
我在上一章《形象谈JVM-第一章-认识JVM》提到的“翻译”,其实就是我们今天所说的“编译”的概念。
上一章原文链接:https://www.cnblogs.com/xingxiangtan/p/17617654.html
原文:
【 虚拟机的职责是将字节码翻译成对应系统能够识别并执行的机器码,
比如在linux系统,java文件被javac编译器翻译成字节码文件(class文件),jvm将字节码文件翻译成linux能够识别并执行的机器码文件,这样java程序便能够被运行起来了。
java文件是咱人类能看懂的文件,字节码文件是虚拟机能看懂的文件,机器码文件是CPU能看懂的文件。 】
本文将分为两个部分来展开,前端编译与优化和后端编译与优化
讲之前我们先来弄清楚这三个关键词的意思,前端、后端和优化。
前后端:以文件进入JVM之前和之后为基准在区分前后的。
优化:一个高级的翻译将英文作品翻译成中文作品时,绝不会逐字死板的去翻译,而是会在不影响原意的前提下加以文采的修饰,以达到读者更好更快的理解,编译器的优化类似,在编译期,在不影响代码逻辑的前提下,会将复杂优化成简洁的,将缓慢的优化成快速的等等,为了程序更好更快(非绝对)的执行。
前端编译器及优化:
前端编译器包括JDK的Javac、Eclipse JDT中的增量式编译器(ECJ)等等, 咱们讲javac,javac本身就是一个由Java语言编写的程序。

执行javac命令,就是javac编译器解析Java源代码,并生成字节码文件的过程。javac编译过程可以分为四个阶段:
1、词法、语法分析。
词法分析是将源代码的字符流转变为标记集合的过程。
语法分析是根据标记序列构造抽象语法树的过程,抽象语法树(Abstract Syntax Tree,AST)是一种用来描述程序代码语法结构的树形表示方式。
举个形象的例子,上中学,学英语科目,我们要弄懂一句话,首先得知道各个单词的意思,这就对应着词法分析了,然后英语的语法有很多种,首先要搞清楚主谓宾结构,还有从句,后置之类的语法,这个就对应了语法分析,这二者都没问题了就能够弄清楚这一句话的意思了。
2、填充符号表。
类之间是会互相引用的,但在编译阶段,无法确定其具体的地址,所以会使用一个符号来替代。等到被引用类加载时,javac 编译器会将符号替换成具体的内存地址。
比如开学第一天,老师让你去找一个班里的一个名字叫“李小花”的同学,这个“名字”就相当于一个“符号”,你不知道李小花同学坐在哪里,你就大喊李小花的名字,李小花同学听到了,便答应,于是你就看到了李小花坐在三排二座,以后你就知道“三排二座”的同学就是李小花了,这个“三排二座”就相当于“地址值”。
3、注解处理。
JDK 5之后,Java语言提供了对注解的支持,注解在设计上原本是与普通的Java代码一样,都只会在程序运行期间发挥作用的,因此在这个阶段会对注解进行分析,根据注解的作用将其还原成具体的指令集。
4、语义分析与字节码生成。
语义分析的主要任务是对结构上正确的源程序进行上下文相关性质的检查,比如类型检查、控制流检查、数据流检查,等等,再进行字节码的生成,最终输出为class文件。
后端编译器及优化:
后端编译器包括JIT(Just In Time)即时编译器和AOT(Ahead Of Time)提前编译器。
而在解释后端编译器之前我们要先来解释一下解释器
解释器:直接执行用编程语言编写的指令的程序。
编译器:把源代码转换成(翻译)低级语言的程序。(这里所指的低级是越接近于机器则越低级)

如上图,编译器如同“笔译员”,对语言进行转换,输出一份可以被用于执行的文件,解释器如同“口译员”,直接将翻译后的结果输出,不保存任何中间文件。
从这二者的工作模式,可以很容易的联想到它们的优点和缺点
解释器:
优点:启动速度快
缺点:执行速度慢,执行效率低
编译器:
优点:执行效率高
缺点:编译速度(启动速度)慢
接下来咱们继续讲回后端编译器。
JIT(Just In Time)即时编译器
HotSpot虚拟机内置了两个(或三个)即时编译器,在执行的过程中,将热点代码(也就是执行次数比较多的代码)转化为本
地机器码,并做优化,以加速执行效率。
客户端编译器(Client Compiler)和服务端编译器(Server Compiler),简称为C1编译器和C2编译器,第三个是在JDK 10时才出现的、目标是代替C2的Graal编译器。咱们本章节只讲解C1、C2编译器。
在 Java 7 以前,我们需要根据程序的特性选择对应的即时编译器。
对于执行时间较短的,或者对启动性能有要求的程序,我们采用编译效率较快的 C1,对应参数 -client。
对于执行时间较长的,或者对峰值性能有要求的程序,我们采用生成代码执行效率较快的 C2,对应参数 -server。
在分层编译(Tiered Compilation)的工作模式出现以前,HotSpot虚拟机通常是采用解释器与其中一个编译器直接搭配的方式工
作,程序使用哪个编译器,只取决于虚拟机运行的模式,HotSpot虚拟机会根据自身版本与宿主机器的硬件性能自动选择运行模式,用
户也可以使用“-client”或“-server”参数去强制指定虚拟机运行在客户端模式还是服务端模式。
无论采用的编译器是客户端编译器还是服务端编译器,解释器与编译器搭配使用的方式在虚拟机中被称为“混合模式”(MixedMode),
用户也可以使用参数“-Xint”强制虚拟机运行于“解释模式”(Interpreted Mode),这时候编译器完全不介入工作,全部代码都使用
解释方式执行。另外,也可以使用参数“-Xcomp”强制虚拟机运行于“编译模式”(Compiled Mode),这时候将优先采用编译方式执行
程序,但是解释器仍然要在编译无法进行的情况下介入执行过程。
可以通过虚拟机的“-version”命令的输出结果显示出这三种模式:

Java 7 引入了分层编译(对应参数 -XX:+TieredCompilation)的概念,综合了 C1 的启动性能优势和 C2 的峰值性能优势。
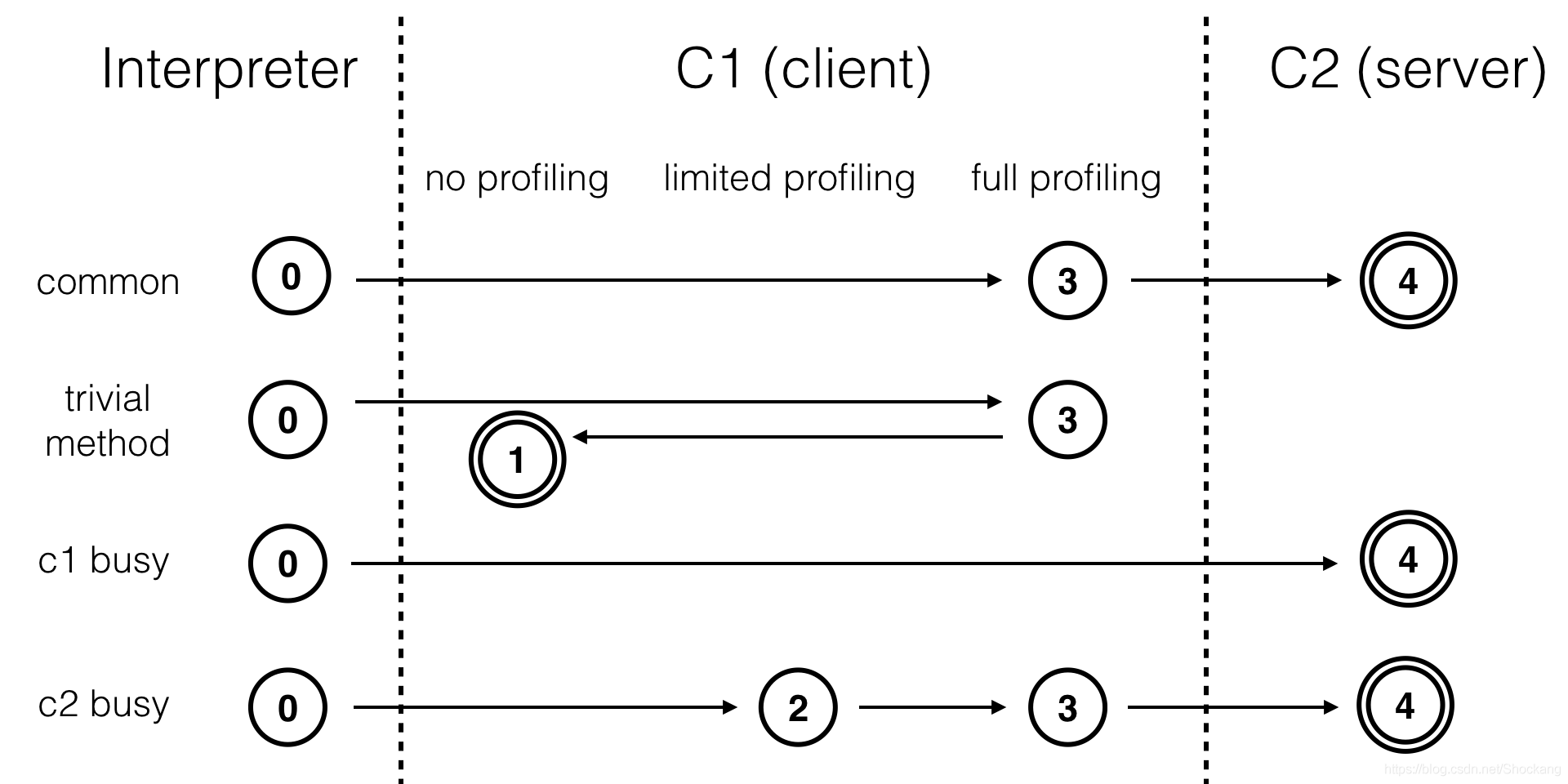
分层编译的五个层次
分层编译将 Java 虚拟机的执行状态分为了五个层次。
五个层级分别是:
1、程序解释执行,不开启Profiling(性能监控功能:解释器替编译器收集性能监控信息);
2、进行简单可靠的稳定优化,执行不带 profiling 的 C1 机器码;
3、执行仅带方法调用次数以及循环回边执行次数 profiling 的 C1 机器码;
4、执行带所有 profiling(除第3层的统计信息外,还会收集如分支跳转、虚方法调用版本等全部的统计信息) 的 C1 机器码;
5、执行 C2 机器码。对比C1,C2会启用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化;
通常情况下,C2 代码的执行效率要比 C1 代码的高出 30% 以上。
然而,对于 C1 代码的三种状态,按执行效率从高至低则是 1 层 > 2 层 > 3 层。
其中 1 层的性能比 2 层的稍微高一些,而 2 层的性能又比 3 层高出 30%。
这是因为 profiling 越多,其额外的性能开销越大。
在 5 个层次的执行状态中,1 层和 4 层为终止状态。当一个方法被终止状态编译过后,如果编译后的代码并没有失效,那么 Java 虚拟机是不会再次发出该方法的编译请求的。
如何来理解这个激进优化呢?
激进:有一定的性能提升,但不一定准确可靠
举例: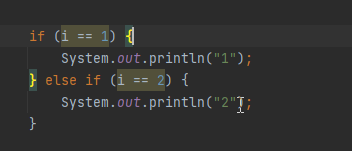
若在运行的过程中,性能监控到前一百次执行都只是走了1分支,那咱们编译还需要去考虑编译2分支吗?不需要了。
但是如果不编译2分支的代码,之后程序真的走了2分支咋办?直接找五层中的第一层的解释器执行就好了。(在后面的章节中我们会讲解更多的优化策略)
AOT(Ahead Of Time)提前编译器
提前编译器也可称为静态预编译器,因为它不像即时编译器,是在程序一边解释执行,一边进行编译的,而是先单独把文件编译完成。
JIT 优点:
1、启动速度快
2、根据运行情况实时编译生成最优机器指令
3、可以处理动态语言,因为可以在运行时确定类型。
JIT 缺点:
1、占用运行时的资源,可能会导致进程执行时候卡顿
2、识别热点代码需要时间,初始编译不能达到最高性能。
AOT 优点:
1、在程序运行前编译,可以避免在运行时的编译性能消耗和内存消耗
2、程序运行初期就达到最高性能,显著的提高执行效率。
AOT 缺点:
1、启动速度慢
2、不能处理动态语言,因为需要在编译时确定类型。
参考书籍:
深入理解虚拟机-第3版-周志明著
参考资料:
https://blog.csdn.net/Shockang/article/details/117392773
https://zhuanlan.zhihu.com/p/107382276
为什么写文章(若有错误,希望得到你的指正,若有问题,都可评论,我将会积极回复)
在作者刚入行时,会遇到很多无法理解的问题,便经常向前辈请教问题,或是于网络之中苦苦寻找答案,经常被一些晦涩难懂的表达折磨的死去活来,现作者是一名拥有多年经验的IT从业者,希望能够将自己的知识以一种形象的方式输出,先从虚拟机开始分享,之后会写更多的专栏,最新的分享将会先在公众号发布,谢谢读者的关注
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


