
少点代码,多点头发
本文已经被GitHub收录,欢迎大家踊跃star 和 issues。
https://github.com/midou-tech/articles
入职第一周,我被坑了
最近刚入职新公司,本来想着这刚来新公司,一般都是熟悉熟悉公司同事,看看组内工程文档,找几个demo自己练练手。
咳咳咳,万万没想到啊,一切都是我以为的,我还是太嫩了。
入职那天下午,组长给我丢了几个文档,让我看下这个这些工程的缓存系统问题,让我把redis升级为哨兵模式。
接到任务的我,内心是懵逼的。

第一、不知道都是些什么类型的服务在用redis。
第二、不知道以什么姿势在用redis。
第三、如果redis挂了会不会影响用户。
第四、我完全没用过redis。
虽说没干过,但咋也不怂。毕竟要是天天干的都是干过的工作,那就是有问题了,很快就被优化掉了。
看来社招入职和校招还是不一样的,校招进来都会有些入职培训或者新人班课程。
通过这些形式的教育,第一、了解公司的文化、价值观,第二、学习工作流程、感受公司技术氛围。
任务
把我们部门所有使用redis服务升级到哨兵模式。
redis的多种模式
都说了升级到哨兵模式,那之前用的不是哨兵模式,肯定还有其他模式。
单机模式、主从模式、哨兵模式、集群模式
单机模式
这个最简单,一看就懂。
就是安装一个redis,启动起来,业务调用即可。具体安装步骤和启动步骤就不赘述了,网上随便搜一下就有了。
单机在很多场景也是有使用的,例如在一个并非必须保证高可用的情况下。
咳咳咳,其实我们的服务使用的就是redis单机模式,所以来了就让我改为哨兵模式。
说说单机的优缺点吧。
优点:
部署简单,0成本。 成本低,没有备用节点,不需要其他的开支。 高性能,单机不需要同步数据,数据天然一致性。
缺点:
可靠性保证不是很好,单节点有宕机的风险。 单机高性能受限于CPU的处理能力,redis是单线程的。
单机模式选择需要根据自己的业务场景去选择,如果需要很高的性能、可靠性,单机就不太合适了。
主从复制
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。
前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
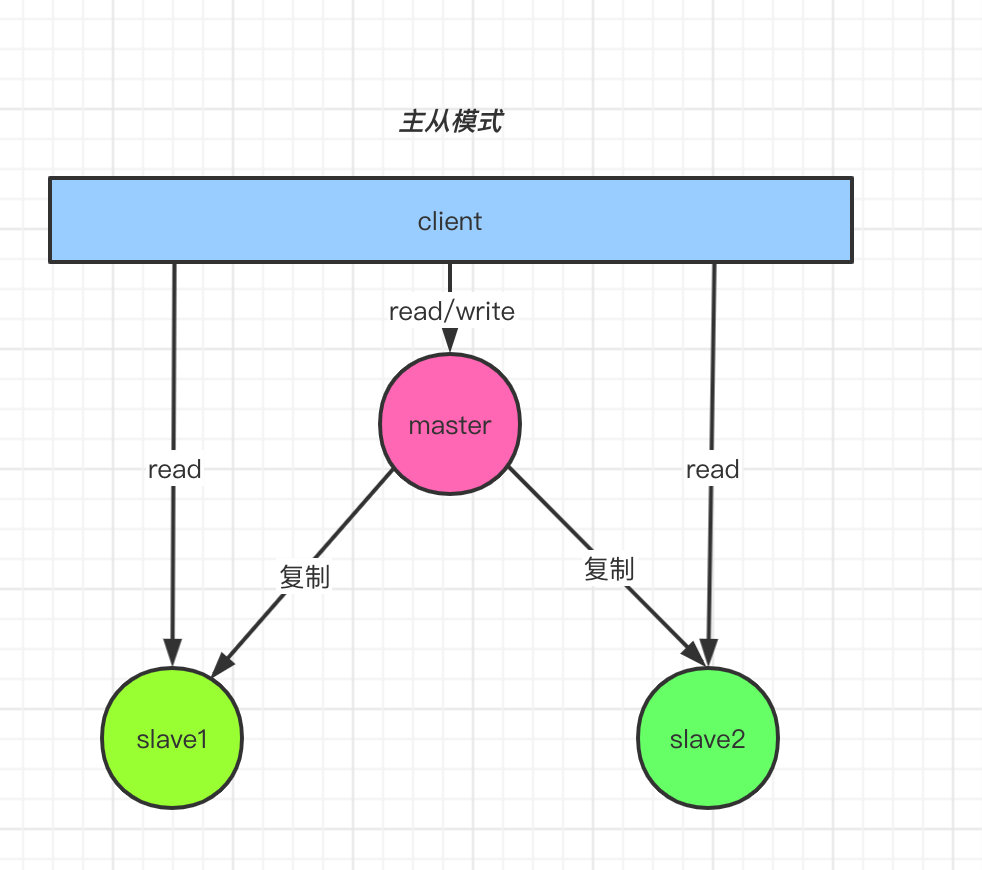
主从模式配置很简单,只需要在从节点配置主节点的ip和端口号即可。
slaveof <masterip> <masterport>
# 例如
# slaveof 192.168.1.214 6379
启动主从节点的所有服务,查看日志即可以看到主从节点之间的服务连接。
从上面很容易就想到一个问题,既然主从复制,意味着master和slave的数据都是一样的,有数据冗余问题。
在程序设计上,为了高可用性和高性能,是允许有冗余存在的。这点希望大家在设计系统的时候要考虑进去,不用为公司节省这一点资源。
对于追求极致用户体验的产品,是绝对不允许有宕机存在的。
主从模式在很多系统设计时都会考虑,一个master挂在多个slave节点,当master服务宕机,会选举产生一个新的master节点,从而保证服务的高可用性。
主从模式的优点:
一旦 主节点宕机,从节点 作为 主节点 的 备份 可以随时顶上来。
扩展 主节点 的 读能力,分担主节点读压力。
高可用基石:除了上述作用以外,主从复制还是哨兵模式和集群模式能够实施的基础,因此说主从复制是Redis高可用的基石。
也有相应的缺点,比如我刚提到的数据冗余问题:
一旦 主节点宕机,从节点 晋升成 主节点,同时需要修改 应用方 的 主节点地址,还需要命令所有 从节点 去 复制 新的主节点,整个过程需要 人工干预。 主节点 的 写能力 受到 单机的限制。 主节点 的 存储能力 受到 单机的限制。
哨兵模式
刚刚提到了,主从模式,当主节点宕机之后,从节点是可以作为主节点顶上来,继续提供服务的。
但是有一个问题,主节点的IP已经变动了,此时应用服务还是拿着原主节点的地址去访问,这...
于是,在Redis 2.8版本开始引入,就有了哨兵这个概念。
在复制的基础上,哨兵实现了自动化的故障恢复。
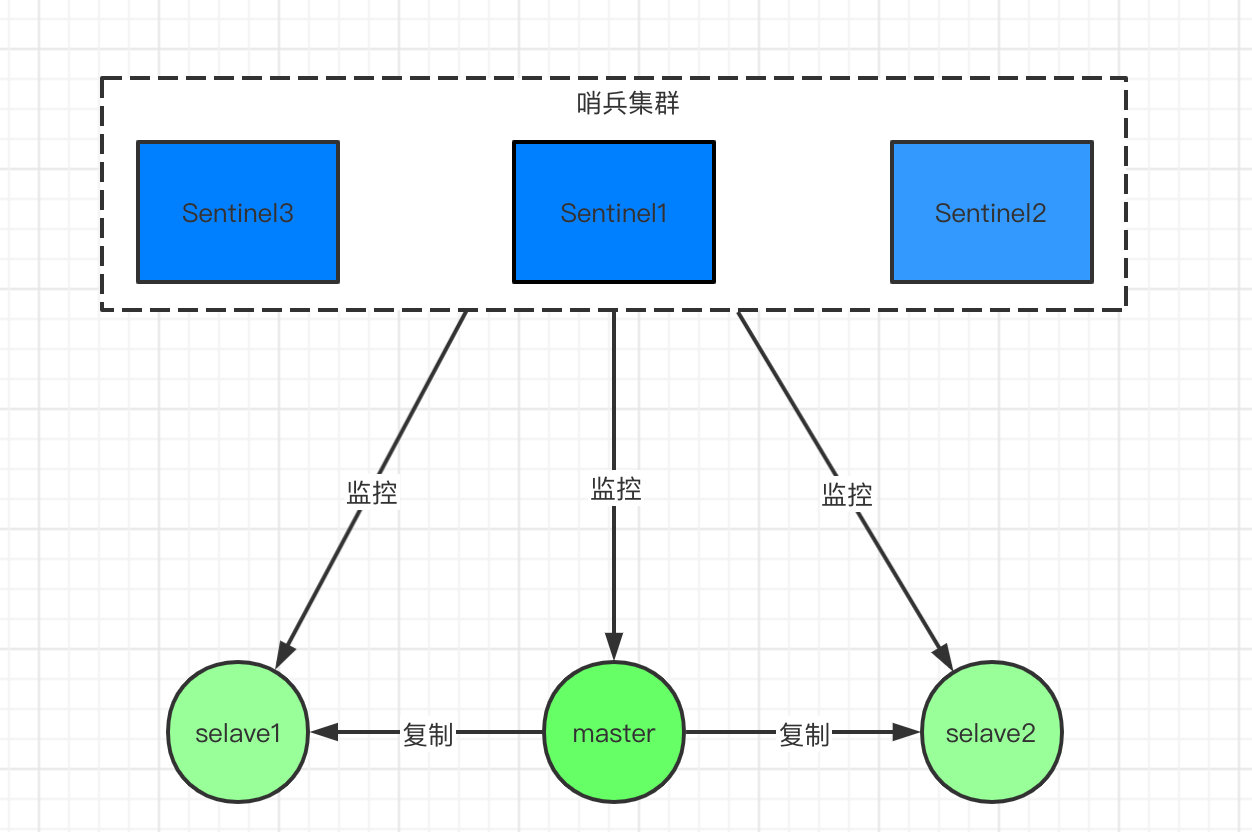
如图,哨兵节点由两部分组成,哨兵节点和数据节点:
哨兵节点:哨兵系统由一个或多个哨兵节点组成,哨兵节点是特殊的redis节点,不存储数据。 数据节点:主节点和从节点都是数据节点。
访问redis集群的数据都是通过哨兵集群的,哨兵监控整个redis集群。
一旦发现redis集群出现了问题,比如刚刚说的主节点挂了,从节点会顶上来。但是主节点地址变了,这时候应用服务无感知,也不用更改访问地址,因为哨兵才是和应用服务做交互的。
Sentinel 很好的解决了故障转移,在高可用方面又上升了一个台阶,当然Sentinel还有其他功能。
比如 主节点存活检测、主从运行情况检测、主从切换。
Redis的Sentinel最小配置是 一主一从。
说下哨兵模式监控的原理
每个Sentinel以 每秒钟 一次的频率,向它所有的 主服务器、从服务器 以及其他Sentinel实例 发送一个PING 命令。

如果一个 实例(instance)距离最后一次有效回复 PING命令的时间超过 down-after-milliseconds 所指定的值,那么这个实例会被 Sentinel标记为 主观下线。
如果一个 主服务器 被标记为 主观下线,那么正在 监视 这个 主服务器 的所有 Sentinel 节点,要以 每秒一次 的频率确认 该主服务器是否的确进入了 主观下线 状态。
如果一个 主服务器 被标记为 主观下线,并且有 足够数量 的 Sentinel(至少要达到配置文件指定的数量)在指定的 时间范围 内同意这一判断,那么这个该主服务器被标记为 客观下线。
在一般情况下, 每个 Sentinel 会以每 10秒一次的频率,向它已知的所有 主服务器 和 从服务器 发送 INFO 命令。
当一个 主服务器 被 Sentinel标记为 客观下线 时,Sentinel 向 下线主服务器 的所有 从服务器 发送 INFO 命令的频率,会从10秒一次改为 每秒一次。
Sentinel和其他 Sentinel 协商 主节点 的状态,如果 主节点处于 SDOWN`状态,则投票自动选出新的主节点。将剩余的 从节点 指向 新的主节点 进行 数据复制。
当没有足够数量的 Sentinel 同意 主服务器 下线时, 主服务器 的 客观下线状态 就会被移除。当 主服务器 重新向 Sentinel的PING命令返回 有效回复 时,主服务器 的 主观下线状态 就会被移除。
哨兵模式的优缺点
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。 主从可以自动切换,系统更健壮,可用性更高。 Sentinel 会不断的检查 主服务器 和 从服务器 是否正常运行。当被监控的某个 Redis 服务器出现问题,Sentinel 通过API脚本向管理员或者其他的应用程序发送通知。
缺点:
Redis较难支持在线扩容,对于集群,容量达到上限时在线扩容会变得很复杂。
我的任务
我部署的redis服务就如上图所示,三个哨兵节点,三个主从复制节点。
使用java的jedis去访问我的redis服务,下面来一段简单的演示代码(并非工程里面的代码):
public static void testSentinel() throws Exception {
//mastername从配置中获取或者环境变量,这里为了演示
String masterName = "master";
Set<String> sentinels = new HashSet<>();
// sentinel的IP一般会从配置文件获取或者环境变量,这里为了演示
sentinels.add("192.168.200,213:26379");
sentinels.add("192.168.200.214:26380");
sentinels.add("192.168.200.215:26381");
//初始化过程做了很多工作
JedisSentinelPool pool = new JedisSentinelPool(masterName, sentinels);
//获取到redis的client
Jedis jedis = pool.getResource();
//写值到redis
jedis.set("key1", "value1");
//读取数据
jedis.get("key1");
}
具体部署的配置文件这里太长了,需要的朋友可以公众号后台回复【redis配置】获取。
听起来是入职第二天就部署了任务感觉很难的样子。
其实现在看来是个so easy的任务,申请一个redis集群,自己配置下。在把工程里面使用到redis的地方改一下,之前使用的是一个两个单机节点。
干完,收工。

虽然领导的任务完成了,但并不意味着学习redis的路结束了。爱学习的龙叔,继续研究了下redis的集群模式。
集群模式
主从不能解决故障自动恢复问题,哨兵已经可以解决故障自动恢复了,那到底为啥还要集群模式呢?
主从和哨兵都还有另外一些问题没有解决,单个节点的存储能力是有上限,访问能力是有上限的。
Redis Cluster 集群模式具有 高可用、可扩展性、分布式、容错 等特性。
Cluster 集群模式的原理
通过数据分片的方式来进行数据共享问题,同时提供数据复制和故障转移功能。
之前的两种模式数据都是在一个节点上的,单个节点存储是存在上限的。集群模式就是把数据进行分片存储,当一个分片数据达到上限的时候,就分成多个分片。
数据分片怎么分?
集群的键空间被分割为16384个slots(即hash槽),通过hash的方式将数据分到不同的分片上的。
HASH_SLOT = CRC16(key) & 16384
CRC16是一种循环校验算法,这里不是我们研究的重点,有兴趣可以看看。
这里用了位运算得到取模结果,位运算的速度高于取模运算。
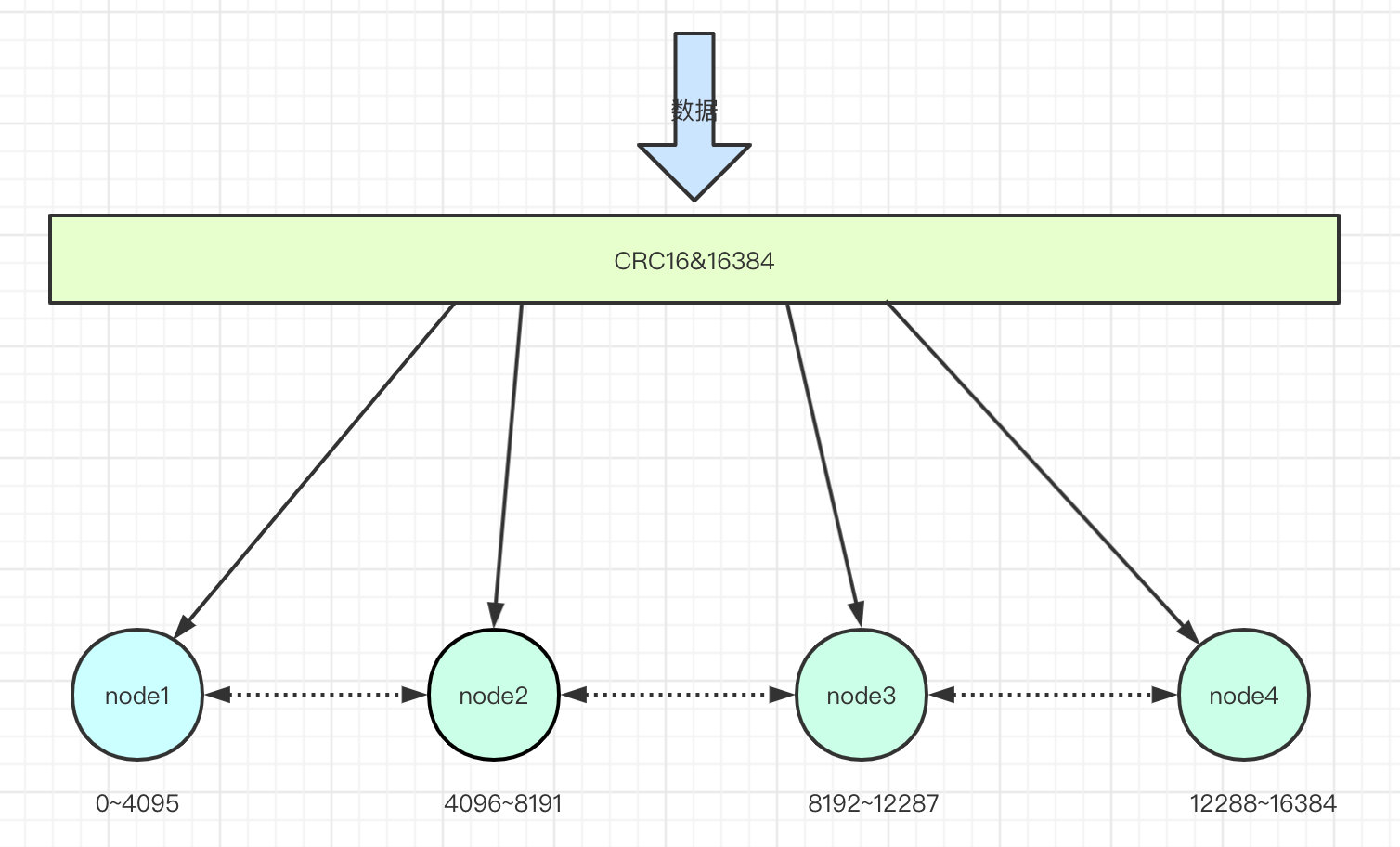
有一个很重要的问题,为什么是分割为16384个槽?这个问题可能会被面试官随口一问
数据分片之后怎么查,怎么写?
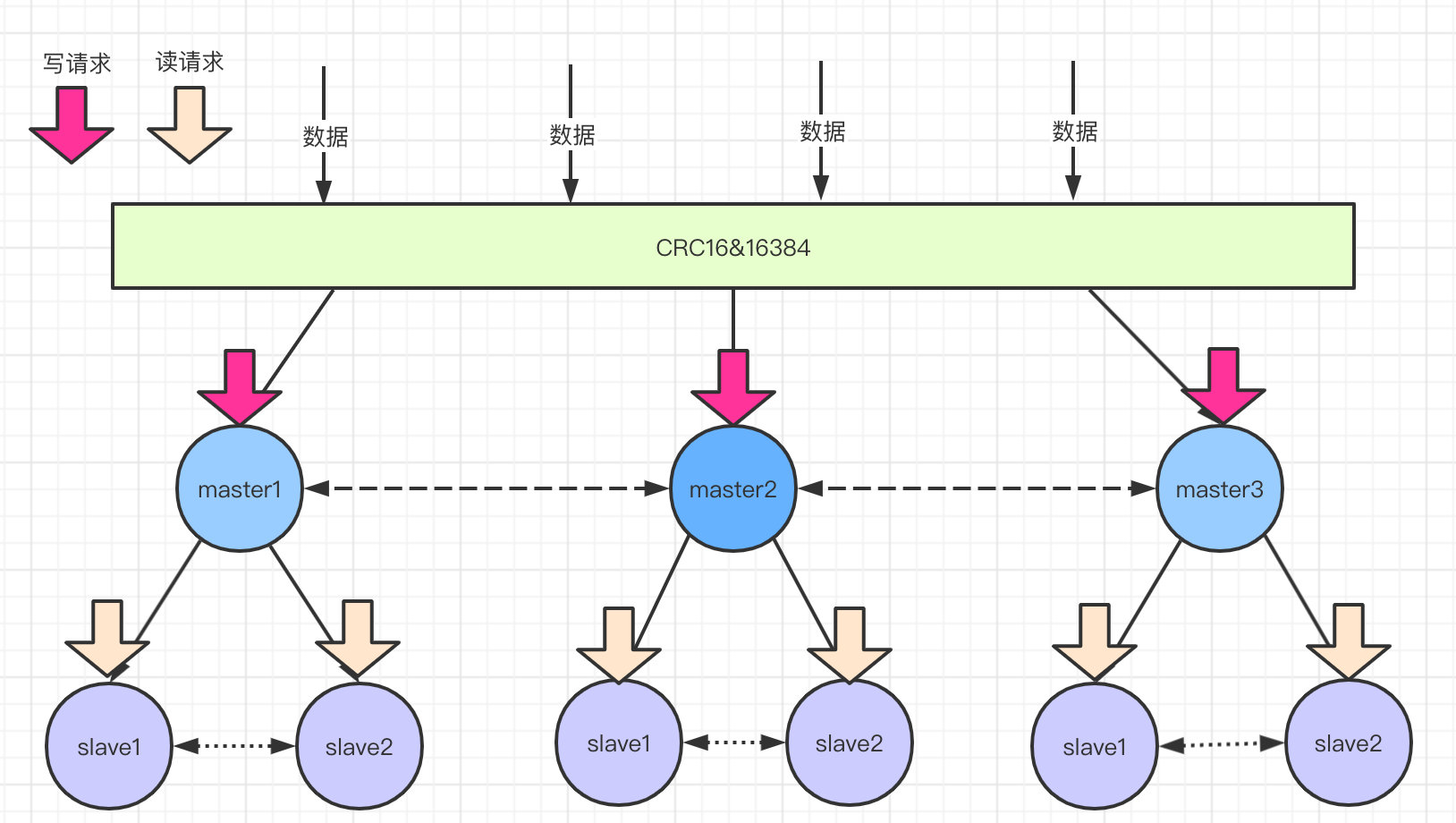
读请求分配给slave节点,写请求分配给master,数据同步从master到slave节点。
读写分离提高并发能力,增加高性能。
如何做到水平扩展?
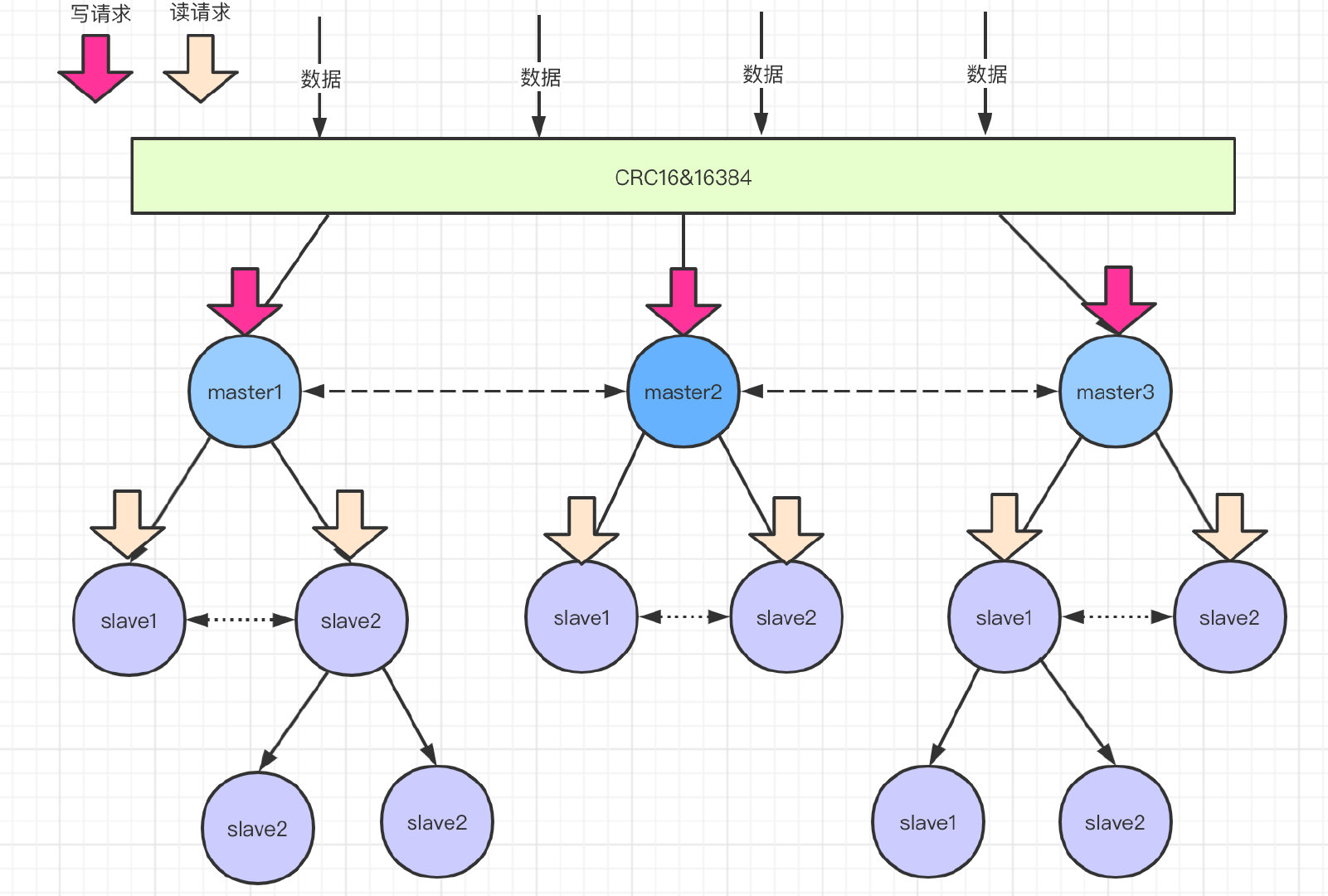
master节点可以做扩充,数据迁移redis内部自动完成。
当你新增一个master节点,需要做数据迁移,redis服务不需要下线。
举个栗子:上面的有三个master节点,意味着redis的槽被分为三个段,假设三段分别是0~7000,7001~12000、12001~16383。
现在因为业务需要新增了一个master节点,四个节点共同占有16384个槽。
槽需要重新分配,数据也需要重新迁移,但是服务不需要下线。
redis集群的重新分片由redis内部的管理软件redis-trib负责执行。redis提供了进行重新分片的所有命令,redis-trib通过向节点发送命令来进行重新分片。
如何做故障转移?
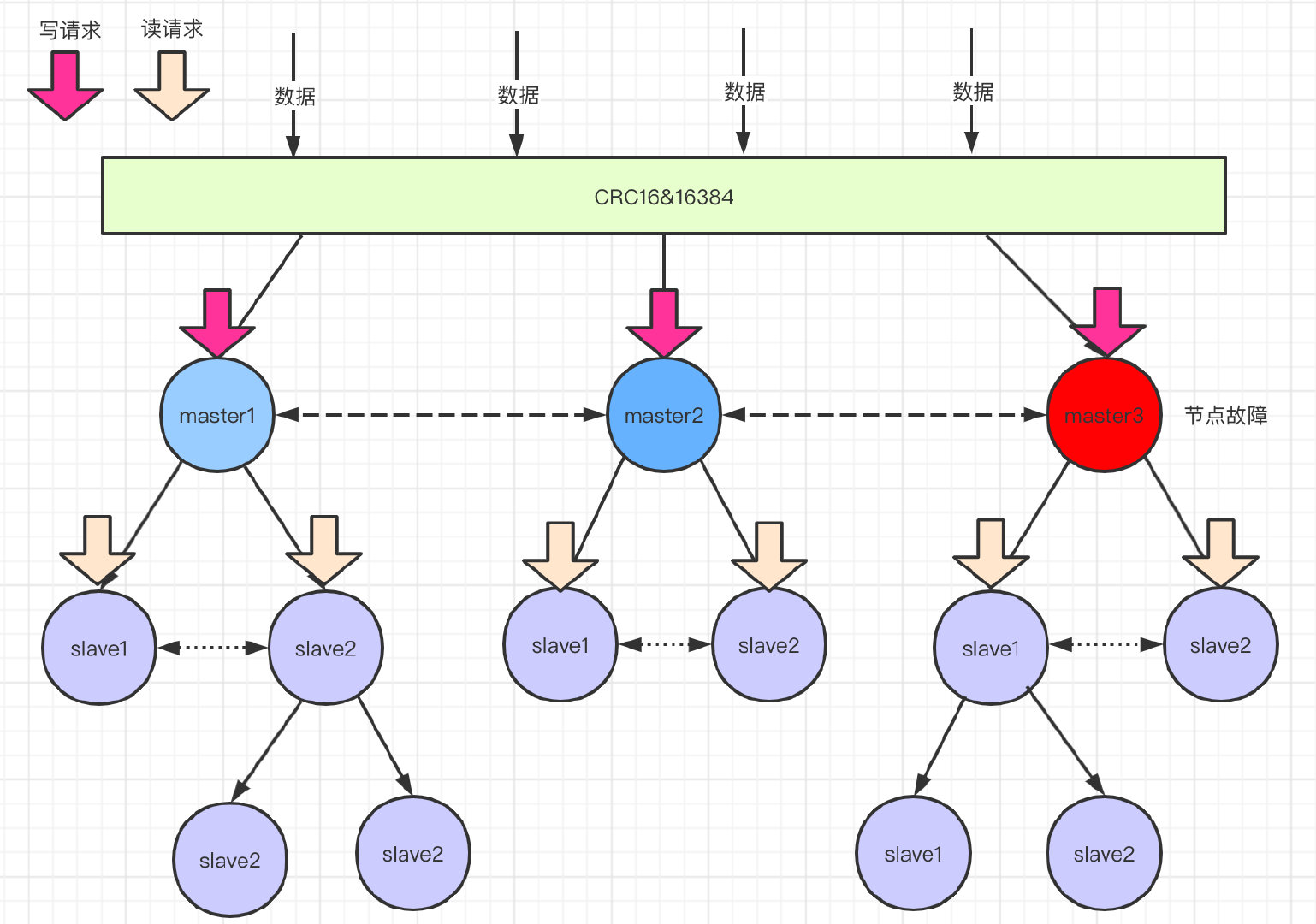
假如途中红色的节点故障了,此时master3下面的从节点会通过 选举 产生一个主节点。替换原来的故障节点。
此过程和哨兵模式的故障转移是一样的。
总结
每种模式都有各自的优缺点,在实际使用场景中要根据业务特点去选择合适的模式。
redis是一个非常常用的中间件,作为一个使用者来说,学习成本一点不高。
如果作为一个很好的中间件去研究的话,还是有很多值得学习和借鉴的地方。比如redis的各种数据结构(动态字符串、跳跃表、集合、字典等)、高效的内存分配(jemalloc)、高效的IO模型等等。
每个点都可以深入研究,在后期设计高并发、高可用系统的时候融入进去。
我是龙叔,一个分享互联网技术和成长心路历程的star。

文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


