
一.pytesseract
1.简介
Pytesseract是一个Python库,用于将图像中的文本转换为可编辑的字符串。它是基于Google的Tesseract OCR引擎开发的 。Tesseract是一个开源的OCR引擎,能够识别超过100种语言的文字。Pytesseract简化了与Tesseract的集成过程,并提供了一个简单的API,使得在Python中使用OCR功能变得更加容易
2.环境配置
1)下载程序并安装,下载地址:https://digi.bib.uni-mannheim.de/tesseract/
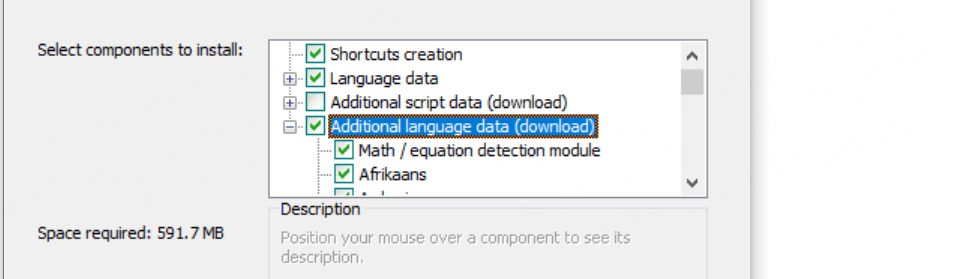
安装的时候记得勾选下载的语言,全选即可。
2)终端下载pytesseract库
pip install pytesseract
下载安装完成之后在当前项目下找到venvLibsite-packagespytesseractpytesseract.py文件,修改tesseract_cmd值

3.基本用法
我们要识别图片文字,最常用的方法就是image_to_string,语法如下,通常使用时传两个参数即可,要识别的图片和语言类型
def image_to_string( image, lang=None, config='', nice=0, output_type=Output.STRING, timeout=0, ):
下面看下实例
result_text = pytesseract.image_to_string("./img/img_5.png", lang='chi_sim') # 输出结果 print(result_text)
如果涉及到识别的图片中存在多种语言,可以在lang中添加多种语言,用+号连接起来
import pytesseract
from PIL import Image
img = Image.open(url) text = pytesseract.image_to_string(img, lang='chi_sim+eng') # 识别中文和英文
各种语言类型如下图
eng |
英文 |
chi_sim |
简体中文 |
chi_tra |
繁体中文 |
ara |
阿拉伯文 |
jpn |
日文 |
kor |
韩文 |
spa |
西班牙文 |
fra |
法文 |
| deu | 德文 |
| ita | 意大利文 |
| por | 葡挞文 |
| rus | 俄文 |
| vie | 越南文 |
| tha | 泰文 |
| tur | 土耳其文 |
| dan | 丹麦文 |
| nld | 荷兰文 |
| fin | 芬兰文 |
| nor | 挪威文 |
| swe | 瑞典文 |
| hun | 匈牙利文 |
| cze | 捷克文 |
| pol | 波兰文 |
| slk | 斯洛伐克文 |
| slv | 斯洛文尼亚文 |
| bul | 保加利亚文 |
| ell | 希腊文 |
| est | 爱沙尼亚文 |
| lit | 立陶宛文 |
| lav | 拉脱维亚文 |
| ron | 罗马尼亚文 |
| srp | 塞尔尼亚文 |
| ukr | 乌克兰文 |
| hin | 印地文 |
| ben | 孟加拉文 |
| mar | 马拉地文 |
| tam | 泰米尔文 |
| tel | 泰卢固问 |
| kan | 卡纳达文 |
| mal | 玛拉雅拉姆文 |
| orl | 奥里亚文 |
| pan | 旁遮普文 |
| guj | 古吉拉特文 |
| sin | 僧伽罗文 |
| mya | 缅甸文 |
二.ddddocr
1.简介
OCR是一种将印刷或手 写文本转换为可编辑文本的技术。ddddOCR利用深度学习算法识别图像中的字符,并将其转换为可编辑的文本。它可以应用于各种场景, 如扫描文档、图像识别、车牌识别等。ddddOCR具有高准确性和高效率,可以在短时间内处理大量的图像,并能够适应不同的字体和文字 样式。它可以应用于各种领域,如办公自动化、数据输入、图像处理等。
2.环境配置
pip install ddddocr
3.基本用法
import ddddocr ocr1 = ddddocr.DdddOcr() # 实例化 with open("./img_2.png", 'rb') as f: img_bytes = f.read() result_text = ocr1.classification(img_bytes) print(result_text)
个人觉得ddddocr识别的特不准,毕竟是免费的,要想准确识别可以参考超级鹰:https://www.cnblogs.com/lihongtaoya/p/16727694.html
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


