
使用python爬虫实现百度翻译功能
python爬虫实现百度翻译: python解释器【模拟浏览器】,发送【post请求】,传入待【翻译的内容】作为参数,获取【百度翻译的结果】
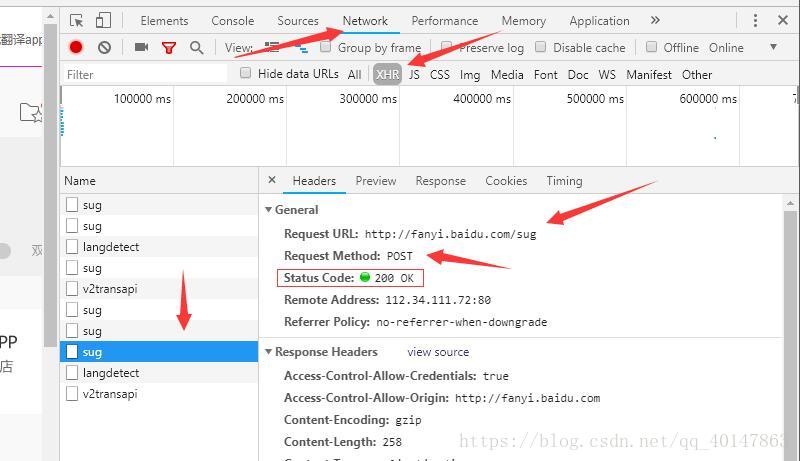
通过开发者工具,获取发送请求的地址
提示: 翻译内容发送的请求地址,绝对不是打开百度翻译的那个地址,想要抓取地址,就要借助【浏览器的开发者工具】,或者其他抓包工具
下面介绍获取请求地址的具体方法
以Chrome为例
- 打开百度翻译:http://fanyi.baidu.com/
- 【点击右键】>【检查】>【network】(如果是火狐浏览器,点击【网络】)
- 点击【XHR】项,(有些需要刷新,有些异步的请求不需要刷新)
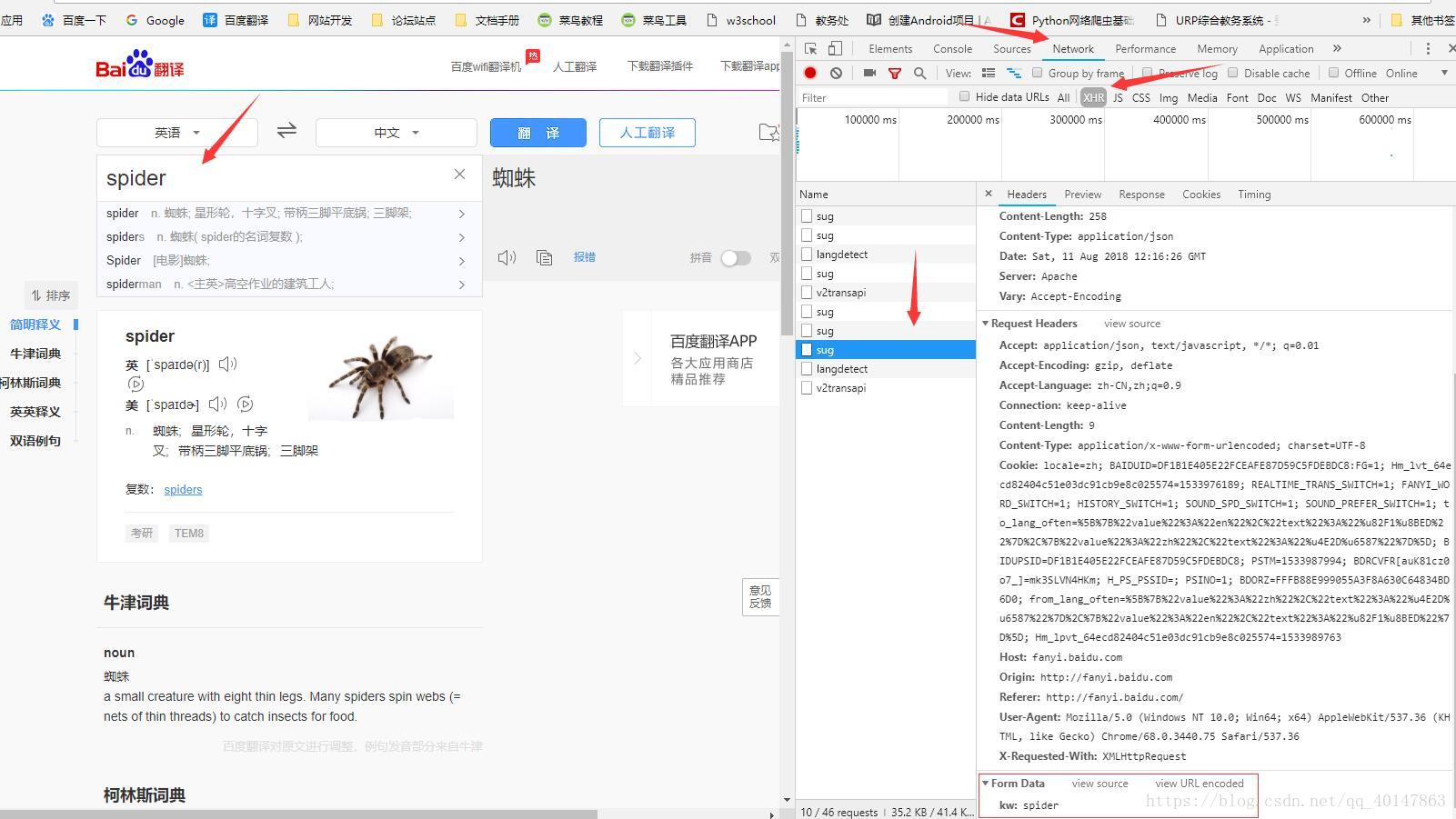
- 在页面【输入翻译的词汇】
- 在XHR项下,查找包含【输入需要翻译的词汇】的请求
查看请求的参数,需要【点击请求】>【Headers】>最下面的【Form Data】
(这里有一个坑:我们会发现有多个sug项,其实是因为百度翻译只要每输入一个字母就会发送一次请求,所以虽然多个请求的地址都是一样的,但是只有最后一个sug项的参数才是最后的词汇)操作截图
请求地址在这里
献上实现的代码
直接上代码,具体步骤下载注释上了
- 不会配置环境,安装python的包,请参考上一篇:
https://blog.csdn.net/qq_40147863/article/details/81451202 - py05bdfanyi.py文件:https://xpwi.github.io/py/py%E7%88%AC%E8%99%AB/py05bdfanyi.py
# python爬虫实现百度翻译
# urllib和request POST参数提交
# 缺少包请自行查看之前的笔记
from urllib import request,parse
import json
def fanyi(keyword):
base_url = 'http://fanyi.baidu.com/sug'
# 构建请求对象
data = {
'kw': keyword
}
data = parse.urlencode(data)
# 模拟浏览器
header = {"User-Agent": "mozilla/4.0 (compatible; MSIE 5.5; Windows NT)"}
req = request.Request(url=base_url,data=bytes(data,encoding='utf-8'),headers=header)
res = request.urlopen(req)
# 获取响应的json字符串
str_json = res.read().decode('utf-8')
# 把json转换成字典
myjson = json.loads(str_json)
info = myjson['data'][0]['v']
print(info)
if __name__=='__main__':
while True:
keyword = input('请输入翻译的单词:')
if keyword == 'q':
break
fanyi(keyword)代码运行

后续还会更精彩
python爬虫实现百度翻译: python解释器【模拟浏览器】,发送【post请求】,传入待【翻译的内容】作为参数,获取【百度翻译的结果】
更多文章链接:Python 爬虫随笔
- 本笔记不允许任何个人和组织转载
内容来源于网络如有侵权请私信删除
- 还没有人评论,欢迎说说您的想法!



 客服
客服


