
你好呀,我是歪歪。
这次给你盘一个特别有意思的源码,正如我标题说的那样:看懂这行源码之后,我不禁鼓起掌来,直呼祖师爷牛逼。
这行源码是这样的:
java.util.concurrent.LinkedBlockingQueue#dequeue

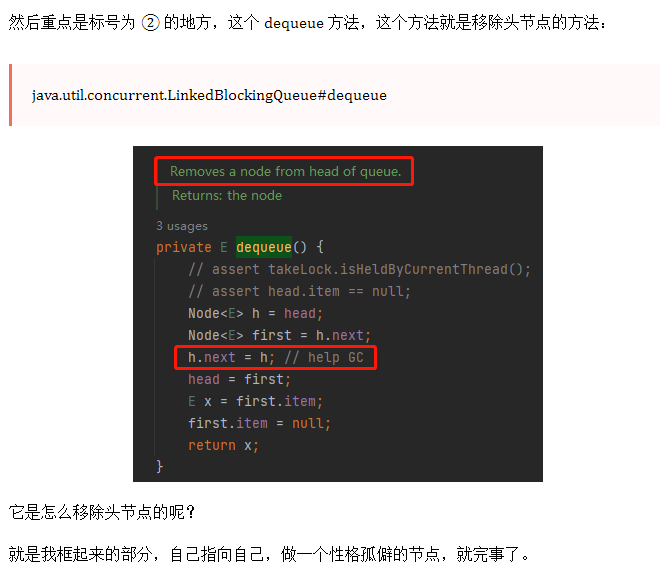
h.next = h,不过是一个把下一个节点指向自己的动作而已。
这行代码后面的注释“help GC”其实在 JDK 的源码里面也随处可见。
不管怎么看都是一行平平无奇的代码和随处可见的注释而已。
但是这行代码背后隐藏的故事,可就太有意思了,真的牛逼,儿豁嘛。

它在干啥。
首先,我们得先知道这行代码所在的方法是在干啥,然后再去分析这行代码的作用。
所以老规矩,先搞个 Demo 出来跑跑:
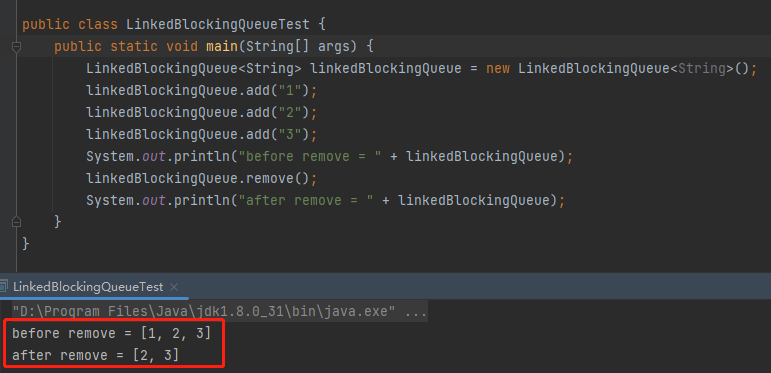
在 LinkedBlockingQueue 的 remove 方法中就调用了 dequeue 方法,调用链路是这样的:
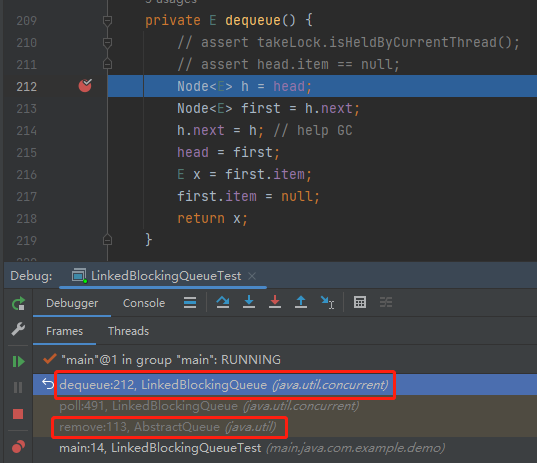
这个方法在 remove 的过程中承担一个什么样的角色呢?
这个问题的答案可以在方法的注释上找到:
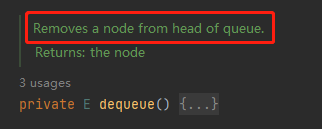
这个方法就是从队列的头部,删除一个节点,其他啥也不干。
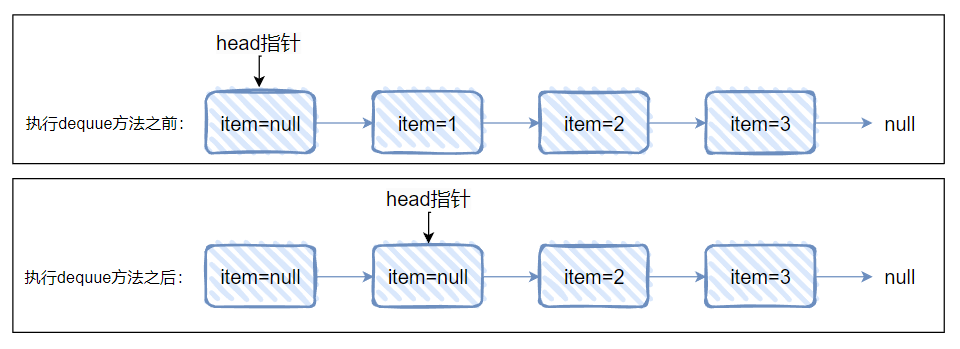
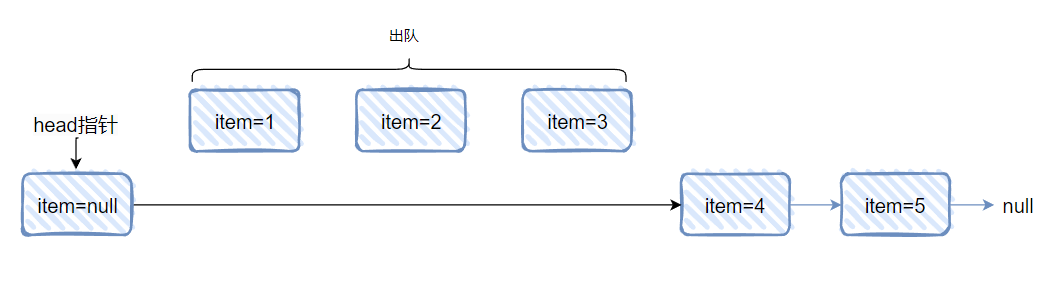
就拿 Demo 来说,在执行这个方法之前,我们先看一下当前这个链表的情况是怎么样的:
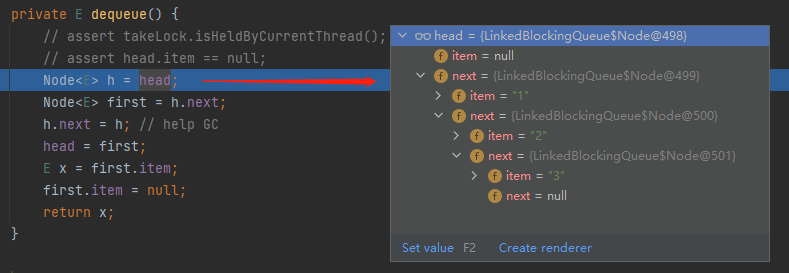
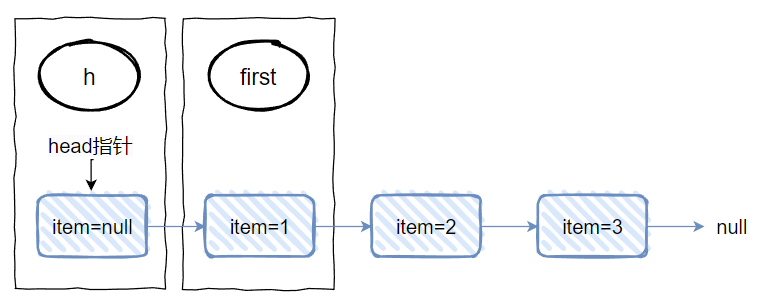
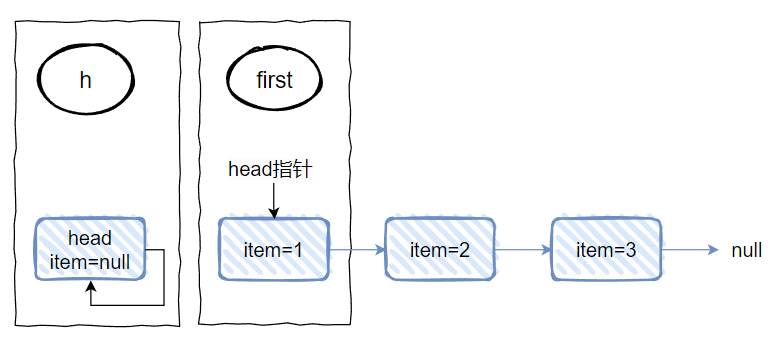
这是一个单向链表,然后 head 结点里面没有元素,即 item=null,对应做个图出来就是这样的:
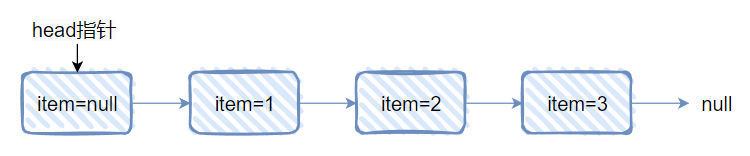
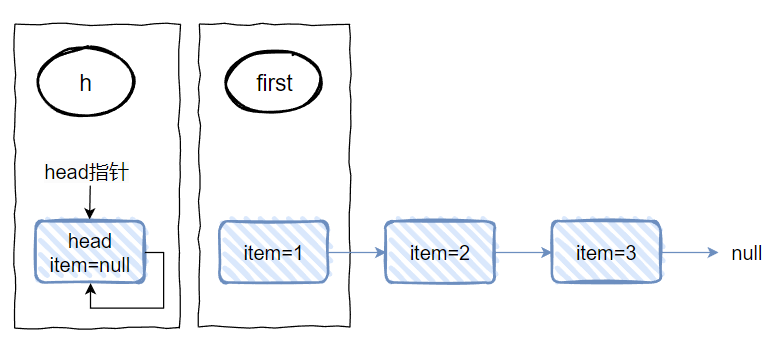
当执行完这个方法之后,链表变成了这样:
再对应做个图出来,就是这样的:
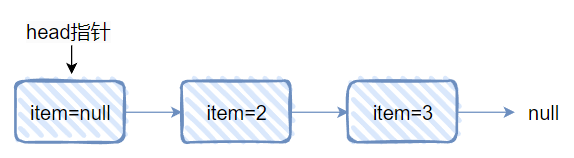
可以发现 1 没了,因为它是真正的“头节点”,所以被 remove 掉了。
这个方法就干了这么一个事儿。
虽然它一共也只有六行代码,但是为了让你更好的入戏,我决定先给你逐行讲解一下这个方法的代码,讲着讲着,你就会发现,诶,问题它就来了。

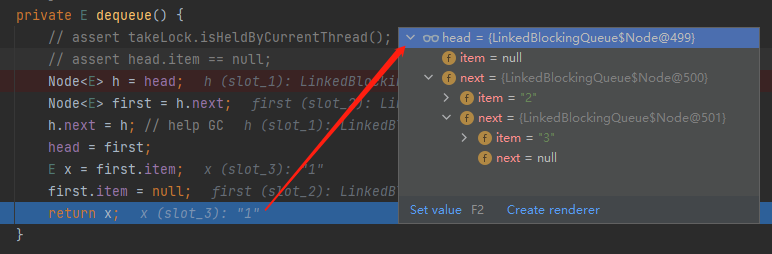
首先,我们回到方法入口处,也就是回到这个时候:
前两行方法是这样的:
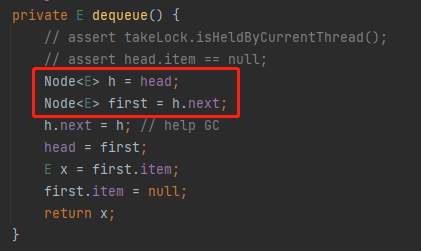
对应到图上,也就是这样的:
h 对应的是 head 节点 first 对应的是 “1” 节点
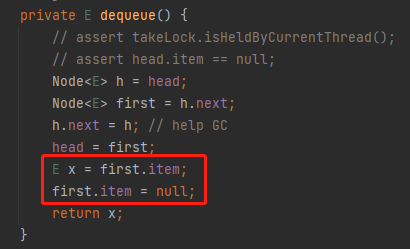
然后,来到第三行:
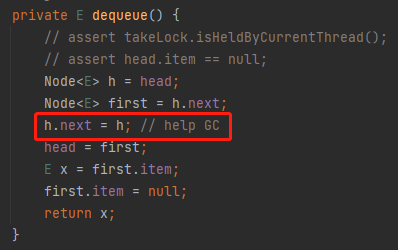
h 的 next 还是 h,这就是一个自己指向自己的动作,对应到图上是这样的:
然后,第四行代码:
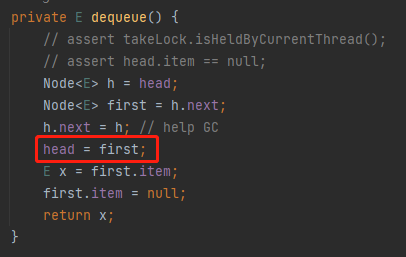
把 first 变成 head:
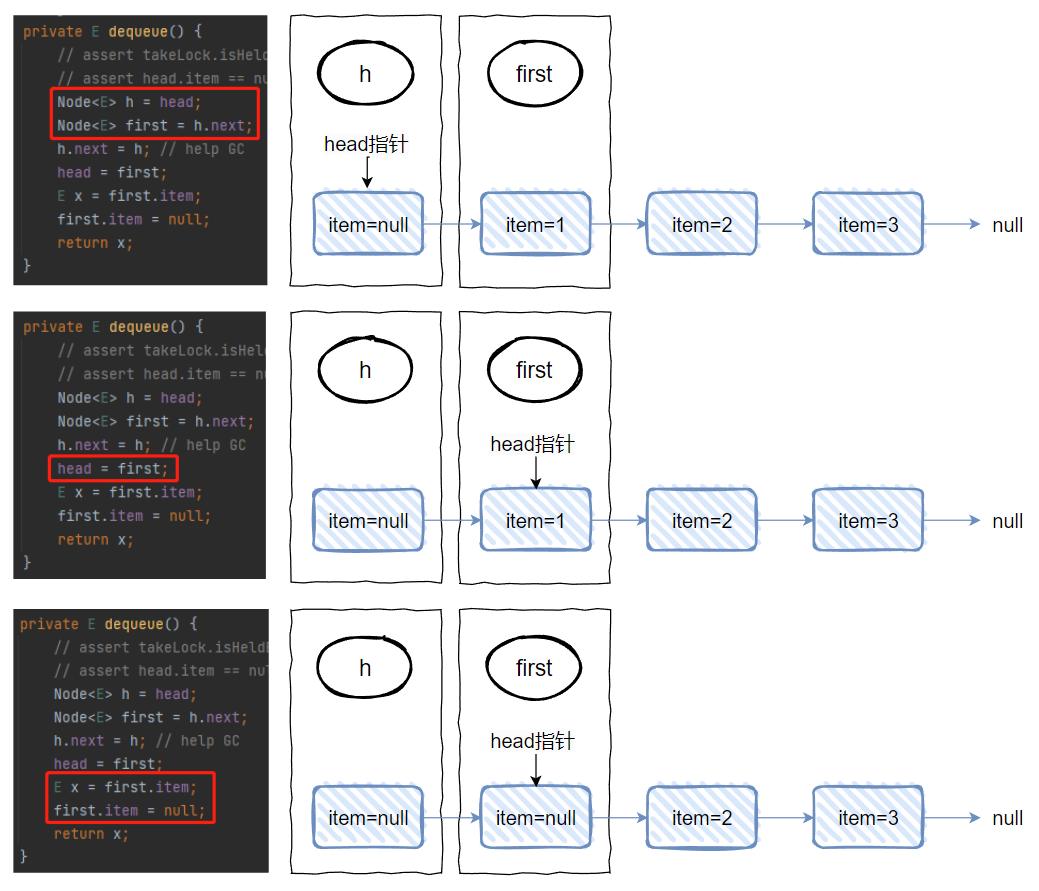
最后,第五行和第六行:
拿到 first 的 item 值,作为方法的返回值。然后再把 first 的 item 值设置为 null。
对应到图中就是这样,第五行的 x 就是 1,第六行执行完成之后,图就变成了这样:

整个链表就变成了这样:

那么现在问题来了:
如果我们没有 h.next=h 这一行代码,会出现什么问题呢?
我也不知道,但是我们可以推演一下:
也就是最终我们得到的是这样的一个链表:
这个时候我们发现,由于 head 指针的位置已经发生了变化,而且这个链表又是一个单向链表,所以当我们使用这个链表的时候,没有任何问题。
而这个对象:

已经没有任何指针指向它了,那么它不经过任何处理,也是可以被 GC 回收掉的。
对吗?
你细细的品一品,是不是这个道理,从 GC 的角度来说它确实是“不可达了”,确实可以被回收掉了。

所以,当时有人问了我这样的一个问题:

我经过上面的一顿分析,发现:嗯,确实是这样的,确实没啥卵用啊,不写这一行代码,功能也是完成正常的。
但是当时我是这样回复的:

我没有把话说满,因为这一行故意写了一行“help GC”的注释,可能有 GC 方面的考虑。
那么到底有没有 GC 方面的考虑,是怎么考虑的呢?
凭借着我这几年写文章的敏锐嗅觉,我觉得这里“大有文章”,于是我带着这个问题,在网上溜达了一圈,还真有收获。
help GC?
首先,一顿搜索,排除了无数个无关的线索之后,我在 openjdk 的 bug 列表里面定位到了这样的一个链接:
https://bugs.openjdk.org/browse/JDK-6805775
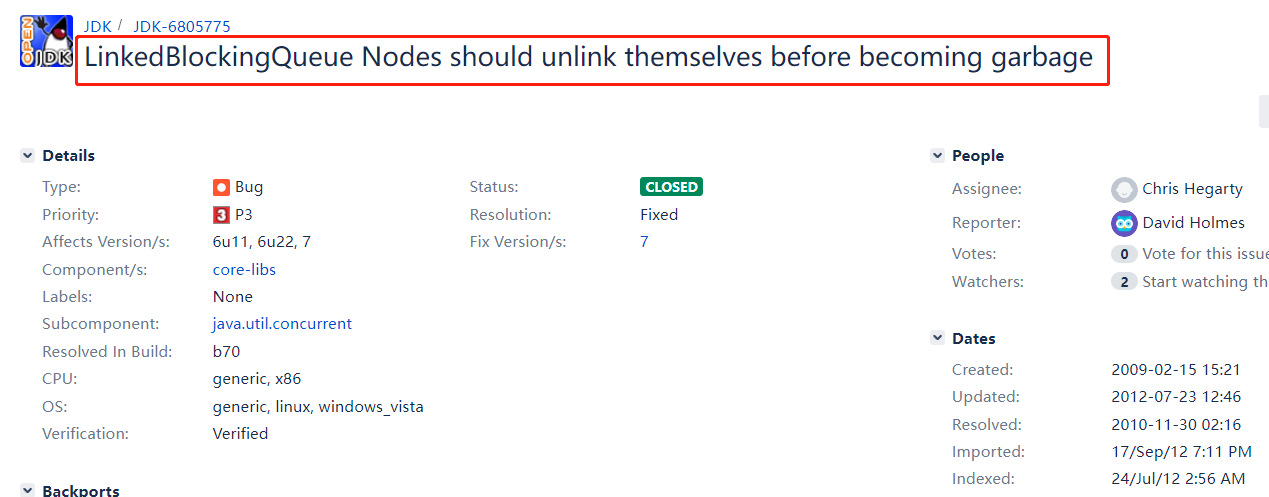
点击进这个链接的原因是标题当时就把吸引到了,翻译过来就是说:LinkedBlockingQueue 的节点应该在成为“垃圾”之前解除自己的链接。
先不管啥意思吧,反正 LinkedBlockingQueue、Nodes、unlink、garbage 这些关键词是完全对上了。
于是我看了一下描述部分,主要关心到了这两个部分:
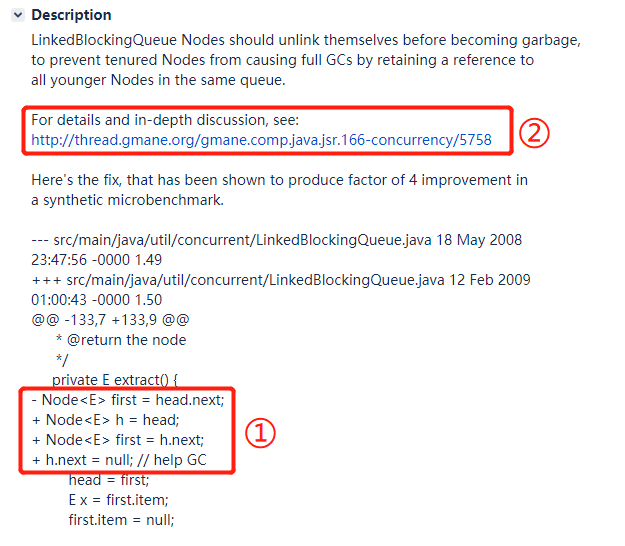
看到标号为 ① 的地方,我才发现在 JDK 6 里面对应实现是这样的:

而且当时的方法还是叫 extract 而不是 dequeue。
这个方法名称的变化,也算是一处小细节吧。

dequeue 是一个更加专业的叫法:

仔细看 JDK 6 中的 extract 方法,你会发现,根本就没有 help GC 这样的注释,也没有相关的代码。
它的实现方式就是我前面画图的这种:
也就是说这行代码一定是出于某种原因,在后面的 JDK 版本中加上的。那么为什么要进行标号为 ① 处那样的修改呢?
标号为 ② 的地方给到了一个链接,说是这个链接里面有关于这个问题深入的讨论。
For details and in-depth discussion, see:
http://thread.gmane.org/gmane.comp.java.jsr.166-concurrency/5758
我非常确信我找对了地方,而且我要寻找的答案就在这个链接里面。
但是当我点过去的时候,我发现不管怎么访问,这个链接访问不到了...
虽然这里的线索断了,但是顺藤摸瓜,我找到了这个 BUG 链接:
https://bugs.openjdk.org/browse/JDK-6806875
这两个 BUG 链接说的其实是同一个事情,但是这个链接里面给了一个示例代码。
这个代码比较长,我给你截个图,你先不用细看,只是对比我框起来的两个部分,你会发现这两部分的代码其实是一样的:
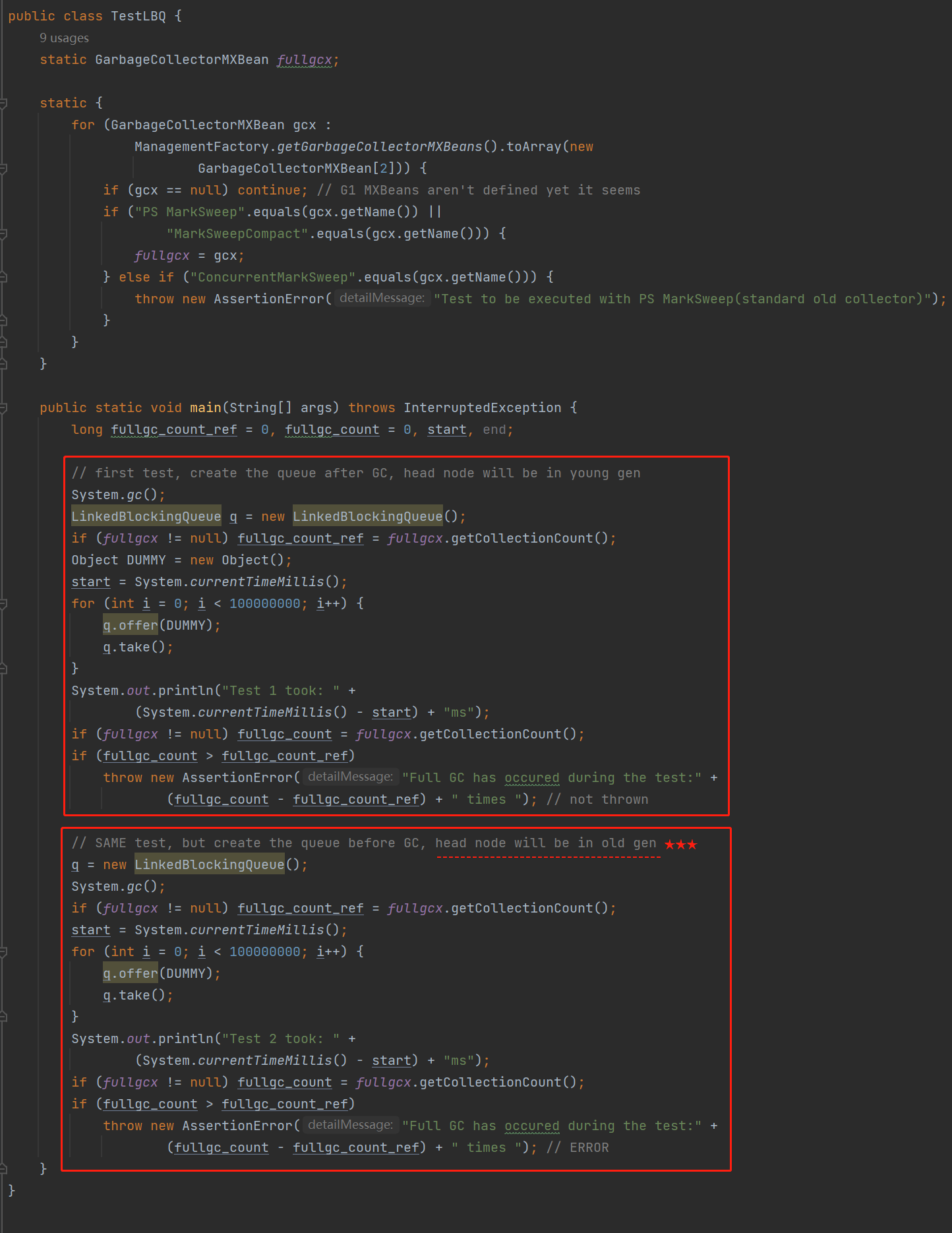
当 LinkedBlockingQueue 里面加入了 h.next=null 的代码,跑上面的程序,输出结果是这样:

但是,当 LinkedBlockingQueue 使用 JDK 6 的源码跑,也就是没有 h.next=null 的代码跑上面的程序,输出结果是这样:

产生了 47 次 FGC。
这个代码,在我的电脑上跑,我用的是 JDK 8 的源码,然后注释掉 h.next = h 这行代码,只是会触发一次 FGC,时间差距是 2 倍:
加上 h.next = h,两次时间就相对稳定:

好,到这里,不管原理是什么,我们至少验证了,在这个地方必须要 help GC 一下,不然确实会有性能影响。
但是,到底是为什么呢?

在反复仔细的阅读了这个 BUG 的描述部分之后,我大概懂了。
最关键的一个点其实是藏在了前面示例代码中我标注了五角星的那一行注释:
SAME test, but create the queue before GC, head node will be in old gen(头节点会进入老年代)
我大概知道问题的原因是因为“head node will be in old gen”,但是具体让我描述出来我也有点说不出来。
说人话就是:我懂一点,但是不多。
于是又经过一番查找,我找到了这个链接,在这里面彻底搞明白是怎么一回事了:
http://concurrencyfreaks.blogspot.com/2016/10/self-linking-and-latency-life-of.html
在这个链接里面提到了一个视频,它让我从第 23 分钟开始看:
我看了一下这个视频,应该是 2015 年发布的。因为整个会议的主题是:20 years of Java, just the beginning:
https://www.infoq.com/presentations/twitter-services/

这个视频的主题是叫做“Life if a twitter JVM engineer”,是一个 twitter 的 JVM 工程师在大会分享的在工作遇到的一些关于 JVM 的问题。
虽然是全程英文,但是你知道的,我的 English level 还是比较 high 的。
日常听说,问题不大。所以大概也就听了个几十遍吧,结合着他的 PPT 也就知道关于这个部分他到底在分享啥了。
我要寻找的答案,也藏在这个视频里面。
我挑关键的给你说。
首先他展示了这样的这个图片:
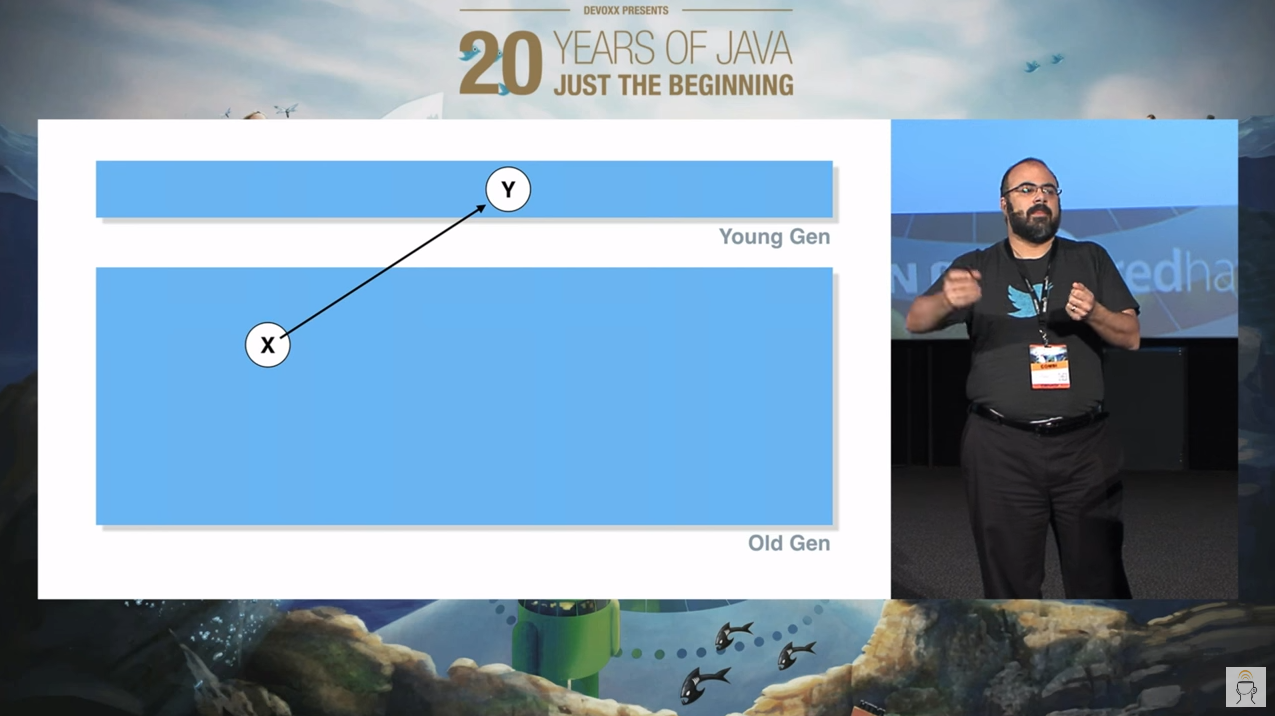
老年代的 x 对象指向了年轻代的 y 对象。一个非常简单的示意图,他主要是想要表达“跨代引用”这个问题。
然后,出现了这个图片:
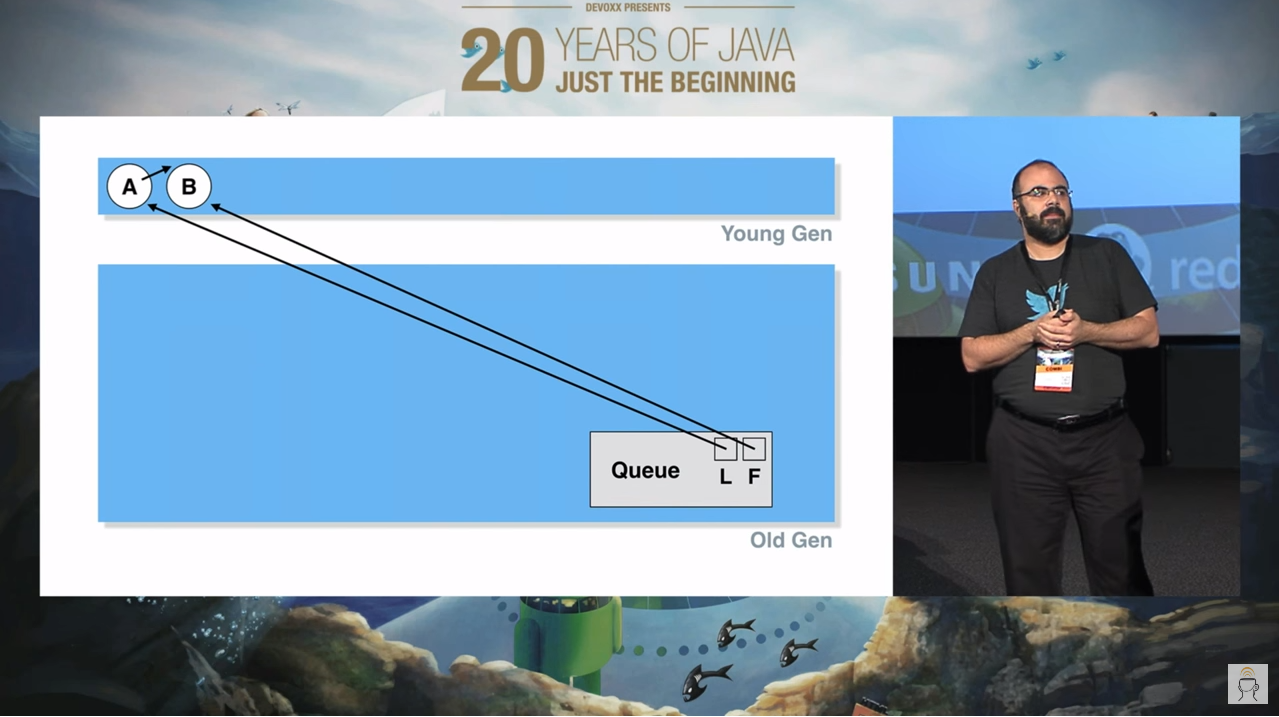
这里的 Queue 就是本文中讨论的 LinkedBlockingQueue。
首先可以看到整个 Queue 在老年代,作为一个队列对象,极有可能生命周期比较长,所以队列在老年代是一个正常的现象。
然后我们往这个队列里面插入了 A,B 两个元素,由于这两个元素是我们刚刚插入的,所以它们在年轻代,也没有任何毛病。
此时就出现了老年代的 Queue 对象,指向了位于年轻代的 A,B 节点,这样的跨代引用。
接着,A 节点被干掉了,出队:

A 出队的时候,由于它是在年轻代的,且没有任何老年代的对象指向它,所以它是可以被 GC 回收掉的。
同理,我们插入 D,E 节点,并让 B 节点出队:
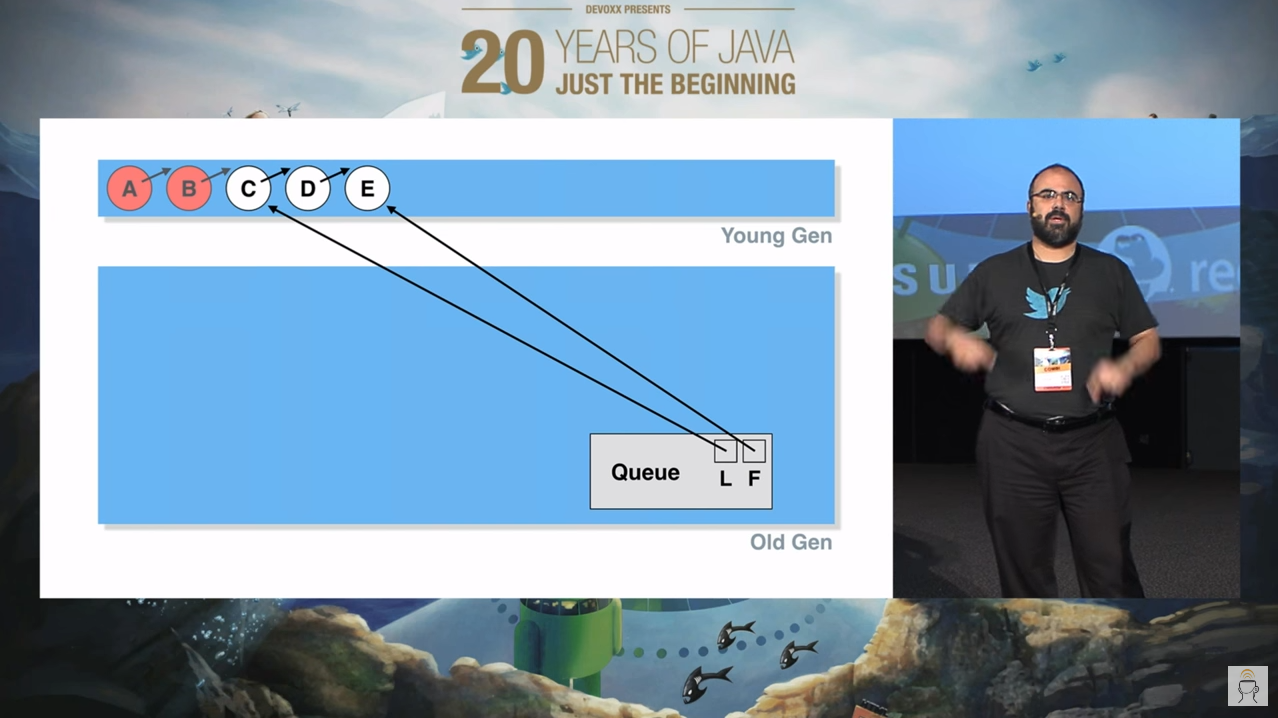
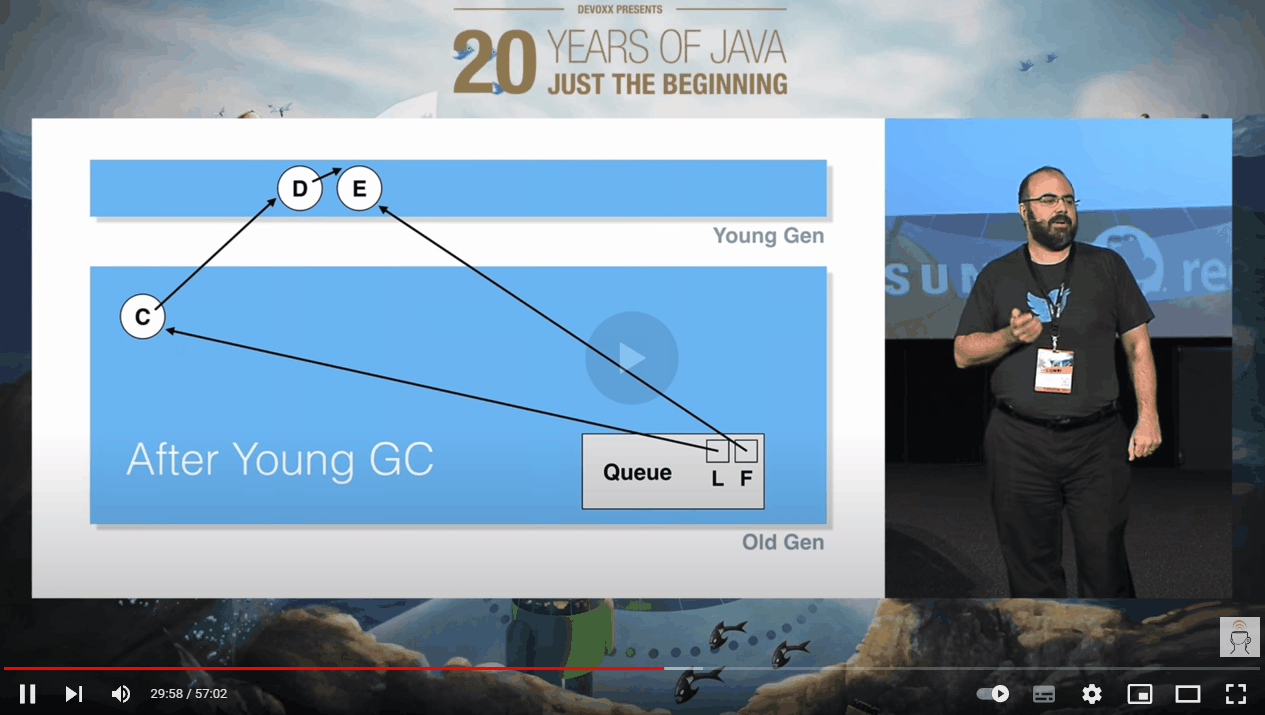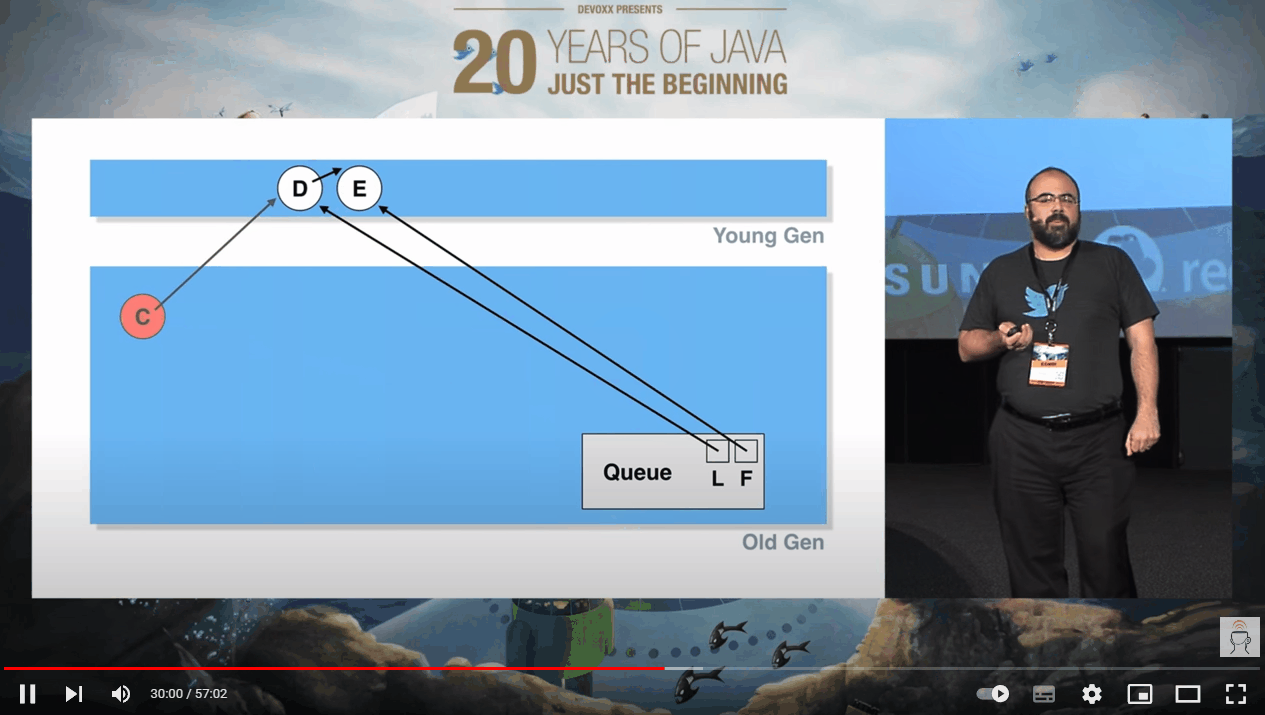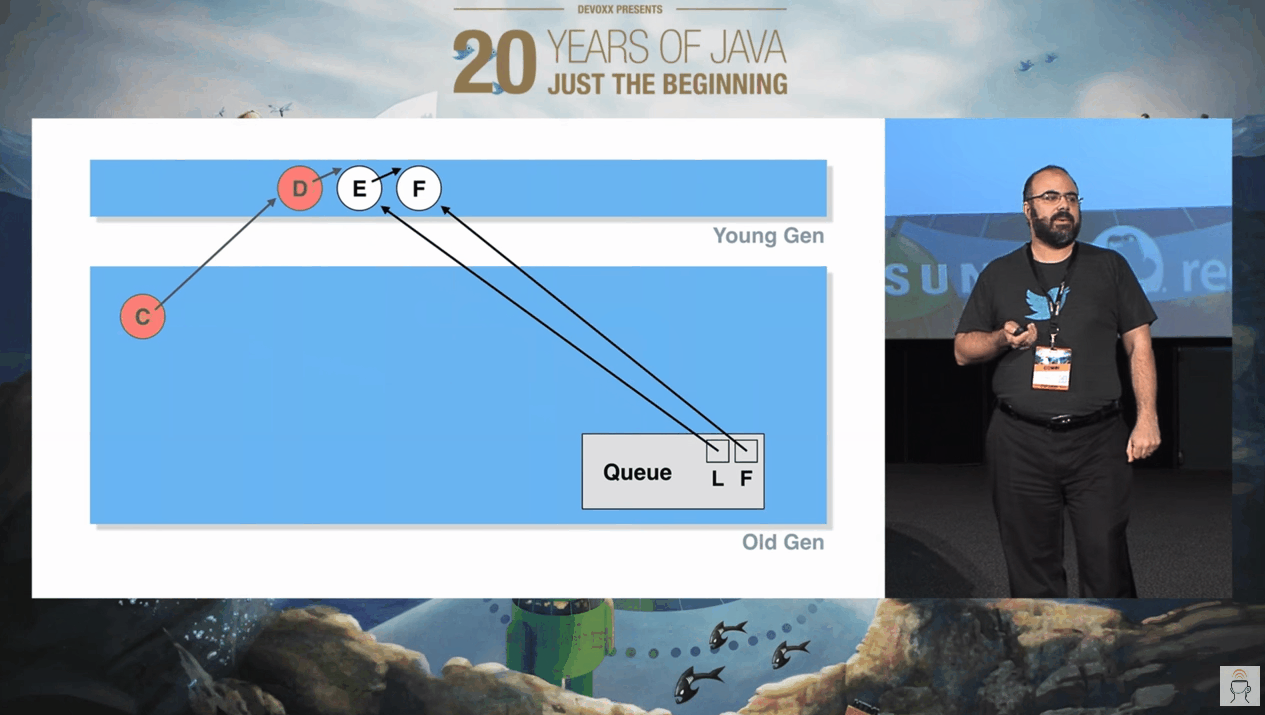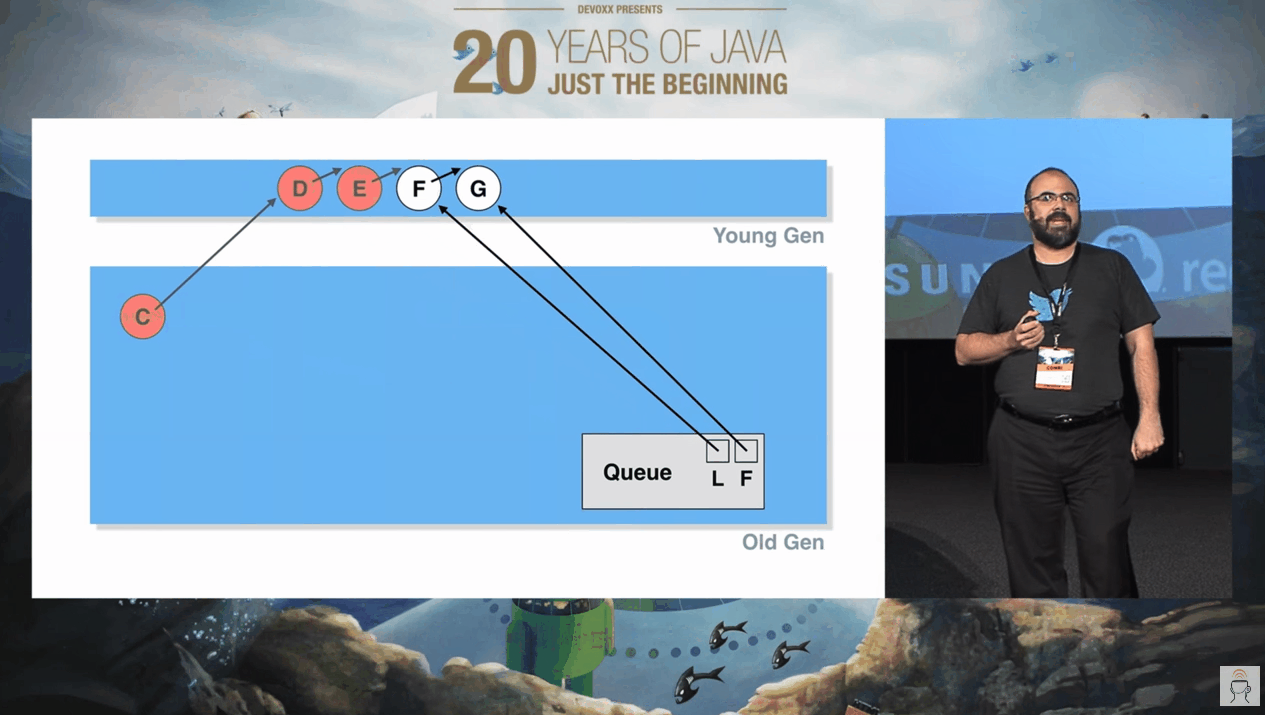
假设此时发生一次 YGC, A,B 节点由于“不可达”被干掉了,C 节点在经历几次 YGC 之后,由于不是“垃圾”,所以晋升到了老年代:
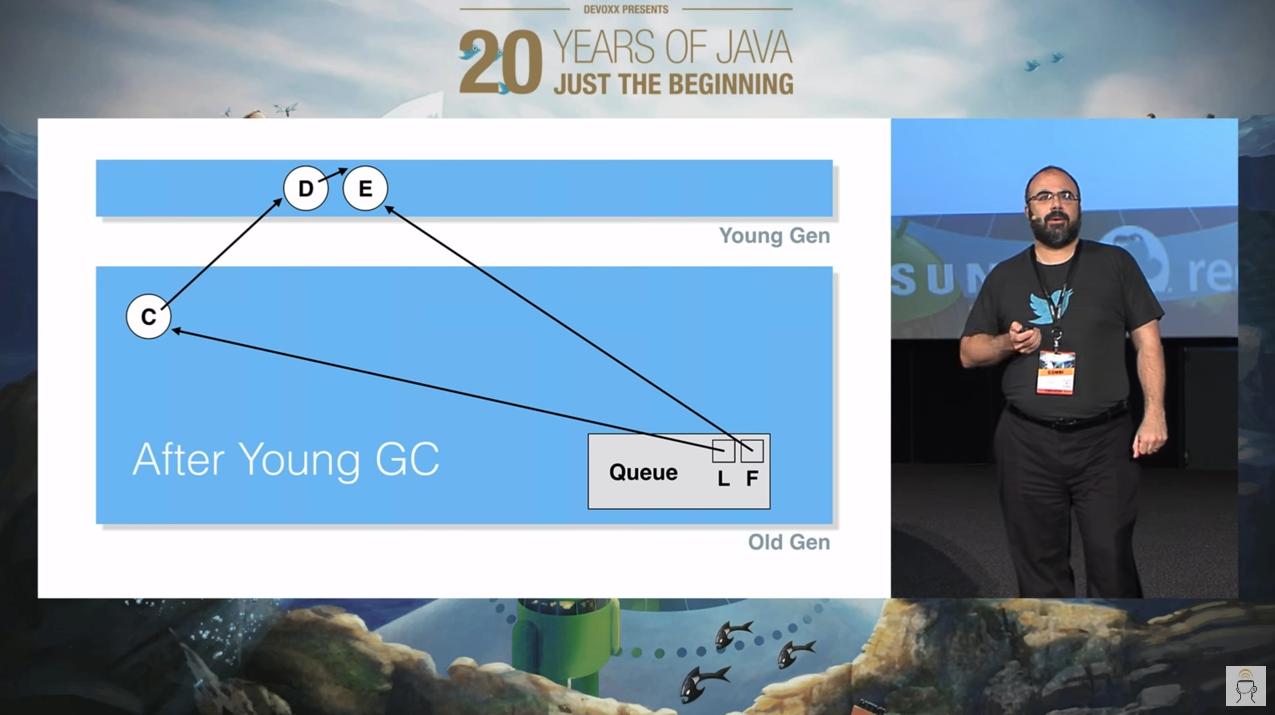
这个时候假设 C 出队,你说会出现什么情况?

首先,我问你:这个时候 C 出队之后,它是否是垃圾?
肯定是的,因为它不可达了嘛。从图片上也可以看到,C 虽然在老年代,但是没有任何对象指向它了,它确实完犊子了:
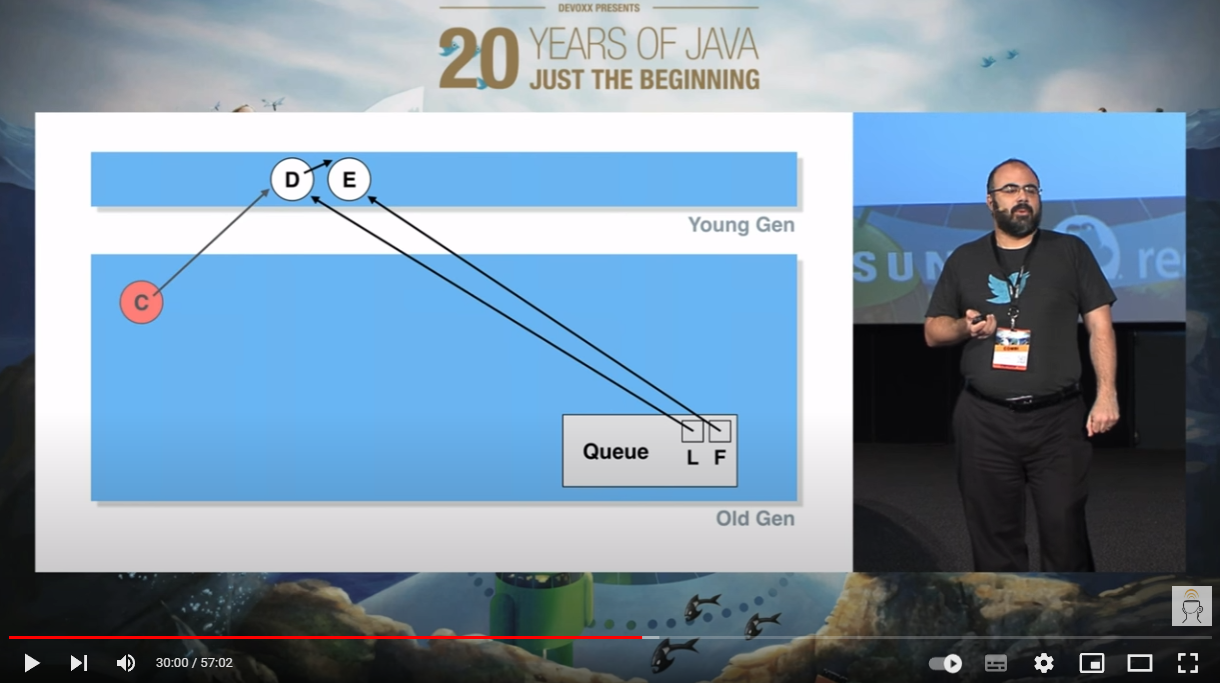
好,接下来,请坐好,认真听了。
此时,我们加入一个 F 节点,没有任何毛病:
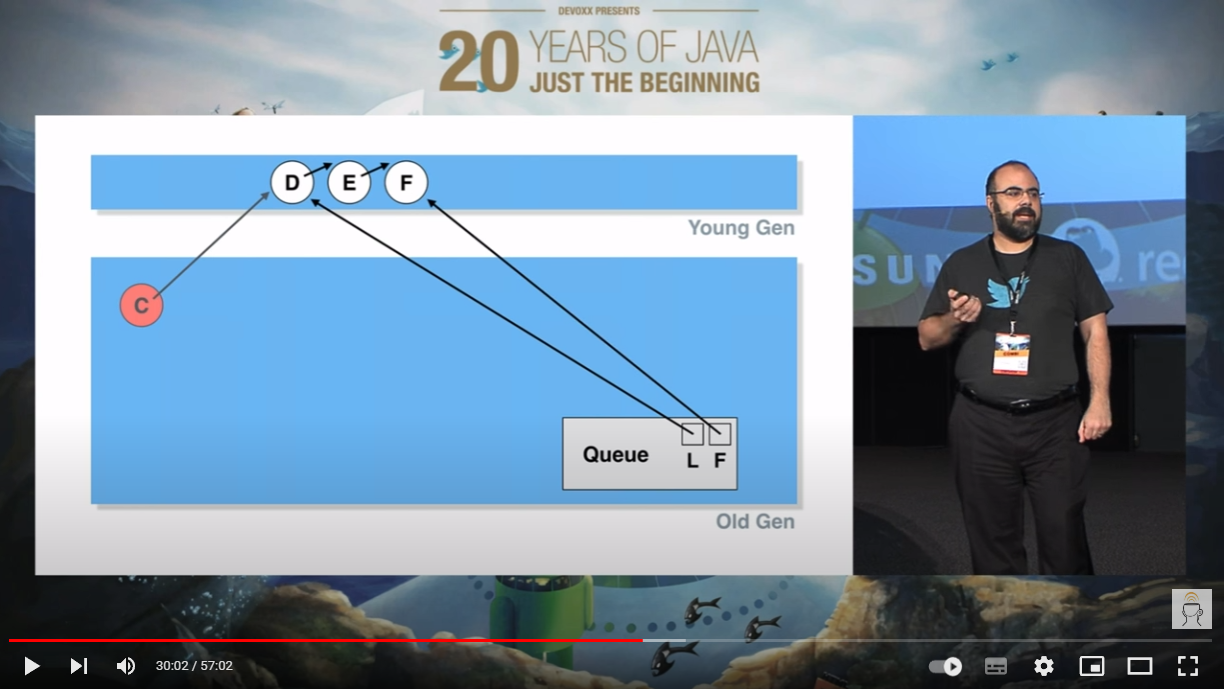
接着 D 元素被出队了:

就像下面这个动图一样:
我把这一帧拿出来,针对这个 D 节点,单独的说:
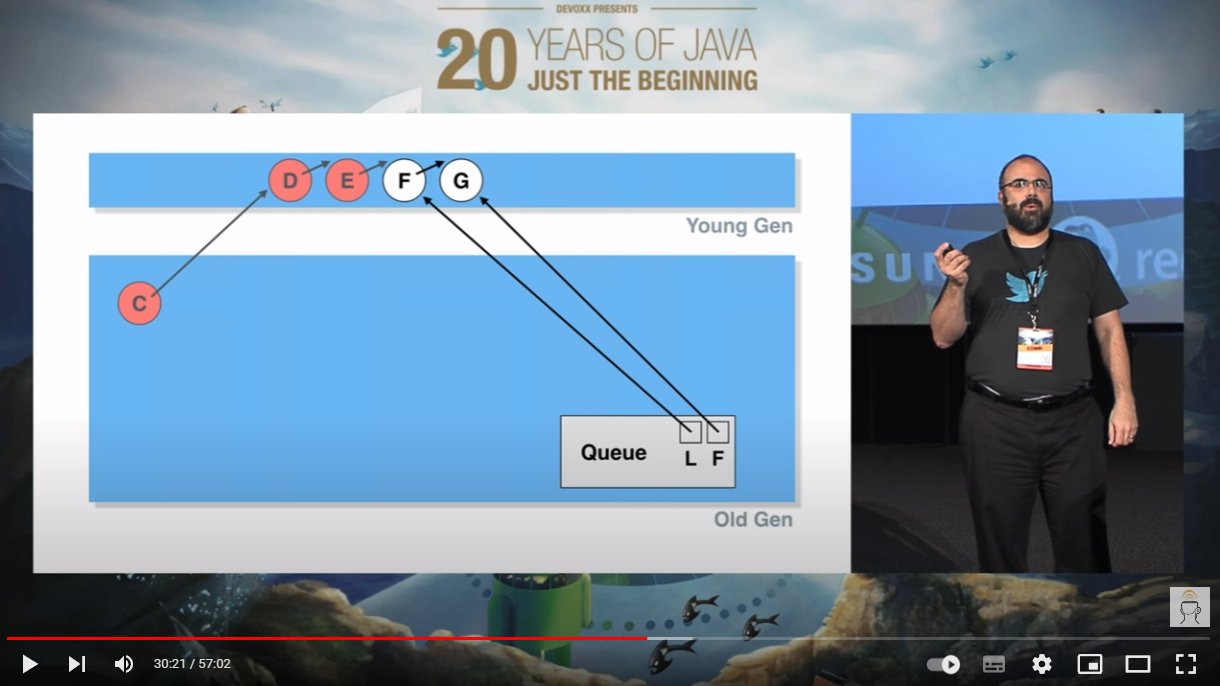
假设在这个时候,再次发生 YGC,D 节点虽然出队了,它也位于年轻代。但是位于老年代的 C 节点还指向它,所以在 YGC 的时候,垃圾回收线程不敢动它。
因此,在几轮 YGC 之后,本来是“垃圾”的 D,摇身一变,进入老年代了:
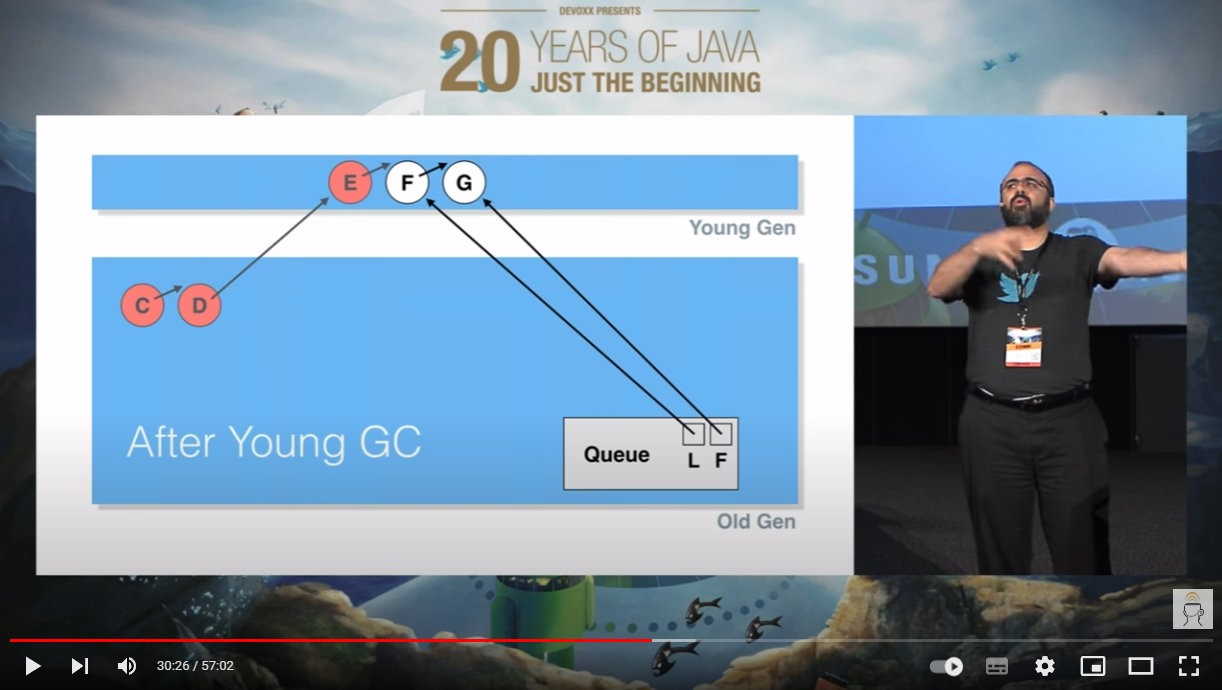
虽然它依然是“垃圾”,但是它进入了老年代,YGC 对它束手无策,得 FGC 才能干掉它了。
然后越来越多的出队节点,变成了这样:

然后,他们都进入了老年代:
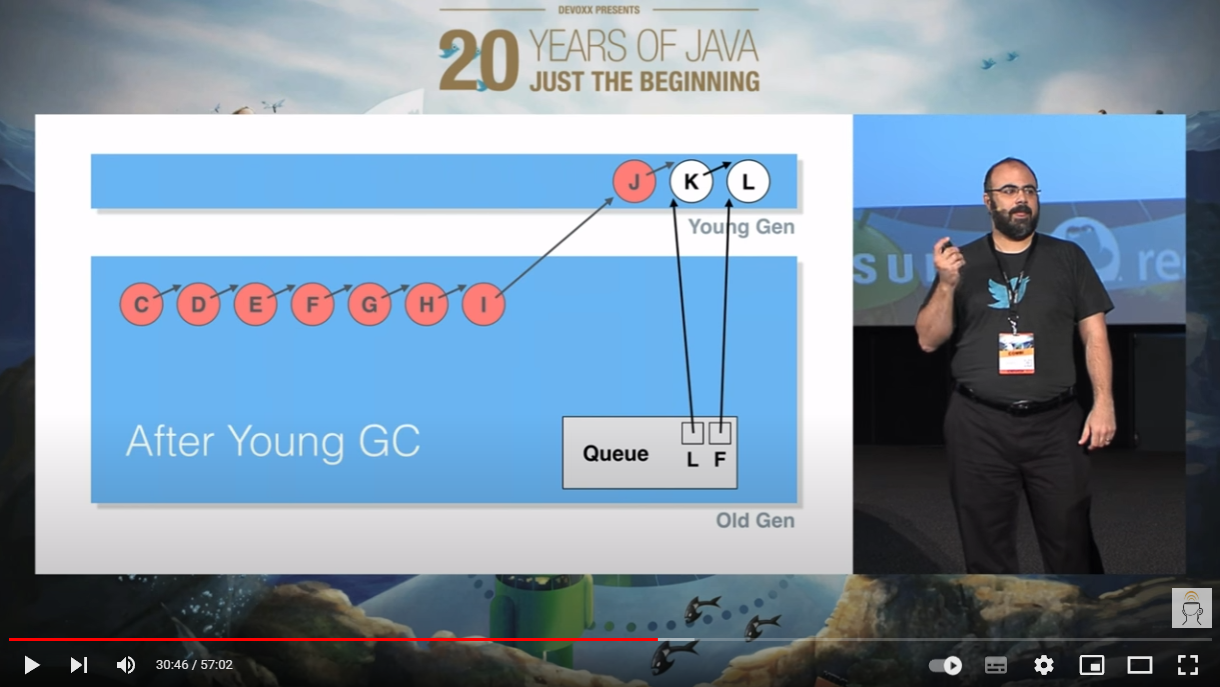
我们站在上帝视角,我们知道,这一串节点,应该在 YGC 的时候就被回收掉。
但是这种情况,你让 GC 怎么处理?
它根本就处理不了。
GC 线程没有上帝视角,站在它的视角,它做的每一步动作都是正确的、符合规定的。最终呈现的效果就是必须要经历 FGC 才能把这些本来早就应该回收的节点,进行回收。而我们知道,FGC 是应该尽量避免的,所以这个处置方案,还是“差点意思”的。
所以,我们应该怎么办?
你回想一下,万恶之源,是不是这个时候:
C 虽然被移出队列了,但是它还持有一个下一个节点的引用,让这个引用变成跨代引用的时候,就出毛病了。
所以,help GC,这不就来了吗?

不管你是位于年轻代还是老年代,只要是出队,就把你的 next 引用干掉,杜绝出现前面我们分析的这种情况。
这个时候,你再回过头去看前面提到的这句话:
head node will be in old gen...
你就应该懂得起,为什么 head node 在 old gen 就要出事儿。
h.next=null ???
前面一节,经过一顿分析之后,知道了为什么要有这一行代码:
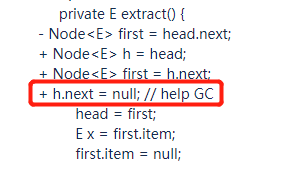
但是你仔细一看,在我们的源码里面是 h.hext=h 呀?
而且,经过前面的分析我们可以知道,理论上,h.next=null 和 h.hext=h 都能达到 help GC 的目的,那么为什么最终的写法是 h.hext=h 呢?
或者换句话说:为什么是 h.next=h,而不是 h.next=null 呢?
针对这个问题,我也盯着源码,仔细思考了很久,最终得出了一个“非常大胆”的结论是:这两个写法是一样的,不过是编码习惯不一样而已。
但是,注意,我要说但是了。
再次经过一番查询、分析和论证,这个地方它还必须得是 h.next=h。
因为在这个 bug 下面有这样的一句讨论:

关键词是:weakly consistent iterator,弱一致性迭代器。也就是说这个问题的答案是藏在 iterator 迭代器里面的。
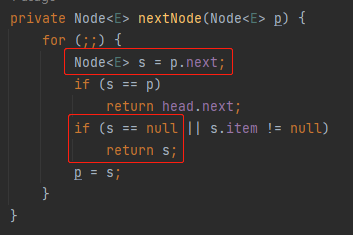
在 iterator 对应的源码中,有这样的一个方法:
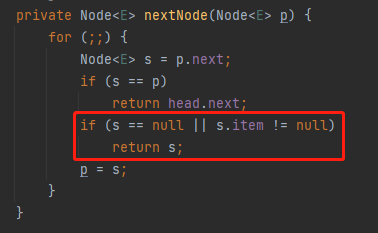
java.util.concurrent.LinkedBlockingQueue.Itr#nextNode
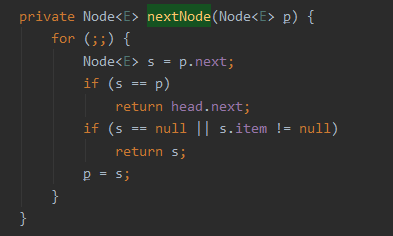
针对 if 判断中的 s==p,我们把 s 替换一下,就变成了 p.next=p:
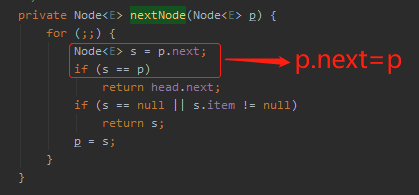
那么什么时候会出现 p.next=p 这样的代码呢?
答案就藏在这个方法的注释部分:dequeued nodes (p.next == p)
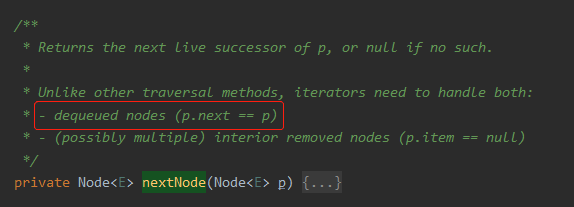
dequeue 这不是巧了吗,这不是和前面给呼应起来了吗?
好,到这里,我要开始给你画图说明了,假设我们 LinkedBlockingQueue 里面放的元素是这样的:
画图出来就是这样的:

现在我们要对这个链表进行迭代,对应到画图就是这样的:
linkedBlockingQueue.iterator();

看到这个图的时候,问题就来了:current 指针是什么时候冒出来的呢?
current,这个变量是在生成迭代器的时候就初始化好了的,指向的是 head.next:
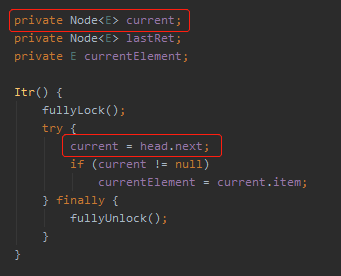
然后 current 是通过 nextNode 这个方法进行维护的:

正常迭代下,每调用一次都会返回 s,而 s 又是 p.next,即下一个节点:
所以,每次调用之后 current 都会移动一格:
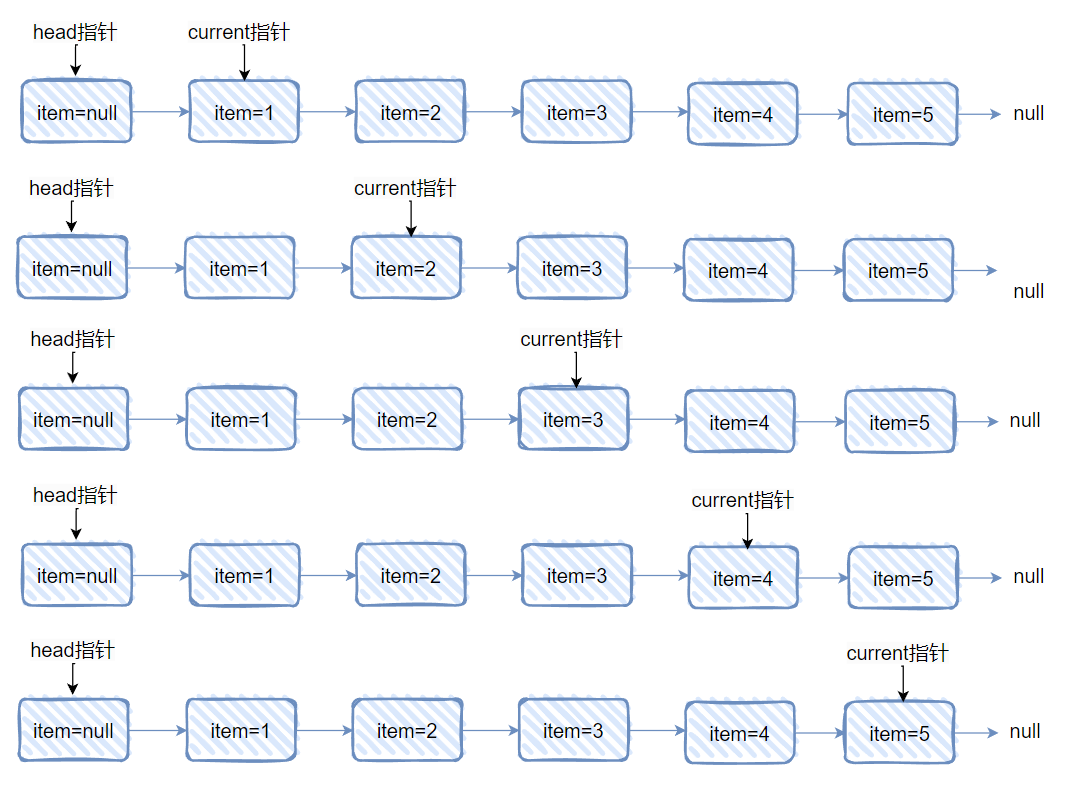
这种情况,完全就没有这个分支的事儿:
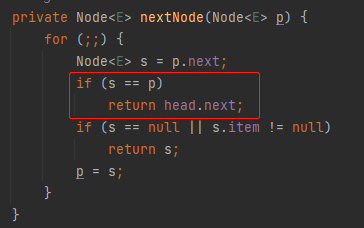
什么时候才会和它扯上关系呢?
你想象一个场景。
A 线程刚刚要对这个队列进行迭代,而 B 线程同时在对这个队列进行 remove。
对于 A 线程,刚刚开始迭代,画图是这样的:

然后 current 还没开始移动呢,B 线程“咔咔”几下,直接就把 1,2,3 全部给干出队列了,于是站在 B 线程的视角,队列是这样的了:

到这里,你先思考一个问题:1,2,3 这几个节点,不管是自己指向自己,还是指向一个 null,此时发生一个 YGC 它们还在不在?
2 和 3 指定是没了,但是 1 可不能被回收了啊。
因为虽然元素为 1 的节点出队了,但是站在 A 线程的视角,它还持有一个 current 引用呢,它还是“可达”的。
所以,这个时候 A 线程开始迭代,虽然 1 被 B 出队了,但是它一样会被输出。
然后,我们再来对于下面这两种情况,A 线程会如何进行迭代:
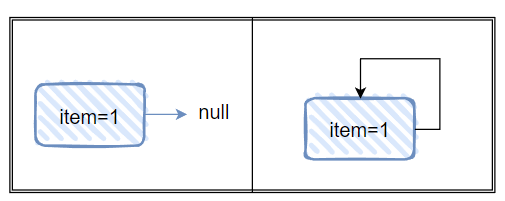
当 1 节点的 next 指为 null 的时候,即 p.next 为 null,那么满足 s==null 的判断,所以 nextNode 方法就会返回 s,也就是返回了 null:
当你调用 hasNext 方法判断是否还有下一节点的时候,就会返回 false,循环就结束了:
然后,我们站在上帝视角是知道的,后面还有 4 和 5 没输出呢,所以这样就会出现问题。
但是,当 1 节点的 next 指向自己的时候,有趣的事情就来了:
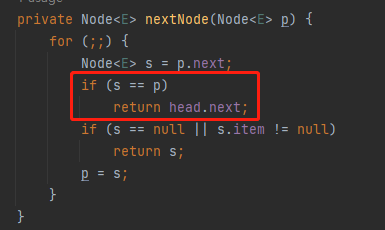
current 指针就变成了 head.next。
而你看看当前的这个链表里面 head.next 是啥?
不就是 4 节点吗?
这不就衔接上了吗?
所以最终 A 线程会输出 1,4,5。
虽然我们知道 1 元素其实已经出队了,但是 A 线程开始迭代的时候,它至少还在。
这玩意就体现了前面提到的: weakly consistent iterator,弱一致性迭代器。
这个时候,你再结合者迭代器上的注解去看,就能搞得明明白白了:
如果 hasNext 方法返回为 true,那么就必须要有下一个节点。即使这个节点被比如 take 等等的方法给移除了,也需要返回它。这就是 weakly-consistent iterator。
然后,你再看看整个类开始部分的 Java doc,其实我整篇文章就是对于这一段描述的翻译和扩充:

看完并理解我这篇文章之后,你再去看这部分的 Java doc,你就知道它是在说个啥事情,以及它为什么要这样的去做这件事情了。
好了,看到这里,你现在应该明白了,为什么必须要有 h.next=h,为什么不能是 h.next=null 了吧?
明白了就好。
因为本文就到这里就要结束了。
如果你还没明白,不要怀疑自己,大胆的说出来:什么玩意?写的弯弯绕绕的,看求不懂。呸,垃圾作者。

最后,我还想要说的是,关于 LBQ 这个队列,我之前也写过这篇文章专门说它:《喜提JDK的BUG一枚!多线程的情况下请谨慎使用这个类的stream遍历。》
文章里面也提到了 dequeue 这个方法:
但是当时我完全没有思考到文本提到的问题,顺着代码就捋过去了。
我觉得看到这部分代码,然后能提出本文中这两个问题的人,才是在带着自己思考深度阅读源码的人。
解决问题不厉害,提出问题才是最屌的,因为当一个问题提出来的时候,它就已经被解决了。
带着质疑的眼光看代码,带着求真的态度去探索,与君共勉之。

文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


