL之后,基尼系数上升速度明显变慢,但最终还是会逼近甚至超过有闭环反馈的系统。因此,闭环反馈也会带来popularity bias,但也不是主要因素。
4.3.3 Model Bias
在Figure 6中,去除了position bias和CFL之后,系统中的popularity bias仍然很严重,这说明,剩下的两个因素,即Model Bias和inherent audience size才是产生popularity bias的主要因素。
为了研究不同实验设置对Model Bias的影响,这部分设计了两组静态实验:
- 第一组,生成了五种不同的半合成补全矩阵(I_1, I_2, I_3, I_4, I_5),这五个矩阵中,物品的潜在受众群体不平衡性不同,不同物品的受众人数的基尼系数分别为0.37,0.45,0.51,0.57,0.64。
- 第一组的实验结果见Figure 7左图。随着受众人数基尼系数上升,推荐结果的机会基尼系数也会上升,而且机会基尼系数远高于受众人数的基尼系数。这说明模型会放大物品直接的不平衡性,带来严重的popularity bias。
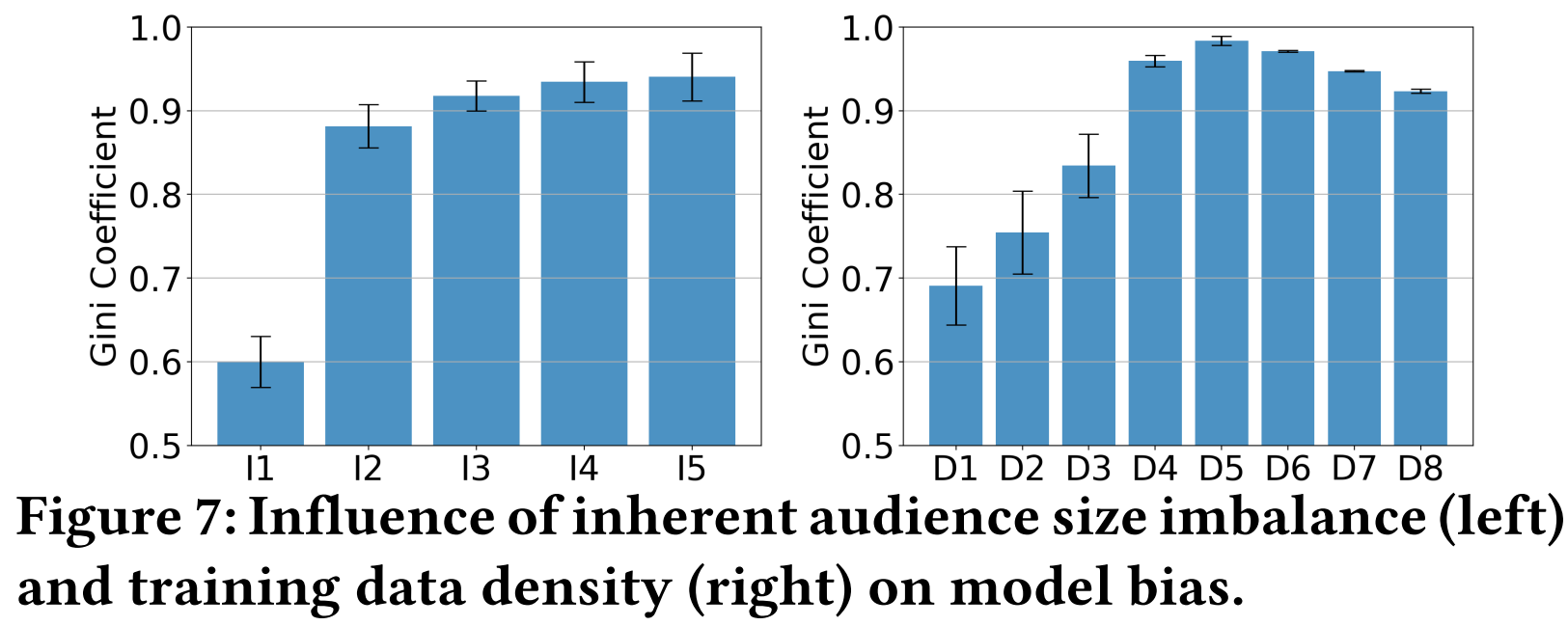
- 第二组,生成8组不同规模的训练数据,观测模型推荐结果的popularity bias。
- 结果如Figure 7右图所示,可见随着训练数据量的增大,模型中的流行度偏差先增大,后减小。这可能是因为,随着数据规模的增大,模型中的bias和以及预测用户兴趣的能力都在增强。当规模超过一个阈值时,预测用户兴趣的能力超过了模型bias增大的速度,使得系统popularity bias可以降低一点。
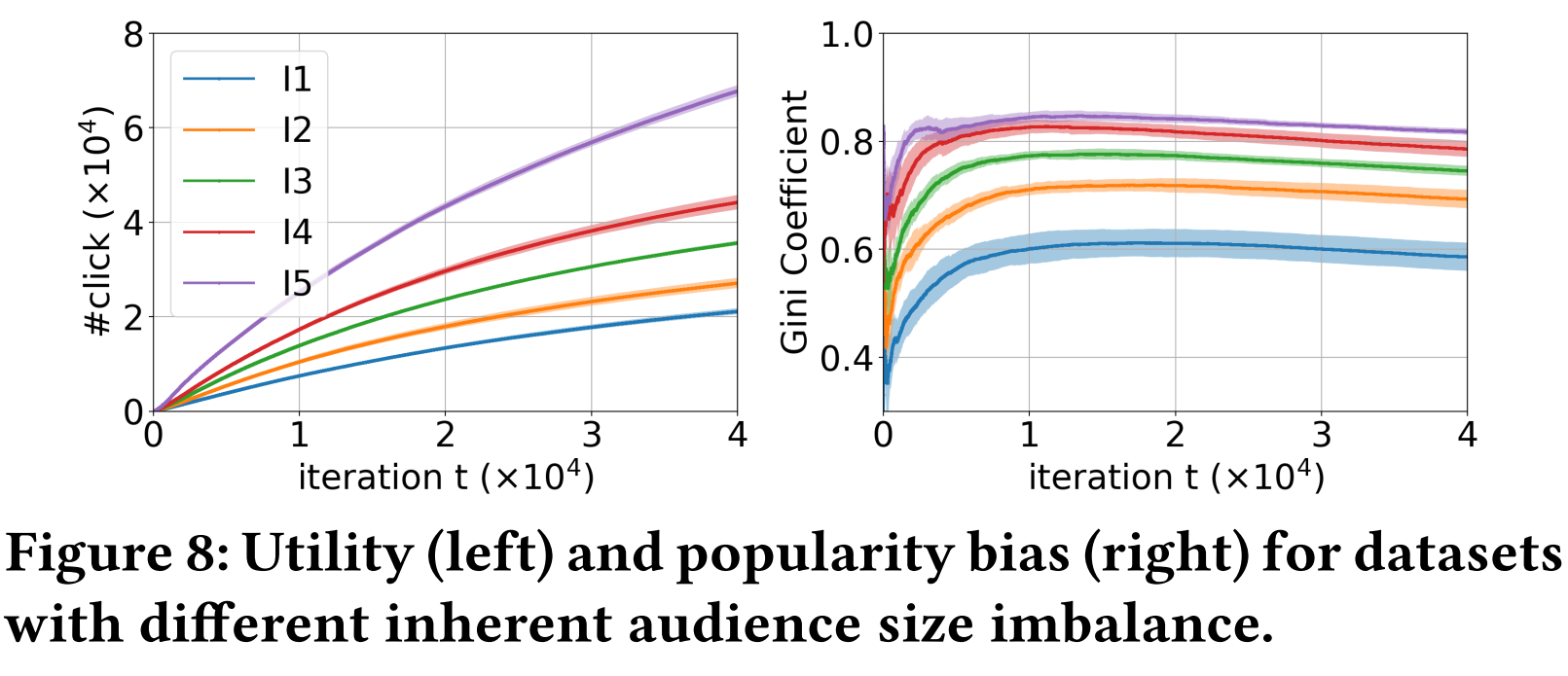
4.3.4 Inherent Audience Size Imbalance
使用4.3.3所述的五种不同Imbalance程度的半合成ground truth,观察随着动态推荐过程,不同程度的Imbalance对推荐精度和系统bias的影响。
Figure 8所示的结果表明,更高的Imbalance会使得推荐模型有更高的推荐准确率,同时,推荐系统的popularity bias也越严重。这是因为Imbalance越强,推荐越简单——只推流行的物品就可以收获很多点击。
4.3.5 总结
model bias和inherent audience size imbalance是产生popularity bias的最重要的两个因素,另外两个因素也会加强popularity bias,但影响不是很大。
另外,作者还发现,训练数据越稠密,audience size imbalance越严重,则model bias就越严重。
4.4 两种负采样策略的比较
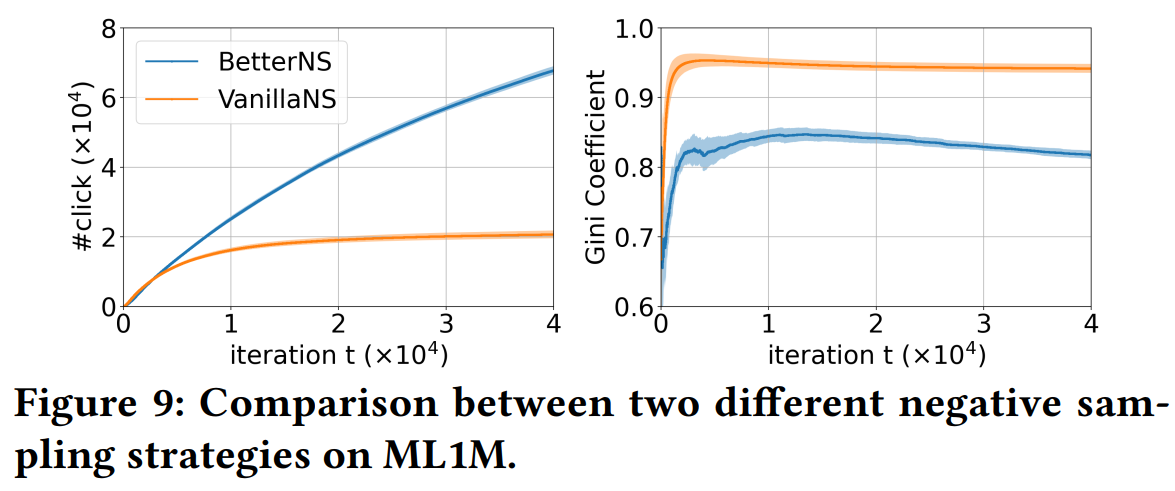
本文的负采样是在曝光未点击的数据上进行的,这种负采样是不太常用的,一方面是缺乏曝光数据,另一方面,曝光未点击不一定能说明用户就不喜欢,可能是因为用户想看,但突然有事没来得及,或者同时有好几个想看的,没来得及都看完。而在仿真实验中,这些情况都不存在了,因此可以放心使用曝光未点击数据作为负样本。
这部分,作者对随机负采样(VanillaNS)和上述负采样方法(BetterNS)做了比较。结果显示,BetterNS策略得到的点击数更高,基尼指数明显更低。
这是因为,BetterNS策略下,曝光未点击的物品会作为负样本,而这些负样本中,流行的物品占比会比较高。也就是说,流行的物品更容易作为负样本,因此可以起到去除一些popularity bias的效果。也正是因为如此:
- 在MF的训练过程中,基尼系数在达到峰值之后缓慢下降。
- Figure 6中,ML1M上without feedback loop的方法的popularity bias最终超过了with feedback loop的方法。
- w/o CFL的方法使用随机推荐策略产生的交互数据进行训练,在这种数据上负采样起不到抵消popularity bias的效果,因此只剩下随着数据规模增大,popularity bias上升(后下降,见Figure 7 右图)的效应。
5. 去偏方法
5.1 动态调整debias强度
一开始,模型没训练的时候,是没有bias的。随着数据的增多,模型带来的bias越来越大。因此,在动态推荐场景下,应该逐步增加debias的强度。
- 静态的debias方法一般都有这种超参数
5.2 利用曝光未点击数据
如果一个物品i之前被推荐给了用户u,但是没有被点击,则应该降低后面再次被推荐的概率。
6. 实验
实验也是采用前面一直在使用的仿真动态实验设置,实验验证了提出的两种方法加到现有的debias方法之后,可以提高推荐精度,降低系统中的popularity bias。
Weakness
以下是个人见解,如有不妥之处还请不吝指出,欢迎大家一起讨论。
- 4.3.3 应该分析model bias对系统中popularity bias的影响,但是有点跑题了,变成了分析什么因素会影响model bias。这部分应该分析model是如何放大了audience size本身带来的bias,或者如何放大了训练数据中的popularity bias。
- 4.3.3 可以考虑用没有audience size imbalance的模拟用户来做一下实验,这样就可以去除audience size imbalance的影响,只看model如何产生popularity bias。
- 4.3.1 去除系统中的position bias,用的是在模型训练时加IPS的方法。既然已经是模拟实验了,完全可以把模拟实验中,产生position bias的机制去掉,这样可以完全去除position bias带来的影响。加IPS毕竟是间接的方法,不一定去除的干净。
- 5.1提出的方法在实际场景下是不怎么适用的,因为训练数据虽然在不断增加,但是初始的数据量就很大,不存在一点点累积起来的情况。
- 5.2提出的方法在实际的曝光未点击数据上不一定有这样的效果,即本文缺乏真实数据集的实验,都是在用模拟实验验证方法,而模拟场景和真实场景差别较大。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


