
Shuffle的深入理解
什么是Shuffle,本意为洗牌,在数据处理领域里面,意为将数打散。
问题:shuffle一定有网络传输吗?有网络传输的一定是Shuffle吗?
Shuffle的概念
通过网络将数据传输到多台机器,数据被打散,但是有网络传输,不一定就有shuffle,Shuffle的功能是将具有相同规律的数据按照指定的分区器的分区规则,通过网络,传输到指定的机器的一个分区中,需要注意的是,不是上游的Task发送给下游的Task,而是下游的Task到上游拉取数据。
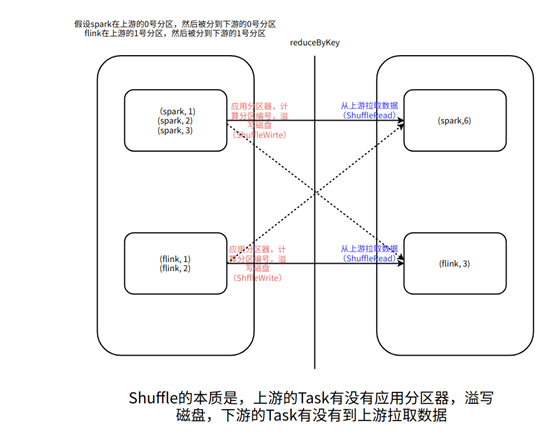
reduceByKey一定会Shuffle吗
不一定,如果一个RDD事先使用了HashPartitioner分区先进行分区,然后再调用reduceByKey方法,使用的也是HashPartitioner,并且没有改变分区数量,调用redcueByKey就不shuffle
如果自定义分区器,多次使用自定义的分区器,并且没有改变分区的数量,为了减少shuffle的次数,提高计算效率,需要重新自定义分区器的equals方法
例如:
//创建RDD,并没有立即读取数据,而是触发Action才会读取数据
val lines = sc.textFile("hdfs://node-1.51doit.cn:9000/words")
val wordAndOne = lines.flatMap(_.split(" ")).map((_, 1))
//先使用HashPartitioner进行partitionBy
val partitioner = new HashPartitioner(wordAndOne.partitions.length)
val partitioned = wordAndOne.partitionBy(partitioner)
//然后再调用reduceByKey
val reduced: RDD[(String, Int)] = partitioned.reduceByKey(_ + _)
reduced.saveAsTextFile("hdfs://node-1.51doit.cn:9000/out-36-82")

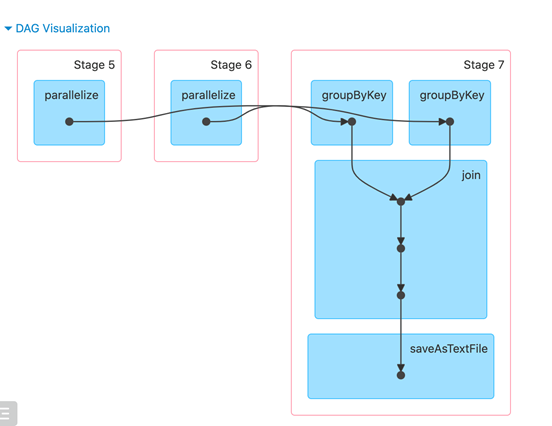
join一定会Shuffle吗
不一定,join一般情况会shuffle,但是如果两个要join的rdd实现都使用相同的分区去进行分区了,并且join时,依然使用相同类型的分区器,并且没有改变分区数据,那么不shuffle
//通过并行化的方式创建一个RDD
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2)), 2)
//通过并行化的方式再创建一个RDD
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2), ("jerry", 4)), 2)
//该join一定有shuffle,并且是3个Stage
val rdd3: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
val rdd11 = rdd1.groupByKey()
val rdd22 = rdd2.groupByKey()
//下面的join,没有shuffle
val rdd33 = rdd11.join(rdd22)
rdd33.saveAsTextFile("hdfs://node-1.51doit.cn:9000/out-36-86")
shuffle数据的复用
spark在shuffle时,会应用分区器,当读取达到一定大小或整个分区的数据被处理完,会将数据溢写磁盘磁盘(数据文件和索引文件),溢写持磁盘的数据,会保存在Executor所在机器的本地磁盘(默认是保存在/temp目录,也可以配置到其他目录),只要application一直运行,shuffle的中间结果数据就会被保存。如果以后再次触发Action,使用到了以前shuffle的中间结果,那么就不会从源头重新计算而是,而是复用shuffle中间结果,所有说,shuffle是一种特殊的persist,以后再次触发Action,就会跳过前面的Stage,直接读取shuffle的数据,这样可以提高程序的执行效率。
广播变量
广播变量的使用场景
在很多计算场景,经常会遇到两个RDD进行JOIN,如果一个RDD对应的数据比较大,一个RDD对应的数据比较小,如果使用JOIN,那么会shuffle,导致效率变低。广播变量就是将相对较小的数据,先收集到Driver,然后再通过网络广播到属于该Application对应的每个Executor中,以后处理大量数据对应的RDD关联数据,就不用shuffle了,而是直接在内存中关联已经广播好的数据,即通实现mapside join,可以将Driver端的数据广播到属于该application的Executor,然后通过Driver广播变量返回的引用,获取实现广播到Executor的数据
广播变量的特点:广播出去的数据就无法在改变了,在没有Executor中是只读的操作,在每个Executor中,多个Task使用一份广播变量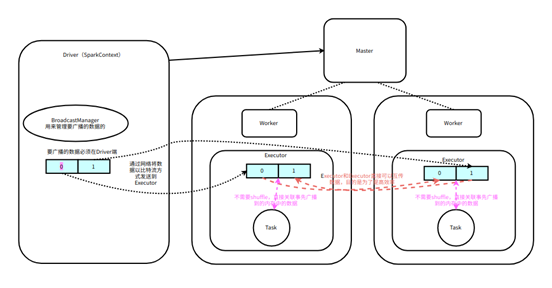
广播变量的实现原理
广播变量是通过BT的方式广播的(TorrentBroadcast),多个Executor可以相互传递数据,可以提高效率
sc.broadcast这个方法是阻塞的(同步的)
广播变量一但广播出去就不能改变,为了以后可以定期的改变要关联的数据,可以定义一个object[单例对象],在函数内使用,并且加一个定时器,然后定期更新数据
广播到Executor的数据,可以在Driver获取到引用,然后这个引用会伴随着每一个Task发送到Executor,然后通过这个引用,获取到事先广播好的数据
序列化问题
序列化问题的场景
spark任务在执行过程中,由于编写的程序不当,任务在执行时,会出序列化问题,通常有以下两种情况,
• 封装数据的Bean没有实现序列化接口(Task已经生成了),在ShuffleWirte之前要将数据溢写磁盘,会抛出异常
• 函数闭包问题,即函数的内部,使用到了外部没有实现序列化的引用(Task没有生成)
数据Bean未实现序列化接口
spark在运算过程中,由于很多场景必须要shuffle,即向数据溢写磁盘并且在网络间进行传输,但是由于封装数据的Bean没有实现序列化接口,就会导致出现序列化的错误!
object C02_CustomSort {
def main(args: Array[String]): Unit = {
val sc = SparkUtil.getContext(this.getClass.getSimpleName, true)
//使用并行化的方式创建RDD
val lines = sc.parallelize(
List(
"laoduan,38,99.99",
"nianhang,33,99.99",
"laozhao,18,9999.99"
)
)
val tfBoy: RDD[Boy] = lines.map(line => {
val fields = line.split(",")
val name = fields(0)
val age = fields(1).toInt
val fv = fields(2).toDouble
new Boy(name, age, fv) //将数据封装到一个普通的class中
})
implicit val ord = new Ordering[Boy] {
override def compare(x: Boy, y: Boy): Int = {
if (x.fv == y.fv) {
x.age - y.age
} else {
java.lang.Double.compare(y.fv, x.fv)
}
}
}
//sortBy会产生shuffle,如果Boy没有实现序列化接口,Shuffle时会报错
val sorted: RDD[Boy] = tfBoy.sortBy(bean => bean)
val res = sorted.collect()
println(res.toBuffer)
}
}
//如果以后定义bean,建议使用case class
class Boy(val name: String, var age: Int, var fv: Double) //extends Serializable
{
override def toString = s"Boy($name, $age, $fv)"
}
函数闭包问题
闭包的现象
在调用RDD的Transformation和Action时,可能会传入自定义的函数,如果函数内部使用到了外部未被序列化的引用,就会报Task无法序列化的错误。原因是spark的Task是在Driver端生成的,并且需要通过网络传输到Executor中,Task本身实现了序列化接口,函数也实现了序列化接口,但是函数内部使用到的外部引用不支持序列化,就会函数导致无法序列化,从而导致Task没法序列化,就无法发送到Executor中了
在调用RDD的Transformation或Action是传入函数,第一步就进行检测,即调用sc的clean方法
为了避免错误,在Driver初始化的object或class必须实现序列化接口,不然会报错误
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f) //检测函数是否可以序列化,如果可以直接将函数返回,如果不可以,抛出异常
new MapPartitionsRDD[U, T](this, (_, _, iter) => iter.map(cleanF))
}
private def ensureSerializable(func: AnyRef): Unit = {
try {
if (SparkEnv.get != null) {
//获取spark执行换的的序列化器,如果函数无法序列化,直接抛出异常,程序退出,根本就没有生成Task
SparkEnv.get.closureSerializer.newInstance().serialize(func)
}
} catch {
case ex: Exception => throw new SparkException("Task not serializable", ex)
}
}
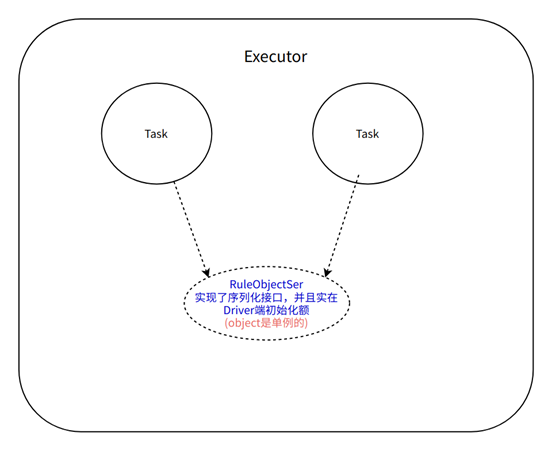
在Driver端初始化实现序列化的object
在一个Executor中,多个Task使用同一个object对象,因为在scala中,object就是单例对象,一个Executor中只有一个实例,Task会反序列化多次,但是引用的单例对象只反序列化一次
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//函数外部定义的一个引用类型(变量)
//RuleObjectSer是一个静态对象,实在第一次使用的时候被初始化了(实在Driver被初始化的)
val rulesObj = RuleObjectSer
//函数实在Driver定义的
val func = (line: String) => {
val fields = line.split(",")
val id = fields(0).toInt
val code = fields(1)
val name = rulesObj.rulesMap.getOrElse(code, "未知") //闭包
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesObj.toString)
}
//处理数据,关联维度
val res = lines.map(func)
res.saveAsTextFile(args(2))
在Driver端初始化实现序列化的class
在一个Executor中,每个Task都会使用自己独享的class实例,因为在scala中,class就是多例,Task会反序列化多次,每个Task引用的class实例也会被序列化
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//函数外部定义的一个引用类型(变量)
//RuleClassNotSer是一个类,需要new才能实现(实在Driver被初始化的)
val rulesClass = new RuleClassSer
//处理数据,关联维度
val res = lines.map(e => {
val fields = e.split(",")
val id = fields(0).toInt
val code = fields(1)
val name = rulesClass.rulesMap.getOrElse(code, "未知") //闭包
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesClass.toString)
})
res.saveAsTextFile(args(2))
在函数内部初始化未序列化的object
object没有实现序列化接口,不会出现问题,因为该object实现函数内部被初始化的,而不是在Driver初始化的
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//不再Driver端初始化RuleObjectSer或RuleClassSer
//函数实在Driver定义的
val func = (line: String) => {
val fields = line.split(",")
val id = fields(0).toInt
val code = fields(1)
//在函数内部初始化没有实现序列化接口的RuleObjectNotSer
val name = RuleObjectNotSer.rulesMap.getOrElse(code, "未知")
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, RuleObjectNotSer.toString)
}
//处理数据,关联维度
val res = lines.map(func)
res.saveAsTextFile(args(2))
sc.stop()

在函数内部初始化未序列化的class
这种方式非常不好,因为每来一条数据,new一个class的实例,会导致消耗更多资源,jvm会频繁GC
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//处理数据,关联维度
val res = lines.map(e => {
val fields = e.split(",")
val id = fields(0).toInt
val code = fields(1)
//RuleClassNotSer是在Executor中被初始化的
val rulesClass = new RuleClassNotSer
//但是如果每来一条数据new一个RuleClassNotSer,不好,效率低,浪费资源,频繁GC
val name = rulesClass.rulesMap.getOrElse(code, "未知")
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesClass.toString)
})
res.saveAsTextFile(args(2))
调用mapPartitions在函数内部初始化未序列化的class
一个分区使用一个class的实例,即每个Task都是自己的class实例
//从HDFS中读取数据,创建RDD
//HDFS指定的目录中有4个小文件,内容如下:
//1,ln
val lines = sc.textFile(args(1))
//处理数据,关联维度
val res = lines.mapPartitions(it => {
//RuleClassNotSer是在Executor中被初始化的
//一个分区的多条数据,使用同一个RuleClassNotSer实例
val rulesClass = new RuleClassNotSer
it.map(e => {
val fields = e.split(",")
val id = fields(0).toInt
val code = fields(1)
val name = rulesClass.rulesMap.getOrElse(code, "未知")
//获取当前线程ID
val treadId = Thread.currentThread().getId
//获取当前Task对应的分区编号
val partitiondId = TaskContext.getPartitionId()
//获取当前Task运行时的所在机器的主机名
val host = InetAddress.getLocalHost.getHostName
(id, code, name, treadId, partitiondId, host, rulesClass.toString)
})
})
res.saveAsTextFile(args(2))
sc.stop()
Task线程安全问题
在一个Executor可以同时运行多个Task,如果多个Task使用同一个共享的单例对象,如果对共享的数据同时进行读写操作,会导致线程不安全的问题,为了避免这个问题,可以加锁,但效率变低了,因为在一个Executor中同一个时间点只能有一个Task使用共享的数据,这样就变成了串行了,效率低!
定义一个工具类object,格式化日期,因为SimpleDateFormat线程不安全,会出现异常
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[*]") //本地模式,开多个线程
//1.创建SparkContext
val sc = new SparkContext(conf)
val lines = sc.textFile("data/date.txt")
val timeRDD: RDD[Long] = lines.map(e => {
//将字符串转成long类型时间戳
//使用自定义的object工具类
val time: Long = DateUtilObj.parse(e)
time
})
val res = timeRDD.collect()
println(res.toBuffer)
object DateUtilObj {
//多个Task使用了一个共享的SimpleDateFormat,SimpleDateFormat是线程不安全
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//线程安全的
//val sdf: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss")
def parse(str: String): Long = {
//2022-05-23 11:39:30
sdf.parse(str).getTime
}
}
上面的程序会出现错误,因为多个Task同时使用一个单例对象格式化日期,报错,如果加锁,程序会变慢,改进后的代码:
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[*]") //本地模式,开多个线程
//1.创建SparkContext
val sc = new SparkContext(conf)
val lines = sc.textFile("data/date.txt")
val timeRDD = lines.mapPartitions(it => {
//一个Task使用自己单独的DateUtilClass实例,缺点是浪费内存资源
val dataUtil = new DateUtilClass
it.map(e => {
dataUtil.parse(e)
})
})
val res = timeRDD.collect()
println(res.toBuffer)
class DateUtilClass {
val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
def parse(str: String): Long = {
//2022-05-23 11:39:30
sdf.parse(str).getTime
}
}
改进后,一个Task使用一个DateUtilClass实例,不会出现线程安全的问题。
累加器
累加器是Spark中用来做计数功能的,在程序运行过程当中,可以做一些额外的数据指标统计
触发一次Action,并且将附带的统计指标计算出来,可以使用Accumulator进行处理,Accumulator的本质数一个实现序列化接口class,每个Task都有自己的累加器,避免累加的数据发送冲突
object C14_AccumulatorDemo3 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[*]") //本地模式,开多个线程
//1.创建SparkContext
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
//在Driver定义一个特殊的变量,即累加器
//Accumulator可以将每个分区的计数结果,通过网络传输到Driver,然后进行全局求和
val accumulator: LongAccumulator = sc.longAccumulator("even-acc")
val rdd2 = rdd1.map(e => {
if (e % 2 == 0) {
accumulator.add(1) //闭包,在Executor中累计的
}
e * 10
})
//就触发一次Action
rdd2.saveAsTextFile("out/113")
//每个Task中累计的数据会返回到Driver吗?
println(accumulator.count)
}
}
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


