
concat
最近在写数据的时候看到用一个concat函数进行整合,但是下面这段代码之后就碰上个很奇怪的地方
for i, bag in enumerate(bags):
coure_result = func()
core_df = pd.DataFrame([core_result])
dfs.append(core_df)
df = pd.concat(dfs)
这段代码首先就是用dfs记录了每一组数据,最后使用concat函数进行连接。在这之后我希望在特定位置插入一列数据
df_summary = pd.DataFrame(summary, columns = ["summary"])
df.insert(1,"summary",df_summary["summary"])
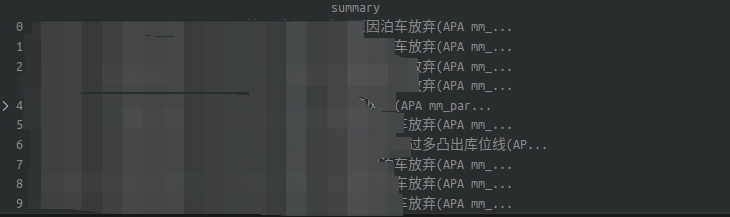
一共有三种类型的文本,10条数据,在df格式下前面也有索引。而我之前拼接好的内容如下图:

按理来说运行insert之后,每一行都会对应一个summary里面的字段,但是最终的运行效果summary里面的内容完全变成同样的话
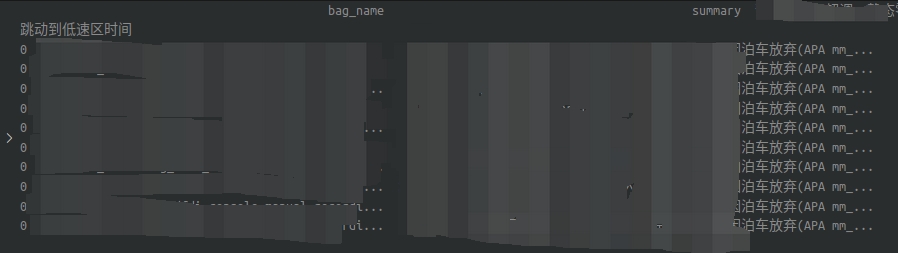
这让我很是奇怪。研究了半天,发现df原来的内容默认索引全都是0,原因是因为在创建和合并DataFrame的时候,concat连接每一个dfs里面的独立的dataframe时,每个DataFrame都有自己独立的索引,从0开始。在运行concat函数时会保留原始的索引,即使在最终的DataFrame里面重复了。因此,再重新插入新的有index的df时,会根据索引位置插入数据,而并不是像Excel那样直接插入。
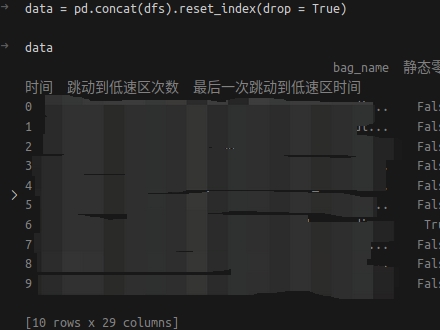
所以需要先改掉原先的索引才能插入
df = pd.concat(dfs).reset_index(drop = True)
意味着重置索引后丢弃掉原来的索引,如果不把drop改成True,那么原来的索引将会变成新的列。
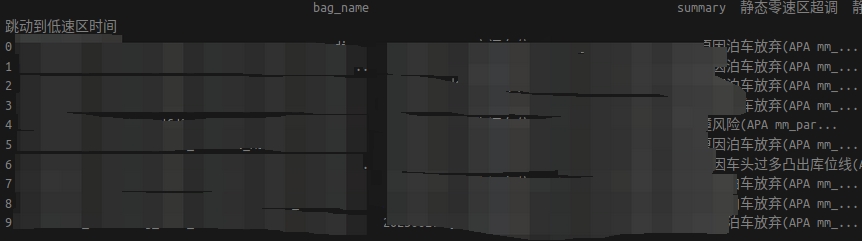
这样的话,df的内容和我要插入内容的索引就可以对应上了,在进行插入的时候就可以了
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


