
1.概述
在数据库设计过程中,用户可能会经常遇到这种问题:是否应该把所有表都按照第三范式来设计?表里面的字段到底改设置为多大长度合适?这些问题虽然很小,但是如果设计不当则可能会给将来的应用带来很多的性能问题。本章中将介绍MySQL中一些数据库对象的优化方法,其中一些方法不仅仅适用于MySQL,也适用于其他类型的数据库管理系统。
2.优化表的数据类型
表需要使用任何的数据类型,是需要根据应用程序来判断的。虽然应用程序设计的时候需要考虑字段的长度留有一定的冗余,但是不推荐让很多字段都留有大量的冗余,这样即浪费磁盘存储空间,同时在应用程序操作时也浪费物理内存。在MySQL中,可以使用函数PROCEDURE ANALYSE()对当前应用的表进行分析,该函数可以对数据表中列的数据类型提出优化建议,用户可以根据应用的实际情况酌情考虑是否实施优化。以下是函数PROCEDURE ANALYSE()的使用方法:
SELECT * FROM tbl_name PROCEDURE ANALYSE(); SELECT * FROM tbl_name PROCEDURE ANALYSE(16,256);
但是我在8.0以上版本的MySQL上执行这条语句是报错的,具体是8.0版本不支持还是改变语法,这边就暂时不深究了,有空再查官网资料了解下。
3.通过拆分提高表的访问效率
这里所说的“拆分”,是指对数据表进行拆分。如果针对MyISAM类型的表进行,那么有两种拆分方法。
●第一种方法是垂直拆分,即把主键和一些列放到一个表,然后把主键和另外的列放到另一个表中。
优点:如果一个表中某些列常用,而另外一些列不常用,则可以采用垂直拆分,另外垂直拆分可以使得数据行变小,一个数据页就能存放更多的数据,在查询时就会减少I/O次数。
缺点:需要管理冗余列,查询所有数据需要联合(JOIN)操作。
●第二种方法是水平拆分,即根据一列或多列数据的值把数据行放到两个独立的表中。水平拆分通常在以下几种情况下使用:
◎表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询速度。
◎表中的数据本来就有独立性,例如,表中分别记录各个地区的数据或不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
◎需要把数据存放到多个介质上。例如,移动电话的账单表就可以分成两个表或多个表。最近3个月的账单数据存在一个表中,3个月前的历史账单存放在另外一个表中,超过1年的历史账单可以存储到单独的存储介质上,这种拆分是最常使用的水平拆分方法。
注:水平拆分会给应用系统增加复杂度,它通常在查询时需要多个表名,查询所有数据需要UNION操作。在许多数据库应用中,这种复杂性会超过它带来的优点,因为只要索引关键字不大,则在索引用于查询时,表中增加2至3倍数据量,查询时也就增加读一个索引层的磁盘次数,所以水平拆分要考虑数据量的增长速度,根据实际情况决定是否需要对表进行水平拆分。
4.逆规范化
●数据库设计时要满足规范化这个道理大家都非常清楚,但是否数据的规范化程度越高越好呢?这还是由实际需求来决定。因为规范化越高,那么产生的关系就越多,关系过多的直接结果就是导致表之间的连接操作越频繁,而表之间的连接操作是性能较低的操作,直接影响到查询的速度,所以对于查询较多的应用程序就需要根据实际情况运用逆规范化对数据进行设计,通过逆规范化来提高查询的性能。
例如,一般电商平台后台的库存列表都会包含商家名称等信息,方便管理人员查看,假设商家ID、名字和其他属性都存放在一个商家信息表A中,而库存型号、品牌、库存量、商家ID和其他属性都存放在一个库存信息表B中,那么我们在库存列表中要显示商家名称等信息时,就必须要在数据库中进行表连接,因为库存信息表B中并不包含商家信息表A的商家名称等信息,所以必须通过关联A表把数据取过来,如果在数据库设计时就考虑到这一点,就可以在B表增加一个冗余字段存放商家名字数据,这样在查询库存列表时就不用再做表关联了,这样也可以使查询有更好的性能。
●反规范的好处是降低连接操作的需求、降低外键和索引的数目,还可能减少表的数目,相应带来的问题是可能出现数据的完整性问题。加快查询速度,但会降低修改速度。因此决定做反规范时,一定要权衡利弊,仔细分析应用程序的数据存取需求和实际的性能特点,好的索引和其他方法经常能够解决性能问题,而不必采用反规范这种方法。
●在进行反规范操作之前,要充分考虑数据的存取需求、常用表的大小、一些特殊的计算(例如合计)、数据的物理存储位置等。常用的反规范技术有增加冗余列、增加派生列、重新组表和分割表。
◎增加冗余列:指在多个表中具有相同的列,它常用来在查询时避免连接操作。
◎增加派生列:指增加的列来自其他表中的数据,由其他表中的数据经过计算生成。增加的派生列其作用是在查询时减少连接操作,避免使用集函数。
◎重新组表:指如果许多用户需要查看两个表连接出来的结果数据,则把这两个表重新组成一个表来减少连接而提高性能。
◎分割表:可以参见3小节“通过拆分提高表的访问效率”的内容。
●另外,逆规范技术需要维护数据的完整性。无论使用何种反规范技术,都需要一定的管理来维护数据的完整性,常用的方法是批处理维护、应用程序逻辑和触发器。
◎批处理维护是指对复制列或派生列的修改积累一定的时间后,运行一批处理作业或存储过程对复制或派生列进行修改,这只能在对实时性要求不高的情况下使用。
◎数据的完整性也可由应用程序逻辑来实现,这就要求必须在同一事务中对所有涉及的表进行增、删、改操作。用应用程序逻辑来实现数据的完整性风险较大,因为同一逻辑必须在所有的应用程序中使用和维护,容易遗漏,特别是在需求变化时,不易于维护。
◎另一种方式就是使用触发器,对数据的任何修改立即触发对复制列或派生列的相应修改。触发器是实时的,而且相应的处理逻辑只在一个地方出现,易于维护。一般来说,是解决这类问题比较好的办法。
5.使用中间表提高统计查询速度
对于数据量较大的表,在其上进行统计查询通常会效率很低,并且还要考虑统计查询是否会对在线的应用程序产生负面影响。通常在这种情况下,使用中间表可以提高统计查询的效率,下面通过对goods_stock库存表的统计来介绍中间表的使用,goods_stock表记录了每天库存导入记录,表结构如下:
DESC goods_stock;
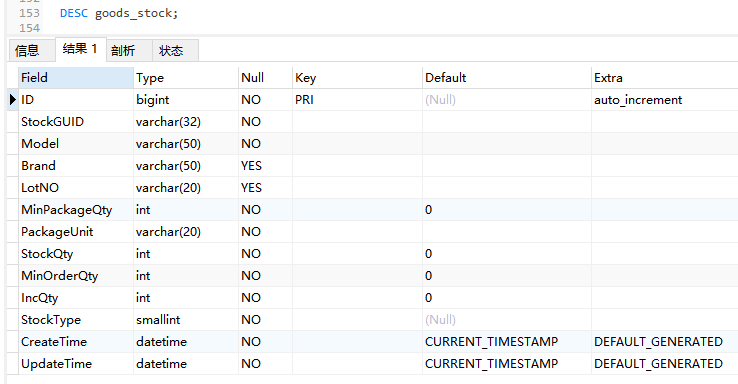
由于每天都会产生大量的库存导入记录,所以goods_stock表的数据量很大,导致分页查询库存导入数据很慢: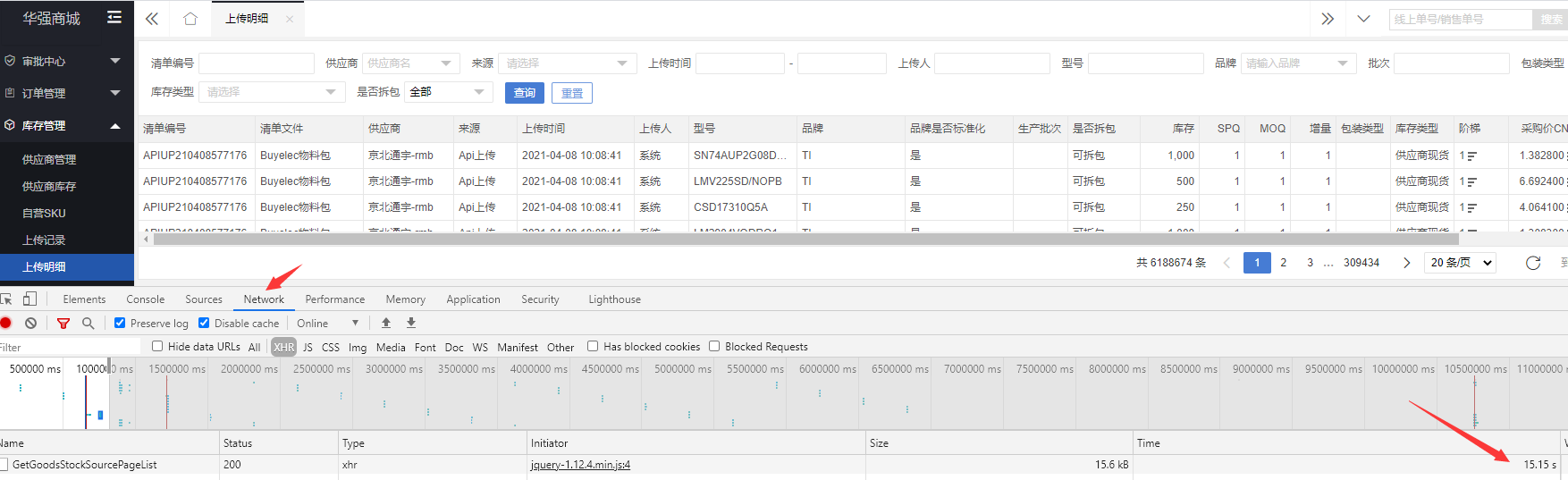
现在业务部门有一具体的需求:希望了解最近30天入库总库存量。针对这一需求我们通过两种方法来得出业务部门想要的结果。
方法1:在goods_stock表上直接进行统计,得出想要的结果:
SELECT SUM(StockQty) AS TotalStockQty FROM goods_stock WHERE CreateTime>ADDDATE(NOW(),-30);

方法2:创建中间表tmp_goods_stock,表结构和源表结构完全相同:
CREATE TABLE `tmp_goods_stock` ( `ID` bigint NOT NULL AUTO_INCREMENT COMMENT '供应商库存ID', `StockGUID` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '用于与子表对应', `Model` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '型号', `Brand` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT '' COMMENT '品牌,标准名称', `LotNO` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NULL DEFAULT '' COMMENT '批次,一般用四位年份+两位周,如:202024', `MinPackageQty` int NOT NULL DEFAULT 0 COMMENT '最小包装量', `PackageUnit` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '包装单位,包装类型', `StockQty` int NOT NULL DEFAULT 0 COMMENT '库存量,数量单位:PCS', `MinOrderQty` int NOT NULL DEFAULT 0 COMMENT '最小起订量', `IncQty` int NOT NULL DEFAULT 0 COMMENT '增量', `StockType` smallint NOT NULL COMMENT '物料类型 10:供应商现货 20供应商排单 30 云仓现货', `CreateTime` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0), `UpdateTime` datetime(0) NOT NULL DEFAULT CURRENT_TIMESTAMP(0), PRIMARY KEY (`ID`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 424449 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '商品库存信息,供应商物料库存' ROW_FORMAT = Dynamic;
转移要统计的数据到中间表,然后在中间表上进行统计,得出想要的结果:
INSERT INTO tmp_goods_stock SELECT * FROM goods_stock WHERE CreateTime>ADDDATE(NOW(),-30);

SELECT SUM(StockQty) AS TotalStockQty FROM tmp_goods_stock;
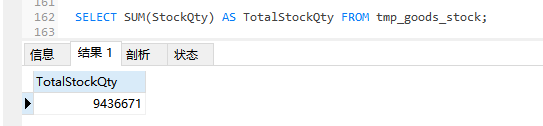
从上面的两种实现方法上看,在中间表中做统计花费的时间很少(这里不计算转移数据花费的时间),另外,针对业务部门想了解“希望了解最近30天入库总库存量”这一需求,在中间表上给出统计结果更为合适,原因是源数据表(goods_stock表)CreateTime字段并没有索引并且源表的数据量较大,所以在按时间进行分时段统计时效率很低,这时可以在中间表上对CreateTime字段创建单独的索引来提高统计查询的速度。中间表在统计查询中经常会用到,其优点如下:
●中间表复制源表部分数据,并且与源表相“隔离”,在中间表上做统计查询不会对在线应用程序产生负面影响。
●中间表上可以灵活的添加索引或增加临时用的新字段,从而达到提高统计查询效率和辅助统计查询作用。
6.总结
本章节介绍了对数据库对象的优化,数据库对象设计的好坏是一个数据库设计的基础,而且一旦数据库对象设计完毕并投入使用,将来再进行修改就比较麻烦,因此在进行数据库设计的时候一定要尽可能地考虑周到。
参考文献:
深入浅出MySQL大全
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


