
MapReduce原理
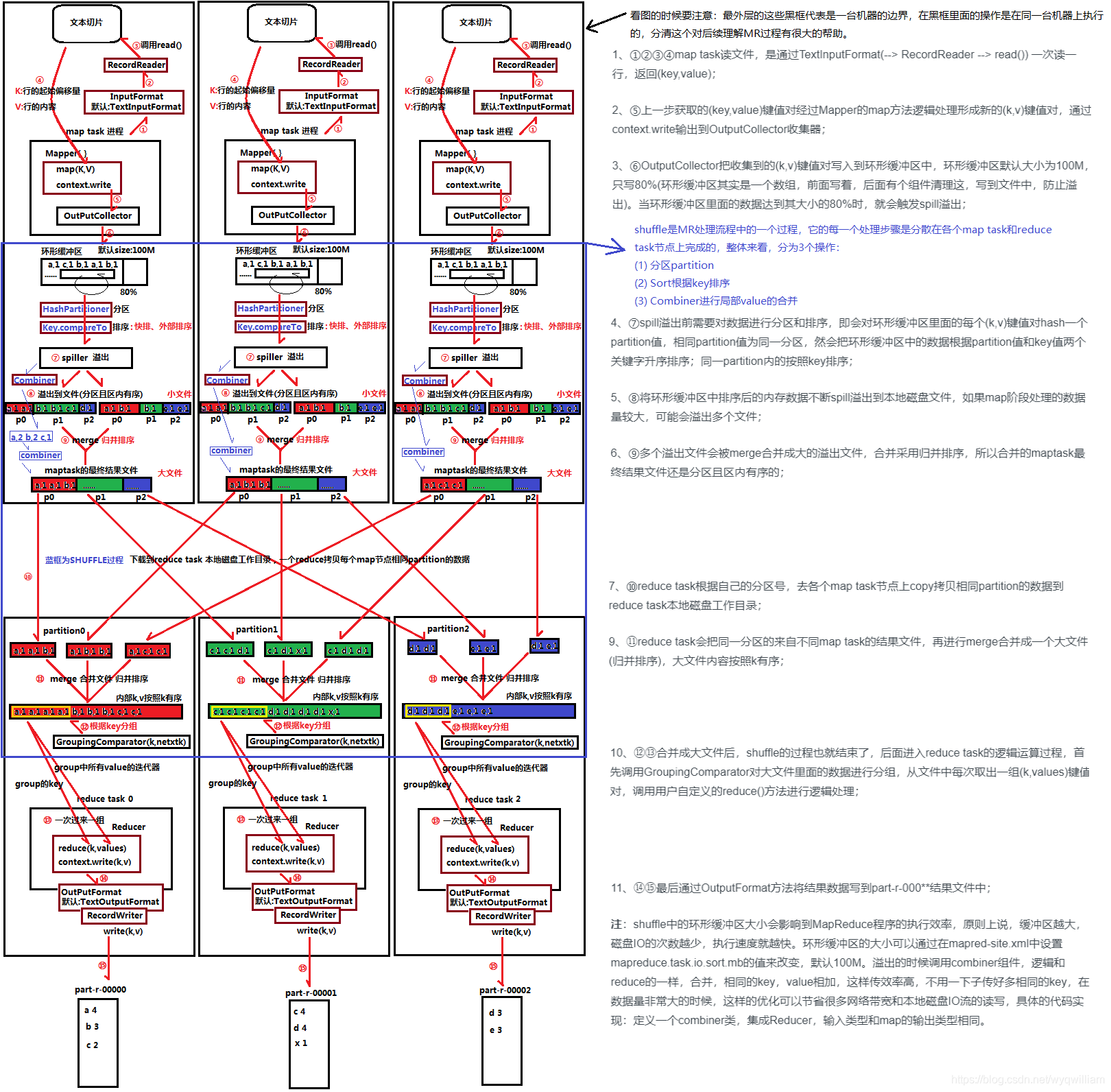

Map阶段
- 文件在被读取(调用read())的是用Inputformat方法读入的。在这里读入一行,返回一个key-vlaue(K,V)对,key是行号的偏移量,value的值是这一行的内容。
- 在上述过程中,在第4步调用map()方法后,将以上内容真正转换成(key,value)的形式,key为值,value为1,然后调用context.write方法将该数据写出来
- 经过outputcollector收集器之后会写入环形缓冲区。在环形缓冲区会做如下几件事
- 排序,调用的是快速排序法
- 分区,调用的 hashpartitioner分区。达到80%之后会溢出将文件写到磁盘。相同的hash值会分到一个分区中,可以认为设定分区数。排序的时候是依据partition和key两个来作为依据的。同一个partition中是按照key进行排序的
- 第7步:环形缓冲区spill溢写到磁盘中,会溢出多次到不同的分区中,之后会进行merge,并进行归并排序。将多个小文件合并成大文件,所以合并之后的大文件还是分区,并且分区内部是有序的
- Combiner阶段是可选项,形式上也是一种reduce操作。在这个过程中可以直接让相同key的value进行聚合(相加等),减少数据量以及在网络中传输的开销,能大大提高效率
Reduce阶段
- Reduce阶段会去map阶段merge之后的文件中拿数据,按照相同的分区去取数据。reduce中有分区号,将数据拿过来之后会存储在本地磁盘。此过程会进行I/O读写,并有相应的网络传输
- 拿到数据后,会按照相同的分区,再将取过来的数据进行merge归并排序,大文件的内容按照key有序进行排序
- 之后会调用 groupingcomparator 进行分组,之后的reduce中会按照这个分组,每次取出一组数据,调用reduce中自定义方法进行处理
- 最后调用outputformat将内容写入到文件中
Shuffle阶段
- 核心机制:数据分区,排序,缓存,分发

针对MR原理进行HIVE优化
- 优化总体思路就是减少数据倾斜,降低I/O,降低网络传输量
- 数据倾斜:是指在shuffle的过程中,把大量相同的key分到了一个Reduce节点上进行处理,其他的key分到其他Reduce节点上,导致Reduct Task处理完后,还有一个Reduct Task节点还在处理数据。最终导致整个Reduce的延迟情况
- 采用分而治之的方式,在Sql层面,通过改写Sql进行优化
环形缓冲区默认100M,mr.sort.mb=100M
参考链接:
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


