
词法分析器
一、 目标和要求
首先本次实验分为三个小题分别为:C语言词法分析器、四则运算文法、解释器。因此以下一 ~ 九部分是C语言词法分析器的实验内容,十 ~ 十三部分是四则运算及其解释器的实验内容。
1.第一小题:
明确目标:
按照已经掌握的C语言的词法规范,编写能够按照C语言规范识别每个词法符号的分析器。从一个文本文件(典型地,就是C语言的源程序文件)中读入字符流,经过识别之后逐个输出词法符号(只需原样输出识别到的词法符号,无需考虑语法属性)。
几个要求:
(1)假定该语言有:
预处理指令:以#开头。
字符常量:单撇号作为界标;
字符串常量:双撇号作为界标;
数值型常量:数字开头,如016、0x8b、1.0f、3L都是,这里只选择整数;
标识符:非数字开头的下划线字母数字串(包括保留字);
运算符:有单字符的,也有多字符的如++、+=、&&=、sizeof等。
分隔符:逗号,分号,括号,花括弧,冒号(定义标号时使用);
(2)至少要有一个空白符将相邻的标识符、数值型常量和关键字隔开,但不能用空白符将符号中的相邻字符分开。
(3)注释是以符号/*开始,并以*/的第一次出现作为结束,或者以//开头。
(4)需要在输出结果前说明该符号的词法属性。例如:预定义:#include<stdio.h>
2.第二小题:
明确目标:
构造一个能够实现四则运算的文法。
几个要求:
对文法的符号、规则、特性以及语言给出准确解释。
3.第三小题:
明确目标:
根据四则运算文法构造编译器。
几个要求:
能够按照文法规则,逐行解释执行输入内容。
二、数据模型
|
单词符号 |
类型编码 |
助记符 |
单词符号 |
类型编码 |
助记符 |
|
标识符 |
1 |
$SYMBOL |
字符常量 |
2 |
$CHARA |
|
字符串常量 |
3 |
$STRING |
数值型常量 |
4 |
$NUMER
|
|
Int |
5 |
$INT |
If |
6 |
$IF |
|
Else |
7 |
$ELSE |
While |
8 |
$WHILE |
|
For |
9 |
$FOR |
Read |
10 |
$READ |
|
Write |
11 |
$WRITE |
+ |
12 |
$ADD |
|
- |
13 |
$SUB |
* |
14 |
$MUL |
|
/ |
15 |
$DIV |
< |
16 |
$L |
|
++ |
17 |
$INC |
-- |
18 |
$DEC |
|
<= |
19 |
$LE |
> |
20 |
$G |
|
>= |
21 |
$GE |
!= |
22 |
#NE |
|
== |
23 |
#E |
= |
24 |
#ASSIGN |
|
( |
25 |
#LPAR |
) |
26 |
#RPAR |
|
, |
27 |
#COM |
; |
28 |
#SEM |
表1 数据模型图
三、描述输出
对于程序段 for(k=0; k<=100; ++k)将产生下面的结果。
|
步骤 |
输出 |
含义 |
|
1 |
9, ’for’ |
标识符for |
|
2 |
25, ‘(‘ |
分隔符( |
|
3 |
1, ’k’ |
标识符k |
|
4 |
24, ’=’ |
运算符= |
|
5 |
4, ‘0’ |
数值型常量 |
|
6 |
28, ’;’ |
分隔符; |
|
7 |
1, ’k’ |
标识符k |
|
8 |
19, ’<=’ |
运算符<= |
|
9 |
4, ‘100’ |
数值型常量 |
|
10 |
28, ’;’ |
分隔符; |
|
11 |
17, ’++’ |
运算符++ |
|
12 |
1, ’k’ |
标识符k |
|
13 |
26, ‘)’ |
分隔符) |
表2 输出描述
四、算法

图1 状态转换图
五、算法细化

图2 状态转换图细化
六、流程图、伪代码

图3 流程图
七、编程
1、预定义与头文件
#include<stdio.h>
#include<ctype.h> //包含isspace函数 ,isalnum()是否字母或数字,isalpha()是否字母
//预处理是以>作为结束,字符是以'作为结束,字符串是以"作为结束,
//数值型常量只能根据当前字符的下一个字符是不是数字判断是否结束,标识符也是根据下一个字符判断。所以要记录下一个字符。
2、全局变量
int current_ch, next_ch,k=0;
int flag = 0;
char word[1024];
FILE *fp;
3、函数原型
//读下一个字符
void read_next_char();
//预处理指令:
void get_preprocessing_line();
//提取字符型常量:'
void get_char_const();
//提取字符串常量
void get_string_const();
//提取数值型常量,读取文本只有整数:
void get_num_const();
//提取标识符:
void get_identifier();
//提取运算符
void get_operator();
//提取分隔符
void get_seperator();
//词法分析部分的基本流程
int lexical_analyzer(FILE * input_file)
int main()
{
fp = fopen("test.txt","r");
if(fp == NULL)
{
printf("无法找到文件n");
return 0;
}
current_ch = fgetc(fp);//当前字符
lexical_analyzer(fp);
return 0;
}
完整代码见附录。
八、测试
集成测试:测试过程中出现了很多问题,最主要的一个就是对next_ch定义不明确。比如预处理指令判断是否current_ch=’>’结束,字符是判断current_ch是否等于单引号和双引号结束。而数值型常量不同,必须判断next_ch是否为数字,标识符也是同样的判断next_ch。所以我添加了一个flag进行判断。

图4 测试文件

图5 输出示例
九、总结
整体来说,本次实验的难度不大,实验过程并不涉及语法分析,只是对C语言简单的词法分析。题目一给出自然想到的就是使用多个判断条件,判断出究竟是保留字、变量、常量、运算符、分隔符、头文件和预定义还是注释。其次就是对输入流字符的处理,我们使用一个字符型数组word来保存。使用flag来判断current_ch是字符型还是数值型。我们使用C语言面向过程的编程方式进行模块化的编程,结构比较清晰。
经过参与这次词法分析的实验,我们对C语言的词法有了更进一步的理解。以及对编程语言的此法构成有了进一步的了解。知道了一些编译器的基本工作方式。相信在接下来的学习中我们会对计算机编译原理有更深层次的理解。
四则运算
十、四则运算文法
四则运算属于2型文法,所以制定以下文法规则:
运算符→+-*/
整数→[1-9][0-9]* | 0
浮点数→整数.[0-9]*
数→整数 | 浮点数
算式→数 | 算式 运算符 数
用相应符号表示:
算式:S,运算符:P,整数:N,浮点数:F,数:D
P→+-*/
N→[1-9][0-9]* | 0
F→N.[0-9]*
D→N | F
S→D | S P D
十一、解释器
解释器的制作需要借助lex和Yacc两个工具来完成,在DEV C++环境下运行。
(1)先使用lex和Yacc的编程规则编写好两个文件:

图6 生成词法和语法解释器的两个文件
(2)然后进入两个文件的所在目录命令行窗口按顺序输入以下命令:
$env:Path += ";C:usrlocalwbin"
flex gr1.txt
bison -y -d gr2.txt
(3)最后将生成的两个.c文件添加到同一项目中运行即可。
词法文件编码:

图7词法分析
文法文件编码:

图8 语法分析
十二、测试
四则运算可以正常执行:

图9 运算测试
以下为一些极端测试:
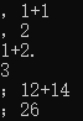
![]()


图10 极端测试
根据以上一些极端测试,可以看出,大部分输入错误该程序都可以进行适当的处理。一些特出错误,程序识别不出来的数据,会直接结束运行。对于大数相乘程序会用浮点数的形式给出结果,并不能算出精确值,最大可精确到小数点后5位。所以可以看出功能还是比较局限的。
十三、总结
在这次试验中我感到lex和Yacc这两个工具的强大,它们可以帮助我们快速生成非常全面解释器,使我们的工作转移到词法和语法分析上。相信在接下来的学习中我们会对计算机编译原理有更深层次的理解。
附录
#include<stdio.h>
#include<ctype.h> //包含isspace函数 ,isalnum()是否字母或数字,isalpha()是否字母
//预处理是以>作为结束,字符是以'作为结束,字符串是以"作为结束,
//数值型常量只能根据当前字符的下一个字符是不是数字判断是否结束,标识符也是根据下一个字符判断。所以要记录下一个字符。
int current_ch, next_ch,k=0;
int flag = 0;
char word[1024];
FILE *fp;
//读下一个字符
void read_next_char()
{
current_ch = fgetc(fp);
}
//预处理指令:
void get_preprocessing_line()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] == '>') //碰到>跳出循环
{
printf("预处理指令:");
break;
}
}
}
//提取字符型常量:'
void get_char_const()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] == ''') //碰到'跳出循环
{
printf("字符型常量:");
break;
}
}
}
//提取字符串常量
void get_string_const()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] == '"') //碰到"跳出循环
{
printf("字符串常量:");
break;
}
}
}
//提取数值型常量,读取文本只有整数:
void get_num_const()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(word[k-1] - '0' < 0 || word[k-1] - '0' > 9) //碰到非数字跳出循环 ,要把char型word转为int型数字
{
next_ch = word[k-1]; //记录最后的字符
word[k-1] = '�';
printf("数值型常量:");
break;
}
}
}
//提取标识符:
void get_identifier()
{
k = 1;
while(1)
{
word[k++]=fgetc(fp);
if(!(isalnum(word[k-1]) || word[k-1] == '_')) //碰到非字母或数字或下划线跳出循环
{
next_ch = word[k-1]; //记录最后的字符
word[k-1] = '�';
printf("标识符:");
break;
}
}
}
//提取运算符
void get_operator()
{
word[1] = next_ch;
printf("多字符运算符:");
}
//提取分隔符
void get_seperator()
{
printf("分隔符:");
}
//词法分析部分的基本流程
int lexical_analyzer(FILE * input_file)
{
int i;
int ch;
while(isspace(current_ch)) read_next_char();//碰到空格,当前word结束
while((ch = current_ch) != EOF)
{
word[0] = ch;
if(ch == '#') get_preprocessing_line();//预处理指令:
else if(ch== ''') get_char_const();//提取字符常量:'
else if(ch=='"') get_string_const();//提取字符串常量
else if(ch>='0'&&ch<='9') {get_num_const();current_ch = next_ch;flag = 1;}//提取数值型常量:
else if(ch=='_' || isalpha(ch)) {get_identifier();current_ch = next_ch;flag = 1;}//提取标识符下划线或字母开头:isalpha()判断字符变量c是否为字母
else if(ch == (int)'+' || ch == (int)'-' || ch == (int)'*' || ch == (int)'/' || ch == (int)'<' || ch == (int)'>' || ch == (int)'!' || ch == (int)'=') //提取运算符
{
next_ch = fgetc(fp);
if(next_ch != '+' && next_ch != '-' && next_ch != '=') //如果下一个字符不是+-=,那么是单字符运算符,否则是多字符运算符
{printf("单字符运算符") ;current_ch = next_ch;flag = 1;}
else
{get_operator();}
}
else if(ch == (int)'(' || ch == (int)')' || ch == (int)',' || ch == (int)';' || ch == (int)'{' || ch == (int)'}') get_seperator();//提取分隔符
else { printf("Unknown syntactics:%c(0X%X)n",ch,ch); return 1; }
printf("%sn", word);
for(i = 0;i < k;i++) //word置空
{
word[i] = '�';
}
do{
if(flag==0)
read_next_char();
flag=0;
}while(isspace(current_ch));
}
}
int main()
{
fp = fopen("test.txt","r");
if(fp == NULL)
{
printf("无法找到文件n");
return 0;
}
current_ch = fgetc(fp);//当前字符
lexical_analyzer(fp);
return 0;
}
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


