
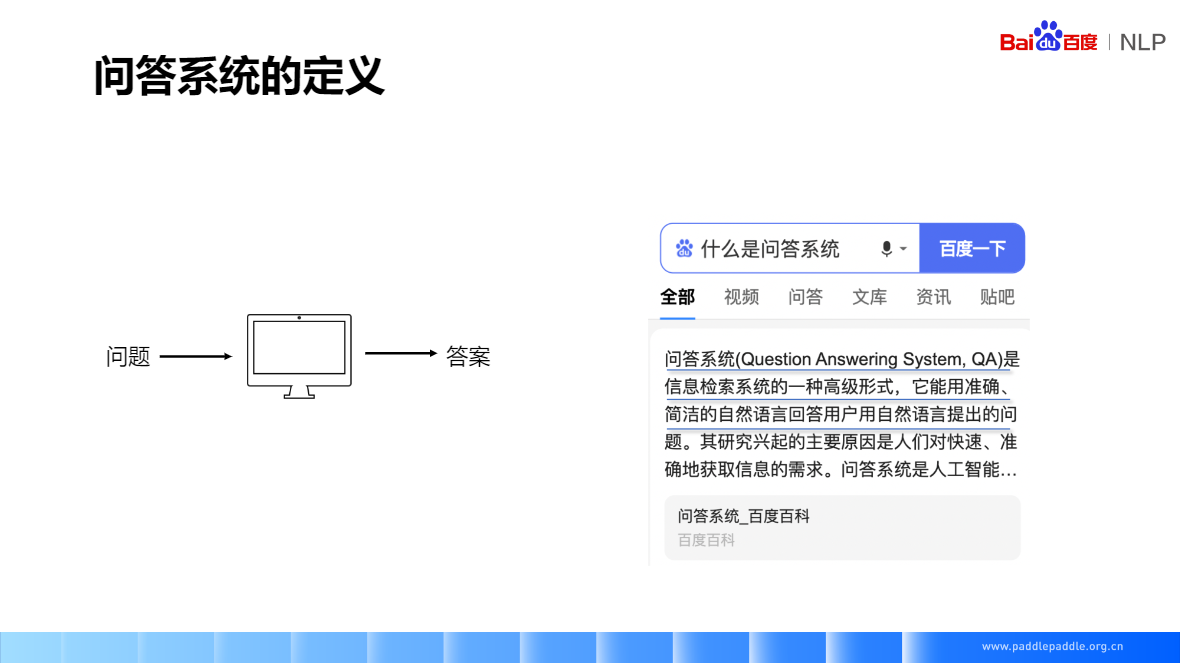
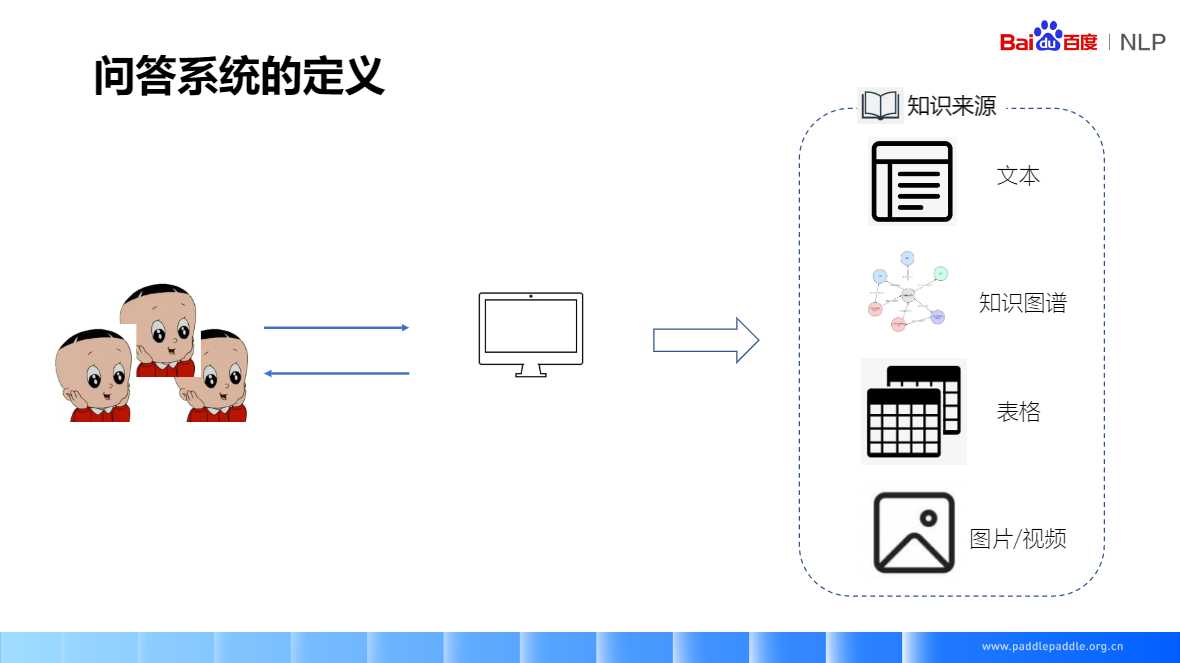
问答系统(Question Answering System,QA) 是信息检索系统的一种高级形式,它能用准确、简洁的自然语言回答用户用自然语言提出的问题。其研究兴起的主要原因是人们对快速、准确地获取信息的需求。问答系统是人工智能.
抽取式阅读理解:它的答案一定是段落里的一个片段,所以在训练前,先要找到答案的起始位置和结束位置,模型只需要预测这两个位置,有点像序列标注的任务,对一段话里的每个字,都会预测两个值,预测是开始位置还是结尾位置的概率,相当于对每个字来讲,都是一个二分类的任务


机器阅读技术:2011年7月20日,姚明正式宣布退役 => 姚明哪一年退役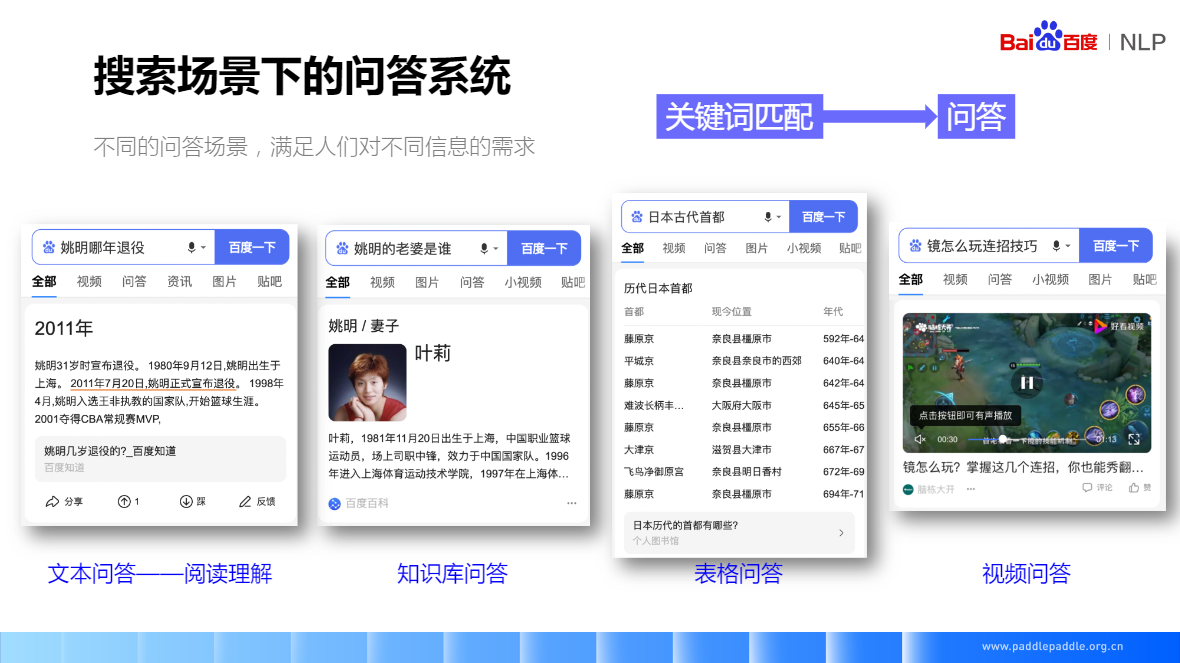
500万的维基百科文档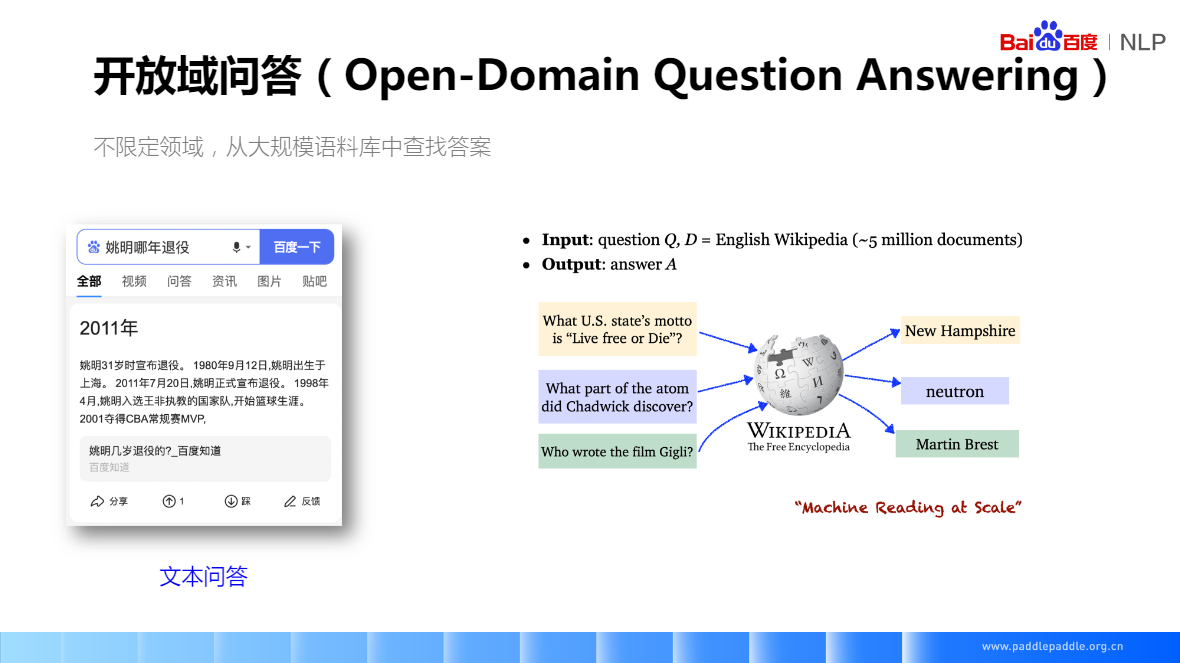
检索式问答:先做段落检索、再做答案抽取
阅读理解:
郭鹤年 => 郭鹤,3个字里面对了2个 => 2/3, 完全匹配 => 1,f1(2/3,1) => 0.8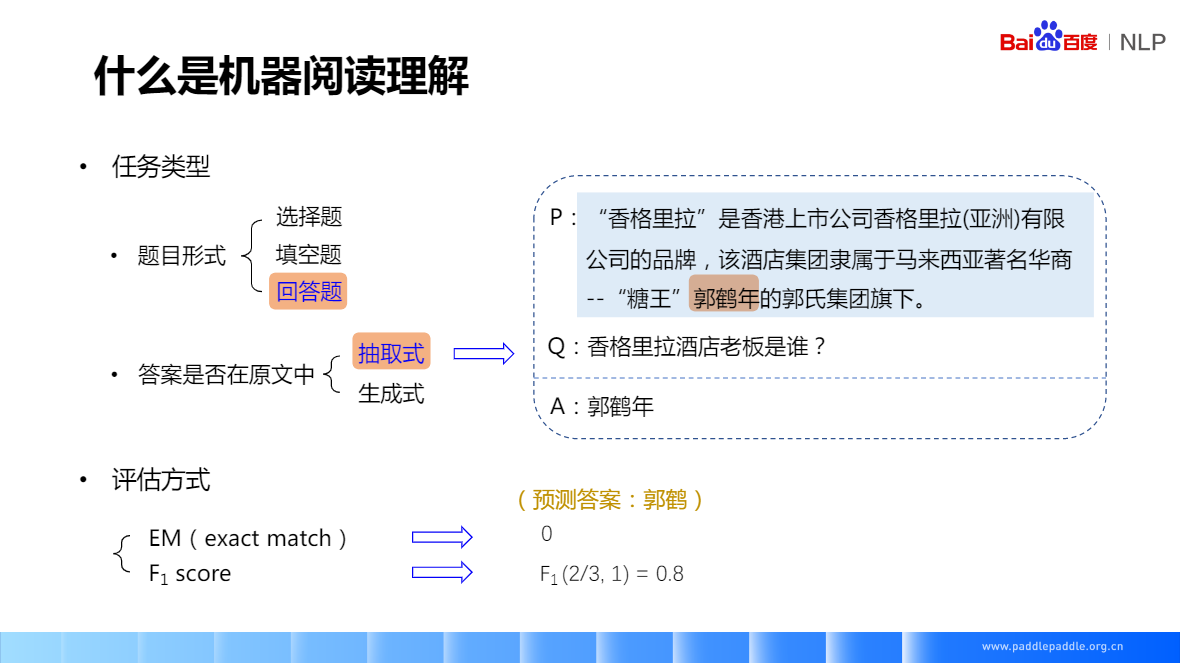
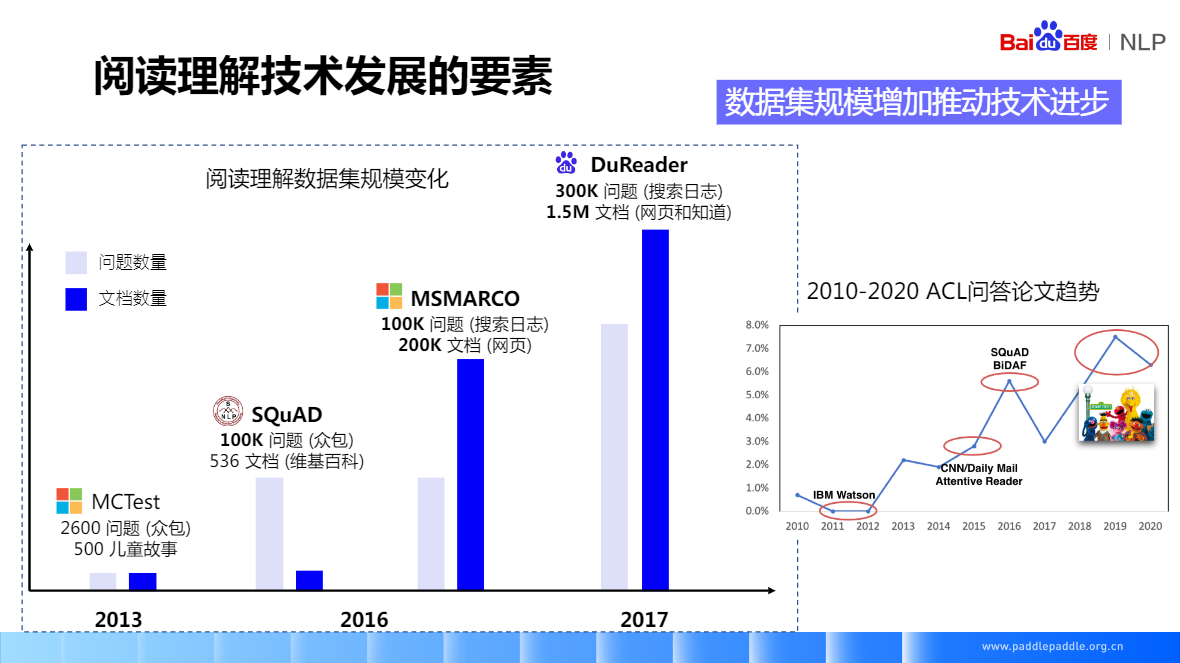
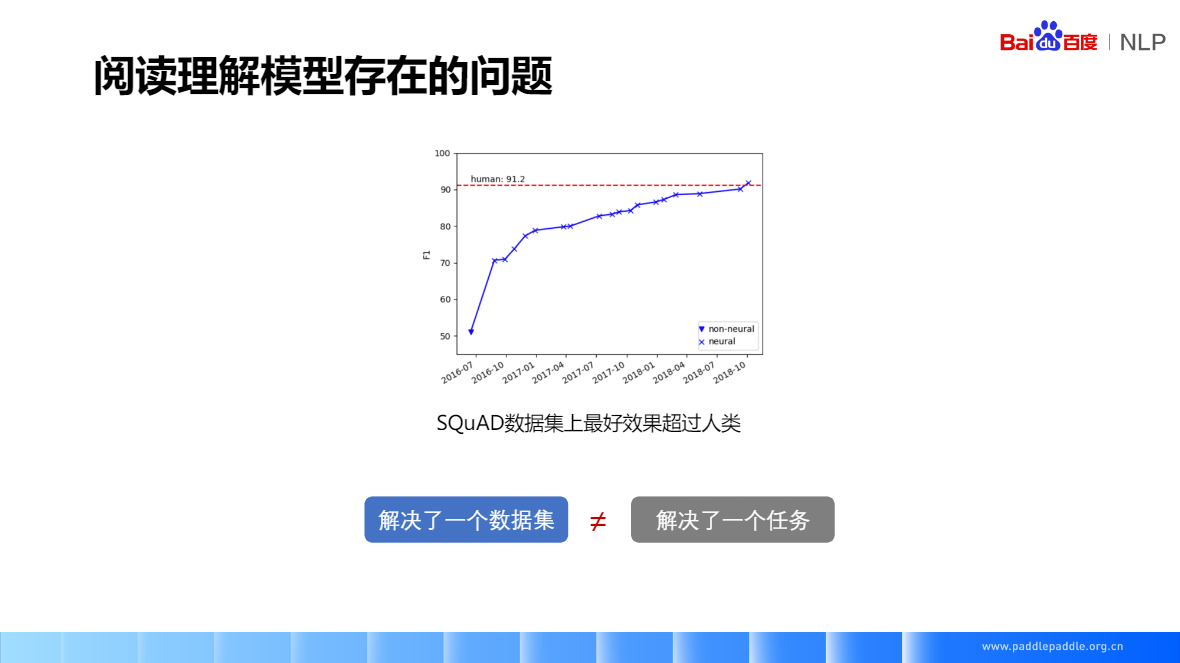
SQuAD(2016) 只能做抽取,数据量是训练深度神经网络的关键要素,数据集有着很大的影响力很多精典的阅读理解模型,也是基于SQuAD做的
DuReader(2017) 百度2017年发布的,迄今为止最大的中文阅读理解数据集,相比较 SQuAD,除了实体类、描述类和事实类的问题,还包含了是非类和观点类的问题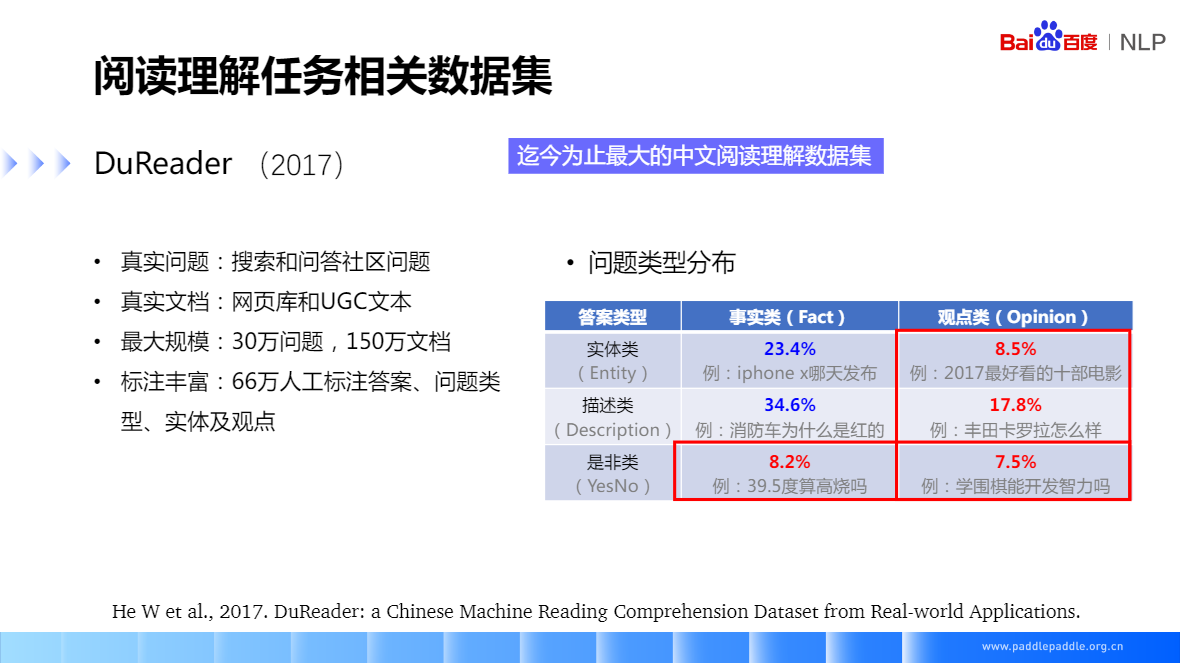
抽取式阅读理解,它的答案一定是段落里的一个片段,所以在训练前,先要找到答案的起始位置和结束位置,模型只需要预测这两个位置,有点像序列标注的任务,对一段话里的每个字,都会预测两个值,预测是开始位置还是结尾位置的概率,相当于对每个字来讲,都是一个二分类的任务
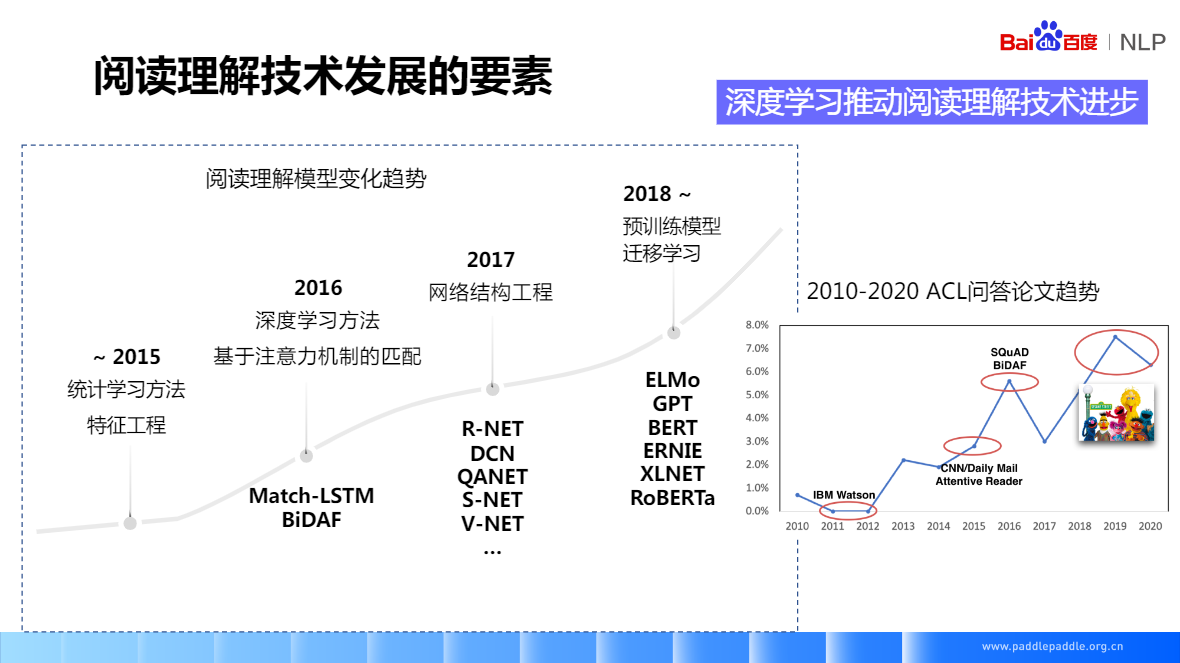
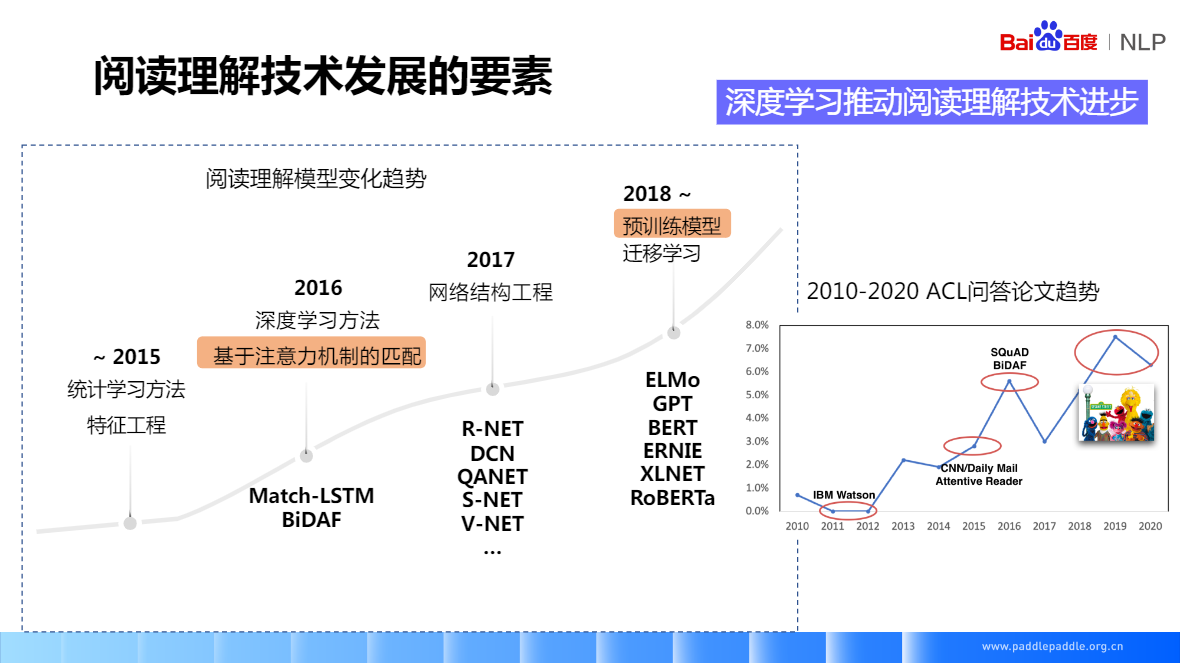
基于LSTM+注意力机制,核心思想就是如何对问题和段落进行交互和语义理解,一般就是在模型里面加各种 attention,各种复杂的模型结构基本上能总结成图中的形式,一般分为四层,
- 向量表示层:主要负责把问题和段落里的token映射成一个向量表示
- 语义编码层:使用RNN来对问题和段落进行编码,编码后,每一个token的向量都包含了上下文的语义信息
- 交互层:最重要的一层,也是大多数研究工作的一个重点,负责捕捉问题和段落之间的交互信息,把问题的向量,和段落的向量做各种交互,一般使用各种注意力机制。最后它会输出一个融合了问题的语义信息的段落表示。
- 答案预测层:会在段落表示的基本上,预测答案的位置,也就是预测答案的开始位置和结尾位置
LSTM 是一个比较基本的模型结构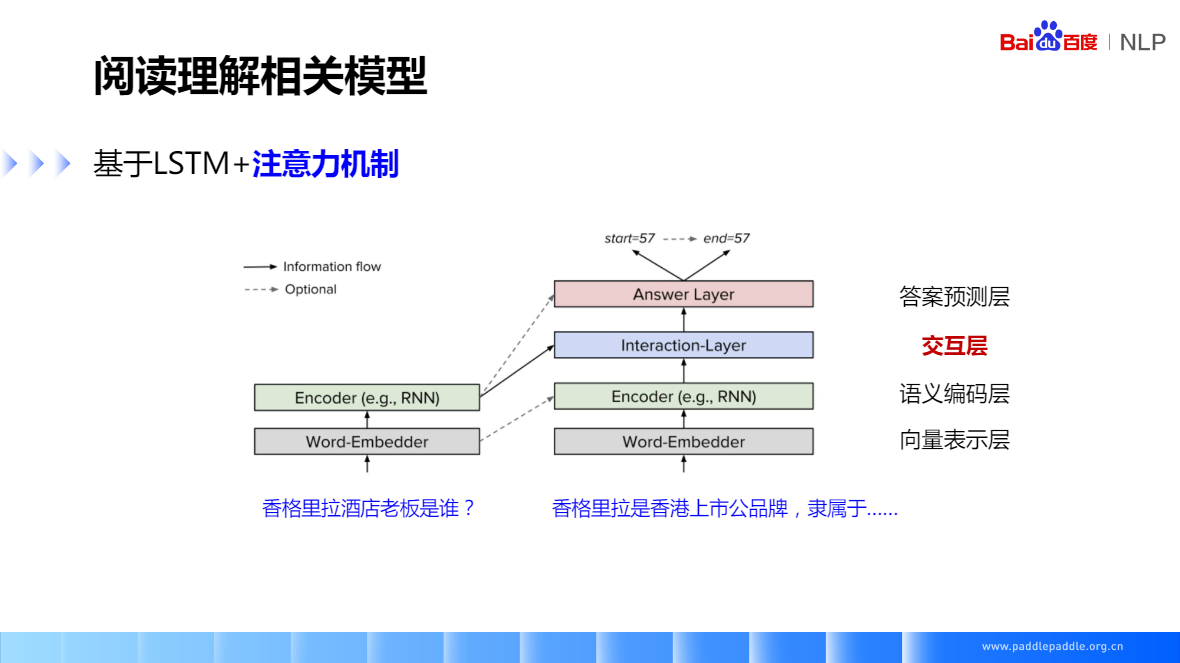
注意力机制,来源于图像,在看一张图片的时候,就会聚焦到图片上的某些地方,通过图片上一些重点地方,获取到主要的信息。
比如图片里是小狗,看到了狗的耳朵、鼻子就能判断出这是小狗。这时候注意力就集中在狗的脸部上。
对于文本也一样,文本的问题和段落匹配过程中,也会聚焦到不同的词上面,比如:香格里拉酒店老板是谁?段落:香格里拉是香港上市公司品牌隶属于郭氏集团。
对于问题香格里拉这个词,在段落文本中更关心香格里拉这个词,带着问题读本文时,所关注点是不一样的。如:老板这个词,关注力在隶属于上。
如果问题是:香格里拉在哪里上市的,那么对于文本的关注点就在“上市公司”上了
注意力机制,就是获取问题和段落文本交互信息的一个重要手段
理论形式:给定了一个查询向量Query,以及一些带计算的值Value,通过计算查询向量跟Key的注意力分布,并把它附加在Value上面,计算出 attention 的值。
- Query 向量是问题,
- Value 对应段落里面编码好的语义表示,
- key 是问题向量和文本向量做内积之后做归一化,代表了每个词的权重
最后对这些 Value 根据这些权重,做加权求和,最后得到了文本经过attention之后的值
一般会事先定义一个候选库,也就是大规模语料的来源,然后从这个库里面检索,检索出一个段落后,再在这个段路上做匹配。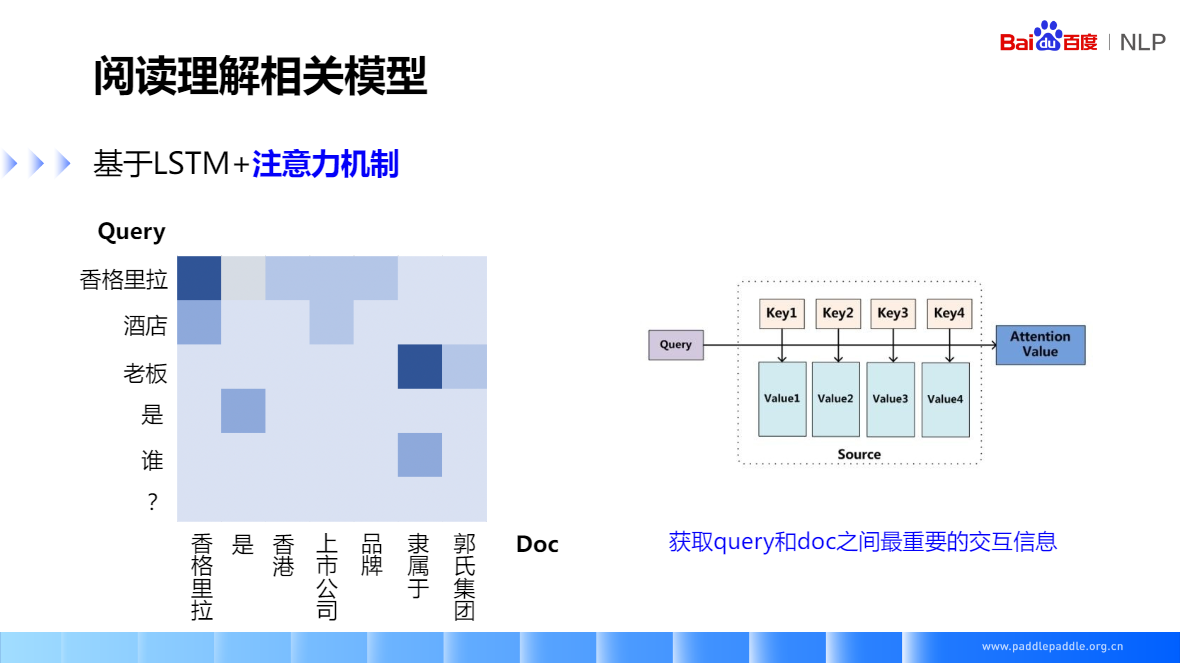
基于预训练语言模型(eg.BERT)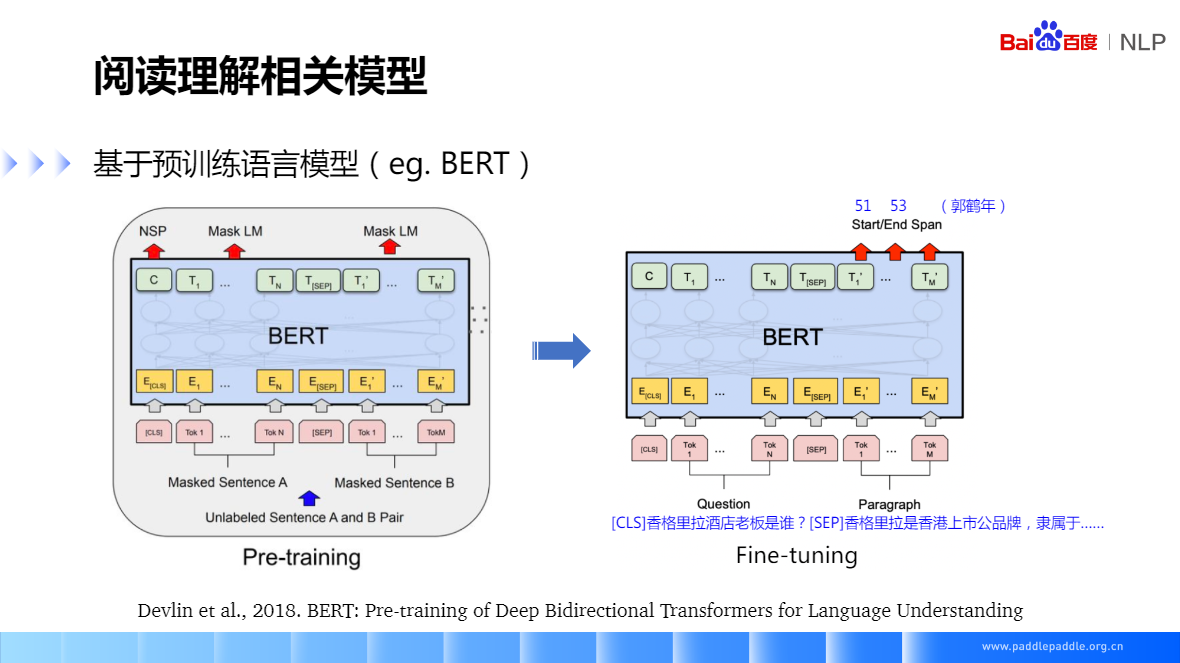
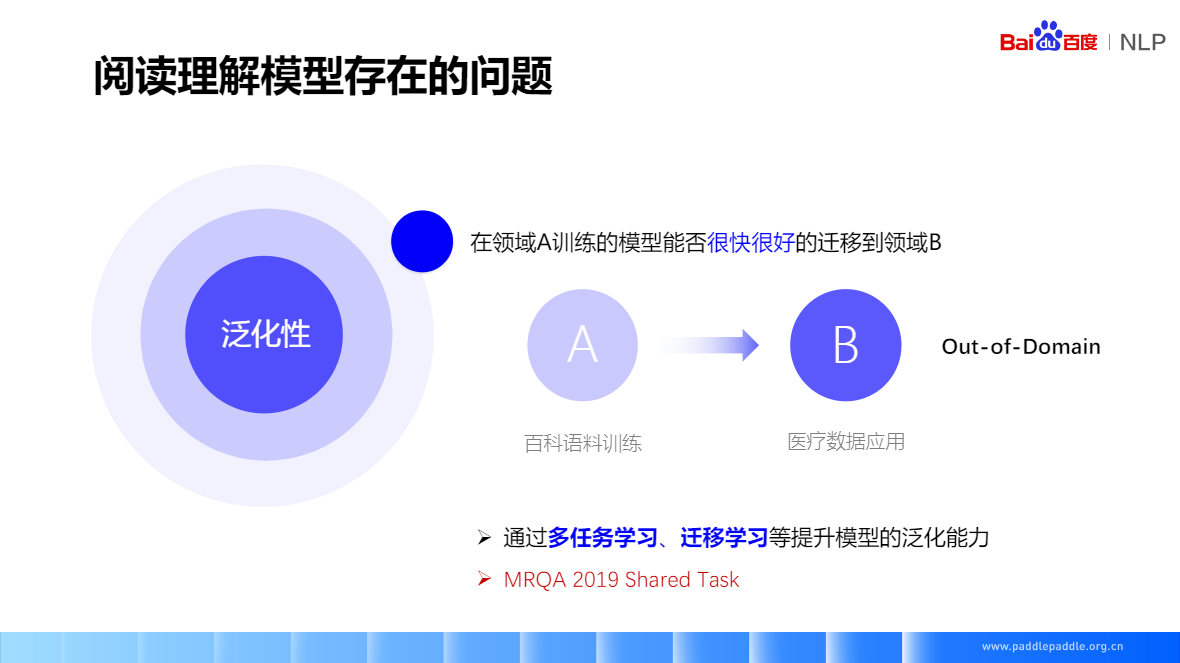
领导A训练好的模型,在领域B应用
- 通过多任务学习、迁移学习等提升模型的泛化能力
- MRQA 2019 Shared Task
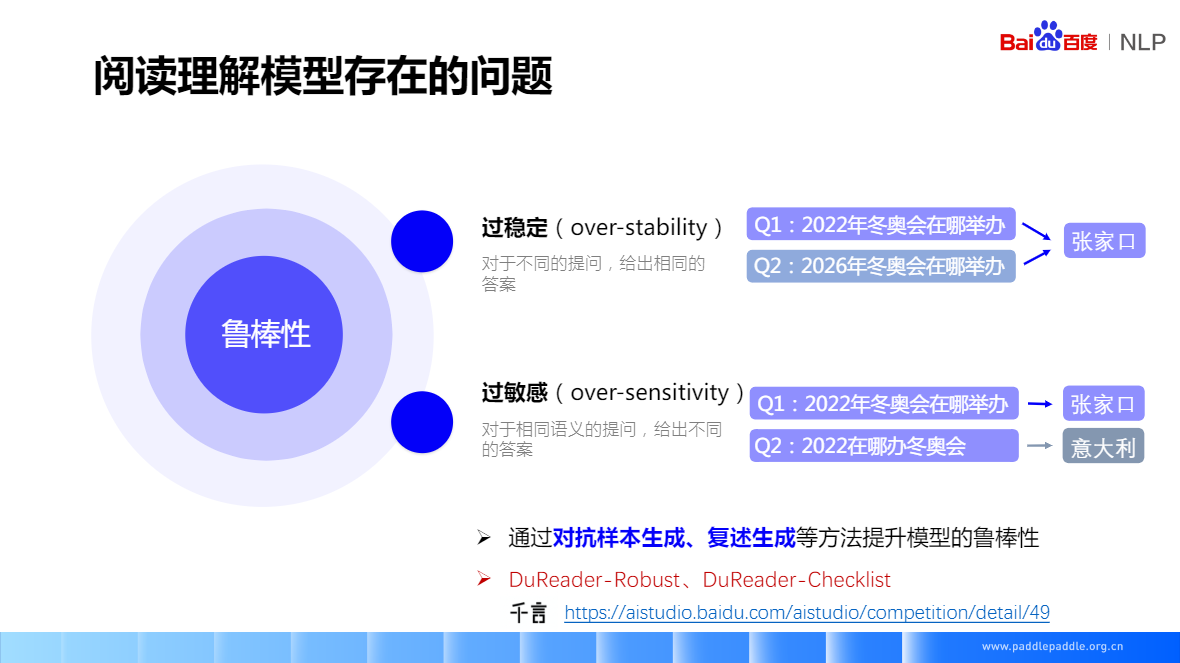
过稳定:对于不同的提问,给出相同的答案
过敏感:对于相同语义的提问,给出不同的答案
提高阅读模型鲁棒性的方法:
- 通过对抗样本生成、复述生成等方法提升模型的鲁棒性
- DuReader-Robust、DuReader-Checklist
千言数据集:https://aistudio.baidu.com/aistudio/competition/detail/49
段落检索

稀疏向量检索:双塔
- 基于词的稀疏表示
- 匹配能力有限,只能捕捉字面匹配
- 不可学习
把文本表示成 one hot (拼写可能有错)的形式,常见的有 TFDF、BM?
文章编码成向量,向量的长度和词典的大小一致,比如词典的大小是3W,稀疏向量表示3W,
每个位置表示这个词有没有在问题中出现过,出现过就是1
倒排索引,一般采用稀疏向量方式,只能做字面匹配
稀疏向量,几百、上千万的文档都支持
稠密向量检索:单塔
- 基于对偶模型结构,进行稠密向量表示
- 能够建模语义匹配
- 可学习的
把文本表示成稠密向量,也就是 Embedding,需要通过模型,对文本的语义信息进行建模,然后把信息记录在向量里,这边的向量长度,一般是128、256、768,相较于稀疏向量检索小很多,每个位置的数字是浮点数
一般通过对偶模型的结构进行训练,来获得建模的语义向量,
例:
Q:王思聪有几个女朋友
P:国民老公的恋人A、B、C......
如果通过 稀疏向量检索,可能完全匹配不到
稠密向量检索,可以学习到,国民老公=>王思聪,恋人=> 女朋友
两者可以互补,一个字面匹配,一个是语义匹配
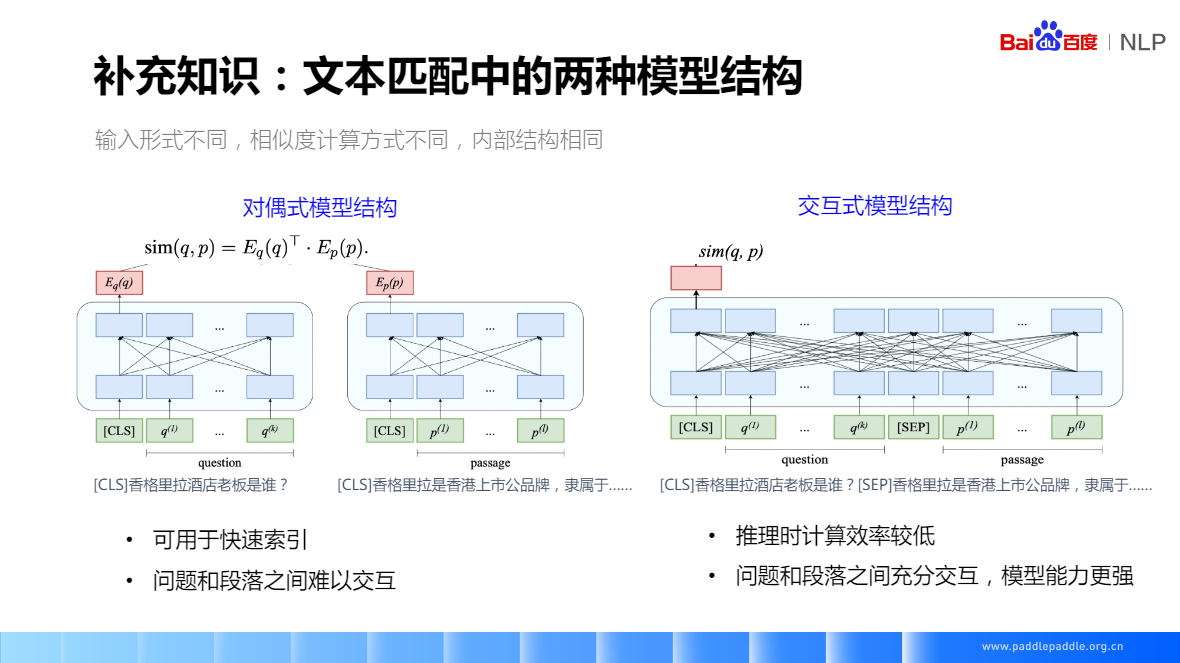
文本匹配中的两种模型结构
- 对偶式模型结构:问题、段落分别编码,得到各自的 Embedding,然后通过内积或者 cosin 来计算向量之间的相似度,这个相似度代表了问题和段落之间的匹配程度
问题和段落之间难以交互,因为他们是分别编码的。底层没有交互,所以逻辑会弱些
可以快速索引,可以提前把段落向量这边计算好 - 交互式模型结构:输入把问题和段落拼一起,在中间交互层问题的文本和段落的文本会有个完全的交互。最后输出一个来表示问题和段落的匹配程度
对偶模型的参数可以共享,共享参数对字面匹配效果好些,不共享效果也差不了太多
实际应用中,把所有的文档都计算完,把向量存储下来。在线计算时,直接去检索
DPR
正例和强负例 1:1 ,弱负例 越多越好
强负例:和文档有些关系
弱负例:和文档内容不相关的。
一般做检索,不会把正例表得那么完整,在标注时,也是通过一个query,先去检索出一些候选的段落,在候选段落里,去标正例和负例,这样因为检索能力的限制,可能没有检索回来的一些段落就没有标注,这样会导致数据集中漏标,所以实际上在训练过程中会对这些漏标的数据集进行处理,有些数据集只标了正例,并没有负例,这时候负例只能通过一些方式去构造

推荐阅读
- Reading Wikipedia to Answer Open-domain Questions
- Bi-DirectionalAttentionFlowForMachineComprehension
- Machine Comprehension UsingMatch-LSTMand Answer Pointer
- Dense Passage Retrieval for Open-Domain Question Answering
- Latent Retrieval for Weakly Supervised Open Domain Question Answering
- Sparse, Dense, and Attentional Representations for Text Retrieval
- REALM:Retrieval-Augmented Language Model Pre-Training
- RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


