
论文地址:《Very Deep Convolutional Networks for Large-Scale Image Recognition》
思维导图:https://mubu.com/explore/5JnjDt1vIng
一、背景
LSVRC:大规模图像识别挑战赛
ImageNet Large Scale Visual Recognition Challenge 是李飞飞等人于2010年创办的图像识别挑战赛,自2010起连续举办8年,极大地推动计算机视觉发展。比赛项目涵盖:图像分类(Classification)、目标定位(Object localization)、目标检测(Object detection)、视频目标检测(Object detection from video)、场景分类(Scene classification)、场景解析(Scene parsing)。
VGG Net由牛津大学的视觉几何组(Visual Geometry Group)参加2014年ILSVRC提出的网络模型,它主要的贡献是展示了卷积神经网络的深度(depth)是算法优良性能的关键部分。
二、Abstract
Q1:做了什么?
研究了“卷积网络的深度”在大规模的图像识别环境下对准确性的影响(即神经网络的深度与其性能之间的关系)。
Q2:怎么做的?
使用一个非常小的卷积核((3times3))对网络深度进行评估,评估发现将网络深度加至16层-19层,性能有了显著提升。
Q3:做得怎么样?
在ImageNet Challenge 2014竞赛中,定位赛道获得第一名,分类赛道获得第二名。
三、Architecture
论文提出了多种规模的网络架构(不同规模深度不尽相同),下图为其中性能表现良好的网络架构之一:VGG16结构图。
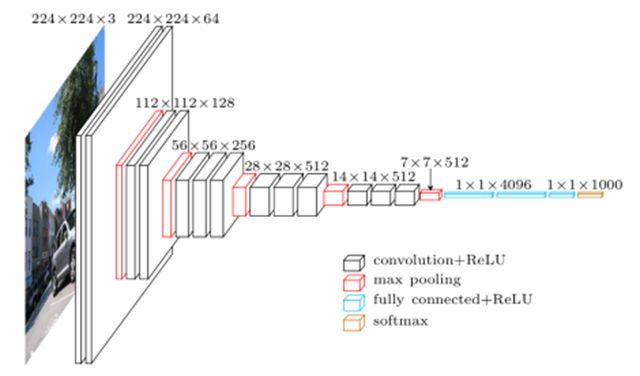
1、输入
- 规格:3@224x224(3个通道,宽高像素均为224);
- 唯一的预处理操作:计算出3个通道的平均值,在每个像素上减去平均值(处理后迭代更少,收敛更快);
2、卷积
- 大部分网络架构使用非常小的3x3卷积核贯穿整个网络;
- 部分网络架构除了3x3卷积核之外还使用了1x1卷积核;
- 卷积层步长(stride)=1,3x3卷积核的填充(padding)=1;
- 所有隐藏卷积层都配备了ReLU非线性激活。
3、池化
- 整个网络架构的池化总共由5个“MAX池化层”实现;
- 池化操作在一系列卷积操作之后执行;
- 池化窗口为2x2,步长=2。
4、分类器
所有卷积操作之后跟有3个全连接层(FC层):
- 前2个FC层:均为4096通道;
- 最后1个FC层:1000个通道;
- 全连接层之后是SoftMax分类器。
四、Dicussion
所有的ConvNet配置如图所示,VGG结构全部都采用较小的卷积核(3x3,部分1x1):
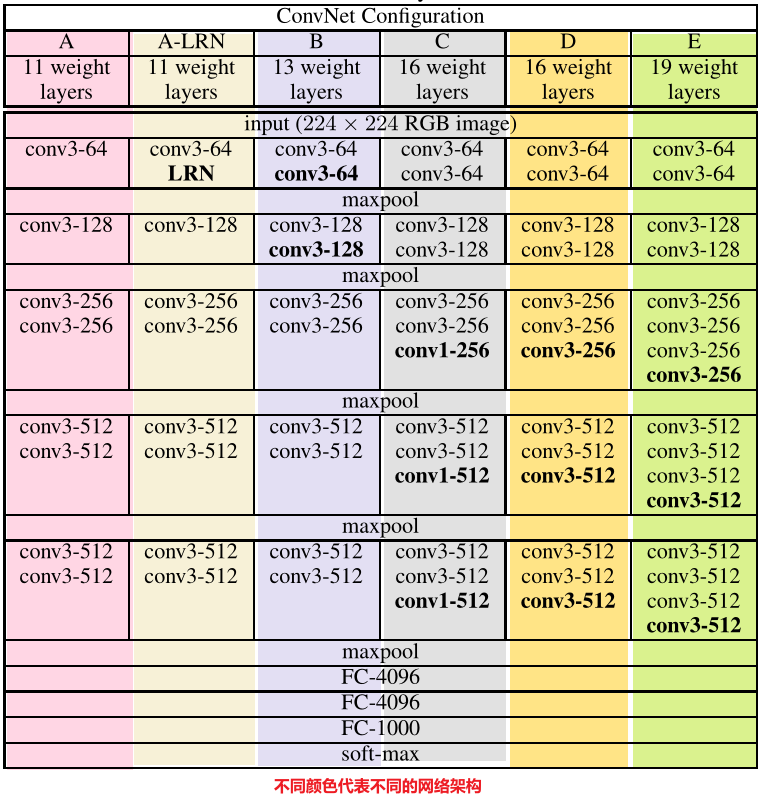
1、3x3卷积核的作用(优势)
两个3×3的卷积层串联相当于1个5×5的卷积层(二者具有等效感受野5x5),3个串联的3×3卷积层串联的效果相当于一个7×7的卷积层;
下图展示了为什么“两个3x3卷积层”与“单个5x5卷积层”具有等效的5x5的感受野。
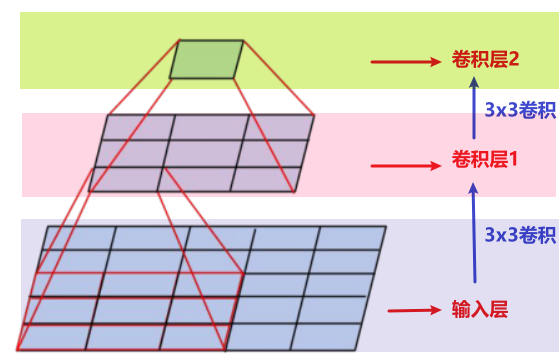
1)作用1:减少网络层参数
- 对于两个3x3卷积核,所用的参数总量为(2times3^2times{channels})(假设通过padding填充保证卷积层输入输出通道数不变);
- 对于单个5x5卷积核,参数量为(5^2times{channels});
- 参数量减少了((1-frac{2times3^2times{channels}}{5^2times{channels}})times100%=28%)。
2)作用2:增加更多的非线性变换
2个3x3卷积层拥有比1个5x5卷积层更多的非线性变换(前者可以使用两次ReLU激活函数,而后者只有一次),使得卷积神经网络对特征的学习能力更强。
2、1x1卷积核的作用
1)作用1:降低运算量
不影响输入输出的维度情况下(即图片宽高尺寸不变),降低了大量运算,同时改变了维度(通道数);
2)作用2:提高非线性
卷积之后再紧跟ReLU进行非线性处理,提高决策函数的非线性。
五、Classification Framework
1、训练
1)参数设置
- 使用了mini-batch的梯度下降法(带有冲量),batch_size设为256,冲量设为0.9;
- 前两个FC层使用了dropout(失活概率为0.5),用来缓解过拟合;
- 训练通过权重衰减(L2惩罚因子设定为(5times{10}^{-4}))进行正则化;
- 学习率初始化为0.01
- 当验证集准确率稳定时,学习率减少为原来(frac{1}{10});
- 整个训练过程,学习率总共降低3次,学习在37万次迭代后停止(74个epochs)。
2)预训练
- 先训练较浅的网络A,待A性能收敛之后,将A的网络权重保存下来;
- 再复用A网络的权重来初始化后面的几个复杂模型
- 只对“前四个卷积层”、“后三层全连接层”复用A的网络权重,其它的中间层都是随机初始化;
- 随机初始化,均值是0,方差是0.01,bias是0。
- 只对“前四个卷积层”、“后三层全连接层”复用A的网络权重,其它的中间层都是随机初始化;
3)多尺度训练
Q1:什么是多尺度训练(Multi-scale)?
详见:https://www.cnblogs.com/xxxxxxxxx/p/11629657.html
通俗点讲,就是将一张图片先进行等比例缩放到不同尺寸(实现1张图片变多张图片),再在缩放后的图片中随机裁剪出指定尺寸区域得到更多的图像。
就这样,实现了训练集的数据增强。
Q2:作用是什么?
数据增强,有利于预防过拟合。
Q3:步骤是什么?
- 步骤1:将原始图像缩放到不同尺寸S;
- Q:S设为多大合适呢?(两种解决方法A1、A2)
- S过小,裁剪到224x224的时候,就相当于几乎覆盖了整个图片,这样对原始图片进行不同的随机裁剪得到的图片就基本上没差别,就失去了增加数据集的意义;
- S过大,,裁剪到的图片只含有目标的一小部分,也不是很好。
- A1:单尺度训练(将S设为一个固定值)
- 论文评估了S=256和S=384两种单尺度模型;
- A2:多尺度训练(将S设为一个区间([S_{min}, S_{max}]))
- 论文随机从[256,512]的区间范围内进行抽样,这样原始图片尺寸不一,有利于训练,这个方法叫做尺度抖动(scale jittering),有利于训练集增强。
- Q:S设为多大合适呢?(两种解决方法A1、A2)
- 步骤2:从缩放后的图片随机裁剪224x224区域的图片;
- 步骤3:对裁剪后的图片进行水平翻转和随机RGB色差调整(改变训练图像中 RGB 通道的强度);
2、测试
测试阶段与训练阶段主要有两点不同:
- 对于测试集同样采用Multi-scale,将图像缩放到尺寸Q,但是Q可以≠训练尺度S;
- 将“FC全连接层”转换为“等效卷积层”
- 第一个FC层转为“7x7卷积层”;后两个FC层均转为“1x1卷积层”;
- 二者为什么可以进行转换?
- 转换的作用是什么?
- ①可以实现与FC层同样的效果(即可以获得与FC层相同的输入输出);
- ②去除了FC层必须要求“输入图像尺寸固定”的限制条件(详见:https://blog.csdn.net/qq_31347869/article/details/89484343
六、Classification Experiments
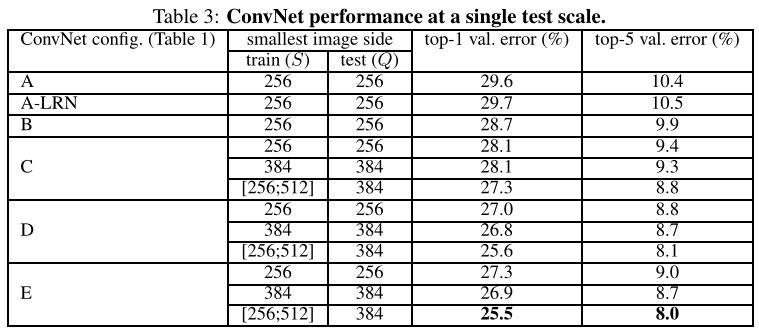
1、Single Scale Evaluation
- 若S采用单尺度,设Q=S;若S采用多尺度,设(Q=0.5(S_{min}+S_{max}));
- 通过“A-LRN”证明,网络中加入LRN没什么用;
- 通过比较A-E的“top-1 val.error”和“top-5 val.error”发现,网络深度越深,训练性能越好,且深度达19层时,性能趋于饱和;
- 通过比较D和C,证明3x3卷积效果优于1x1卷积;
- 通过将“B”和“带有5x5卷积的浅层网络”,发现两个3x3卷积效果优于单个5x5卷积(即使二者具有等效的感受野);
- 通过比较单尺度S和多尺度S,发现尺度抖动有利于训练集数据增强。
2、Multi-Scale Evaluation
- 保持S为单尺度((S=256 or S=384)),查看多尺度Q的性能((Q={S-32, S, S+32}));
- 令S为多尺度((Sin[S_{min}, S_{max}])),查看多尺度Q的性能((Q={ S_{min}, 0.5(S_{min}+S_{max}, S_{max}) }));
- 证明测试时的尺度抖动导致了更好的性能。
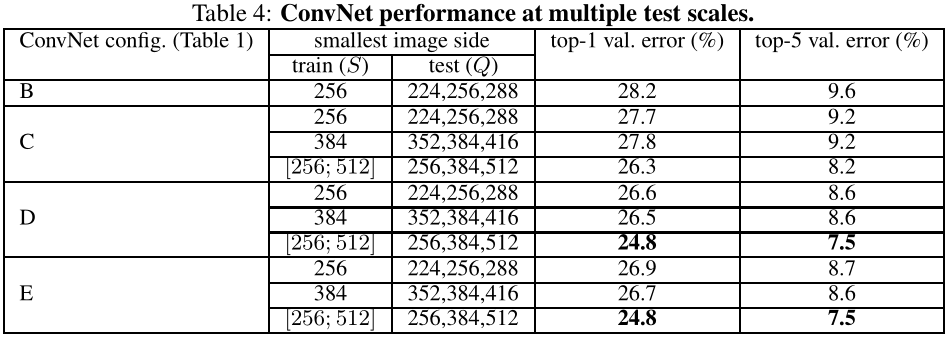
3、Multi-Crop Evaluation
- 将“稠密(ConvNet)(即未进行多裁剪)评估”与“多裁剪图像评估”进行比较;
- 通过平均其soft-max输出来评估两种评估技术的互补性;
- 证明了使用多裁剪图像表现比密集评估略好,而且这两种方法确实是互补的(因为它们的组合优于其中的每一种)。
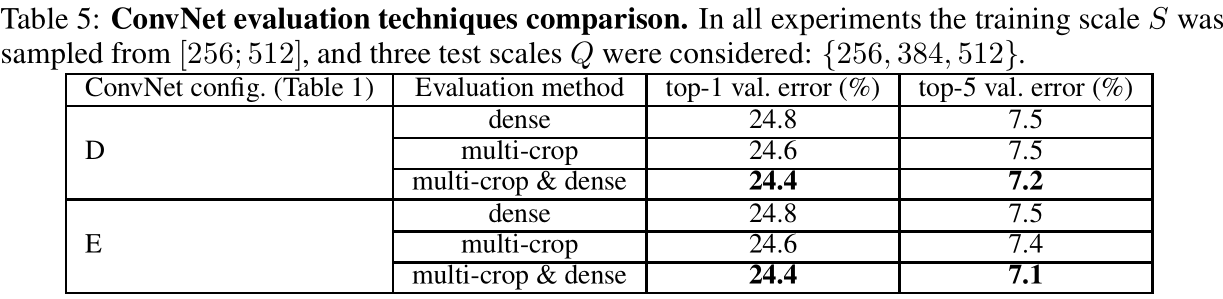
4、ConvNet Fusion
- 查看多个卷积网络融合结果;
- ILSVRC提交的是单规模网络;post-提交的是多规模网络;
- 表现最好的多尺度模型(配置D和E)的组合,它使用密集评估将测试误差降低到7.0%,使用密集评估和多裁剪图像评估将测试误差降低到6.8%。

七、我的总结
VGGNet网络特点:
- 层数深(VGG拥有5段卷积,每段卷积内包含2-3个卷积层),同时每段尾部配有最大池化层,适用于大型数据集;
- 网络简洁,使用了同样大小的卷积核尺寸(3x3)和最大池化尺寸(2x2)贯穿整个网络架构;
- 采用“几个小滤波器(3x3)卷积层的串联组合”替代“一个大滤波器(5x5或7x7)卷积层”,效果更好;
- 训练和测试阶段都对数据集进行了Multi-scale将图片缩放并采样,实现了数据增强;
- 测试阶段将全连接层转换为等效卷积层,去除了FC层对输入图像尺寸的限制;
- 采用多GPU并行训练,每个GPU处理部分数据。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


