
目录
1.事务
事务在SQL Server中相当于一个工作单元,可以确保同时发生的行为与数据的有效性不发生冲突,并且维护数据的完整性。在实际应用中,多个用户在同一时刻对同一部分数据进行操作时,可能会由于一个用户的操作使其他用户的操作和数据失效。事务可以很好地解决这一点。事务总是确保数据库的完整性。
1.1.事务的ACID属性
- 原子性(Atomicity):事务是工作单元。事务内的所有工作要不全部完成,要不全部没完成,不存在完成一部分的说法。
- 一致性(Consistency):事务完成时,所有的数据都必须是一致的。事务结束时,所有内部数据结构都必须是正确的。
- 隔离性(Isolation):由并发事务所做的修改必须与其他并发事务所做的修改隔离。事务识别数据时数据所处的状态,要不是另一并发事务修改前的状态,要不是另一并发事务修改后的状态,不存在中间状态。
- 持久性(Durability):事务提交后,事务所完成的工作结果会得到永久保存。
示例1:情况如下2个代码
--语句1:
UPDATE student
SET stu_birthday='1993-02-01',
stu_native_place='山西',
stu_phone='15729810290'
WHERE stu_no='20180101'
--语句2:
UPDATE student
SET stu_birthday='1993-02-01'
WHERE stu_no='20180101'
UPDATE student
SET stu_native_place='山西'
WHERE stu_no='20180101'
UPDATE student
SET stu_phone='15729810290'
WHERE stu_no='20180101'在语句1中,只有一个事务,对列的更新要不全部成功更新,要不全部更新失败。而语句2中,有三个事务,就算其中有某个列更新失败,也不会影响其他列的更新。
1.2.事务分类
1.2.1.系统提供的事务
系统提供的事务是指执行某些T-SQL语句时,一条语句段构成了一个事务,如ALTER TABLE,CREATE,DELETE,DROP,FETCH等。
1.2.2.用户自定义的事务
实际应用中,经常使用用户自定义的事务。自定义的方法是,以BEGIN TRANSACTION开始,以COMMIT TRANSACTION或ROLLBACK TRANSACTION结束。这两个语句之间所有语句都被视为一体。
示例2:自定义事务的应用
BEGIN TRANSACTION
INSERT INTO student(stu_no,stu_name,stu_birthday,stu_enter_score)
VALUES('20180013','贾乃亮','1993-01-20','498')
INSERT INTO student(stu_no,stu_name,stu_birthday,stu_enter_score)
VALUES('20180014','周星星','1993-07-20','532')
INSERT INTO student(stu_no,stu_name,stu_birthday,stu_enter_score)
VALUES('20180015','雨化田','错误格式数据','570')
INSERT INTO student(stu_no,stu_name,stu_birthday,stu_enter_score)
VALUES('20180016','周琪','1993-01-20','653')
INSERT INTO student(stu_no,stu_name,stu_birthday,stu_enter_score)
VALUES('20180017','陈璐','1998-01-20','599')
COMMIT TRANSACTION在上面的事务中,第三条插入数据是错误数据,无法成功插入,执行上面的语句,发现所有插入语句都没有被执行成功。
还有一种用户自定义事务——分布式事务。如果在比较复杂的环境中,有多台服务器,为了保证服务器中数据的完整性和一致性,就必须定义一个分布式事务。举个例子,有2台服务器,一台存放库存数据,另一台存放订单数据,用户下单的逻辑是,下单前先扣除库存数据,再下单。如果没有分布式事务,容易出现扣除库存数量,单下单却没成功,造成两个数据库数据不一致的情况。
1.3.管理事务
主要使用以下4条语句管理事务:BEGIN TRANSACTION,COMMIT TRANSACTION,ROLLBACK TRANSACTION和SAVE TRANSACTION。此外还有2个全局变量可以用在事务处理语句中:@@ERROR和@@TRANCOUNT。
BEGIN TRANSACTION,COMMIT TRANSACTION,ROLLBACK TRANSACTION不多说了。
1.3.1.SAVE TRANSACTION
允许部分地提交一个事务,同时仍能回退这个事务的剩余部分。
示例3:BEGIN TRANSACTION,COMMIT TRANSACTION,ROLLBACK TRANSACTION和SAVE TRANSACTION的结合使用
执行下列语句
BEGIN TRANSACTION changed
INSERT INTO student(stu_no,stu_name,stu_sex,stu_enter_score)
VALUES('20180014','谭晶','男','533')
SAVE TRANSACTION saveinsert--设置保存事务点saveinsert
UPDATE student
SET stu_sex='错误数据'
WHERE stu_no='20180014'
ROLLBACK TRANSACTION saveinsert--回滚到保存事务点saveinsert
COMMIT TRANSACTION changed上述代码完成了一个这样的功能:设置一个事务,事务名changed,该事务的作用是向student表中插入一条记录并更新该记录的stu_sex字段。如果更新失败,则回滚到插入操作,即保证不管更新是否成功,插入操作都能成功。
1.3.2.@@TRANCOUNT变量和@@ERROR变量
@@TRANCOUNT变量报告当前嵌套事务为第几层嵌套,每个BEGIN TRANSACTION都能使@@TRANCOUNT加一,@@ERROR变量用来保存任何一条T-SQL语句的最新错误号。
示例4:对示例3中代码加上对@@TRANCOUNT和@@ERROR变量的访问
执行下列语句
BEGIN TRANSACTION changed
SELECT @@TRANCOUNT AS trancount
INSERT INTO student(stu_no,stu_name,stu_sex,stu_enter_score)
VALUES('20180016','陈甜甜','女','661')
SAVE TRANSACTION saveinsert--设置保存事务点saveinsert
UPDATE student
SET stu_sex='错误数据'
WHERE stu_no='20180016'
SELECT @@ERROR AS error
ROLLBACK TRANSACTION saveinsert--回滚到保存事务点saveinsert
COMMIT TRANSACTION changed
GO结果如图所示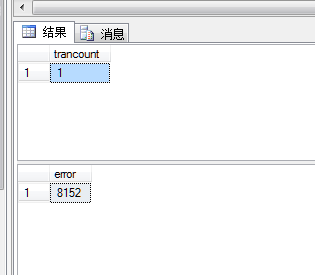
示例5:对@@TRANCOUNT变量的理解
执行下列语句
BEGIN TRANSACTION changed1
SELECT @@TRANCOUNT AS trancount
INSERT INTO class(class_id,class_name,enter_score_level)
VALUES('07','TEST','TEST')
BEGIN TRANSACTION changed2
INSERT INTO class(class_id,class_name,enter_score_level)
VALUES('08','TEST','TEST')
BEGIN TRANSACTION changed3
SELECT @@TRANCOUNT AS trancount
INSERT INTO class(class_id,class_name,enter_score_level)
VALUES('09','TEST','TEST')
COMMIT TRANSACTION changed3
COMMIT TRANSACTION changed2
COMMIT TRANSACTION changed1我在changed1和changed3中对@@TRANCOUNT变量进行了访问,结果如图所示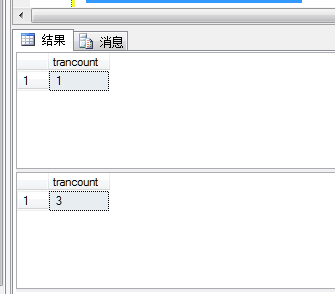
每个BEGIN TRANSACTION都使@@TRANCOUNT加一。
1.4.SQL Server本地事务支持
应用程序主要通过设置事务开始时间和事务结束时间来管理事务。这可以通过函数或者应用程序接口(API)实现。默认情况下,事务按连接级别进行处理,使用API函数或者SQL语句,可以将事务作为显式,隐式和自动提交事务来处理。
1.4.1.自动提交事务模式
自动提交事务模式是SQL Server默认的事务管理模式,每个SQL语句都是一个事务,在完成时都会被提交或回滚。在自动提交事务模式下,当遇到的错误是编译时错误,会回滚整个批处理,当遇到的错误是运行时错误,不会回滚整个批处理,而是执行部分语句并提交。
示例6:遇到编译时错误和运行时错误时,事务处理方式是不同的
执行下列语句
--编译时错误代码
USE test
GO
CREATE TABLE T1(
id INT NOT NULL,
name VARCHAR(20),
age INT,
CONSTRAINT pk_id PRIMARY KEY(id)
)
GO
INSERT INTO T1(id,name,age)VALUES
('1001','宋佳佳','26')
INSERT INTO T1(id,name,age)VALUES
('1002','陈琦','23')
INSERT INTO T1(id,name,age)VALUE
('1003','卢哲','27')--语法错误,回滚整个批处理
GO
SELECT * FROM T1结果可以看到,T1表虽然被创建了,但是三条数据都没有插入成功。可见编译时错误会回滚整个批处理。
删除T1表后执行下列语句
--运行时错误代码
USE test
GO
CREATE TABLE T1(
id INT NOT NULL,
name VARCHAR(20),
age INT,
CONSTRAINT pk_id PRIMARY KEY(id)
)
GO
INSERT INTO T1(id,name,age)VALUES
('1001','宋佳佳','26')
INSERT INTO T1(id,name,age)VALUES
('1002','陈琦','23')
INSERT INTO T1(id,name,age)VALUES
('1001','卢哲','27')--主键重复错误,仅该语句不执行
GO
SELECT * FROM T1结果如图所示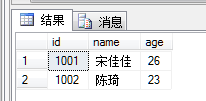
仅错误的INSERT语句不执行,而整个批处理并没有回滚。可见运行时错误不会导致整个批处理被回滚,仅仅只是中断执行。
1.4.2.显式事务模式
有明显使用BEGIN TRANSACTION语句定义一个事务的就是显式事务模式。示例2,3,4,5都是显式事务模式。
1.4.3.隐式事务模式
隐式事务模式是一种连接选项,在该选项下每个连接执行的SQL语句都被视为单独的事务。当连接以隐式事务模式进行操作时,SQL Server将在事务提交或事务回滚后自动开始新事务。隐式事务模式无需BEGIN TRANSACTION这种语句来进行定义。
1.4.3.1.通过SET IMPLICIT_TRANSACTIONS ON语句设置隐式事务模式
显式事务模式模式会在有大量DDL和DML语句执行时自动开始,并一直保持到用户明确提交为止。也就是说,如果设置了隐式事务模式,而SQL语句中又有事务没有明确提交,即使用COMMIT TRANSACTION语句提交,那么用户断开连接,或者关闭数据库时,系统会询问有未提交的事务,是否提交,如果选择否,那么未提交的事务将会被回滚,下次连接时就不存在了。
示例7:执行下列语句
SET IMPLICIT_TRANSACTIONS ON
GO
USE test
CREATE TABLE T1(
id INT NOT NULL,
name VARCHAR(20),
age INT,
CONSTRAINT pk_id PRIMARY KEY(id)
)
INSERT INTO T1(id,name,age)VALUES
('1001','宋佳佳','26')
COMMIT TRANSACTION
INSERT INTO T1(id,name,age)VALUES
('1002','陈琦','23')
INSERT INTO T1(id,name,age)VALUES
('1003','卢哲','27')
SELECT * FROM T1结果如图所示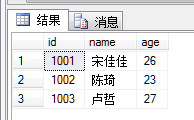
然后断开连接,出现如下提示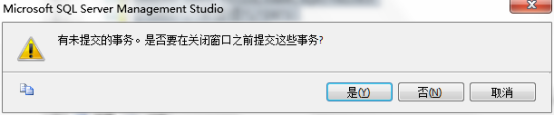
如果选择否的话,再次连接成功后SELECT T1表,结果如图所示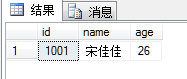
会发现1002和1003的记录都被回滚了,那是因为在插入的时候,这两条语句的事务没有COMMIT,只有第一条插入语句被提交了。这就是隐式事务模式。
1.4.3.2.调用API函数来设置隐式事务模式
用来设置隐式事务模式的API机制是ODBC和OLE DB(不能理解,不多说了)
1.4.4.批范围的事务
该事务只适用于多个活动的结果集。在MARS会话中启动的SQL显式或隐式事务,将变成批范围事务,当批处理完成时,如果批范围事务还没有被提交或回滚,SQL Server将自动对其进行回滚。
1.5.隔离级别
当多个线程都开启事务来操作数据库中的数据时,数据库要能进行隔离操作,以确保各个线程获取数据的准确性。如果没有隔离操作,会出现以下几种情况:
- 脏读:一个事务处理过程里读取了另一个未提交的事务中的数据。
例如:A转100块钱给B,SQL语句如下
UPDATE acount
SET cash=cash+100
WHERE name='B'--此时A通知B
UPDATE acount
SET cash=cash-100
WHERE name='A'执行完第一条语句时,A通知B,让B确认是否到账,B确认钱到账(此时发生了脏读),而后无论第二条SQL语句是否执行,只要事务没有提交,所有操作都将回滚,B第二次查看时发现钱没有到账。
- 不可重复读:一个事务范围内多次查询某个数据,返回不同的值,这是因为该数据被另一个事务修改并提交了。脏读和不可重复读的区别在于,脏读是读取了另一个事务还未提交的数据,不可重复都是读取了反复读取了前一个事务提交了的数据
- 幻读:比如事务T1将表中某一列数据从1修改成2,同时T2事务插入一条数据,该列值仍然是1,那么用户查询时就会发现该表还有1列数据为1,未被T1事务修改。
1.5.1.四种隔离级别
- 未提交读(READ UNCOMMITTED):事务隔离的最低级别,可执行未提交读和脏读,任何情况都无法保证
- 提交读(READ COMMITTED):在读取数据时控制共享锁,避免脏读,但无法避免不可重复读和幻读。它是SQL Server 2008的默认值。
- 可重复读(REPEATABLE READ):锁定查询过程中所有数据,防止用户更新数据,避免了脏读和不可重复读的发生,无法避免幻读。
- 可串行读(SERIALZABLE):在数据集上放置一个范围锁,防止其他用户在事务完成之前更新数据或插入行,是事务隔离的最大限制级别,避免了脏读,不可重复读和幻读的发生。
事务隔离级别越高,越能保证数据的一致性和完整性。
1.5.2.设置事务隔离级别
默认情况下,SQL Server 2008的事务隔离级别为提交读。可通过SET TRANSACTION ISOLATION LEVEL来设置事务隔离级别。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED1.6.分布式事务
对多个数据库中的数据进行修改的事务,是分布式事务。这些数据库可以是本地数据库,也可以是其他链接服务器上的数据库。
分布式事务由一个分布式事务协调程序(DTC)来控制,若想使用分布式事务,必须先启动该服务。在分布式事务中用COMMIT TRANSACTION提交事务,数据库会自动调用一个两步提交协议:1.通知每个数据库核实它们能够提交该事务并保留资源。2.当每个相关数据库通知SQL Server 2008可以随时提交该事务后,SQL Server 2008通知相关数据库提交该事务。如果有一个数据库不能成功提交该事务,则SQL Server 2008会通知所有相关数据库回滚该事务。
1.7.高级事务主题
- 嵌套事务:显式事务可以嵌套在存储过程中
- 事务保存点:提供了一种可以部分回滚事务的机制
- 绑定会话:有利于在一个服务器上的多个会话之间的协调操作,允许一个或多个会话共享事务和锁,并且可以使用同一个数据,不会有锁的冲突
1.8.管理长时间运行的事务
1.8.1.查看长时间运行的事务
执行下列语句
SELECT * FROM sys.dm_tran_database_transactions结果如图所示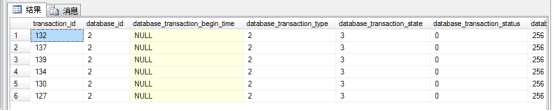
1.8.2.停止事务
停止事务可能必须运行KILL语句,使用该语句时要小心,特别是在运行重要的进程时。
- 还没有人评论,欢迎说说您的想法!
 客服
客服


