
为让学校统计学社的同学了解python在数据处理方面的功能,将手游模拟城市的工厂生产进行建模,让同学在建模与处理非结构数据的过程中学习和了解python。将准备的内容放在此让更多需要的人特别是统计人(准备时是按照统计学生的平时会遇到的问题准备的)学习。
首先是模拟城市这款手游

它的一个非常令人头秃之处是等级高时非常缺金币,而要在游戏内获取基本只能通过生产商品并出售。我们要做的是分析可以生产的商品,计算生产每种商品增加值以及结合各生产部门生产能力寻找出单位时间内能生产出价值最高的产品组合。
一、基本分析
我们所有的讨论都是基于这个游戏等级为10级的情况。十级时共有5个生产部门,包括工厂(生产原材料如:铁、木、塑料等)、材料厂、工具厂、家具厂、农贸厂。每个部门生产的产品都需要耗费时间都有一定的价格,除了工厂生产的原材料其他部门生产的产品都需要原料合成,于是,我们可以得到这些部门生产产品的基本信息(在实际经济的核算中我们也会得到各种不同形式的原始数据,一下面的表格为例进行分析)。
工厂:生产铁、木头、塑料、和种子
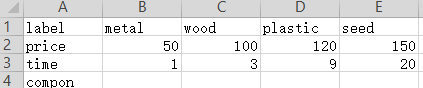
材料厂:生产木板和钉子,他们分别消耗两个木头和两个铁
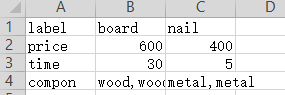
材料厂:生产榔头、卷尺和铲子

家具厂:生产椅子,需耗费两个木头、一个榔头和一个钉子

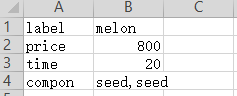
农贸厂:生产果蔬需耗费两个种子
数据很少很简单,但处理这种广义表结构的数据值得我们练习
二、计算所有产品增加值
#导入pandas和numpy包,这两个包是数据处理最常用的包
import pandas as pd
import numpy as np
#构建字典来存储不同部门生产的不同商品每个商品都含有三个属性:价格、耗费时间、组成成分
'''rooms={'instrum':{'hammer':{'price':450,'time':1,'compon':['Fe','wood']}},
'materl':{'nail':{'price':400,'time':2,'compon':['Fe','Fe']}},
'elem':{'Fe':{'price':50,'time':3,'compon':[]},'wood':{'price':1,'time':1,'compon':[]},'seed':
{'price':1,'time':1,'compon':[]}}}
我们需要把excel中的数据转化成这种字典
'''
#每个部门的数据被存储在excel的一个sheet中,read_excel的sheet参数取None得到一个panel其键为sheet名。
data=pd.read_excel('result.xls',None)
rooms={}
for sheet in data.keys():
print(sheet)
df=pd.read_excel('result.xls',sheet,index_col =0)
tools={}
for name in df.columns:
labels={}
for idx in df.index:
if idx=='compon':
try:
labels[idx]=df[name][idx].split(',')
print(labels[idx])
except:
labels[idx]=['nan']
else:
labels[idx]=df[name][idx]
tools[name]=labels
rooms[sheet]=tools
#为方面我们后面使用,创建一个字典存放产品是属于哪个部门的
fromdic={}
for i in rooms:
for j in rooms[i]:
fromdic[str(j)]=i
#计算各产品增加值,得到一个以产品名为主码属性包含增加值的表
df={}
time,price,add,name=[],[],[],[]
room1,room2,room3,room4,room5=[],[],[],[],[]
for room in rooms:
for tools in rooms[room]:
toolsdic=rooms[room][tools]
for i in rooms:
occdic[i] = 0
time.append(rooms[room][tools]['time'])
price.append(rooms[room][tools]['price'])
sump=[]
occdic[fromdic[tools]] = rooms[room][tools]['time']
if tools not in rooms['factory']:
add.append(rooms[room][tools]['price']-np.sum([rooms[fromdic[i]][i]['price'] for i in rooms[room][tools]['compon']]))
for comp in rooms[room][tools]['compon']:
occdic[fromdic[comp]] += rooms[fromdic[comp]][comp]['time']
if comp in rooms['factory']:
pass
else:
for i in rooms[fromdic[comp]][comp]['compon']:
occdic[fromdic[i]] += rooms[fromdic[i]][i]['time']
else:
add.append(rooms[room][tools]['price']-0)
name.append(str(tools))
df['time']=time
df['price']=price
df['addition'] = add
df['name']=name
三、计算生产每种商品的收益和成本(cost)
我们的目的是找出单位时间内赚金币最快的生产组合,可以思考一下当我们生产椅子时耗费了什么。首先需要占据椅子店一定的时间,然后要耗费一个锤子、一个钉子和两个木头,每生产一个椅子我们其实必须生产一个锤子、一个钉子和两个木头。
所以我们可以把椅子分解为一个抽象的家具A加它的组成产品(家具A没有组成材料且价格为椅子增加值,生产家具A要且只要耗费家具厂生产一个椅子的时间),那么我们生产的椅子其实是一个产品集合即{锤子,钉子,2*木头,家具A}。我们生产锤子和钉子又分别耗费工具店的一定时间、一木一铁和材料店的一定时间、两铁,
我们又可以把锤子和钉子分别分解为{工具A,木头,铁}{材料A,2*铁},其中工具A是抽象的工具不耗费材料价格为锤子的增加值且生产它要耗费工具厂生产一个锤子的时间。最后我们可以把铁、木头等价表示为{工厂A、工厂B}生产他们分别要耗费工厂生产一个铁和一个木头的时间。那么椅子就可以分解为集合{工具A,材料A,家具A,3*工厂A,3*工厂B},集合中给工具A、材料A、家具A表示生产椅子实质会占用这三个部门生产时间。
于是我们可以把每种产品都写成它占据各部门时间的集合。
occdic={}
for i in rooms:
occdic[i]=0
df=pd.DataFrame(df)
df={}
time,price,add,name=[],[],[],[]
room1,room2,room3,room4,room5=[],[],[],[],[]
for room in rooms:
for tools in rooms[room]:
toolsdic=rooms[room][tools]
for i in rooms:
occdic[i] = 0
time.append(rooms[room][tools]['time'])#此处先记直接占用部门的时间
price.append(rooms[room][tools]['price'])
sump=[]
occdic[fromdic[tools]] = rooms[room][tools]['time']
if tools not in rooms['factory']:
for comp in rooms[room][tools]['compon']:
occdic[fromdic[comp]] += rooms[fromdic[comp]][comp]['time']#此处记录间接占用部门的时间
if comp in rooms['factory']:
pass
else:
for i in rooms[fromdic[comp]][comp]['compon']:
occdic[fromdic[i]] += rooms[fromdic[i]][i]['time']
name.append(str(tools))
room1.append(occdic['instrum'])
room2.append(occdic['metrl'])
room3.append(occdic['factory'])
room4.append(occdic['vegatable'])
room5.append(occdic['furnit'])
df['time']=time
df['price']=price
df['name']=name
df['instrum']=room1
df['metrl']=room2
df['factory']=room3
df['vegatable']=room4
df['furnit']=room5
四、总结
最终我们得到了一个含有各种产品增加值、占用各部门时间的数据框。
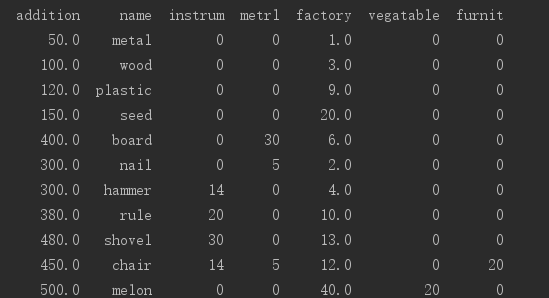
有了这个数据框我们就可以根据提炼出的信息寻优找到在给定部门使用时间内生产总值最大的产品组合。因为这个问题本质是一个限制条件下求极大值问题,对于真实情况我们可以选择各种算法比如遗传算法、随机森林、神经网络等等,当然对于我们这个小规模的问题甚至可以枚举选出收益最大的组合。
所以本文主要是对不那么结构化的数据进行处理是我们后面的数据分析更加方便简单,希望对学习用python做数据分析的人有帮助。
内容来源于网络如有侵权请私信删除
- 还没有人评论,欢迎说说您的想法!



 客服
客服


