
这是why哥的第 70 篇原创文章
从Dubbo的一次提交开始
故事得从前段时间翻阅 Dubbo 源码时,看到的一段代码讲起。
这段代码就是这个:
org.apache.dubbo.rpc.RpcContext
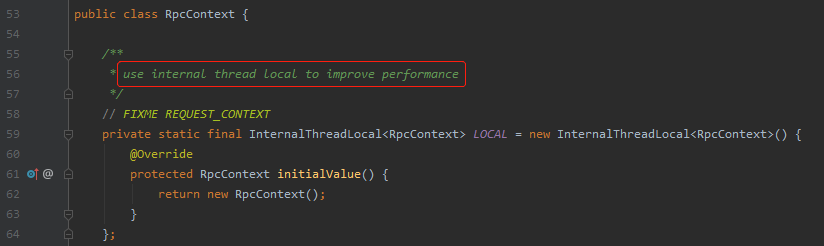
使用 InternalThreadLocal 提升性能。
相信作为一个程序猿,都会被 improve performance(提升性能)这样的字眼抓住眼球。
心里开始痒痒的,必须要一探究竟。
刚看到这段代码的时候,我就想:既然他是要提升性能,那说明之前的东西表现的不太好。
那之前的东西是什么?
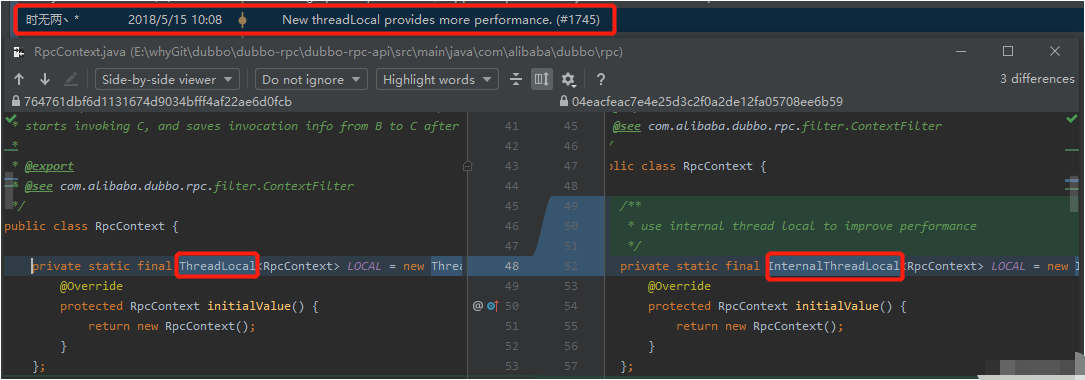
经过长时间的推理、缜密的分析,我大胆的猜测到之前的东西就是:ThreadLocal。
来,带大家看一下:
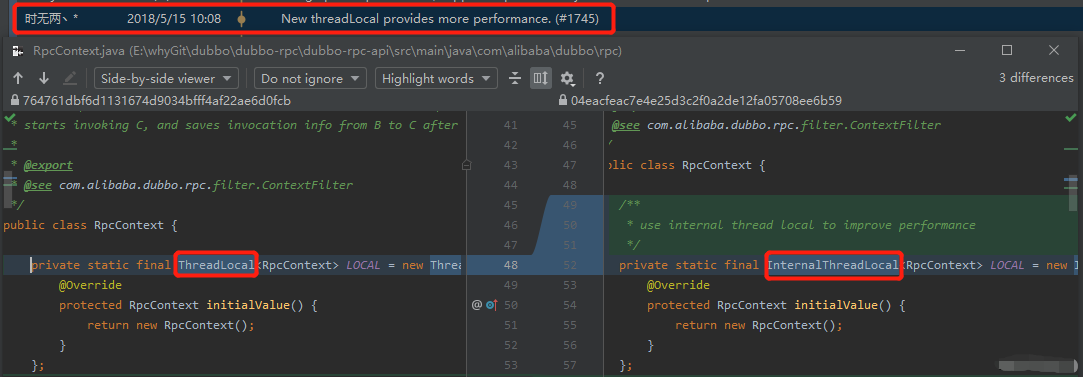
果不其然,我真是太厉害了。
2018 年 5 月 15 日的提交:New threadLocal provides more performance. (#1745)
可以看到这次提交的后面跟了一个数字:1745。它对应一个 pr,链接如下:
https://github.com/apache/dubbo/pull/1745
在这个 pr 里面还是有很多有趣的东西的,出场人物一个比一个骚,文章的最后带大家看看。
能干啥用?
在说 ThreadLocal 和 InternalThreadLocal 之前,还是先讲讲它们是干啥用的吧。
InternalThreadLocal 是 ThreadLocal 的增强版,所以他们的用途都是一样的,一言蔽之就是:传递信息。
你想象你有一个场景,调用链路非常的长。当你在其中某个环节中查询到了一个数据后,最后的一个节点需要使用一下。
这个时候你怎么办?你是在每个接口的入参中都加上这个参数,传递进去,然后只有最后一个节点用吗?
可以实现,但是不太优雅。
你再想想一个场景,你有一个和业务没有一毛钱关系的参数,比如 traceId ,纯粹是为了做日志追踪用。
你加一个和业务无关的参数一路透传干啥玩意?
通常我们的做法是放在 ThreadLocal 里面,作为一个全局参数,在当前线程中的任何一个地方都可以直接读取。当然,如果你有修改需求也是可以的,视需求而定。
绝大部分的情况下,ThreadLocal 是适用于读多写少的场景中。
举三个框架源码中的例子,大家品一品。
第一个例子:Spring 的事务。
在我的早期作品《事务没回滚?来,我们从现象到原理一起分析一波》里面,我曾经写过:
Spring 的事务是基于 AOP 实现的,AOP 是基于动态代理实现的。所以 @Transactional 注解如果想要生效,那么其调用方,需要是被 Spring 动态代理后的类。
因此如果在同一个类里面,使用 this 调用被 @Transactional 注解修饰的方法时,是不会生效的。
为什么?
因为 this 对象是未经动态代理后的对象。
那么我们怎么获取动态代理后的对象呢?
其中的一个方法就是通过 AopContext 来获取。
其中第三步是这样获取的:AopContext.currentProxy();
然后我还非常高冷的(咦,想想就觉得羞耻)说了句:对于 AopContext 我多说几句。
看一下 AopContext 里面的 ThreadLocal:
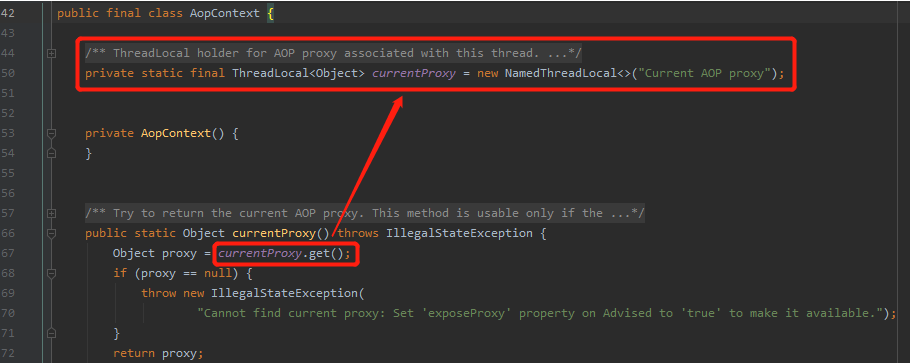
调用 currentProxy 方法时,就是从 ThreadLocal 里面获取当前类的代理类。
那他是怎么放进去的呢?
我高冷的第二句是这样说的:
对应的代码位置如下:
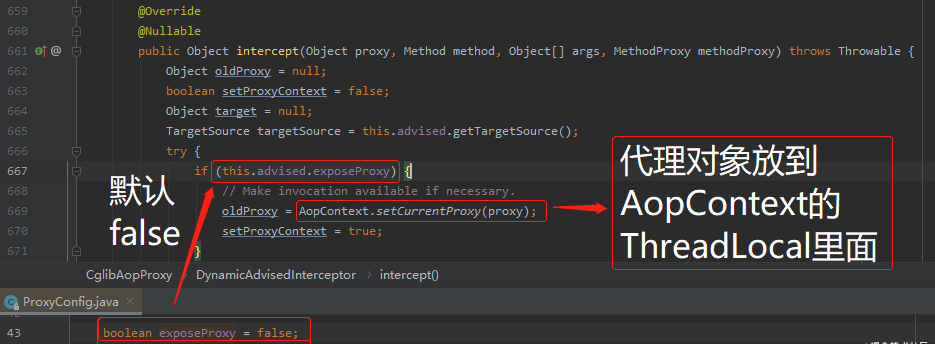
可以看到,经过一个 if 判断,如果为 true ,则调用 AopContext.setCurrentProxy 方法,把代理对象放到 AopContext 里面去。
而这个 if 判断的配置默认是 false,所以需要通过刚刚说的配置修改为 true,这样 AopContext 才会生效。
附送一个知识点给你,不客气。
第二个例子:mybatis 的分页插件,PageHelper。
使用方法非常简单,从官网上截个图:
这里它为什么说:紧跟着的第一个 select 方法会被分页。
或者说:什么情况下会导致不安全的分页?
来,就当是一个面试题,并且我给你提示了:从 ThreadLocal 的角度去回答。
其实就是因为 PageHelper 方法使用了静态的 ThreadLocal 参数,分页参数和线程是绑定的:
如果我们写出下面这样的代码,就是不安全的用法:
这种情况下由于 param1 存在 null 的情况,就会导致 PageHelper 生产了一个分页参数,但是没有被消费,这个参数就会一直保留在这个线程上,也就是放在线程的 ThreadLocal 里面。
当这个线程再次被使用时,就可能导致不该分页的方法去消费这个分页参数,这就产生了莫名其妙的分页。
上面这个代码,应该写成下面这个样子:
这种写法,就能保证安全。
核心思想就一句话:只要你可以保证在 PageHelper 方法调用后紧跟 MyBatis 查询方法,这就是安全的。
因为 PageHelper 在 finally 代码段中自动清除了 ThreadLocal 存储的对象。
就算代码在进入 Executor 前发生异常,导致线程不可用的情况,比如常见的接口方法名称和 XML 中的不匹配,导致找不到 MappedStatement ,由于自动清除,也不会导致 ThreadLocal 参数被错误的使用。
所以,我看有的人为了保险起见这样去写:
怎么说呢,这个代码....
第三个例子:Dubbo 的 RpcContext。
RpcContext 这个对象里面维护了两个 InternalThreadLocal,分别是存放 local 和 server 的上下文。
也就是我们说的增强版的 ThreadLocal:

作为一个 Dubbo 应用,它既可能是发起请求的消费者,也可能是接收请求的提供者。
每一次发起或者收到 RPC 调用的时候,上下文信息都会发生变化。
比如说:A 调用 B,B 调用 C。这个时候 B 既是消费者也是提供者。
那么当 A 调用 B,B 还是没调用 C 之前,RpcContext 里面保存的是 A 调用 B 的上下文信息。
当 B 开始调用 C 了,说明 A 到 B 之前的调用已经完成了,那么之前的上下文信息就应该清除掉。
这时 RpcContext 里面保存的应该是 B 调用 C 的上下文信息。否则会出现上下文污染的情况。
而这个上下文信息里面的一部分就是通过InternalThreadLocal存放和传递的,是 ContextFilter 这个拦截器维护的。
ThreadLocal 在 Dubbo 里面的一个应用就是这样。
当然,还有很多很多其他的开源框架都使用了 ThreadLocal 。
可以说使用频率非常的高。
什么?你说你用的少?
那可不咋的,人家都给你封装好了,你当个黑盒,开箱即用。
其实你用了,只是你不知道而已。
强在哪里?
前面说了 ThreadLocal的几个应用场景,那么这个 InternalThreadLocal 到底比 ThreadLocal 强在什么地方呢?
先说结论。
答案其实就写在类的 javadoc 上:

InternalThreadLocal 是 ThreadLocal 的一个变种,当配合 InternalThread 使用时,具有比普通 Thread 更高的访问性能。
InternalThread 的内部使用的是数组,通过下标定位,非常的快。如果遇得扩容,直接数组扩大一倍,完事。
而 ThreadLocal 的内部使用的是 hashCode 去获取值,多了一步计算的过程,而且用 hashCode 必然会遇到 hash 冲突的场景,ThreadLocal 还得去解决 hash 冲突,如果遇到扩容,扩容之后还得 rehash ,这可不得慢吗?
数据结构都不一样了,这其实就是这两个类的本质区别,也是 InternalThread 的性能在 Dubbo 的这个场景中比 ThreadLocal 好的根本原因。
而 InternalThread 这个设计思想是从 Netty 的 FastThreadLocal 中学来的。
本文主要聊聊 InternalThread ,但是我希望的是大家能学到这个类的思想,而不是用法。
首先,我们先搞个测试类:
public class InternalThreadLocalTest {
private static InternalThreadLocal<Integer> internalThreadLocal_0 = new InternalThreadLocal<>();
public static void main(String[] args) {
new InternalThread(() -> {
for (int i = 0; i < 5; i++) {
internalThreadLocal_0.set(i);
Integer value = internalThreadLocal_0.get();
System.out.println(Thread.currentThread().getName()+":"+value);
}
}, "internalThread_have_set").start();
new InternalThread(() -> {
for (int i = 0; i < 5; i++) {
Integer value = internalThreadLocal_0.get();
System.out.println(Thread.currentThread().getName()+":"+value);
}
}, "internalThread_no_set").start();
}
}
上面代码的运行结果是这样的:
由于 internalThread_no_set 这个线程没有调用 InternalThreadLocal 类的 set 方法,所以调用 get 方法输出为 null。
里面主要用到了 set、get 这一对方法。
下面借助 set 方法,带大家看看内部原理(先说一下,为了方便截图,我有可能会调整一下源码顺序):
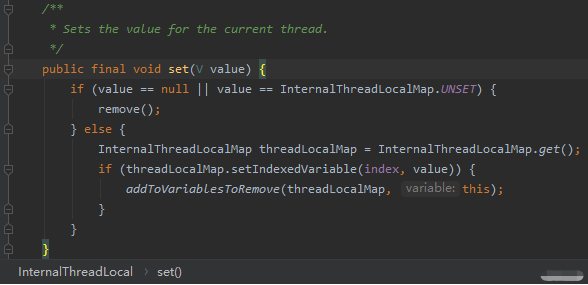
首先是判断了传进来的 value 是否是 null 或者是 UNSET,如果是则调用 remove 方法。
null 是好理解的。这个 UNSET 是个什么鬼?
根据 UNSET 能很容易的找到这个地方:
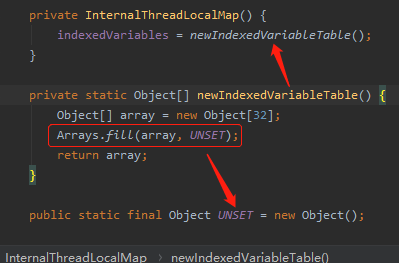
原来是 InternalThreadLocalMap 初始化的时候会填充 UNSET 对象。
所以,如果 set 的对象是 UNSET,我们可以认为是需要把当前位置上的值替换为 UNSET,也就是 remove 掉。
而且,我们还看到了两个关键的信息:
1.InternalThreadLocalMap 虽然名字叫做 Map ,但是它挂羊头卖狗肉,其实里面维护的是一个数组。
2.数组初始化大小是 32。
接着我们回去看 else 分支的逻辑:
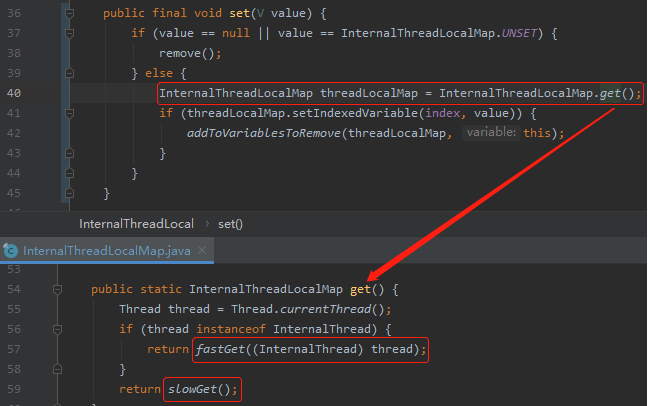
调用的是 InternalThreadLocalMap 对象的 get 方法。
而这个方法里面的两个 get 就有趣了。
能走到 fastGet 方法的,说明当前线程是 InternalThread 类,直接可以获取到类里面的 InternalThreadLocalMap。
如果走到 slowGet 了,则回退到原生的 ThreadLocal ,只是在原生的里面,我还是放的 InternalThreadLocalMap:
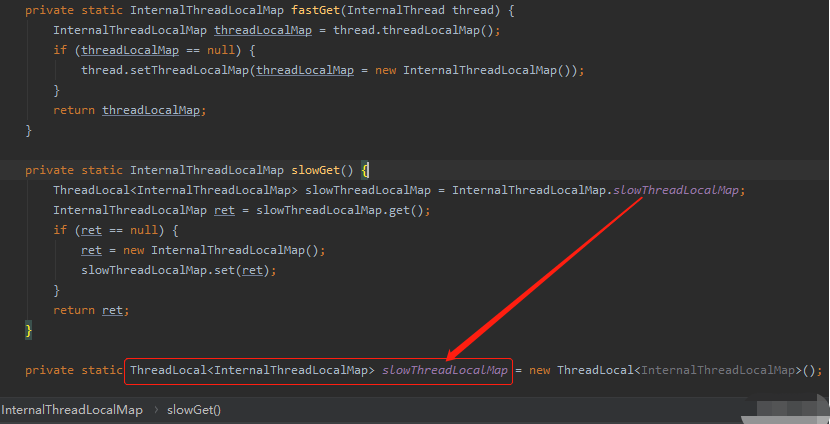
所以,其实线程上绑定的数据都是放到 InternalThreadLocalMap 里面的,不管你操作什么 ThreadLocal,实际上都是操作的 InternalThreadLocalMap。
那问题来了,你觉得一个叫做 fastGet ,一个叫做 slowGet。这个快慢,指的是 get 什么东西的快慢?
对咯,就是获取 InternalThreadLocalMap。
InternalThreadLocalMap 在 InternalThread 里面是一个变量维护的,可以直接通过 InternalThread.threadLocalMap() 获得:
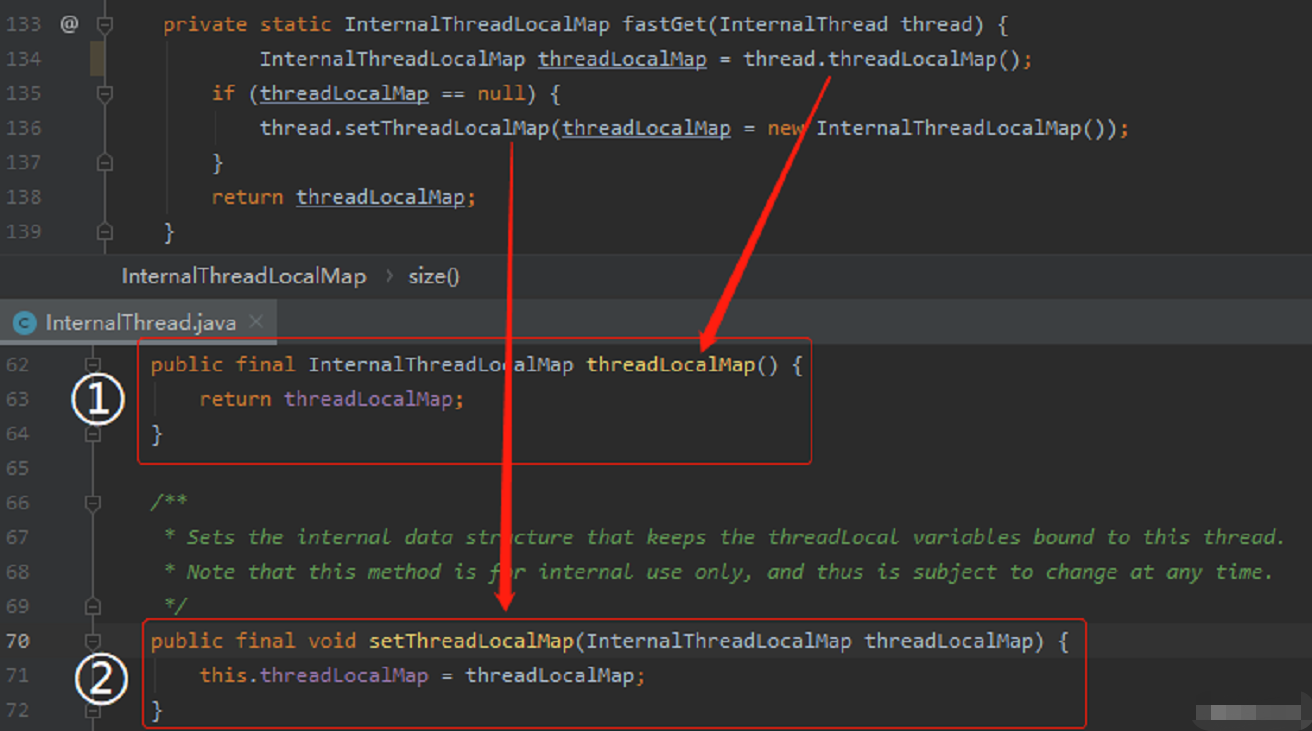
标号为 ① 的地方是获取,标号为 ② 的地方是设置。
都是一步到位,操作起来非常的方便。
这是 fastGet。
而 slowGet 是从 ThreadLocal 中获取:
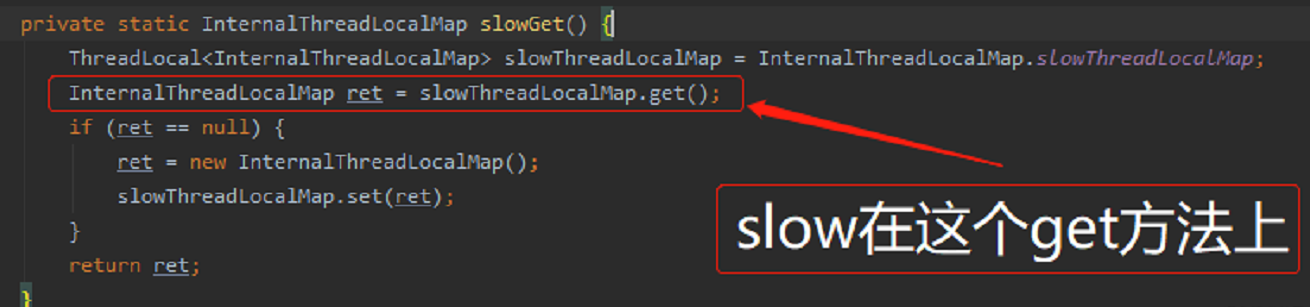
这里的 get ,就是原生 ThreadLocal 的 get 方法,一眼望去,就复杂多了:
标号为 ① 的地方,首先计算 hash 值,然后拿着 hash 值去数组里面取数据。如果取出来的数据不是我们想要的数据,则到标号为 ② 的逻辑里面去。
那么我问你,除了这个位置上的值真的为 null 外,还有什么原因会导致我拿着计算出来的 hash 值去数组里面取数据取不到?
就是看你熟不熟悉 ThreadLocal 对 hash 冲突的处理方式了。
那么这个问题稍微的升级一下就是:你知道哪些 hash 冲突的解决方案呢?
1.开放定址法。
2.链式地址法。
3.再哈希法。
4.建立公共溢出区。
我们非常熟悉的 HashMap 就是采用的链式地址法解决 hash 冲突。
而 ThreadLocal 用的就是开放定址法中的线性探测。
所谓线性探测就是,如果某个位置的值已经存在了,那么就在原来的值上往后加一个单位,直至不发生哈希冲突,就像这样的:
上面的动图就是需要在一个长度为 7 的数组里面,再放一个进过 hash 计算后为下标为 2 的数据,但是该位置上有值,也就是发生了 hash 冲突。
于是解决 hash 冲突的方法就是一次次的往后移,直到找到没有冲突的位置。
所以,当我们取值的时候如果发生了 hash 冲突也需要往后查询,这就是上面标号为 ③ 的 while 循环代码的其中一个目的。
当然还有其他目的,就隐藏在 440 行的 expungeStaleEntry 方法里面。不是本文重点,就不多说了。
但是如果你不知道这个方法,你一定要去查阅一下相关的资料,有可能会在一定程度上改变你印象中的:用 ThreadLocal 会导致内存泄漏的风险。
至少,你可以知道 JDK 为了避免内存泄漏的问题,是做了自己的最大努力的。
好了,不扯远了,说回来。
从上面我们知道了,从 ThreadLocal 中获取 InternalThreadLocalMap 会经历如下步骤:
1.计算 hash 值。
2.判断通过 hash 值是否能直接获取到目标对象。
3.如果没有获取到目标对象则往后遍历,直至获取成功或者循环结束。
比从 InternalThread 里面获取 InternalThreadLocalMap 复杂多了。
现在你知道了 fastGet/slowGet 这个两个方法中的快慢,指的是从两个不同的 ThreadLocal 中获取 InternalThreadLocalMap 的操作的快慢。而快慢的根本原因是数据结构的差异。
好,现在我们获取到 InternalThreadLocalMap 了,接着看 set 方法:

标号为 ① 的地方就是往 InternalThreadLocalMap 这个数组中存放我们传进来的 value。
存的时候分为两种情况。
标号为 ② 的地方是数组容量还够,能放进去,那么可以直接设置。
标号为 ③ 的地方是数组容量不够用,需要扩容了。
这里抛出两个问题:
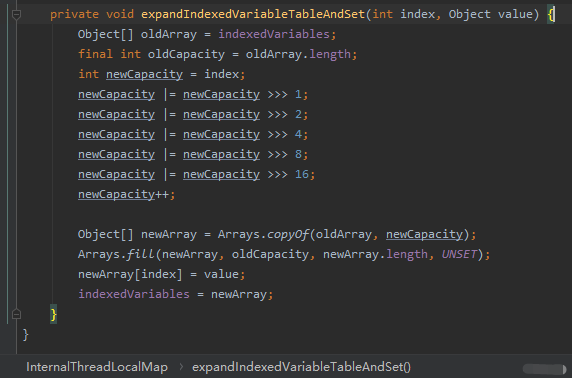
扩容是怎么扩的?
数组下标是怎么来的?
先看问题一,怎么扩容的?
看源码:
怎么样,看到的第一眼你想到了什么?
大声的说出来,是不是想到了 HashMap 里面的一段源码?
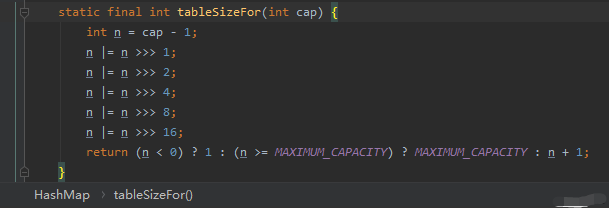
和 HashMap 里面的位运算异曲同工。
在 InternalThreadLocalMap 中扩容就是变成原来大小的 2 倍。从 32 到 64,从 64 到 128 这样。
扩容完成之后把原数组里面的值拷贝到新的数组里面去。
然后剩下的部分用 UNSET 填充。最后把我们传进来的 value 放到指定位置上。
再看看问题二,数组下标怎么来的?也就是这个 index:

从上往下看,可以看到最后,这个 index 本质上是一个 AtomicInteger 。
主要看一下标号为 ① 的地方。
index 每次都是加一,对应的是 InternalThreadLocalMap 里的数组下标。
第一眼看到的时候,里面的 if 判断 index<0 我是可以理解的,防止溢出嘛。
但是下面在抛出异常之前,还调用了 decrementAndGet 方法,又把值减回去了。
你说这是为什么?
开始我没想明白。但是有天晚上睡觉之前,电光火石一瞬间我想明白了。
如果不把值减回去,加一的代码还在不断的被调用,那么这个 index 理论上讲是有可能又被加到正数的,这一点你能明白吧?
为什么我说理论上呢?
int 的取值范围是 [-2147483648 到 2147483647]。
如果 int 从 0 增加,一直溢出到 -2147483648,再从 -2147483648 加到 0,中间有 4294967295 个数字。
一个数字对应数组的一个下标,就算里面放的是一个字节的 boolean 型,那么大概也就是 4T 的内存吧。
所以,我觉得这是理论上的。
到这一步,我们已经完成了从 Thread 里面取出 InternalThreadLocalMap ,并且往里面放数据的操作。
最后,InternalThreadLocal 的 set 方法只剩下最后一行代码,我们还没说:
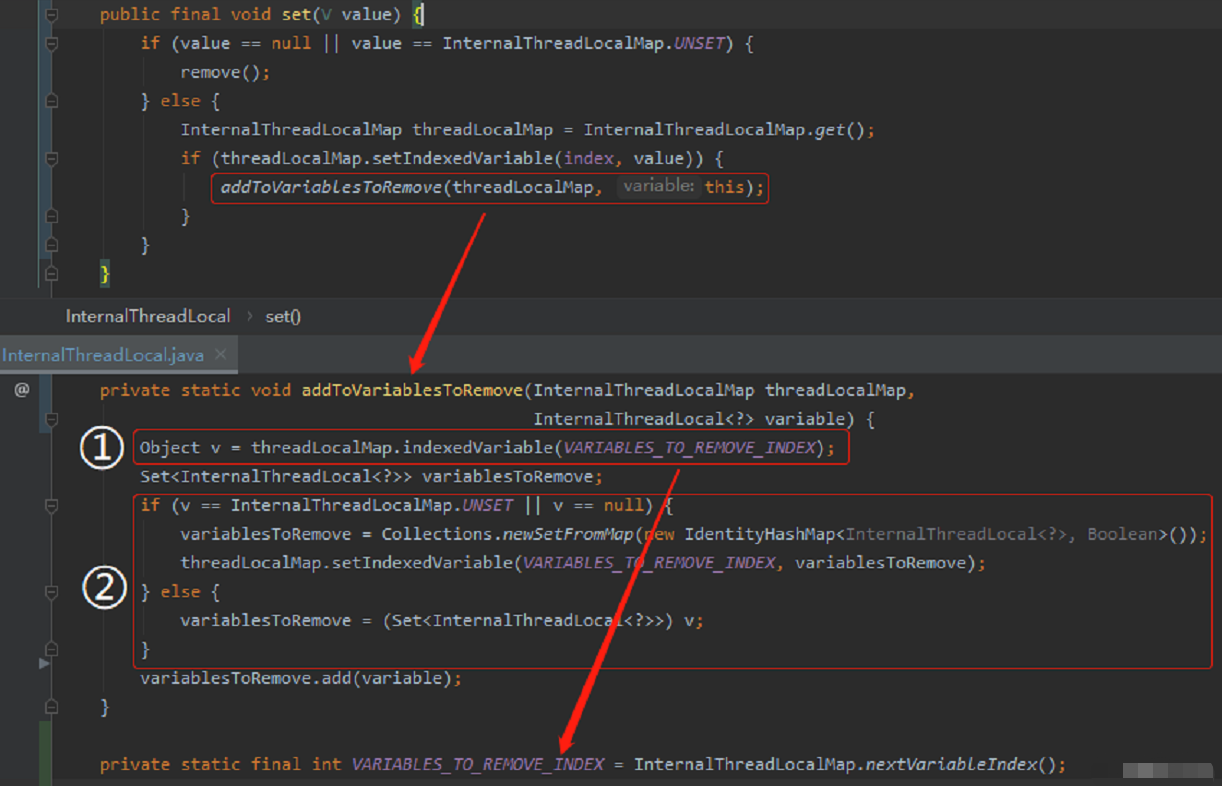
就是 setIndexedVariable 方法返回 true 后,会执行 addToVariablesToRemove 方法。
这个方法其实就是在数组的第一个位置维护当前线程里面的所有的 InternalThreadLocalMap 。
这里的关键点其实就是这个变量:

static final,能保证 VARIABLE_TO_REMOVE_INDEX 恒等于 0,也就是数组的第一个位置。
用示例程序,给大家演示一下,它第一个位置放的东西:

在第 21 行打上断点,然后看一下执行完 addToVariablesToRemove 方法后,InternalThreadLocalMap 数组的情况:

诚不欺你,第 0 个位置上放的是所有的 InternalThreadLocal 的集合。
所以,我们看一下它的 size 方法,就能明白这里为什么要减一了:
那么在第一个位置维护线程里面所有的 InternalThreadLocal 集合的用处是什么?
看看它的 removeAll 方法:

直接从数组中取出第 0 个位置的数据,然后循环干掉它就行。
set 方法就分析到这里啦,算是保姆级的一行行手把手教学了吧。
借助这个方法,也带大家看了内部结构。
点到为止。get 方法很简单的,大家记得自己去看一下哦。
我们再看一下这次 pr 提交的东西:
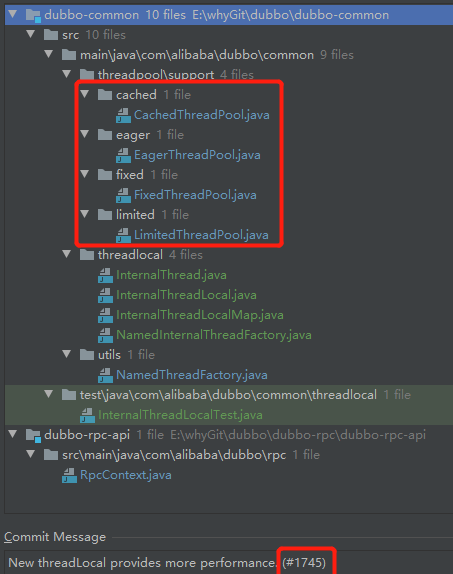
我们看看这四个线程池有什么变化:

就是换了工厂类。
换工厂类的目的是什么呢?
newThread 的时候,new 的是 InternalThread 线程。
好一个偷天换日。
前面我们说了,要用改造版的 ThreadLocal ,必须要配合 InternalThread 线程使用,否则就会退化为原生的 ThreadLocal 。
其实, Dubbo 这次提交,改造的东西并不多。关键的、核心的代码都是从 Netty 那边 copy 过来的。
我这就是一个引子,大家可以再去看看 Netty 的 FastThreadLocal 类。
关于这次 pr 提交
接下来又是 get 奇怪知识点的时刻了。
前面说了,这个 pr 里面出场人物一个比一个“骚”,这一节我带大家看一下,是怎么个“骚”法。
https://github.com/apache/dubbo/pull/1745·
首先是 pr 的提交者,carryxyh 同学的代码在 2018 年 5 月 15 日的时候被 merge 了:
正常来说,carryxyh 同学对于开源社区的一次贡献就算是完美结束了,简历上又可以浓墨重彩的写上一小笔。
但是 15 天之后发生的事情,可能是他做梦也想不到的。
那一天,一个叫做 normanmaurer 的哥们在这个 pr 下面说了一句话:
先不管他说的啥。
你知道他是谁吗?他在我之前的文章中其实也出现过的。
他就是 Netty 的爸爸。
他是这样说的:
他的意思就是说:
哥们,你这个东西我怎么觉得是从 Netty 那边弄过来的呢?本着开源的精神,你直接弄过来是没有问题的,但是你至少得按照规矩办事吧?得遵循 AL2 协议来。而且我甚至看到你在你的 pr 里面提到了 Netty 。
至于这个 AL2 到底是什么,我是没有看明白的。
但是不重要,我就把它理解为一个给开源社区贡献代码时需要遵守的一个协议吧。
carryxyh 同学看到 Netty 的爸爸找他了,很快就回复了两条消息:
carryxyh同学说道:
老哥,我在 javadoc 里面提到了,我的灵感来源就是 Netty 的 FastThreadLocal 类。我写这个的目的就是告诉所有看到这个类的朋友,这里的大部分代码来自 Netty。
那我除了在 javadoc 里面写上来源是 Netty 外,还需要做什么吗?还有你说的 AL2 是什么东西,你能不能告诉我?
我一定会尽快修复的。
这么一来一回,我大概明白这两个人在说什么了。
Netty 的爸爸说你用了我的代码,这完全没有问题,但是你得遵循一个协议哦。
carryxyh 同学说,我已经在 javadoc 里说了我这部分代码就是来自 Netty 的,我真不知道还该做什么,请你告诉我。
Netty 的爸爸回复了一个链接:
他说:你就看着这个链接,按照它整就行。
他发的这个链接我看了,怎么说呢,非常的哇塞,纯英文,内容非常的多。先不关注是啥吧,反正 carryxyh 同学肯定会认真阅读的。
在 carryxyh 同学没有回复之前,一个叫做 justinmclean 的哥们出来对 Netty 的爸爸说话了:
他说:实际上,ALv2 许可证已经不适用了,有新的政策出来了,以新的通知和许可证文件为准。
这个哥们既然这样轻描淡写的说有新政策了。我潜意识就觉得他不是一个一般人,于是我查了一下:
主席、30年+、PMC、导师......
还愣着干嘛,开始端茶吧。
大佬都出来了,接下来的对话大概也就是围绕着怎么才是一次符合开源标准的提交。
主席说,到底需不需要声明版权,得看代码的改造点多不多。
Netty 的爸爸说:据我所知,除了包名和类名不一样外,其他的基本没有变化。
最终 carryxyh 同学说把 Netty 的 FastThreadLocal 的文件头弄过来,是不是就完事了,
主席说:没毛病,我就是这样想的。
所以,我们现在在 Dubbo 的 InternalThreadLocal 文件的最开始,还可以看到这样的 Netty 的说明:

这个东西,就是这样来的,不是随便写的,是有讲究。

好了,这应该是我所有文章中出现过的第 9 个用不上的傻吊知识点了吧。送给你,不必客气。
好了,这次的文章就到这里啦。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


