
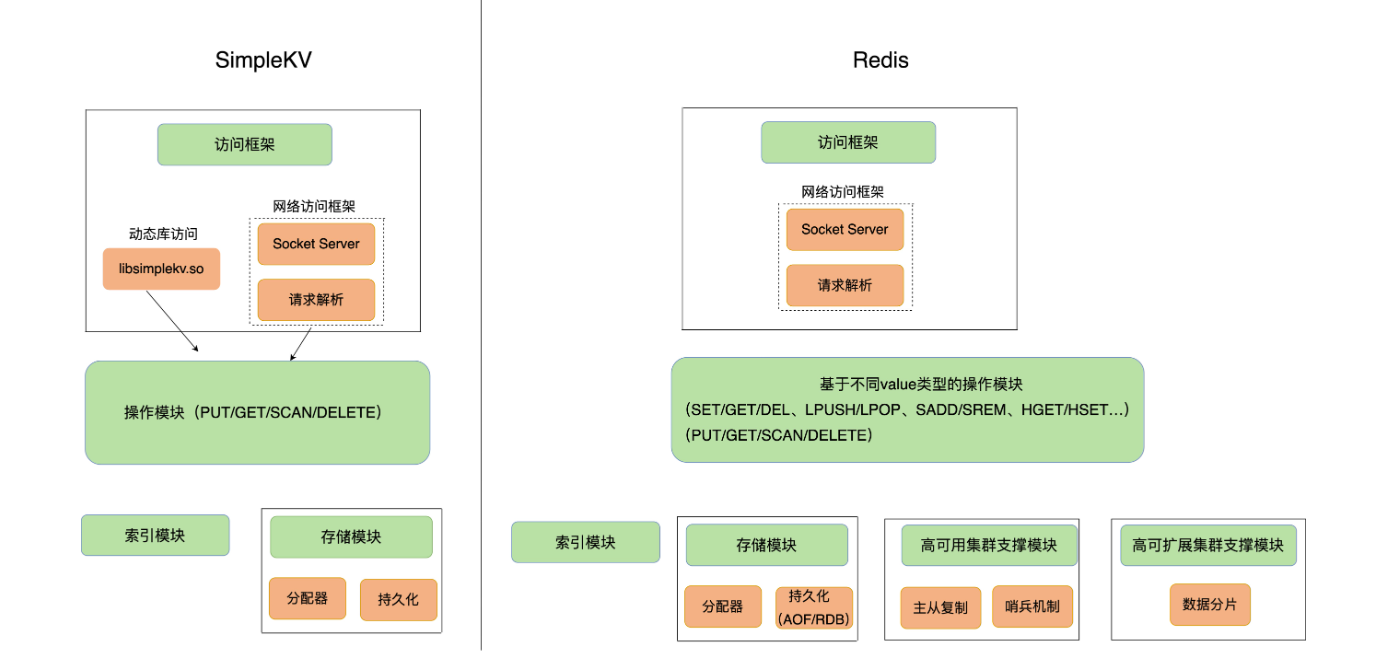
分为访问模块,操作模块,索引模块,存储模块
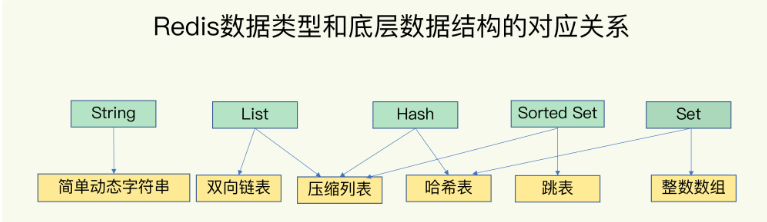
除了String类型,其他类型都是一个键对应一个集合,键值对的存储结构采用哈希表
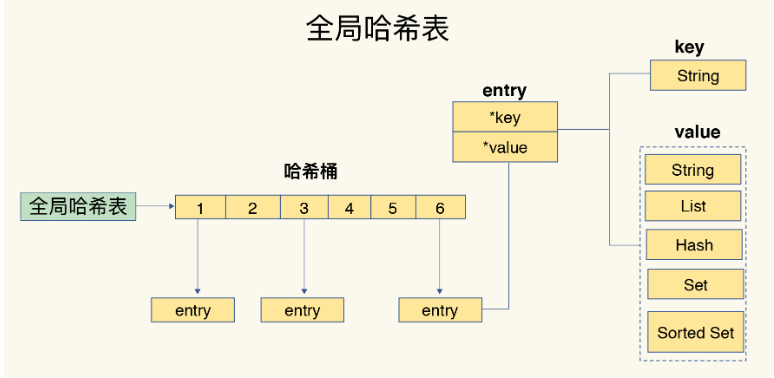
哈希表由多个哈希桶组成,桶中存储entry元素,存储key和value的地址
但是当hash冲突元素过多会导致查询效率变慢,所以引入rehash操作
采用两个全局hash表,但是从一个哈希表复制到另一个哈希表肯定会造成线程阻塞,所以使用渐进式哈希 :分摊到多次拷贝
接受第一次请求就拷贝第一个索引的entry元素,下一次再拷贝第二个,以此类推
对于集合类型的底层数据结构:双向链表,压缩列表,哈希表,跳表,整数数组
压缩列表:

跳表:
增加多级索引,通过索引位置的跳转,快速找到元素 (时间复杂度为logn)
不同操作所对应的时间复杂度也不同
对于单个元素的操作一般为O(1)
范围操作一般为O(n),一般使用scan来代替
统计操作,因为底层的数据结构中有元素个数的统计,所以时间复杂度为O(1)
单线程(多路复用)不会阻塞在一个客户端的请求连接上,因为在请求过程中有可能会因为监听到有连接请求但是迟迟没有建立起连接或者建立起连接数据一直没有到达都会发生阻塞,所以采用多路复用非阻塞结构,允许在内核中存在多个监听套接字和已连接套接字,采用**事件回调机制**,当有事件到来,进入一个队列,redis处理队列中的请求,针对每个事件都有相应的回调函数
在内存中操作数据
高效的底层数据结构
mysql数据库是写前日志,redis是写后日志,所以不会阻塞当前的写操作
但是有两个风险:1.redis宕机,有丢失一段时间内数据的可能 2.因为在主线程中进行aof操作,有可能会阻塞下一个操作
但是随着时间的推移,aof文件越来越大怎么办,数据恢复效率肯定会降低?
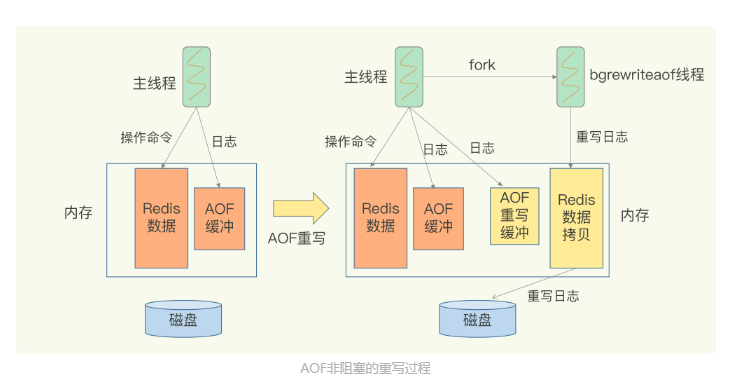
引入aof重写
多变一,把多条对同一个键的旧操作合并成最新的一条操作
但是aof重写会阻塞主线程吗?
不会的,和aof追加写入不一样,采用的不是主线程,是由主线程fork出的子线程bgrewriteaof线程重写,子线程里也有父线程的内存的最新数据(共享页表)
在重写过程中,客户端的操作也会由主线程写入当前aof的缓冲区和重写aof的缓冲区,保证宕机也是数据齐全的,重写之后数据也是最新的
把某一时刻的状态记录到磁盘上
两个命令生成RDB:1. save,使用主线程,会阻塞主线程 2. bgsave,使用子线程,避免了阻塞问题(但是主线程只可读,不可写)
那么在记录到磁盘的时间段内,怎么保证数据不被修改?
使用bgsave+写时复制:主线程修改处于RDB中的数据时,需要生成一个副本,子进程把副本数据写进RDB文件
虽然RDB恢复速度快,但是进行持久化的时间间隔却不好把控,所以Redis4.0推出AOF和RDB结合的方法:在两次RDB持久化期间,期间发生的改动由AOF记录,这样恢复数据即快,又避免了频繁fork子线程对主线程的阻塞。
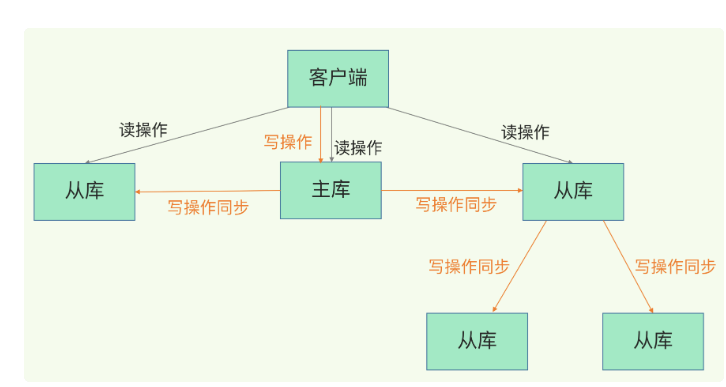
主从同步过程
第一步:从库发送同步命令,包括主库ID和复制进度offset
第二步:主库生成RDB文件,发送RDB文件,全量复制,发送包含两个参数:主库ID和复制进度offset
第三步:主库把第二步过程中收到的命令发送到从库
那么当从库增多,主库fork子线程生产RDB的压力必然会增大,所以采用主-从-从架构,进行从库之间的级联,取一些从库帮主库分担压力
那么网络断了怎么办?
redis2.8之前是再进行一次全量复制
之后是进行增量复制
在redis中存在一个环形缓冲区,记录主库写的进度和从库复制的进度,由两个参数确定,master-repl-offset和slave-repl-offset
网络断开再重连之后,从库根据offset位置进行增量复制就好
但是如果从库复制进度赶不上主库写的进度,缓冲区就会被覆盖,就会触发从库的全量复制,所以一般增大缓冲区为2倍
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


