

作者:小傅哥
博客:https://bugstack.cn
一、前言
我们不一样,就你没对象! 对,你是面向过程编程的!
我说的,绝大多数码农没日没夜被需求憋着肝出来的代码,无论有多么的吭哧瘪肚,都不可能有重构,只有重新写。为什么?因为重新写所花的时间成本,远比重构一份已经烂成团的代码,要节省时间。但谁又不敢保证重写完的代码,就比之前能好多少,况且还要承担着重写后的代码事故风险和几乎体现不出来的业务价值!
虽然代码是给机器运行的,但同样也是给人看的,并且随着每次需求的迭代、变更、升级,都需要研发人员对同一份代码进行多次开发和上线,那么这里就会涉及到可维护、易扩展、好交接的特点。
而那些不合理分层实现代码逻辑、不写代码注释、不按规范提交、不做格式化、命名随意甚至把 queryBatch 写成 queryBitch 的,都会造成后续代码没法重构的问题。那么接下来我们就分别介绍下,开发好能重构的代码,都要怎么干!
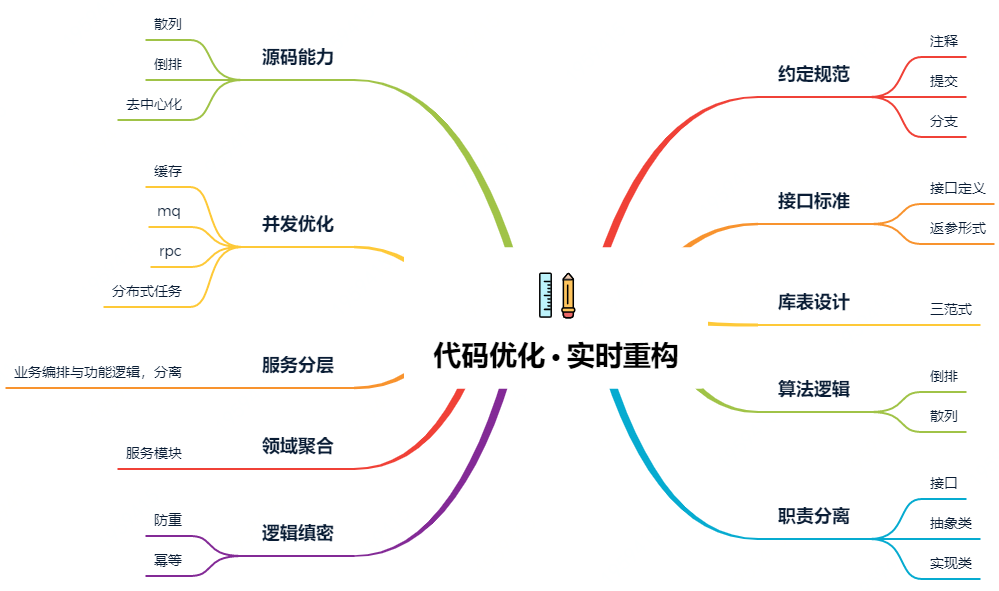
二、代码优化
1. 约定规范
# 提交:主要 type
feat: 增加新功能
fix: 修复bug
# 提交:特殊 type
docs: 只改动了文档相关的内容
style: 不影响代码含义的改动,例如去掉空格、改变缩进、增删分号
build: 构造工具的或者外部依赖的改动,例如webpack,npm
refactor: 代码重构时使用
revert: 执行git revert打印的message
# 提交:暂不使用type
test: 添加测试或者修改现有测试
perf: 提高性能的改动
ci: 与CI(持续集成服务)有关的改动
chore: 不修改src或者test的其余修改,例如构建过程或辅助工具的变动
# 注释:类注释配置
/**
* @description:
* @author: ${USER}
* @date: ${DATE}
*/
- 分支:开发前提前约定好拉分支的规范,比如
日期_用户_用途,210905_xfg_updateRuleLogic - 提交:
作者,type: desc如:小傅哥,fix:更新规则逻辑问题参考Commit message 规范 - 注释:包括类注释、方法注释、属性注释,在 IDEA 中可以设置类注释的头信息
Editor -> File and Code Templates -> File Header推荐下载安装 IDEA P3C 插件Alibaba Java Coding Guidelines,统一标准化编码方式。
2. 接口标准
在编写 RPC 接口的时候,返回的结果中一定要包含明确的Code码和Info描述,否则使用方很难知道这个接口是否调用成功还是异常,以及是什么情况的异常。
定义 Result
public class Result implements java.io.Serializable {
private static final long serialVersionUID = 752386055478765987L;
/** 返回结果码 */
private String code;
/** 返回结果信息 */
private String info;
public Result() {
}
public Result(String code, String info) {
this.code = code;
this.info = info;
}
public static Result buildSuccessResult() {
Result result = new Result();
result.setCode(Constants.ResponseCode.SUCCESS.getCode());
result.setInfo(Constants.ResponseCode.SUCCESS.getInfo());
return result;
}
// ...get/set
}
返回结果包装:继承
public class RuleResult extends Result {
private String ruleId;
private String ruleDesc;
public RuleResult(String code, String info) {
super(code, info);
}
// ...get/set
}
// 使用
public RuleResult execRule(DecisionMatter request) {
return new RuleResult(Constants.ResponseCode.SUCCESS.getCode(), Constants.ResponseCode.SUCCESS.getInfo());
}
返回结果包装:泛型
public class ResultData<T> implements Serializable {
private Result result;
private T data;
public ResultData(Result result, T data) {
this.result = result;
this.data = data;
}
// ...get/set
}
// 使用
public ResultData<Rule> execRule(DecisionMatter request) {
return new ResultData<Rule>(Result.buildSuccessResult(), new Rule());
}
- 两种接口返回结果的包装定义,都可以规范返回结果。在这样的方式包装后,使用方就可以用统一的方式来判断
Code码并做出相应的处理。
3. 库表设计
三范式:是数据库的规范化的内容,所谓的数据库三范式通俗的讲就是设计数据库表所应该遵守的一套规范,如果不遵守就会造成设计的数据库不规范,出现数据库字段冗余,数据的查询,插入等操作等问题。
数据库不仅仅只有三范式(1NF/2NF/3NF),还有BCNF、4NF、5NF…,不过在实际的数据库设计时,遵守前三个范式就足够了。再向下就会造成设计的数据库产生过多不必要的约束。
0NF

- 第零范式是指没有使用任何范式,数据存放冗余大量表字段,而且这样的表结构非常难以维护。
1NF
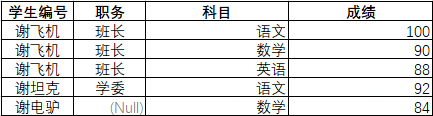
- 第一范式是在第零范式冗余字段上的改进,把重复字段抽离出来,设计成一个冗余数据较少便于存储和读取的表结构。
- 同时在第一范式中也指出,表中的所有字段都应该是原子的、不可再分割的,例如:你不能把公司雇员表的部门名称和职责存放到一个字段。需要确保每列保持原子性
2NF

- 满足1NF后,要求表中的列,都必须依赖主键,确保每个列都和主键列之间联系,而不能间接联系,也就是一个表只能描述一件事情。需要确保表中的每列都和主键相关。
3NF
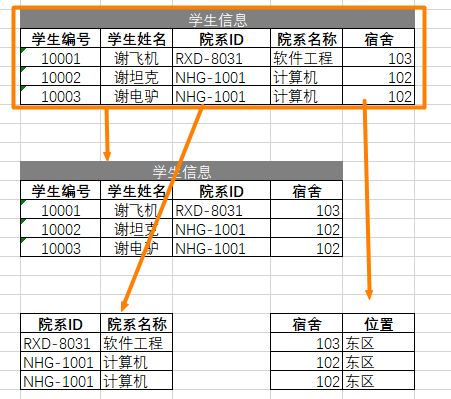
- 不能存在依赖关系,学号、姓名,到院系,院系到宿舍,需要确保每列都和主键列直接相关,而不是间接相关。
反三范式
三大范式是设计数据库表结构的规则约束,但是在实际开发中允许局部变通:
- 有时候为了便于查询,会在如订单表冗余上当时用户的快照信息,比如用户下单时候的一些设置信息。
- 单列列表数据汇总到总表中一个数量值,便于查询的时候可以避免列表汇总操作。
- 可以在设计表的时候冗余一些字段,避免因业务发展情况多变,考虑不周导致该表繁琐的问题。
4. 算法逻辑
通常在我们实际的业务功能逻辑开发中,为了能满足一些高并发的场景,是不可能对数据库表上锁扣减库存、也不能直接for循环大量轮训操作的,通常需要考虑
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


