
本机环境规划及说明:
① k8s环境规划:
podSubnet(pod网段) 10.244.0.0/16
serviceSubnet(service网段): 10.10.0.0/16
② 主机和ip规划 (云主机)一台Master和一台node,后面资源不够时再添加
操作系统:Centos7.6
配置: 4核8G、100G数据盘(Master 4C8G,node 2核4G,前期可以练习使用,后期可以再进行配置升级)
开启虚拟机的虚拟化:
| 主机名 | IP | 角色 |
|---|---|---|
| k8s-master1 | 192.168.1.56 | Master1 |
| k8s-node1 | 192.168.1.78 | node1 |
| ... | ... | .... |
一、初始化实验环境
1.1 配置静态ip
1.2 修改yum源
1.2.1 备份原来的 yum 源mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
1.2.2 下载阿里的 yum 源wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
1.2.3 配置安装 k8s 需要的 yum 源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
EOF
1.2.4 清理 yum 缓存yum clean all
1.2.5 生成新的 yum 缓存yum makecache fast
1.2.6 更新 yum 源yum -y update
1.2.7 安装软件包yum -y install wget net-tools nfs-utils lrzsz gcc gcc-c++ make cmake libxml2-devel openssl-devel curl curl-devel unzip sudo ntp libaio-devel wget vim ncurses-devel autoconf automake zlib-devel python-devel epel-release openssh-server socat ipvsadm conntrack ntpdate yum-utils device-mapper-persistent-data lvm2
1.2.8 添加新的软件源yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
1.2.9 清理 yum 缓存yum clean all
1.2.10 生成新的 yum 缓存yum makecache fast
1.3 配置防火墙
关闭 firewalld 防火墙,在 k8s 各个节点都要关闭,centos7 系统默认使用的是 firewalld 防火墙,停止
firewalld 防火墙,并禁用这个服务。
在 k8s 的各个节点操作如下命令。systemctl stop firewalld && systemctl disable firewalld
1.4 时间同步chrony
- 在 k8s 的各个节点使用yum安装chrony时间服务
yum install -y chrony - 编辑/etc/chrony.conf文件修改啊时间同步地址,可以百度搜索一个,也可以直接设置成ntp1.aliyum.com同步阿里的时间服务器地址
- 把chrony服务设置为开机自启动并启动服务
systemctl enable chronyd && systemctl start chronyd
1.5 关闭 selinux
k8s 的各个节点都要关闭 selinux。
关闭 selinux,设置永久关闭,这样重启机器 selinux 也处于关闭状态可用下面方式修改:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
上面文件修改之后,需要重启虚拟机,如果测试环境可以用如下命令强制重启:
reboot -f
注:生产环境不要 reboot -f,要正常关机重启
查看 selinux 是否修改成功
重启之后登录到机器上用如下命令:getenforce
显示 Disabled 说明 selinux 已经处于关闭状态
1.6 关闭交换分区
在 k8s 的各个节点操作如下命令。swapoff -a
临时禁用sed -i 's/.*swap.*/#&/' /etc/fstab
#永久禁用,打开/etc/fstab 注释掉 swap 那一行。
1.7 修改内核参数
在 k8s 的各个节点操作如步骤。
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
注:sysctl --system 这个会加载所有的 sysctl 配置
此功能如果不开启,后面在kubeadm初始化k8s时就会报错:
就表示没有开启ip_forward,需要开启。
为什么要开启net.ipv4.ip_forward = 1参数?
net.ipv4.ip_forward是数据包转发:
出于安全考虑,Linux系统默认是禁止数据包转发的。所谓转发即当主机拥有多于一块的网卡时,其中一块收到数据包,根据数据包的目的ip地址将数据包发往本机另一块网卡,该网卡根据路由表继续发送数据包。这通常是路由器所要实现的功能。
要让Linux系统具有路由转发功能,需要配置一个Linux的内核参数net.ipv4.ip_forward。这个参数指定了Linux系统当前对路由转发功能的支持情况;其值为0时表示禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
1.8 修改主机名
在 192.168.1.56 上:hostnamectl set-hostname master1
在 192.168.1.79 上:hostnamectl set-hostname node1
1.9 配置 hosts 文件
K8s 各个节点 hosts 文件保持一致即可,可按如下方法修改:
在/etc/hosts 文件增加如下几行:
[root@k8s-master1 ~]# cat /etc/hosts
192.168.1.56 master1 k8s-master1
192.168.1.79 node1 k8s-node1
1.10 配置各个主机之间无密码登陆
配置 master1 到 node1 无密码登陆
在 master1 上操作
[root@k8s-master1 ~]# ssh-keygen #一直回车就可以
[root@k8s-master1 ~]# ssh-copy-id node1
#上面需要输入 yes 之后,输入密码,输入 node1 物理机密码即可
8 安装 docker
在 k8s 的各个节点都需要安装docker,安装方法按如下操作即可:
1.1 查看 docker 版本yum list docker-ce --showduplicates |sort -r
1.2 安装 docker
yum install -y docker-ce-19.03.7-3.el7
systemctl enable docker && systemctl start docker
#查看 docker 状态,如果状态是 active(running),说明 docker 是正常运行状态systemctl status docker
1.3 修改 docker 配置文件
cat > /etc/docker/daemon.json <<EOF
{
"registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker-cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com"],
"exec-opts":["native.cgroupdriver=systemd"], "log-driver":"json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver":"overlay2",
"storage-opts": [ "overlay2.override_kernel_check=true"
]
}
EOF
注:
"registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker.cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub-mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com"]
上面配置的是镜像加速器
如果有harbor镜像仓库可以按如下方法加一个字段,指定镜像仓库地址
cat > /etc/docker/daemon.json <<EOF
{
"insecure-registries":["192.168.0.56"],
"registry-mirrors":["https://rsbud4vc.mirror.aliyuncs.com","https://registry.docker- cn.com","https://docker.mirrors.ustc.edu.cn","https://dockerhub.azk8s.cn","http://hub- mirror.c.163.com","http://qtid6917.mirror.aliyuncs.com"],
"exec-opts":["native.cgroupdriver=systemd"], "log-driver":"json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver":"overlay2", "storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
"insecure-registries":["192.168.0.56"] #配置的是 harbor 私有镜像仓库地址
1.4 重启 docker 使配置生效systemctl daemon-reload && systemctl restart docker && systemctl status docker
1.5 开启机器的 bridge 模式
以下步骤在 k8s 各个节点都需要操作
#临时生效
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables echo 1 >/proc/sys/net/bridge/bridge-nf-call-ip6tables
#永久生效
echo """
vm.swappiness = 0
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
""" > /etc/sysctl.conf
sysctl -p
1.6 开启 ipvs
不开启 ipvs 将会使用 iptables,但是效率低,所以官网推荐需要开通 ipvs 内核,
在 k8s 的各个节点都需要开启
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack"
for kernel_module in ${ipvs_modules};
do
/sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1
if [ $? -eq 0 ]; then
/sbin/modprobe ${kernel_module}
fi
done
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules &&
bash /etc/sysconfig/modules/ipvs.modules &&
lsmod | grep ip_vs
显示如下,说明 ipvs 开启成功了: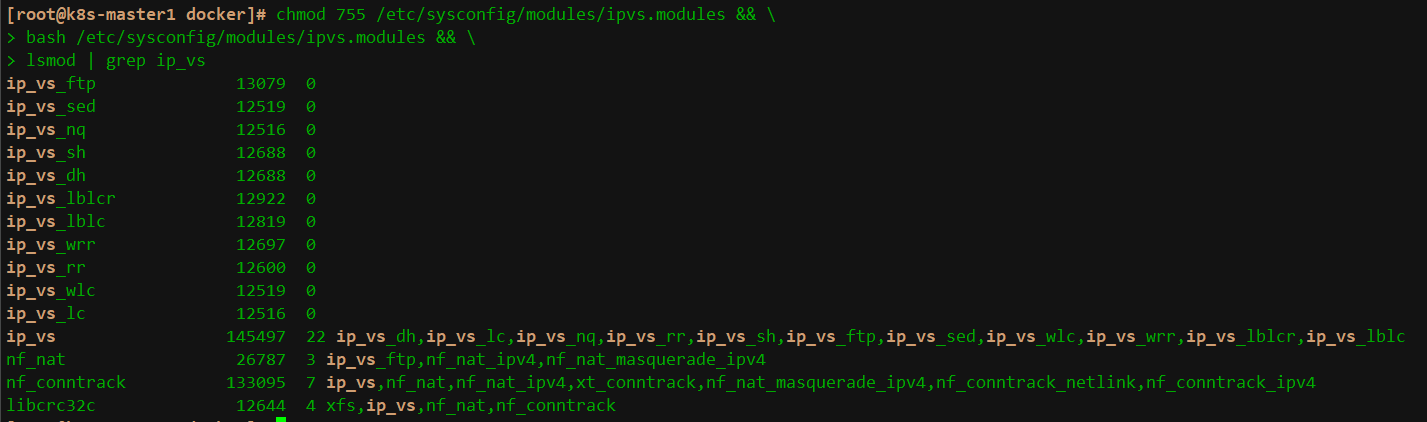
二、安装 kubernetes 高可用集群
2.1 安装kubeadm和kubelet
1.1 在 master1 和 node1 上安装 kubeadm 和 kubelet
yum install kubeadm-1.19.6 kubelet-1.19.6 kubectl-1.19.6 -y
systemctl enable kubelet
2.2 K8s集群初始化
在 k8s 的 master1 节点操作
kubeadm init --kubernetes-version=v1.19.6
--pod-network-cidr=10.244.0.0/16
--apiserver-advertise-address=192.168.1.56
--image-repository registry.aliyuncs.com/google_containers
注:
1)
--image-repository registry.aliyuncs.com/google_containers 是指定阿里云的镜像源,国内的镜像源访问速度会比较快,
--kubernetes-version=v1.19.6 是指定 k8s 版本,基于这个我们可以安装任何版本的 k8s。
2)
如果大家机器访问网络比较慢,可以在执行 kubeadm init --kubernetes-version=v1.19.6 --pod- network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.40.130 --image-repository registry.aliyuncs.com/google_containers
这串命令之前把 aliyun-kubernetes-master-1-19-6.tar.gz 上传到 k8s 的 master1 节点,
通过 docker load -i aliyun-kubernetes-master-1-19-6.tar.gz手动解压,把 aliyun-kubernetes-slave-1-19-6.tar.gz 上传到 k8s 的 node1 节点,
通过 docker load -i aliyun-kubernetes-slave-1-19-6.tar.gz 手动解压。
初始化命令执行成功之后显示如下内容,说明初始化成功了
[root@k8s-master1 ~]# kubeadm init --kubernetes-version=v1.19.6
--pod-network-cidr=10.244.0.0/16
--apiserver-advertise-address=192.168.1.56
--image-repository registry.aliyuncs.com/google_containers # 命令输出
W0829 15:12:17.476712 19429 configset.go:348] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.19.6
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [k8s-master1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.1.56]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [k8s-master1 localhost] and IPs [192.168.1.56 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [k8s-master1 localhost] and IPs [192.168.1.56 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 15.002119 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.19" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-master1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: njtz23.0rq9a629zab3rsf9
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.56:6443 --token njtz23.0rq9a629zab3rsf9
--discovery-token-ca-cert-hash sha256:f59119cf40b5470120d98a69506164328b5cfbc9bc973d71e9b187b58210a830
注:kubeadm join ... 这条命令需要记住,我们把 k8s 的 node1 节点加入到集群需要在这些节点节点输入这条命令,每次执行这个结果都是不一样的,大家记住自己执行的结果,在下面会用到
2.3 在 master1 节点授权,这样才能有权限操作 k8s 资源
mkdir -p $HOME/.kube
sudo cp -ifr /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
注: 我们下面执行 kubectl 的命令都是在 k8s 的 master1 节点操作
在 master1 节点执行kubectl get nodes
显示如下,master1 节点是 NotReady
NAME STATUS ROLES AGE VERSION
master1 NotReady master 103s v1.19.6
kubectl get pods -n kube-system
显示如下,可看到 cordns 是处于 pending 状态
NAME READY STATUS RESTARTS AGE
coredns-6d56c8448f-ccb8n 0/1 Pending 0 100s coredns-6d56c8448f-dpklb 0/1 Pending 0 100s
注意:上面可以看到 STATUS 状态是 NotReady,cordns 是 pending,是因为没有安装网络插件,需要安装 calico 或者 flannel,接下来我们安装 calico,在 master1 节点安装calico 网络插件:
2.4 安装 calico 网络插件
需要的镜像是 quay.io/calico/cni:v3.5.3 和 quay.io/calico/node:v3.5.3手动上传上面两个镜像的压缩包到 master1 和 node1 节点,在master1 和 node1 上通过 docker load -i 解压
docker load -i cni.tar.gz
docker load -i calico-node.tar.gz
注意:calico.yaml 里需要修改如下内容:
找到 IP_AUTODETECTION_METHOD 对应的 value 值:
- name: IP_AUTODETECTION_METHOD
value: "can-reach=192.168.1.56"
这个 ip 写你自己环境的 node1 节点的 ip,假如 node 节点有多个,那么只写一个 node 节点 ip 即可,所以大家只需要写 node1 的 ip 即可
应用yaml 文件:kubectl apply -f calico.yaml
2.6 查看 node 节点和coredns的pod 状态,在 master1 节点执行
kubectl get nodes
显示如下,看到 STATUS 是 Ready
NAME STATUS ROLES AGE VERSION
master1 Ready master 8m19s v1.19.6
kubectl get pods -n kube-system
看到 cordns 也是 running 状态,说明 master1 节点的calico 安装完成
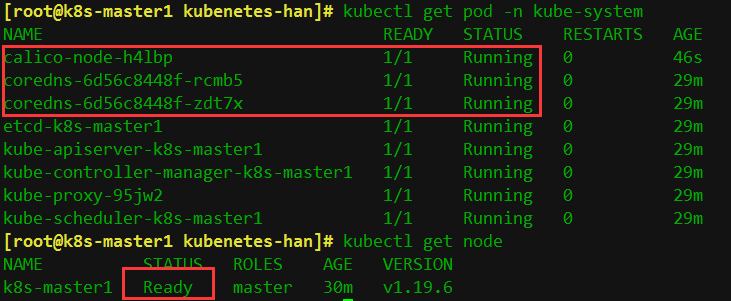
2.7 扩容添加node节点
把 node1 节点加入到 k8s 集群,在 node1 节点操作
注:下面的这个是把 node1 节点加入到 k8s 的一串命令,下面的这串命令就是初始化的时候生成的,每个人的都不一样
kubeadm join 192.168.1.56:6443 --token njtz23.0rq9a629zab3rsf9
--discovery-token-ca-cert-hash sha256:f59119cf40b5470120d98a69506164328b5cfbc9bc973d71e9b187b58210a830
上面命令执行之后,出现如下图所示,说明 node1 节点已经加入到 k8s 集群: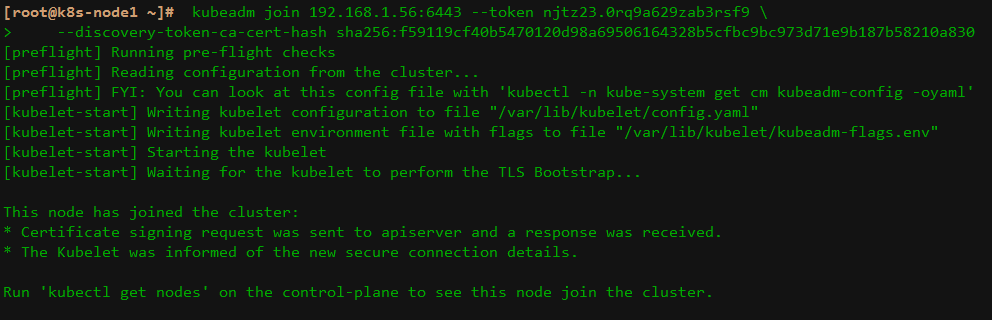
在 master1 节点查看集群节点状态
kubectl get nodes
显示如下: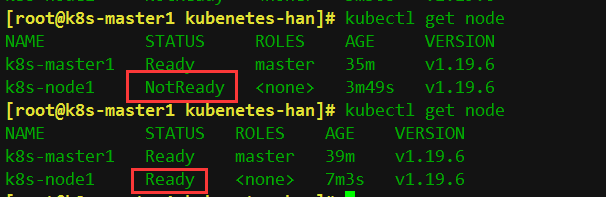
看到上面 STATUS 状态是 Ready,说明 node1 节点也加入到 k8s 集群了,通过以上就完成了 k8s 单master 节点高可用集群的搭建
kubectl get cs
显示如下:
看到 cotroller-manager 和 scheduler 是 Unhealthy,按如下方面解决:
vim /etc/kubernetes/manifests/kube-scheduler.yaml
修改如下内容:
把 --bind-address=127.0.0.1
变成 --bind-address=192.168.1.56 #注意:192.168.1.56 是 k8s 的 master1 节点 ip
把 httpGet:字段下的 host 25和39行
由 127.0.0.1
变成 192.168.1.56
把—-port=0 注释
编辑controller-manager的yaml文件
vim /etc/kubernetes/manifests/kube-controller-manager.yaml
把 --bind-address=127.0.0.1
变成 --bind-address=192.168.1.56
把—-port=0 注释
把 httpGet:字段下的 hosts
由 127.0.0.1
变成 192.168.1.56
修改之后在 k8s 各个节点执行
systemctl restart kubelet
kubectl get cs
显示如下:
```bash
[root@k8s-master1 kubenetes-han]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
可以查看一下端口是否监听了
ss -antulp | grep :10251
ss -antulp | grep :10252
可以看到相应的端口已经被物理机监听了
集群初始化完成,下面先测试一下
三、测试集群功能是否正常
Pod网络测试和代理测试
pod介绍下一篇文章会介绍,此处只是运行测试一下
1、运行busybox
使用docker run运行一个容器镜像,进去使用ping测试一下网络是否有问题。
docker run --rm -it busybox:1.28 sh
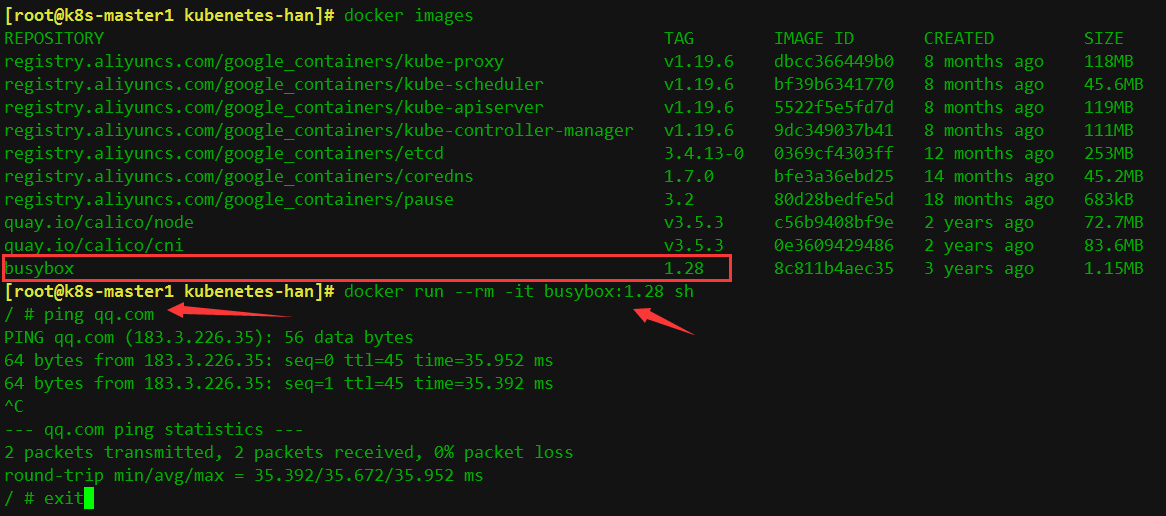
可以ping通外网则说明网络插件功能正常
2、测试一下kubelet是否正常代理
运行一个tomcat容器,编辑一个yaml文件(yaml语法要求严格,错一个空格都会报错,仔细)
vim tomcat.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
env: dev
spec:
containers:
- name: tomcat-pod-java
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
使用kubectl应用,使用自定义的yaml文件创建容器
[root@k8s-master1 kubenetes-han]# kubectl apply -f tomcat.yaml
pod/demo-pod created
[root@k8s-master1 kubenetes-han]# kubectl get pod
NAME READY STATUS RESTARTS AGE
demo-pod 1/1 Running 0 23s
再编辑一个用于创建tomcat的svc的yaml文件
```yaml
apiVersion: v1
kind: Service
metadata:
name: tomcat
spec:
type: NodePort
ports:
- port: 8080
nodePort: 30080
selector:
app: myapp
env: dev
应用该yaml文件创建svc,然后使用get svc获取
[root@k8s-master1 kubenetes-han]# kubectl apply -f tomcat-service.yaml
service/tomcat created
[root@k8s-master1 kubenetes-han]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5h56m
tomcat NodePort 10.99.224.78 <none> 8080:30080/TCP 20s
# 访问node节点的ip+30080(映射的端口)
[root@k8s-master1 kubenetes-han]# curl 192.168.1.79:30080
3、测试集群的dns是否可以正常工作
kubectl run busybox --image busybox:1.28 --restart=Never --rm -it busybox -- sh
nslookup kubernetes.default.svc.cluster.local
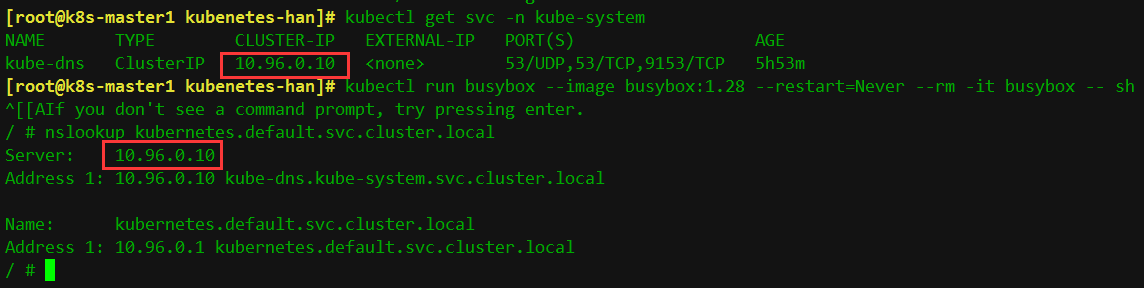
能正常解析则说明集群状态正常!
四、安装Dashboard可视化界面
1、安装dasboard
从本地上传镜像和yaml文件
把安装kubernetes-dashboard需要的镜像上传到工作节点node1上,手动导入,yaml放到master上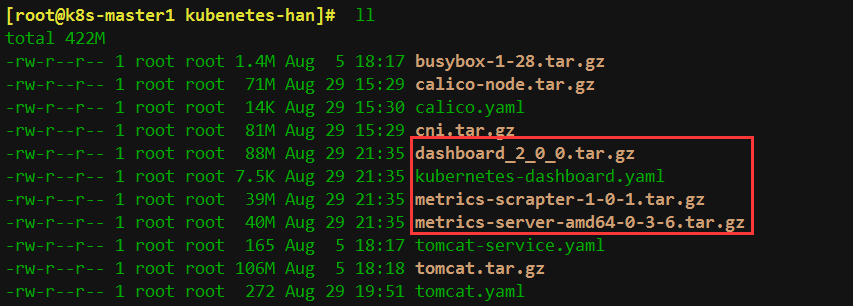
安装dashboard组件
在k8s-master1节点操作如下命令:
[root@k8s-master1 kubenetes-han]# kubectl apply -f kubernetes-dashboard.yaml
查看dashboard的状态
[root@xianchaomaster1 ~]# kubectl get pods -n kubernetes-dashboard
显示如下,说明dashboard安装成功了
[root@k8s-master1 kubenetes-han]# kubectl get pods -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-7445d59dfd-hwx59 1/1 Running 0 15s
kubernetes-dashboard-54f5b6dc4b-6mfxl 1/1 Running 0 15s
[root@k8s-master1 kubenetes-han]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.109.63.228 <none> 8000/TCP 30s
kubernetes-dashboard ClusterIP 10.101.169.211 <none> 443/TCP 30s
// 修改service type类型变成NodePort(后面的文章中会讲到)
[root@k8s-master1 kubenetes-han]# kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
再次查看,类型就被改为了NodePort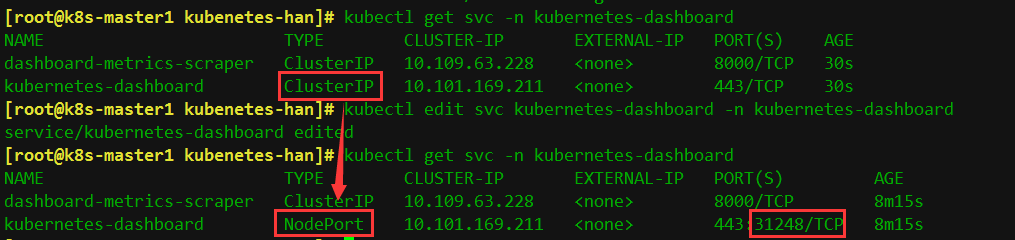
上面可看到service类型是NodePort,访问任何一个工作节点ip: 31248端口即可访问kubernetes dashboard,在浏览器(使用火狐浏览器)访问如下地址:
使用其他浏览器可能会被拦截打不开页面,访问https://node节点的ip:31248,会有安全风险提示,点击接受继续访问即可看到可看到出现了dashboard界面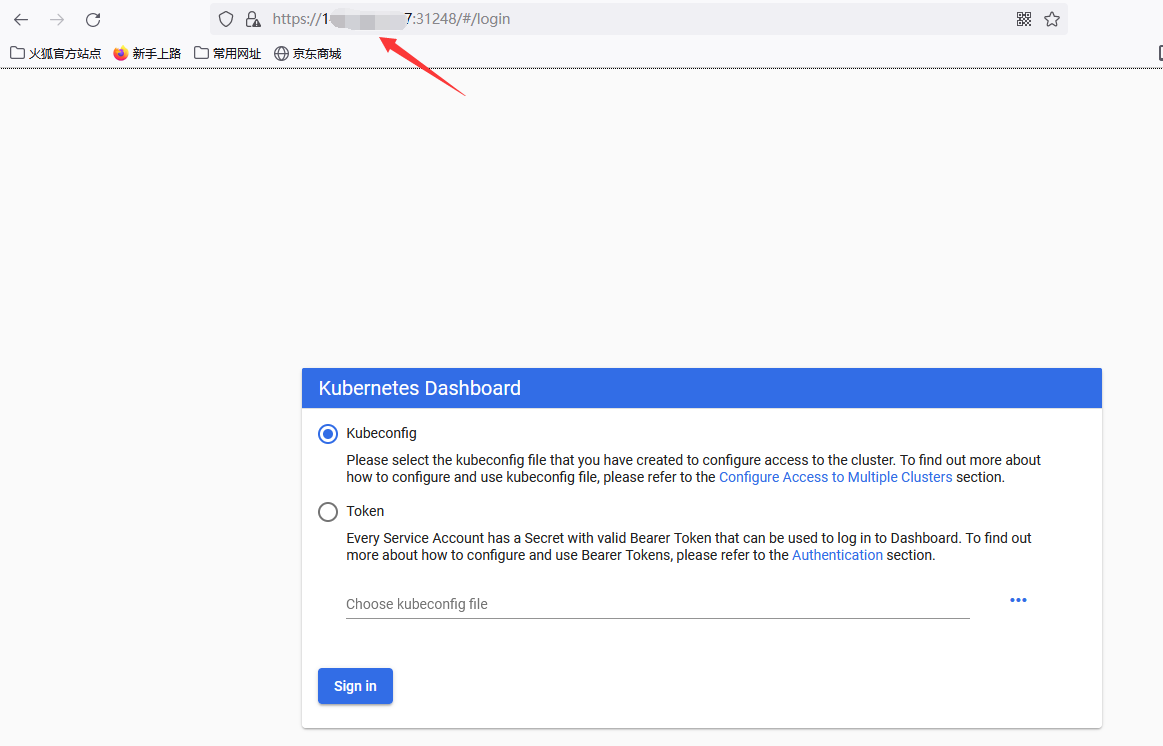
通过token令牌访问dashboard
通过Token登陆dashboard
创建管理员token,具有查看任何空间的权限,可以管理所有资源对象
[root@k8s-master1 kubenetes-han]# kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin --serviceaccount=kubernetes-dashboard:kubernetes-dashboard
clusterrolebinding.rbac.authorization.k8s.io/dashboard-cluster-admin created
使用get查看一下
[root@k8s-master1 kubenetes-han]# kubectl get secret -n kubernetes-dashboard
NAME TYPE DATA AGE
default-token-z7bkm kubernetes.io/service-account-token 3 23m
kubernetes-dashboard-certs Opaque 0 23m
kubernetes-dashboard-csrf Opaque 1 23m
kubernetes-dashboard-key-holder Opaque 2 23m
kubernetes-dashboard-token-2qqmr kubernetes.io/service-account-token 3 23m
找到对应的带有token的pod的name,使用以下命令查看
[root@k8s-master1 kubenetes-han]# kubectl describe secret kubernetes-dashboard-token-2qqmr -n kubernetes-dashboard
...
...
token: eyJhbGciOiJSUzI1NiIsImtpZCI6IjZBVVFxN01QSUF2a25BbDNOTEZGYTZyNWttVUppSGRyckh4blA5azd5ZU0ifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZC10b2tlbi0ycXFtciIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjEwYTI3N2M1LTY0MjYtNDBhNi1iNjgzLWEyYWY3MDhiMzIyMCIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlcm5ldGVzLWRhc2hib2FyZDprdWJlcm5ldGVzLWRhc2hib2FyZCJ9.ikMgpHASp0bJ8diqK8RsoQN41Ip-UHXQHCCkN0Dvam5uWPk1y9vxGYs2Sv5HWvLl6xanZ5TyTw0y3pF-zdZoaF5ivu1KOJsdjTd5g0DQr7l5jvtGSBGNNBJSxAtUP0IyO-hTFzxIH4ePoLO_TY2j_QNMdNdBpMlRlUR917kykQaY-N_C9KhfPRuaoqz3qBpOSxQyXaXCNPfU_uweE0kmyQjr-wNIX6ZZmQpZVmt7-CNVRnFswQFTVPZBmChU5caaISVd4x6us1N2LD3AH4qk9VvrWxA7TEfoYedfCQNzzgeXGnjtEh19h11ZtCWIse_lHhTqCC04P06Fn3YtOvOQXg
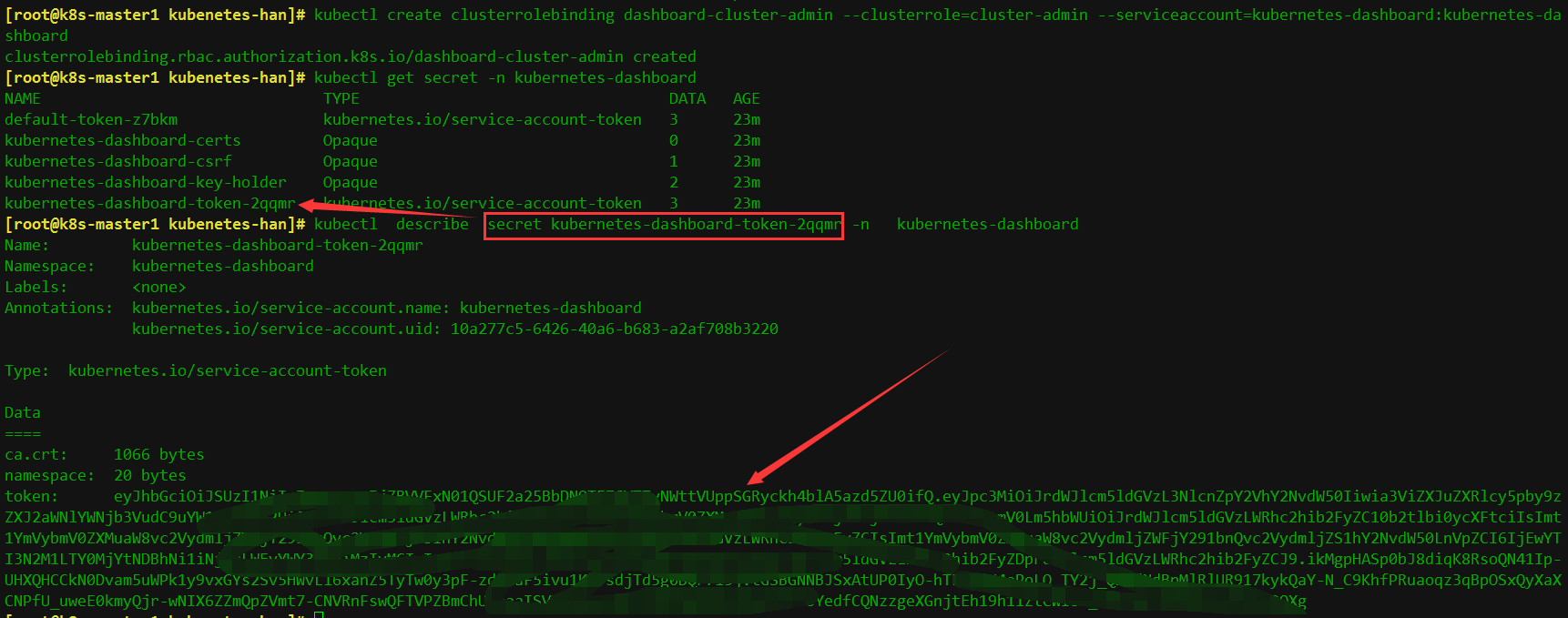
记住token后面的值,把下面的token值复制到浏览器token登陆处即可登陆:
登入后界面如下,这次就可以看到和操作任何名称空间的资源了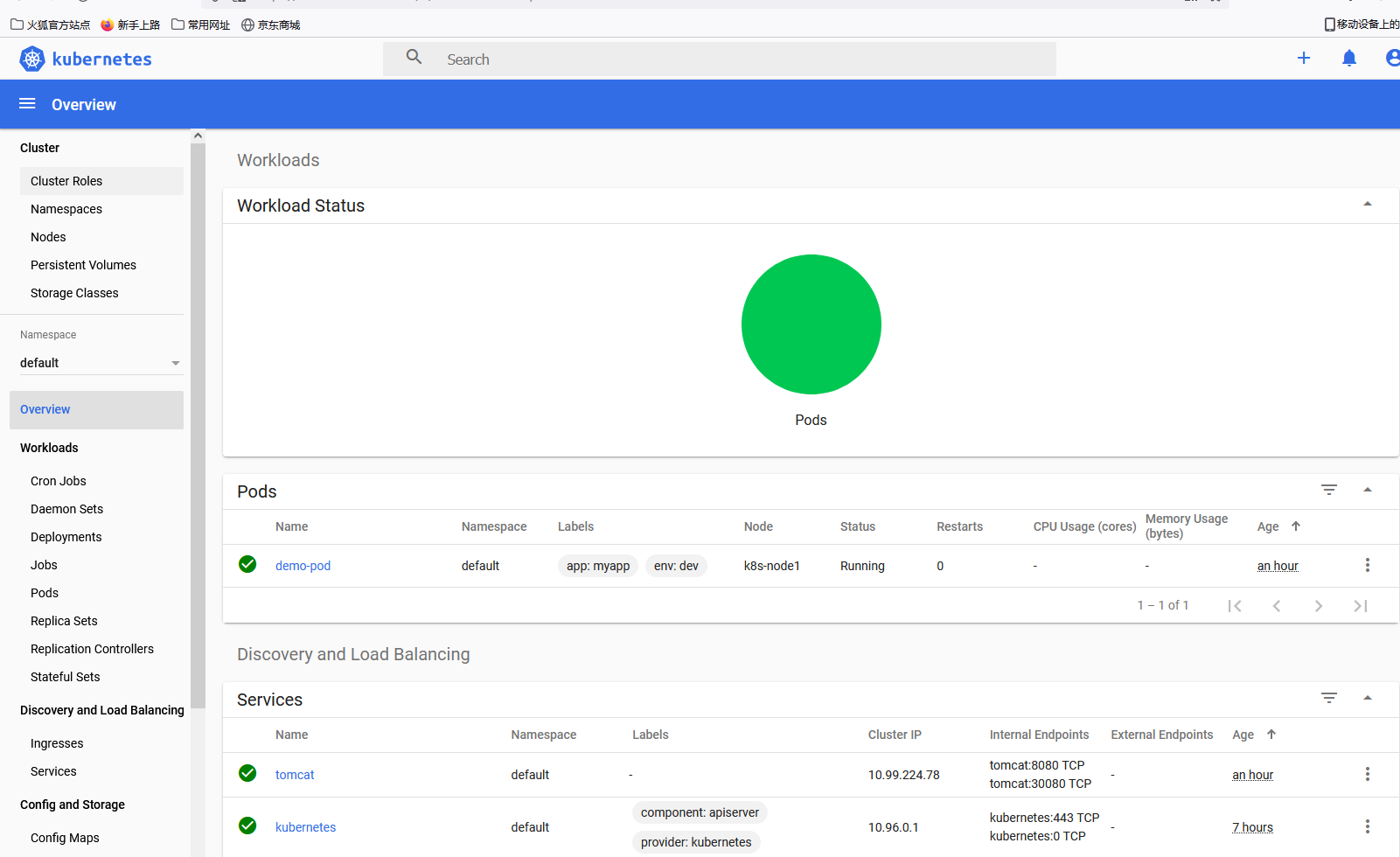
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


