
前戏
一、 知识储备
1.函数 : def args kwargs
def func(参数1,参数2): # def 用来定义函数及函数名,参数1和参数2就是定义时的形参,也就是将来调用函数时必须要传入的参数 变量1 = 参数1+参数2 return 变量1
# *args 就是 将未定义且多余的 位置参数记录在内,偷偷的告诉你,args是个元祖,里面记录着你个函数传递的多余位置参数 # **kwargs 就是 将多余的关键字参数记录在内,kwargs 其实是个dict哦,里面大概就是{"name":"python","age":1+1+1+1+1+1+18}
def args_func(a,b,*args): # args 里面保存着除了ab之外的所有多余参数 print(args) # 这回知道是元组了吧 for i in args: print(i) args_func(1,2,3,4,5,6) # 这里调用的时候1,2分别传递给a,b,那么3456就会保存在args里面哦
def kwargs_func(a, b, **kwargs): # kwargs 里面保存着除了ab之外其他关键字传入参的参数 print(kwargs) # 这回知道是字典了吧 for k, v in kwargs: print(k, v) kwargs_func(1, 2, c=3, d=4, e=5) # 这里调用的时候,12分别传递给a,b 那么c=3,d=4,e=5 就会保存在**kwargs里面哦
def args_kwargs_func(*args, **kwargs): # 这里一定要注意*args 要在 **kwargs之前 print(args) print(kwargs) args_kwargs_func(1, 2, a=1, b=2) # 12存入args a=1,b=2 存入kwargs,这里要注意的是关键字传参之后,不可以在位置传参了
2.推导式
两个栗子:
2.1 列表推导式:
li = [i for i in range(10)] # 简单的列表推导式,就是在列表内写一个for循环对吧 print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] lis = [i for i in range(10) if i % 2 == 0] # 这是带if 条件的列表推导式 print(lis) # [0, 2, 4, 6, 8
2.2 生成器推导式:
gener = (i for i in range(10)) # 简单的生成器推导式,就是在元组内写一个for循环对吧 print(gener) # <generator object <genexpr> at 0x04F9B3C0> geners = (i for i in range(10) if i % 2 == 0) # 这是带if 条件的生成器推导式 print(geners) # <generator object <genexpr> at 0x04F9B3F0>
从上述来看,列表推导式和生成器推导式只是[] 与 () 的区别
但是实际上,生成器推导式的效率非常高,但可控性很差,比如不直观,用一次就没了
相对而言列表推导式的效率比较低,但是可控性强,可以反复利用,而且数据显示很直观
3.模块
字符串之json模块
import json # 我们做一个字典 dic = { "name": "Dragon", "age": 20, "hobby": ["摩托车", "骑车"], "other": { "say": "hello", "see": "beautiful girl", } } json_dic = json.dumps(dic) # json序列化 print(type(json_dic), json_dic) # <class 'str'> {"name": "Dragon", "age": 20, "hobby": ["u6469u6258u8f66", "u9a91u8f66"], "other": {"say": "hello", "see": "beautiful girl"}} loads_dic = json.loads(json_dic) # json 反序列化 print(type(loads_dic), loads_dic) # <class 'dict'> {'name': 'Dragon', 'age': 20, 'hobby': ['摩托车', '骑车'], 'other': {'say': 'hello', 'see': 'beautiful girl'}}
os模块,集成了很多操作系统的方法,比如创建文件夹,拼接路径,删除文件,创建文件等等
import os os.path.join("a","b") # 组合路径 a/b os.system("ls") # 执行系统命令 os.sep() # 获取当前操作系统的路径分隔符 os.path.dirname(__file__) # 获取当前文件的所在目录
os补充:
import os os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd os.curdir() # 返回当前目录: ('.') os.pardir() # 获取当前目录的父目录字符串名:('..') os.makedirs('dir1/dir2') # 可生成多层递归目录 os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove("file_name") # 删除一个文件 os.rename("oldname", "new") # 重命名文件/目录 os.stat('path/filename') # 获取文件/目录信息 os.sep() # 操作系统特定的路径分隔符,win下为"\",Linux下为"/" os.linesep() # 当前平台使用的行终止符,win下为"tn",Linux下为"n" os.pathsep() # 用于分割文件路径的字符串 os.name() # 字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") # 运行shell命令,直接显示 os.environ() # 获取系统环境变量 os.path.abspath(path) # 返回path规范化的绝对路径 os.path.split(path) # 将path分割成目录和文件名二元组返回 os.path.dirname(path) # 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) # 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) # 如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) # 如果path是绝对路径,返回True os.path.isfile(path) # 如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) # 如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) # 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) # 返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) # 返回path所指向的文件或者目录的最后修改时间
4.文件操作
f = open("123.txt","rb") #打开文件句柄 print(f.read()) # 读取文件内容 f.close() # 关闭文件句柄
打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
打开文件的模式有:
- r ,只读模式【默认】
- w,只写模式【不可读;不存在则创建;存在则清空内容;】
- x, 只写模式【不可读;不存在则创建,存在则报错】
- a, 追加模式【可读; 不存在则创建;存在则只追加内容;】
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型
# 文件上下文操作 with open("123.txt","rb") as f: # 文件句柄f 自动打开关闭文件句柄 f.read() # 读取文件内容(全部) with open("123.txt","rb") as f: f.read() #读取文件内容(全部) f.readline() # 读取文件中一行文件 f.readlines() # 读取文件中所有行 ["1","2"] f.write("666") # 写入文件内容 f.writelines("666") # 写入一行文件 f.flush()# 刷新文件 f.seek(10) # 移动光标到10位置 f.truncate(6) # 从光标当前位置截取6位 f.tell() # 获取当前光标位置
人工智能底层的择取
预备环境: 1.FFmpeg: 链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密码:w6hk 2.baidu-aip: pip install baidu-aip
此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径
目前失眠上主流的AI技术提供公司有很多,BAT和只能问答的图灵机器人等,另外提一点:主做语音的科大讯飞是佼佼者但它是有偿使用
这里我们采用百度的完全免费接口
开启人工智能技术的大门 : http://ai.baidu.com/
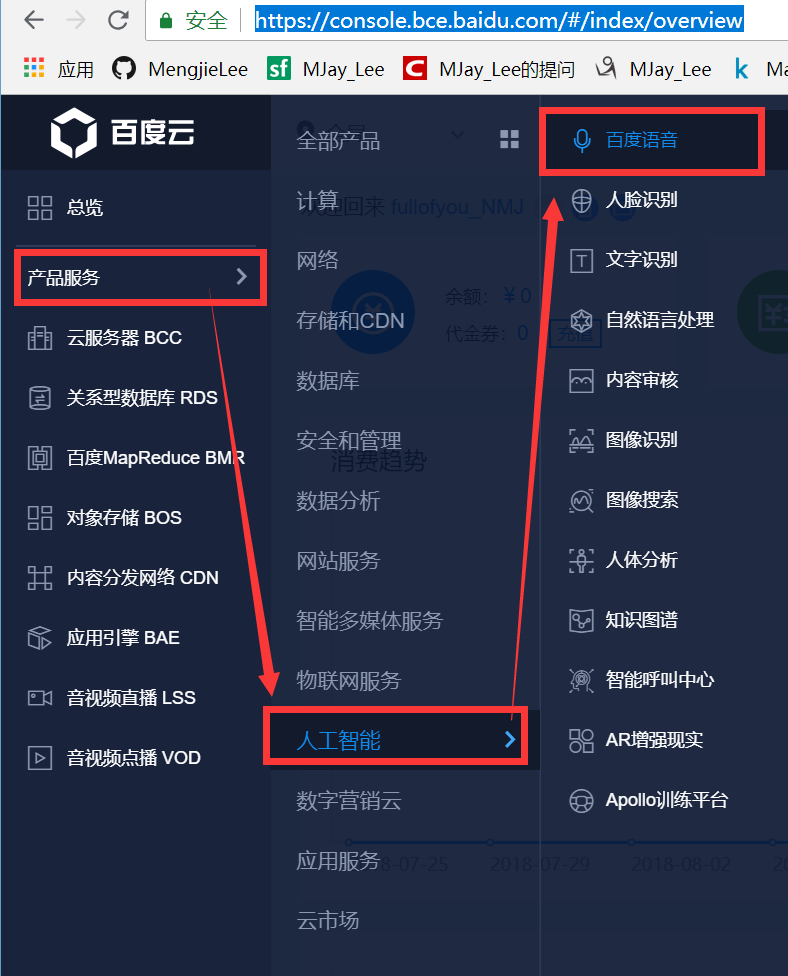
首先进入控制台,注册一个百度的账号(百度账号通用)
开通一下我们百度AI开放平台的授权
然后找到已开通服务中的百度语音
这里省去自行创建应用过程
进入管理应用,牢记下述3个值,后面实例接口时会用上
二、 百度的人工智能SDK:
1.安装SDK与测试
首先咱们要 pip install baidu-aip 安装一个百度人工智能开放平台的Python SDK实在是太方便了,这也是为什么我们选择百度人工智能的最大原因
在工程目录下,就可以看到s1.mp3这个文件了,可用播放器试听效果
上面咱们测试了一个语音合成的例子,那么就从语音合成开始入手
2.语音合成


#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/08/25 18:28 # @Author : MJay_Lee # @File : ai.py # @Contact : limengjiejj@hotmail.com from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11721488' API_KEY = 'RSs9MrcwhhdndG6vLHN9Q9dC' SECRET_KEY = 'RpQwPMiPUYXYNOFb0bmFIHORNj4t6Nb0' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) res = client.synthesis( "智能语音的第一个示例", # text,合成的文本,使用UTF-8编码,请注意文本长度必须小于1024字节 "zh", # lang,语言,中文:zh 英文:en 1, # ctp,客户端信息这里就写1 { # 这是一个dict类型的参数,里面的kv是关键,如下: "vol":5, # 合成音频文件的准音量 "spd":4, # 语速,0~9,默认为5,中语速 "pit":8, # 语调音调,0~9,默认为5,中语调 "per":4, # 发音人选择,0为女声,1为1男声,3为度逍遥,4为度丫丫,默认为普通女声 } ) if not isinstance(res,dict): with open("audio.mp3","wb")as f: f.write(res) else: print(res) ''' # 错误返回示例: { 'err_detail': 'Params error.', 'err_msg': 'parameter error.', 'err_no': 501, 'err_subcode': 29, 'tts_logid': 3204603220 } '''
技术上,代码上的任何疑虑都可以从官方文档中得到答案
baidu-aip Python SDK 语音合成技术文档 : https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top
刚才我们做了一个语音合成的例子,借此可继续展开说明
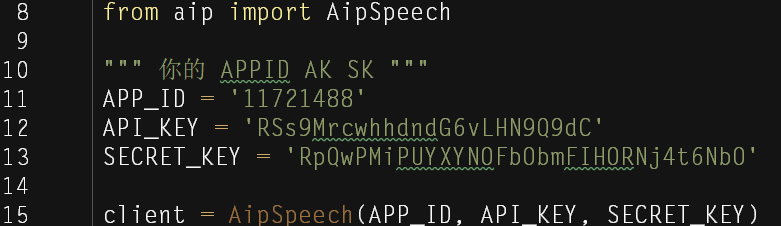
这里与百度进行一次加密校验,认证你是合法用户,合法的应用
AipSpeech 是百度语音的客户端,认证成功之后,客户端都将被开启,这里的client就是已经开启的百度语音的客户端
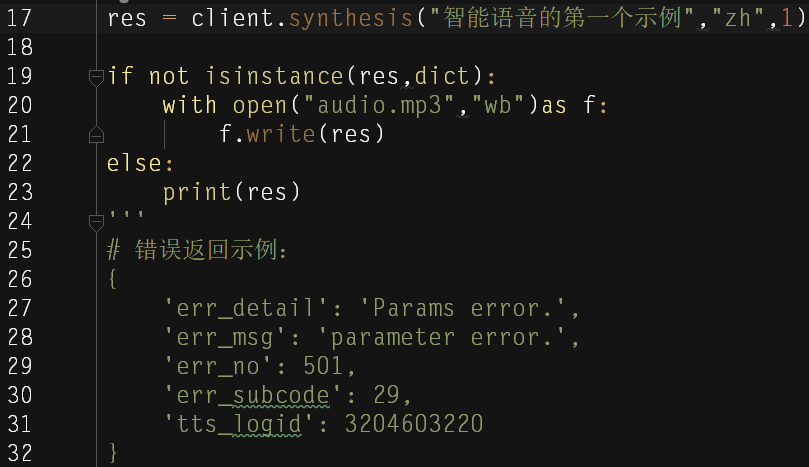
res就是咱们音频文件的byte流
如果失败,res就会是个字典,如上图的 #错误返回示例。
用百度语音客户端中的synthesis方法,并提供相关参数
成功可以得到音频文件,失败则返回一段错误信息
重点看一下 synthesis 这个方法 , 从 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 来获得答案吧
从参数入手分析:

至此,人工只能中的语音合成技术点到为止了。
3.语音识别
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/08/25 18:28 # @Author : MJay_Lee # @File : ai.py # @Contact : limengjiejj@hotmail.com from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11721488' API_KEY = 'RSs9MrcwhhdndG6vLHN9Q9dC' SECRET_KEY = 'RpQwPMiPUYXYNOFb0bmFIHORNj4t6Nb0' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('audio.pcm'), 'pcm', 16000, { 'dev_pid': 1536, }) print(res) ''' # res内容 { 'corpus_no': '6594294686519761176', 'err_msg': 'success.', 'err_no': 0, 'result': ['陈杰陈杰你好'], 'sn': '995932809701535353876' } '''
声音这个东西格式太多样化了,如果要想让百度的SDK识别咱们的音频文件,就要想办法转变成百度SDK可以识别的格式PCM
已知可以实现自动化转换格式并且屡试不爽的工具 : FFmpeg
FFmpeg 环境变量配置:
首先你要解压缩,然后找到bin目录,
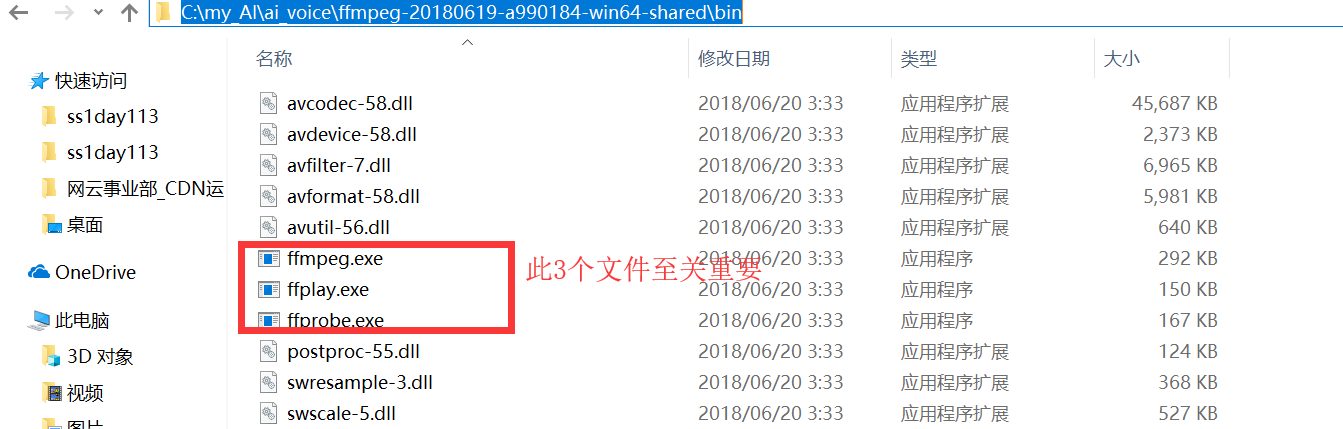
我的目录是 C:my_AIai_voiceffmpeg-20180619-a990184-win64-sharedbin
以window10为例,配置环境变量
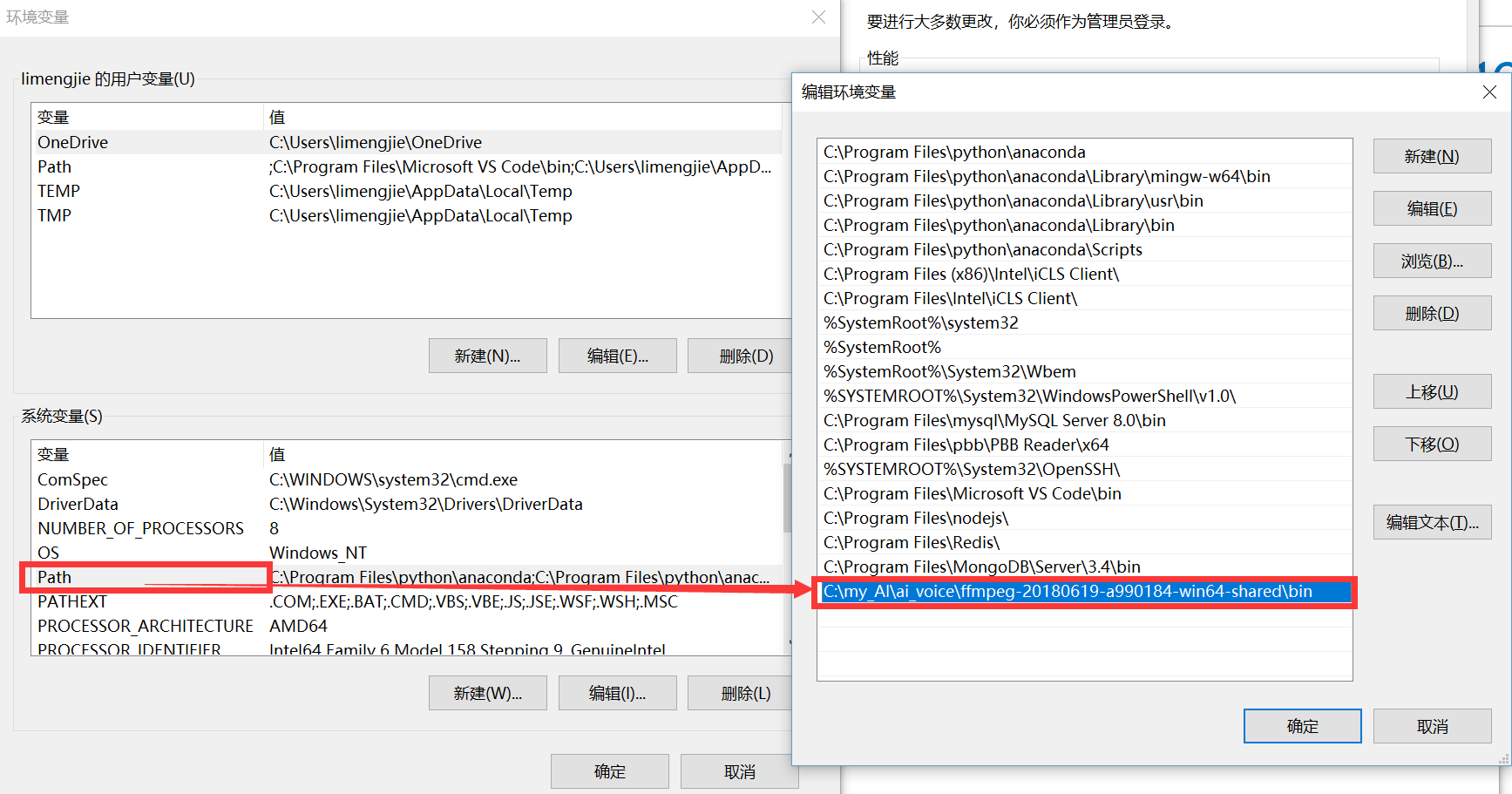
尝试一下是否配置成功
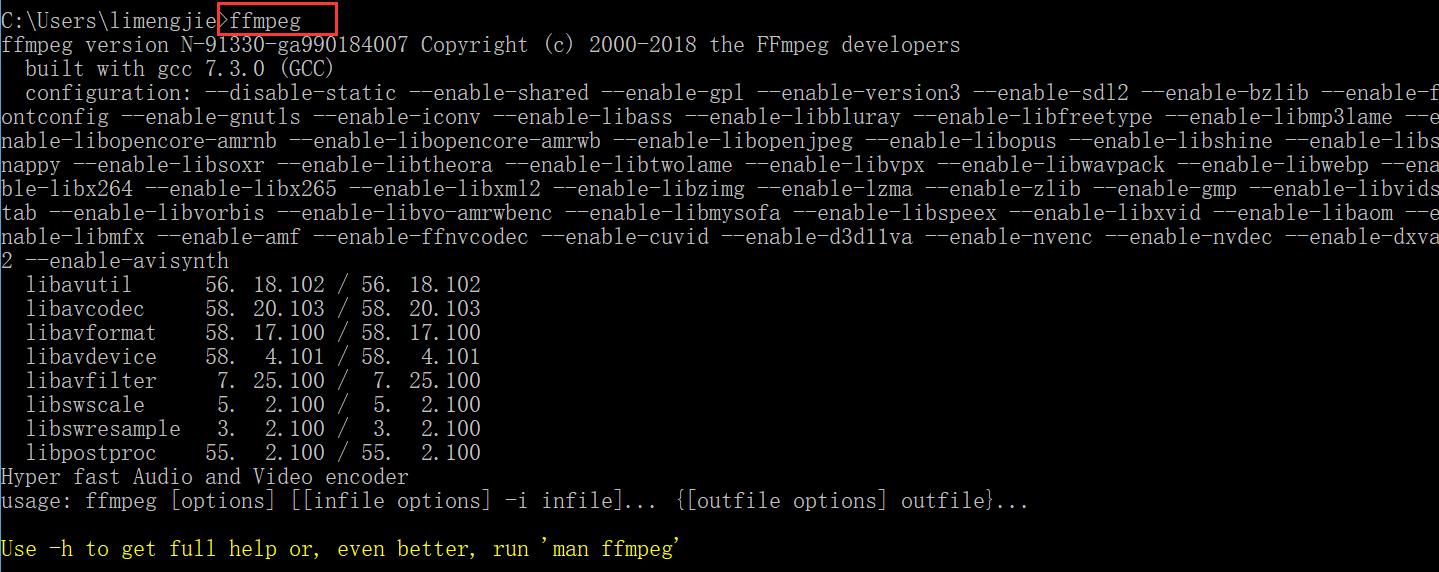
看到这个界面就算配置成功了
ffmpeg 这个工具可以将wav wma MP3 等音频文件转换为pcm无压缩音频文件,测试过程如下:
# 做一个测试,首先要打开windows的录音机,录制一段音频(说普通话) # 现在假设录制的音频文件的名字为 audio.wav 放置在 c:myaudio # 然后我们用命令行对这个 audio.wav 进行pcm格式的转换然后得到 audio.pcm # 命令是 : ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
在录音文件所在目录下,执行上述命令,然后打开目录,就可以看到pcm文件了
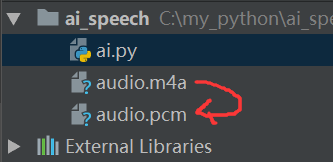
好了,换个环境
以mac为例,配置环境变量
自行安装brew,然后导入ffmpeg
brew install ffmpeg
切换root用户
su root
成功切换至root用户后,添加ffmpeg至环境变量
vim /etc/profile # 进入profile文件,将ffmpeg绝对路径添加至export中,如下: export "PATH=/usr/local/mysql/bin:/anaconda3/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/tools/unrar:/usr/local/Cellar/ffmpeg/4.0.2/bin/ffmpeg"
最后重启服务即可
source /etc/profile
接下来步骤同windows一样,找到目标文件,执行事先制定好的pcm文件命令即可得到我们需要的pcm文件
那么, pcm文件已经得到了,进入正题
百度语音识别SDK的应用:

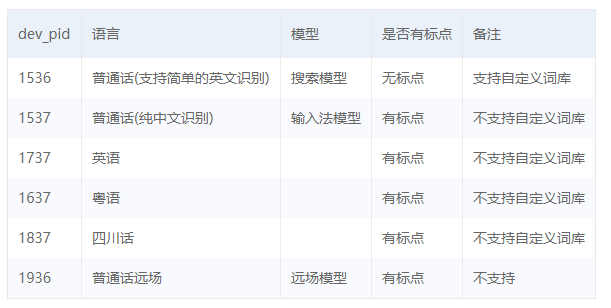
asr函数需要四个参数,第四个参数可以忽略,自有默认值,参照一下这些参数是做什么的
# 第一个参数: speech 音频文件流 建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。(虽说支持这么多格式,但是只有pcm的支持是最好的) # 第二个参数: format 文件的格式,包括pcm(不压缩)、wav、amr (虽说支持这么多格式,但是只有pcm的支持是最好的) # 第三个参数: rate 音频文件采样率 如果使用刚刚的FFmpeg的命令转换的,你的pcm文件就是16000 # 第四个参数: dev_pid 音频文件语言id 默认1537(普通话 输入法模型)
最后再看看返回结果:
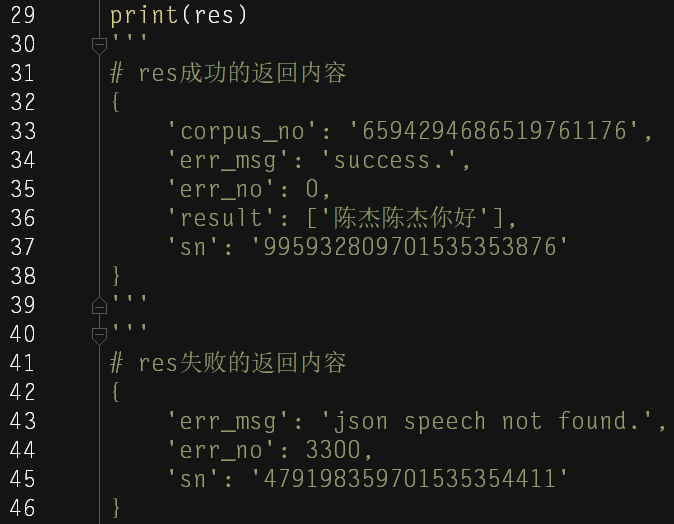
成功的dict中 result 就是我们要的识别文本
失败的dict中 err_no 就是我们要的错误编码,错误编码代表什么呢?

如果err_no不是0的话,就参照一下错误码表
到此百度AI语音部分的调用就结束了。
补充:mac环境中,自动执行mp3文件,要改用指令:os.system("open xueshuohua.mp3")
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2018/08/27 15:31 # @Author : MJay_Lee # @File : ai_xueshuohua.py # @Contact : limengjiejj@hotmail.com import os from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = '11721488' API_KEY = 'RSs9MrcwhhdndG6vLHN9Q9dC' SECRET_KEY = 'RpQwPMiPUYXYNOFb0bmFIHORNj4t6Nb0' client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 自动化交互将自己说的音频内容转换为pcm文件 file_name = "audio" cmd_str = f"ffmpeg -y -i {file_name}.m4a -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {file_name}.pcm" os.system(cmd_str) # 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('audio.pcm'), 'pcm', 16000, { 'dev_pid': 1536, }) # 提取自己说的内容 text = res['result'][0] # 合成ai的音频文件对象 speech = client.synthesis(text,'zh',1,{ 'spd': 4, 'vol': 8, 'pit': 8, 'per': 4 }) # 创建ai的音频文件 with open("xueshuohua.mp3","wb") as f: f.write(speech) os.system("xueshuohua.mp3")
三、 Pyaudio实现录音 自动化交互问答
Python 很强大其原因就是因为它庞大的三方库 , 资源是非常的丰富 , 当然也不会缺少关于音频的库
关于音频, PyAudio 这个库, 可以实现开启麦克风录音, 可以播放音频文件等等,此刻我们不去了解其他的功能,只了解一下它如何实现录音的
首先
pip install pyaudio
1.Pyaudio实现麦克风录音
(补充flask理论先)
- 还没有人评论,欢迎说说您的想法!



 客服
客服


