
配置Redis哨兵集群时日志显示+sdown slave的问题
一、配置及其环境描述(问题产生的原因是因为Redis复制中主节点对从节点的ip配置错误,从而导致哨兵无法识别从节点,进而无法进行故障转移)
1.操作系统:Linux
虚拟机:VMware Workstation 16 Pro 、WSL
Redis主从复制配置为在VM虚拟机上设置一台master,WSL虚拟机上设置两台slave。
Redis哨兵配置为在WSL上设置三台哨兵。
注:虚拟机一共只开启了两台,分别是VM和WSL。在WSL上我分别在两个端口部署了redis-server,以达到两个slave的目的。然后在WSL上我又在三个端口上部署了三个哨兵,用于在监视VM上部署的master。
2.配置的哨兵集群想达成如下效果:
当我使用shutdown命令关闭部署在VM上的master时,哨兵能够即时检测到master已经宕机,并进行投票选举选出新的master。
3.master的内网ip及端口为:192.xxx.xxx.xxx:6379,两个slave的内网ip及端口为:172.xxx.xxx.xxx:6380与172.xxx.xxx.xxx:6381
二、问题复现
启动一主二从,并启动三台哨兵。手动使master宕机,按照理想状态得到的结果应该是哨兵从剩下的两个slave中选取一个成为新的master,但是剩下的两台slave只是在原地等待旧master的回归,并未有新的master产生。
三、分析并解决问题
1.1)翻阅刚启动哨兵时候的哨兵日志,发现如下内容

"+sdown slave",说明一件事,就是哨兵无法与我们的两个从机取得联系(哨兵认为slave主观下线)。那么也很容易就明白了,在之后的投票选出新master的过程中,也无法在两个slave中选出。同时,我们还注意到一件事,从节点的ip竟然是以192开头的,这不对劲,因为从节点的ip应该以172开头。
2)启动Redis复制的一主二从,通过在master上设置键值对,并且在两个从机上取得了对应的键值对可以验证出,主从架构是搭建成功的。然后在master上使用命令"info replication"查询主从机联机状态如下图
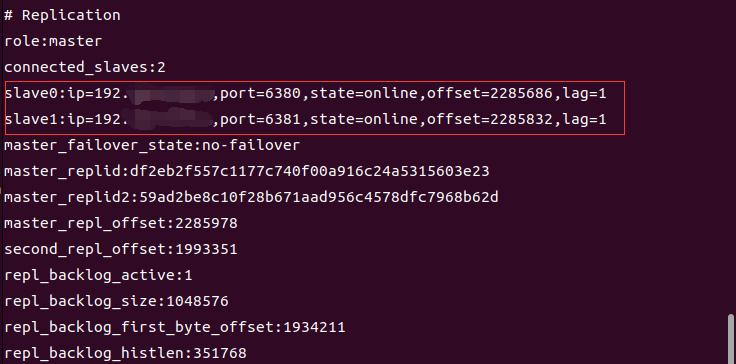
从图中看出,两台slave是成功连到了master的。但是,slave的ip开头竟然是192而不是172,说明,master识别从机的ip时,应该出现了问题。
3)那么解决问题就应该从master正确识别slave的ip地址入手了。在Redis配置文件中可以配置配置项"slave-announce-ip 从机ip地址",slave-announce-ip 用于指定从节点在复制(Replication)过程中向主节点汇报的 IP 地址。通过在从节点的Redis配置文件中配置该配置项,我们可以使得master正确的反映出slave的ip地址。在经过上述配置后,我们再在master中使用"info replication"查询主从机联机状态时,发现slave的ip地址显示正确,此时再去哨兵的日志文件中检查,发现,哨兵成功的联系到了两个slave。
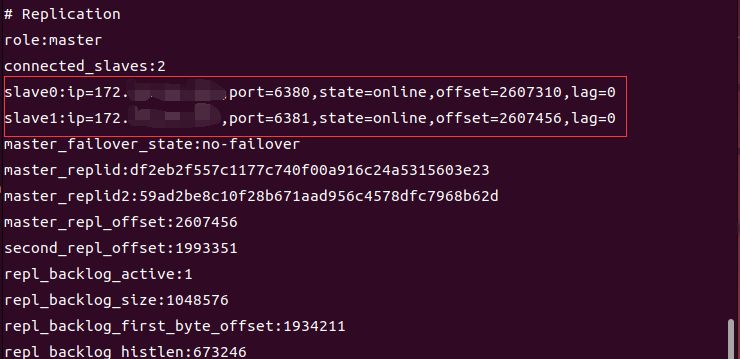
注:哨兵成功联系到slave的哨兵日志显示应该是下面的截图所示的内容

这里的"+slave slave"表示哨兵成功与slave的IP以172开头,端口为6381的slave联系成功。
4)再次使master宕机,发现哨兵成功的选举出了新的master,并变更了相应的Redis配置(使得旧的master成为新的master的slave,并使得原本效忠于旧master的slave重新效忠于新的master)
2.1)因为哨兵有在启动的时候会将一些主从机以及自己的基本信息写进哨兵配置文件的操作,所以,上述流程的分析中还可以加上分析哨兵配置文件的流程。
2)具体问题具体分析,但是分析流程可以相同
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


