原文地址:https://www.cnblogs.com/taiyonghai/p/7244878.html
CPU是一台电脑的灵魂,决定电脑整体性能。现在的主流CPU都是多核的,有的运用了多线程技术(Hyper-threading,简称HT)。多核可能还容易理解些,相信不少玩家都能说出个所以然。但超线程是个什么东西,究竟有什么实际意义,一个支持超线程的CPU开启和关闭HT有什么不同,能解释清楚的人可能就不太多了。为此,我特地开此贴给大家介绍一下双核、超线程技术。此贴结合我平时自己工作中的积累、同厂商(英特尔)的交流经验、以及私下里作为一个DIY玩家的认识,力争做到最权威、最准确,同时保证通俗易懂,希望能用几个简单的例子让你迅速达到硬件专家的认识水平 。
不过事先说一下,
1)这是论坛帖子不是论文发表,有些知识点真的只能是点到为止。
2)有些只能是尽量准确,为保证通俗易懂,可能达不到学术级别的精准度。
3)本帖强调知识和理解。而现实中,究竟是花六七百买个i3,还是一千多买个i5,这个要具体情况具体分析,没有固定答案。
4)如果是土豪,只图一个‘爽’字。不求划算,只求最贵。这个帖子建议也不用看了,因为所有的理论都无法解释为什么挂QQ需要用到4核8线程的i7。
希望你看完此文后,从此装机选U不再困扰!!!!!
有经验的玩家应该都知道下面最常见的五种英特尔消费级CPU,说它们是消费级是为了和企业级处理器Xeon(志强)区分:
- 赛扬是双核,不支持超线程 - 入门玩家
- 奔腾是双核,不支持超线程 - 中低端玩家
- i3是双核,支持超线程 - 中端玩家
- i5是4核,不支持超线程 - 中高端玩家
- i7是4核,支持超线程 - 高端玩家
而志强的一些低端CPU,普通玩家也可以用,比如
- E3是4核,支持超线程 - 高端玩家
当然,变态级i7 Extreme可以达到6核12线程,8核16线程,不过一般都是发烧友买的,普通玩家中并不常见。
一些入门的E3,其实方案基本就是沿用i7,比如备受推崇的E3 1231v3,这个U性价比很高,其实就是去了集显、不能手动超频的i7。但价格却便宜了不少,所谓i5的价格,i7的性能。
CPU架构
要谈超线程和多核,就不得不谈CPU的架构和逻辑。无关的技术细节太多,这里略去。我们重点谈一下CPU中两个相关的模块:
1)Processing Unit(运算处理单元),简称PU
2)Architectual State(架构状态单元),简称AS
PU一般就是执行运算,比如算数运算加减乘除。AS执行一些逻辑和调度方面的操作,比如控制内存访问等。
单核CPU(先从简单的谈起)
一般一块传统意义的CPU上会有一个PU、一个AS。
比喻:一个小饭馆(单核CPU),夫妻老婆店,老板兼大厨厨房炒菜,老板娘兼服务员点单。这不,来了一个客人,首先,走到老板娘的收银台前,看菜单准备点单。差不多5分钟后,客人点完了一份盖浇饭。老板娘抄好了单,递给了在后厨的老公。老公开始炒菜。在这个例子中,老板娘可以理解成AS,老板/大厨可以理解称PU(干实事的)。
多核CPU
这里说的多核,是多个物理核,比如i3的双核,i5的4核。这中架构下,每一个物理核都有一个PU和一个AS。所以。对于i3来说,就有总共两个PU,两个AS。对于i5来说,就有总过4个PU,4个AS。
比喻:上面小饭馆的列子,对于5、6个客人可能还能忙的过来。但设想一下子来他个16个客人,这队估计要排到街上了。如果再告诉你,每10分种就有16个新客人过来点单。。。完了。生意估计是做不下去了 - 老板、老板娘忙到死。
这时,我们就需要一个更大的单位食堂(多核CPU)。有4个服务生、4个大厨。4个服务生同时点单,4个大厨同时开炒(1号服务生专给一号大厨下单,二号服务神生专给二号大厨下单。。。以此类推)。这样相比小饭馆一个老板娘、一个客人队列,这里成了4个队列,效率顿时比小饭馆提高4倍。16个客人,平均分配成4个队列,每个队列就只有4个客人了,情况是不是好了很多?
这个应该还是比较容易理解的。
超线程技术(HT)
重头戏来了,超线程是个啥玩意。他是我们平时说的多线程吗?
超线程(HT)并不是我们一般说的多线程。我们一般说的多线程(multi-threading)是指程序方面的,简单的说就是‘软’的,代码级别的。而超线程一般指的是硬件架构方面的,是‘硬’的:通过调整AS而模拟出来的‘逻辑核’。
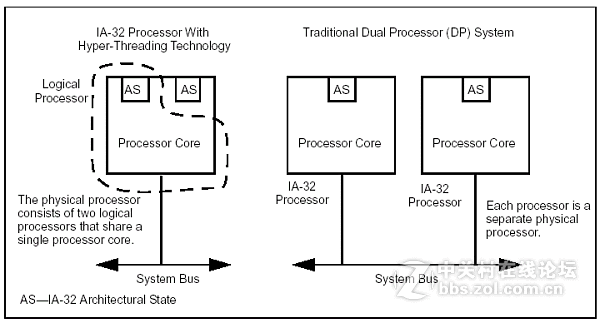
简单的说吧,超线程就是一个物理核里面,有两个AS,一个PU。两个AS共享一个PU。为什么这么做,看下面的例子:
比喻:刚刚那个单位食堂,4个服务生,4个大厨,4个队列。会不会效率问题?
有!
设想每个客人都有看单选单的时候,你能保证每个客人都看两眼就下单?有的客人难免会磨磨蹭蹭,问东问西,一个菜点它个15分钟。而设想大厨平均炒一个菜只要10分种。那剩下的那5分钟呢?大厨在厨房闲着没事干,喝茶看报纸。时间全被客人-服务生点菜这个环节给浪费掉了。
那有没有解决方法?我想大家应该都能猜出来了
--- 增加服务生!
这时候,我们给每个大厨多增加一个服务生,从一个服务生变成了两个服务生(AS),服务生1A和服务生1B开两个队列,同时给一个大厨(PU)下单。这样,当出现服务生1A的客人15分钟单子都没有下完的情况下,1B的客人单子很有可能3分钟下好送给大厨开炒了(PU),这样大厨就不会站在厨房傻等1A客人的订单。这样,最大限度地榨干大厨的劳动力 (大厨估计要骂娘了),而对于CPU来说,最大限度的提高了CPU的使用率,减少了CPU的(IDLE)空闲时间。有的时候,真不能怪大厨(PU)不卖力,而是你服务生(AS)叫单太墨迹。

在下图中,橙色和蓝色表明大厨(PU/CPU)是在工作的,白色格子表明大厨(PU)是空闲的。A图是单核没有没有用超线程,B图双核没有超线程,图C是单核启用了超线程。可以清晰地看到,从单核增加到双核(在没有超线程的情况下),CPU使用率并没有增加。而用了超线程后,整体CPU使用率提高了,虽然只是一个核。
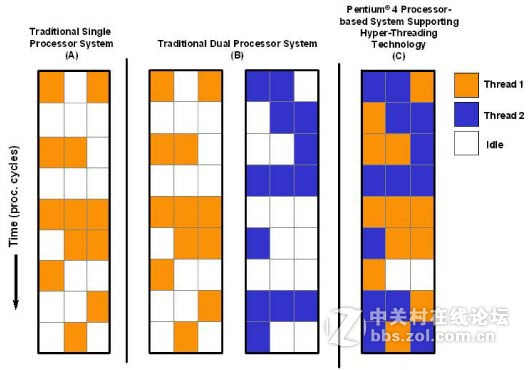
左边的图是单核超线程,右边的图是双核,不带超线程。看出区别了吧?
现在来看实际中多核和超线程的相关问题:
1)i3 双核4线程,和i5 4核4线程,是一回事吗?
首先先说一下i3,i3是双核,开了HT以后,变成4个逻辑核(4线程)。最新的Win10我不知道,但在Win7里面逻辑核是被显示成物理核的,和i5一样。那i3和i5一回事吗?如果你觉得是一回事,那我上面的东东全都是白写了。
i3是4个服务生两个厨子,i5是4个服务生4个厨子,你觉得一样吗????
2)那i5 4核4线程,相比较开了HT的i7(4核8线程)一样吗?
i5是4个服务生4个厨子。i7如果开了HT,是8个服务生4个厨子。当然从CPU利用率尤其是运行多进程/线程程序上面来看,是开了HT的i7好。
3)那i5 4核4线程,相比较关了HT的i7(4核4线程)一样吗?
i5是4个服务生4个厨子。i7如果关了HT,也是4个服务生4个厨子。乍一看差不多,至少在大厨(PU)、服务生(AS)的数量上打成平手。但是i7的单核处理能力要稍强于i5,也就是说i7的厨子是特级厨子,i5的厨子的一级厨子。所以其实i5和i7还是有差距,但是从理论上来说,差距并不是特别大。
总结:理论上来说,i3和i5的差距是相当的大。而i5和i7差距主要是厨子(PU)质量的好坏和多出的那4个服务生。其实差距并不是像i5-i3之间的差距那么大。
4)那对与同一个CPU,比如i7,开了HT有什么优点:
- 并行能力增强:处理多进程/线程的能力加强,对于支持多线程的游戏提供比较明显。
- CPU利用率增高:一般理论上,总体性能提高差不多20%-30%。从这个角度上看,i3开启了超线程,提高了20%-30%整体水平。但是,这就意味着能和i5打成平手了??? 如果这是真的话,i5也不要卖了。两个大厨(i3),不是我等拿个鞭子抽抽就能顶的上4个大厨(i5)的。。。。
5) 开HT有什么缺点
- 单核性能下降:
一般在5%-15%之间,主要表现在运行单线程程序。两个AS的额外开销比一个AS的开销要大
比喻:只有一个客人来点餐,指定一号大厨,但你两个服务生站在那儿,而这个客人可能就会过一下脑子,想想,我是找服务生1A呢,还是服务生1B呢?? 这么一想,半分钟过去了。。。是不是还不如只有一个服务生来的简单。
所以现实中我们超算系统测试跑分的时候一般都是要HT关掉的,因为追求极限性能。现在最新的CPU可以做到5%-15%的性能损耗,而老的超线程CPU,比如10几年前的老奔腾4/志强,我见过单核性能超过50%的性能损耗的,启动HT的额外开销极大。
- 电费增加,一般功耗平均上升30%。你多请的4个服务生,不用给工钱???
- 在核特别多的情况下,比如双槽服务器的情况下,容易发生拥塞。
比喻:试想一个超大的食堂,有56个服务员(双CPU,28核,56线程至强E5系列CPU),来了几百个人过来,是不是会乱了套?大家刚进食堂一开始都不知道该排哪个队了(一般决定排哪个队,是操作系统定下的)。(在操作系统的安排下)一个客人,把56个队列一条一条地查一遍,看看哪条队客人最少就排哪条。。。。
我想问的是,现实中你去食堂打饭,假设有56个队,你会一条一条的检查,找出人最少的队,然后再做决定吗?估计你56条队查完,15分钟过去了,你的小伙伴饭都吃完了。这时候,是不是我将队伍减少到28个队,对你来说会相对容易一些?(当然28队也还还是够累的)
- 老系统支持的差
比如老的Win2008,Win2000,对超线程支持比较差。
比喻:如果食堂比较空,没人。这时候来了两个客人A和B来订餐,结果两个人分别跑到同一个大厨的两个服务生1A和1B上排队(一般这都是操作系统干的好事),你能发现哪儿不对劲吗?
正确的做法应该是A去一号大厨(1号物理核),B去二号大厨(2号物理核)。你让A,B都挤到一号大厨那里,二号、三号、四号大厨啥事没有,闲到死,有意义吗?
其实问题就在于,操作系统不能分辨物理核和逻辑核。看那里有两个服务生,两个队列,就以为有两个大厨,所以把客人A和B分别打发到1A和1B去排队,完全不知道后厨的实际情况 - 究竟有几个大厨。
回到现实,我究竟需要什么样的CPU?
这里,我分情况讨论。
1)上网,聊QQ,简单的办公用(比如Office文档处理),老人机
赛扬其实就可以了。赛扬是2核2线程,其实和2核4线程的i3相比,在对付这类应用时候,抛去主频,缓存的区别,i3的优势完全发挥不出来。注意i3的价格差不多是赛扬的3倍。
还有一个就是奔腾,奔腾其实就是主频稍高,缓存稍大的赛扬。同样是2核2线程,性能比赛扬只高一点点,但价格差不多可以买1.5个赛扬。个人觉得没什么意思,多出这钱,真不如买个高级点的键盘、鼠标、显示器。至少,使用方面的体验是实实在在的。
2)轻量级游戏,平面图形工作者(比如PS)
i3其实挺适合。小游戏,还有一些网页游戏,PS什么的,虽然是多线程程序(比如PS),但其实对CPU的负担不会特别重。反而瓶颈有可能是磁盘I/O速度等。所以开了超线程的i3对付这类情况,其实问题不大。
3)重量级大型3D游戏
现在的3D游戏,会将很多比如3D加速的任务交由GPU去做,GPU工作的时候,一般CPU都会处于blocking(中断等待)状态,直到GPU指令执行完毕,CPU再继续。所以这里就会出现两个瓶颈,一个来自CPU,一个来自GPU。
对于3D游戏来说,一般来看i5完全可以胜任,你说要不要上i7?当然,你腰包鼓上i7没问题,跑分肯定会提高。但如果预算有限的话,可能将钱投入到升级显卡上面来的更简单直接。比如,i5配中高端显卡比如970这种比较均衡,相对于i7+950。
拥有i7性能的E3值不值得入手?当然值得入手。但如果E3 1231v3价格被JS价格炒过了头,还不如用i5算了。
4) 3D图形工作者
如果工作中出现很多3D建模,渲染啥的。CPU很重要,GPU也重要。CPU(逻辑)核越多越好,因为各种渲染的方法,从算法上来说,都是可以高度并行的。每个逻辑核,都可以给你任务队列塞得满满的,最大程度的榨干CPU的性能。绝对不会出现偌大一个食堂,只有一两个顾客这种情况。而这时候,E3/i7,和i5的区别就有可能非常大。
GPU负担也重,而且普通的游戏显卡比如GTX980这种有可能不能胜任,而需要Quadro图形卡。不是说980不够强悍,而是因为一些图形相关的驱动/库是没有被加入GTX980这种游戏卡的,没驱动就没法在GPU上面跑,跑不了就只能依靠CPU来模拟运行。结果就是,CPU本身的逻辑要跑,而GPU跑不了的,最后也是通通让你CPU跑。你说CPU不足够强悍,还能活命吗?
所以这类应用,一定要挑一个强悍的CPU,比如i7, E3这种,甚至是中档志强E3系列 - 6核12线程,8核16线程的CPU。
进阶篇 - 为什么系统跑分测试的时候,我们是关闭超线程的
这时候你可能会问,既然HT能提高系统的性能,尤其是处理多线程程序的能力,为什么你们系统测试时要关掉。比如一个4核8线程的E3 1231v3关掉HT后,只剩4核4线程,也就是4个服务员,4个大厨,4个队列。性能不是会变差吗?CPU空闲时间不是会高吗?
这其实是个很实际、很有趣的问题,按道理来说我们应该开超线程。
例子:
比如来了64个客人,每个人都要一个盖浇饭,两种情况
1)到了一个8个服务生、8个队列的、4个大厨的食堂,每个队列有几个客人? - 8个。
2)到了一个4个服务生、4个队列的、4个大厨的食堂,每个队列有几个客人? - 16个。
哪个快?应该是第一个,因为同时8个服务生,交错开接单,当然能减少某个客人犹豫、磨磨叽叽带来的延迟。让4个大厨忙个不停。
别忘了,我们之前已经探讨了,开启超线程以后,因为增加了4个服务员,会带来额外的开销 - 每个客人入队前都会犹豫,都要花时间思考 - “两个队我究竟应该怎么排?哪个队人少?哪个服务生看的养眼?。。。。”。这种额外的开销(处理延迟,性能损耗)是硬件级别的,是英特尔设计CPU的时候就规定死了的。我们任何事都无法解决硬件方面的问题。而唯一的办法就只能是 ----> 关掉HT。但关掉HT,每个队列变成16个客人,而每个服务生,从接待8个客人,增加到16个客人(AS延迟从8份,增加到了16份),怎么破????
重头戏来了,硬件我们当然无法改动,但是软件程序上我们可以进行优化,我们可以重写程序的并行调度算法,使得程序最大程度上针对CPU天生的硬件架构进行优化。具体的算法上细节太专业不容易懂,我举下面这个例子一说,你可能明白了:
例子:
比如来了64个客人,每个人都想吃一个盖浇饭。来到一个4个服务生、4个队列的、4个大厨的食堂。每个队列会有几个客人? - 16个。
好,对于每一个队,现在我不让这16个人都去排队,而是从队里面推选出1名代表,让这个代表代替16个人去向服务生点单。一个单子上16份盖浇饭,其余15人退后。这样一来,总共只有4个客人(代表)点单,其余的60个人在下面歇息。而点单速度方面,每个队最多也就(一个代表)磨叽一次。后堂大厨接到16份盖浇饭的订单,也只有拼命做的份。你总不能炒一个盖浇饭歇5分钟吧。。。
瞧, 是不是问题解决了?
1)既避免了8个服务员、开8个队列所带来的AS额外开销
2)也最大程度的利用了大厨(减少了PU的闲置时间)
作为一个超算系统,大家都在追求极限性能。世界上每年都会进行500强超级计算机性能排名,一点点的性能差异都有可能会让你的排名退后不少,所以大家都需要尽可能地压榨系统的最后一点性能。
同时,这个实例也告诉DIY玩家们,硬件重要,软件也重要。硬件强悍的同时,软件(驱动)也要进行相关的优化。如果软件没有针对性的优化,再强的硬件也发挥不出100%的威力。这个也从侧面解释了为什么有些硬件,属于跑分王类型。比如测试3Dmark这种,得分暴高,而一到实际游戏中,表现一塌糊涂。
买硬件,要买用的人多的,不要搞太小众的东西。
软硬兼施,不仅硬件性能要强,软件优化也要做到位
1)相对于4核8线程(开超线程),4核4线程(关超线程)后在处理(调度)多线程方面的劣势,我们完全可以通过修改源代码,把这个劣势给抵消掉。而8线程(多了4个硬件AS)所带来的硬件架构方面的额外开销,这个可以理解成集成电路级别的,我们无能为力。
所以就像华山的剑宗和气宗。
剑宗就是:简单的增加程序线程的数量,同时打开CPU超线程功能。
气宗就是:修改程序,做算法上面的改变,手动的计算运算周期,调整并行策略,将延迟隐藏掉。
剑宗速成,气宗慢成。同样练1年,剑宗练到6级威力,而气宗只能是3级。但是如果给足够时间,剑宗的极限只能练成9级,就无法突破了。而气宗最终可以练到10级。
2)还有就是优化。这里面牵涉到一个平衡的问题。性能 vs 通用性。
举个简单例子,如果给你一个加法运算:
1+1+1+1+1+1+1+1 (8个1相加,当然现实中,这么小颗粒度的运算根本没有必要进行并行,不值得。这里是为了举例需要。)
第一种方案 (性能低下+通用性最高):
什么优化都不做,程序员只要小学一年级毕业就行了。程序太简单明了了,一行搞定,扔给CPU,做了7次运算,算一次1秒钟,这样就是7秒钟。多核一点用都没有,完全是拼单核性能。强调一句:一个单序程序(serial program)比如8个1相加,你不在代码级别做并行化,它不会自己变成一个多核程序。也就是说:它只会用一个核!!!这里,没有奇迹,没有魔术!怎么做并行化?改你的程序,用上pthread, fork, MPI, openMP。。。等很多种方法,具体细节不多说了。感兴趣的话求助一下度娘。
总时间:7秒钟
第二种方案 (良好性能+高通用性)
做并行优化:
1)首先,数一下你的机器有几个核,这里假设只有物理核。好,数好了,有4个核,花费0.5秒钟 (时间值只是举例)。
2)这时,我可以根据核的数量(=4),把运算劈成4份,产生4个(程序上的)线程,变成下面形式,从而和硬件核心个数(=4)进行1:1匹配。这样的调度开销0.5秒钟,
3)然后,开始下面的计算
(1+1) (1+1) (1+1) (1+1)第一轮每个核都是一次运算,共1秒钟
(2+2) (2+2) 第二轮1号2号核都是一次运算,共1秒钟
(4+4) 第三轮只有1号核工作 共1秒钟
花了1+1+1=3秒。而且这个也是有数学证明的(Divide and Conquer问题,具体细节不多说了。感兴趣的话求助一下度娘), 相信大家都学过对数,Log28 = 3 。
总时间:0.5+0.5+3=4秒钟
第三种方案,比较极端 (极限性能+低通用性)
如果,我知道我的系统里面有4个核,是不是:1)数多少个核 2)调度开销 全都可以省了?好,这些费时间的步骤全部去掉。直接奔步骤3)。
----> 这样,最终只要3秒钟。
但是,这种方法只适合4核的机器,如果你给他双核或者8核的机器,整体速度会大打折扣,还不如第二种方案,因为第二种方案带有一定的通用性和自适应性。而第三种方案是“死”的,无脑的。也就是编程时候的hard coding (翻译过来叫死码或硬码),这种编程习惯不推荐,因为写出来的程序实用性会很差。
现在不知道你看出点端倪来了没有?
其实,我们系统测试追求的是第三种方案,因为我们非常清楚自己系统的架构。完全不用考虑什么比如双核和4核CPU的情况(我们一般多用8核的U)。CPU中二级三级缓存的大小都是固定的。也就是说我们的代码优化可以是非常极端的,完全面向特定型号硬件的优化。这样的优化换来的就是低通用性,也就是说我们所达到的指标性能,只有在我们的系统上才行。
再举个有趣的例子:
Fermi一代的NVIDIA显卡,也就是GTX460这种,基本上是在300个左右的CUDA Core(可以理解成流处理器)。而Fermi下一代是开普勒(Kepler),也就是GTX660这种,相比460,性能差不多翻倍。但是怎么翻倍的,你知道吗?GTX660的流处理器增加到了1000个左右。但是单个流处理器的性能,660只有460差不多1/2。所以660全靠数量打赢的。
结果,问题来了。我们的一个用户,同样一个GPU程序(Gromacs)分别放在Fermi卡上和Kepler卡上跑(Tesla计算卡,差不多就等同于460和660),结果Kepler反而比Fermi慢了不少,运行时间多了一倍。按道理来说不应该啊,用户求助我们。我们检查后确定不是硬件故障,两个卡都工作正常,NV驱动也正常。然后,我就开始看程序的源代码,花了一番功夫后找到了原因!!! 那个程序里面调用的线程数是死的!设置成了最大产生256的线程(至于为什么是256而不是257,因为CUDA里面有个thread wrap(线程包)的概念,一个包是32个,所以一般总线程数习惯都是32的倍数。具体不多说了,感兴趣的可以看一下《GPU高性能编程CUDA实战》)。这样的话,在300个核的Fermi上,基本整个卡的流处理器(几乎)全部跑满了。但是对于1000个流处理器的Kepler,256等于只用了差不多1/4,有700多个流处理器从头到尾就是空闲的。别忘了,Kepler单核性能=50%Fermi单核性能。所以,这样一来,为什么Kepler卡跑得慢,就可以解释了。
我们不知道Gromacs这个软件的逻辑,其实也没有必要知道,因为我们并不是计算分子动力学专家。所以后来,我们把我们的发现,汇报给Gromacs程序的开发者,让他们对程序进行了优化和改进,重新改进了并行算法,增加了线程数,下个版本更新时终于把这个问题解决掉了,使得Kepler这代的显卡可以完美地得到支持。
可见,有针对性的程序优化是多么的重要!
(下面是我作为玩家的理解,不一定专业和准确)
实际消费市场中,一个消费级产品,尤其是它的硬件驱动,采取第三种思路,就很有可能会出现‘跑分王’现象。这里,我举显卡的例子,可能大家更容易理解些。像很多年前的ATI显卡,硬件驱动针对那些跑分软件比如3Dmark,很有可能做了极度的优化。为什么会这样?有大程度上是因为ATI(第二种方案)拼不过NVIDIA (第二种方案),而这些厂商深知道消费者买显卡之前都是看评测跑分的,那好,我就给你来这套 田忌赛马:ATI(第三种方案)去和NVIDIA拼 。结果跑分上面不落下峰了,但通用性可能大大下降。实际运用中,遇到各种各样的游戏,如果游戏没有进一步对显卡驱动进行匹配优化,就会导致性能大减。所以这里是一个: 游戏程序 <--> 硬件驱动 <--> 硬件架构 三者相互匹配、相互优化调度的问题。(当然,现实中可能还会多出游戏引擎这个环节,也就是4者)。
Crysis(孤岛危机)这类的游戏开发者 (包括Cryengine这种3D引擎开发者),和开发硬件驱动的厂家,思路一般是不太一样的。也就是说孤岛的开发者肯定要考虑平台的通用性,一般不会采取特别极端的开发思路(比如第三种方案)。实际中,游戏速度慢,卡顿,一般怪的多的是厂商(ATI,NV),怪产品不给力,但你会怪游戏开发者写的代码垃圾吗?就算孤岛一向被称为是硬件杀手,那又能怎么样呢?作为消费者,你只能不断的掏钱升级显卡。。。。
如果孤岛采取的第二种方案思路,那就说的通了。2核4线程、4核4线程、4核8线程当然是不一样的。因为你从来都不会有绝对性能上的标杆 - 孤岛究竟应该多快多流畅,究竟有没有把GTX980这个硬件的绝对性能榨干到极致。而你只可能有相对的感受 - 用核少的i3打孤岛,肯定没有核多的i7打孤岛那么爽。
- 还没有人评论,欢迎说说您的想法!



 客服
客服


