
——书接上文
Training
半监督网络的训练分两步进行:a)对标记数据独立训练学生模块,由教师模块生成伪标签;b)结合两个模块的训练,得到最终的预测结果。
伪标签框架



实验
数据集:
TableBank是文档分析领域中用于表识别问题的第二大数据集。该数据集有417,000个通过arXiv数据库爬虫过程注释。该数据集具有来自三类文档图像的表格:LaTeX图像(253,817)、Word图像(163,417),以及两者的组合(417,234)。它还包括一个用于识别表格的结构的数据集。在论文的实验中,只使用进行表检测的数据。
PubLayNet是一个大型公共数据集,训练集中有335,703张图像,验证集中有11,240张图像,测试集中有11,405张图像。它包括注释,如多边形分割和图形的边界框,列出标题、表格和来自研究论文和文章的图像文本。使用coco分析技术对该数据集进行了评估。在实验中,作者只使用了86,460个表注释中的102,514个。
DocBank是一个包含5000多个带注释的文档图像的大型数据集,旨在训练和评估诸如文本分类、实体识别和关系提取等任务。它包括标题、作者姓名、隶属关系、摘要、正文等方面的注释。
ICDAR-19:表检测和识别(cTDaR)竞赛于2019年由ICDAR组织。对于表格检测任务(TRACKA),在比赛中引入了两个新的数据集(现代和历史数据集)。为了与之前的最先进的方法进行直接比较,实验提供了在IoU阈值范围为0.5-0.9的现代数据集上的结果。
实验设置细节:
实验使用在ImageNet数据集上预先训练的ResNet-50为主干的可变形DETR作为检测框架,以评估半监督方法的有效性。在PubLayNet、ICDAR-19、DocBank和TableBank的三类数据集上进行训练。实验使用10%、30%和50%的标记数据,其余的作为未标记数据。伪标记的阈值设置为0.7。将所有实验的训练周期设置为150,在第120期的学习率降低了0.1倍。应用强增强作为水平翻转,调整大小,去除斑块,裁剪,灰度和高斯模糊。实验使用水平翻转来应用弱增强。可变形DETR解码器输入的query数的值N被设置为30,因为它能给出最好的结果。除非另有说明,实验都使用mAP(AP50:95)度量来评估结果。

实验结果讨论:
TableBank:
实验提供了对不同比例的标签数据的表库数据集的所有分割的实验结果。还比较了基于transformer的半监督方法与以前的基于深度学习的监督和半监督方法。此外,实验给出了10%标记数据的TableBank-both数据集在所有IoU阈值下的结果。表1提供了半监督方法在TableBank-latex, TableBank-word, 和TableBank-both数据集,分别10%、30%和50%标记数据时的实验结果。它表明,在10%标记数据时,TableBank-both数据集的AP50值最高,为95.8%,TableBank-latex为93.5%,TableBank-word有92.5%。
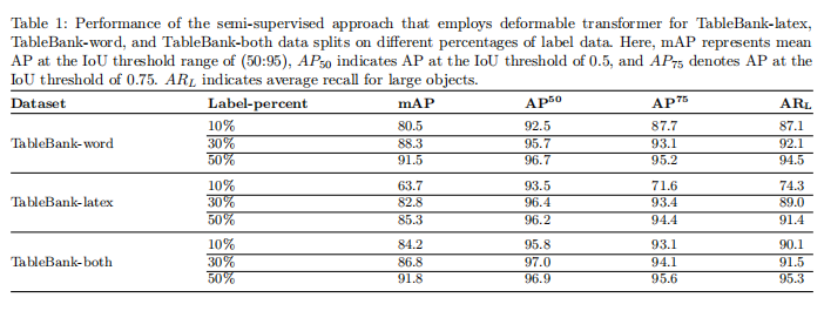
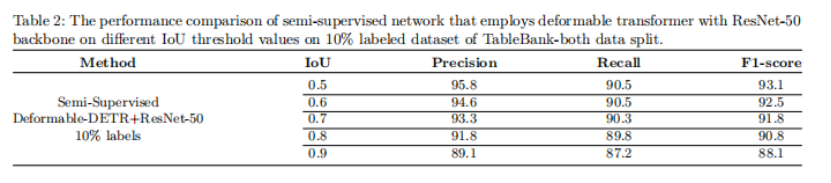
表格的半监督学习的定性分析如图5所示。图5的(b)部分有一个与行和列结构相似的矩阵,网络将该矩阵检测为一个表格,给出false positive检测结果。在这里,不正确的检测结果表明网络不能提供正确的表格区域检测。表2给出了这种半监督方法对10%标签数据上的所有数据集的不同IoU阈值的结果。在TableBank10%标记数据集上使用不同的ResNet-50骨干的半监督网络的准确率、召回率和f1-score的可视化比较如图6所示。

与以前的监督方法和半监督方法的比较
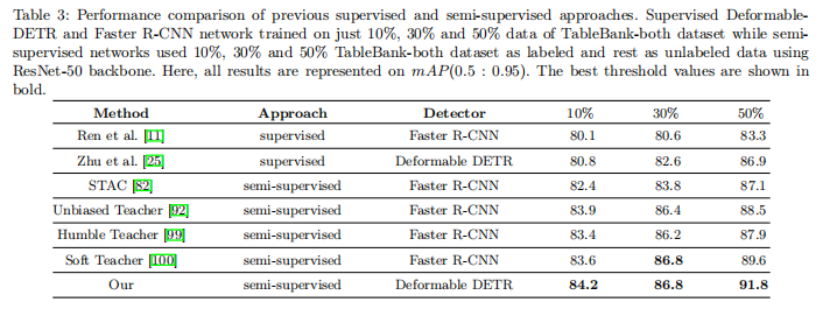
表3比较了ResNet-50主干上基于深度学习的监督网络和半监督网络。还将在10%、30%和50%TableBank-both数据集标签数据上训练的监督可变形DETR与使用可变形transformer的半监督方法进行了比较。结果表明,基于attention机制的半监督方法使用候选生成过程和后处理步骤,如非最大抑制(NMS),取得了可观的结果。
PubLayNet:
实验讨论了在PubLayNet表类数据集上对不同标记数据百分比的实验结果。还比较了基于transformer的半监督方法与以前的基于深度学习的监督和半监督方法。此外,实验给出了10%标记数据的PubLayNet数据集上的所有IoU阈值的结果。表4提供了半监督方法的结果,该方法对PubLayNet表类数据使用可变形transformer来处理标记数据的不同百分比。在这里,10%、30%和50%的标记数据的AP50值分别为98.5%、98.8%和98.8%
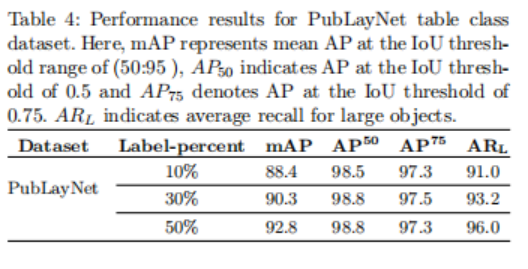
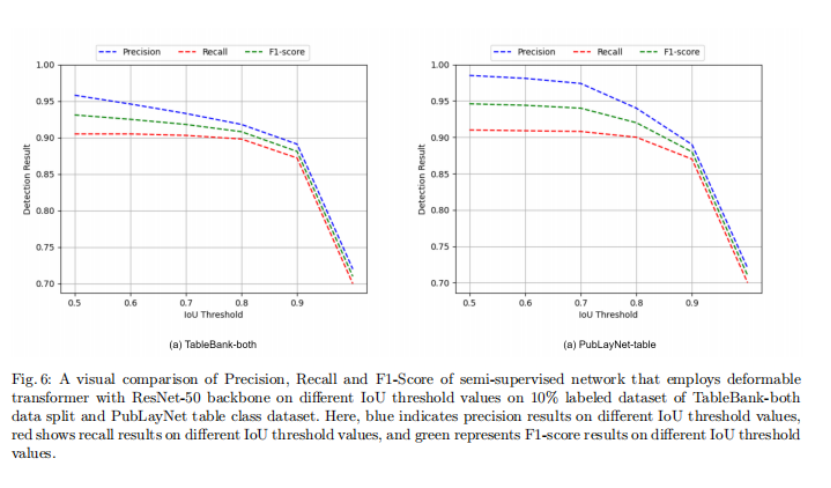
此外,半监督网络在10%的标记的PubLayNet数据集上,在不同的IoU阈值上进行训练。表5给出了半监督方法对10%标记数据上的PubLayNet表类的不同IoU阈值的结果。在PubLayNet表类的10%标记数据集上,在不同的IoU阈值上使用具有ResNet-50主干的可变形transformer网络的半监督网络的准确率、召回率和f1-score的可视化比较如图6(b)所示。这里,蓝色表示不同IoU阈值的准确率结果,红色表示不同IoU阈值的召回结果,绿色表示对不同IoU阈值的f1-score结果。
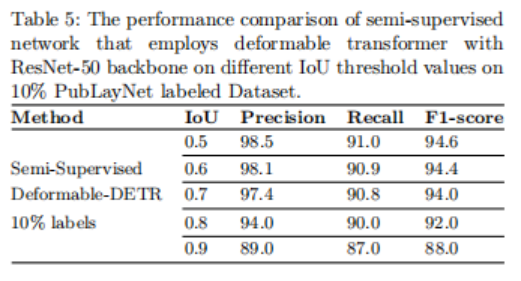
与以前的监督方法和半监督方法的比较
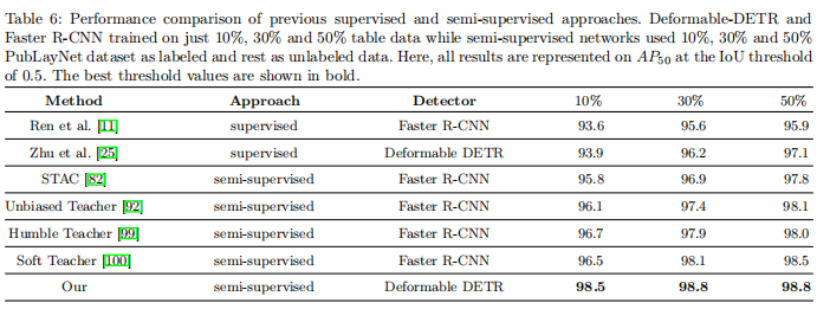
表6比较了使用ResNet-50骨干网的PubLayNet表类上基于深度学习的监督网络和半监督网络。还比较了在10%、30%和50%的PubLayNet表类标签数据上训练的有监督的可变形detr与使用可变形transformer的半监督方法。它表明,半监督方法不使用候选和后处理步骤,如非最大抑制(NMS),提供了有竞争力的结果。
DocBank:
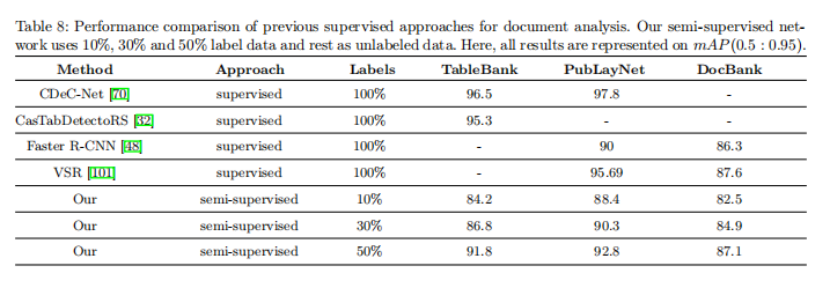
实验讨论了在DocBank数据集上的不同标签百分比数据的实验结果。在表7中比较了基于transformer的半监督方法与以前的基于cnn的半监督方法。

此外,还比较了表8中对不同比例的标记数据的半监督方法与之前针对不同数据集的表格检测和文档分析方法。虽然不能直接比较作者的半监督方法与以前的监督文档分析方法。然而,可以观察到,即使有50%的标签数据,作者也获得了与以前的监督方法类似的结果。
ICDAR-19:
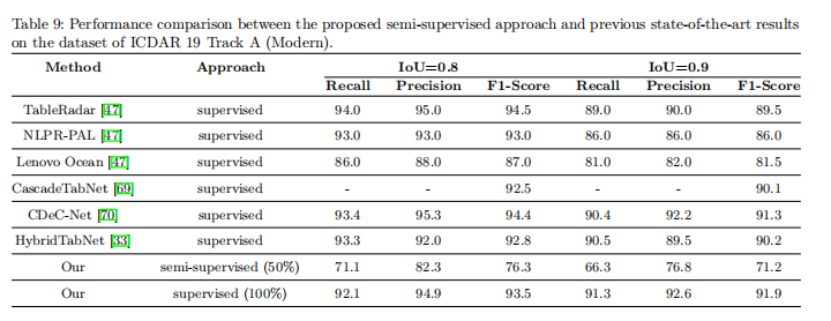
实验还评估了在Modern Track A数据集上的表格检测方法。作者总结了该方法在不同百分比的标签数据下的定量结果,并将其与表9中以前的监督表格检测方法进行了比较。在更高的IoU阈值0.8和0.9下评估结果。为了与以前的表格检测方法进行直接比较,作者还在100%的标签数据上评估了论文的方法。论文方法在100%标签数据的IoU阈值上获得了92.6%的准确率和91.3%的召回率。
消融实验:
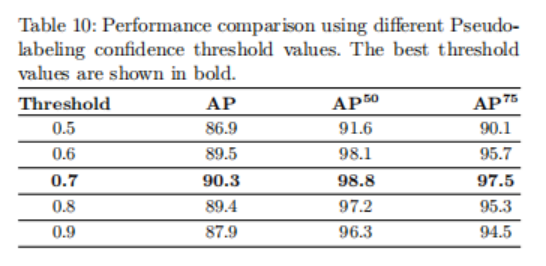
伪标记置信阈值
阈值(称为置信阈值)在决定生成的伪标签的准确性和数量之间的平衡方面起着重要的作用。随着这个阈值的增加,通过过滤器的样本将会更少,但它们的质量将会更高。相反,较小的阈值将导致更多的样本通过,但false positive的可能性更高。从0.5到0.9的各种阈值的影响如表10所示。根据计算结果,确定最优阈值为0.7。
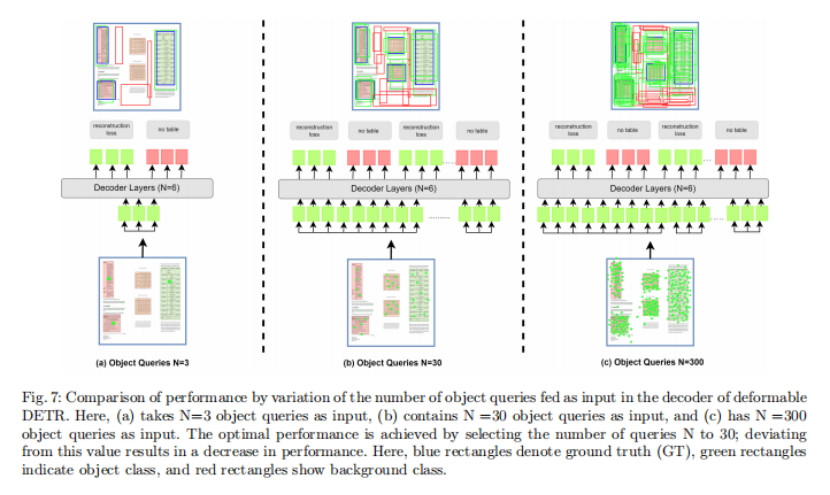
可学习query数量的影响
在分析中,作者研究了改变作为可变形DETR解码器中输入的query数量的影响。图7通过改变作为可变形DETR解码器中输入的对象query的数量来比较预测结果。当query数N设置为30时,达到最佳性能;偏离此值会导致性能下降。表11显示并分析了不同对象query数量的结果。为N选择一个较小的值可能会导致模型无法识别特定的对象,从而对其性能产生负面影响。另一方面,选择一个较大的N值可能会导致模型由于过拟合而表现不佳,因为它会错误地将某些区域分类为对象。此外,在师生模块中,该半监督自注意机制的训练复杂度依赖于对象query的数量,并通过最小化对象query的数量来降低复杂度而得到提高。
结论
本文介绍了一种利用可变形transformer对文档图像进行表格检测的半监督方法。该方法通过将伪标签生成框架集成到一个简化的机制中,减轻了对大规模注释数据的需要,并简化了该过程。同时生成伪标签产生了一个被称为“飞轮效应”的动态过程,随着训练的进行,一个模型不断改进另一个模型产生的伪边框。在该框架中,使用两个不同的模块学生和教师,对伪类标签和伪边界框进行了改进。这些模块通过EMA功能相互更新,以提供精确的分类和边界框预测。结果表明,当应用于TableBank和PubLayNet训练数据的10%、30%和50%时,该方法的性能超过了监督模型的性能。此外,当对PubLayNet的10%标记数据进行训练时,该模型的性能与当前基于cnn的半监督基线相比较。在未来,作者的目标是研究标记数据的比例对最终性能的影响,并开发出以最小数量的标记数据有效运行的模型。此外,作者还打算采用基于transformer的半监督学习机制来进行表结构识别任务。
参考文献:
Gao L C, Li Y B, Du L, Zhang X P, Zhu Z Y, Lu N, Jin L W, Huang Y S, Tang Z . 2022.A survey on table recognition technology. Journal of Image and Graphics, 27(6): 1898-1917.
M Kasem , A Abdallah, A Berendeyev,E Elkady , M Abdalla, M Mahmouda, M Hamada, D Nurseitovd, I Taj-Eddin.Deep learning for table detection and structure recognition: A survey.arXiv:2211.08469v1 [cs.CV] 15 Nov 2022
S A Siddiqui , M I Malik,S Agne , A Dengel and S Ahmed. DeCNT: Deep Deformable CNN for Table Detection. in IEEE Access, vol.6, pp.74151-74161, [DOI: 10.1109/ACCESS.2018.2880211]
T Shehzadi, K A Hashmi, D Stricker, M Liwicki , and M Z Afzal.Towards End-to-End Semi-Supervised Table Detection with Deformable Transformer.arXiv:2305.02769v2 [cs.CV] 7 May 2023
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


