
某个接口耗时大约8s,一开始我以为是io(主要是数据库)或者网络传输的瓶颈问题。
想着多半是SQL优化的问题。
接手一看,没有进行任何的IO操作或网络传输,仅仅是内存循环处理而已。
我的开发电脑cpu是i7 8代,其运算能力,大概是,整数51.74GIPS,浮点43.99GFLOPS
一个GFLOPS(gigaFLOPS)约等于每秒拾亿(=10^9)次的浮点运算
好家伙,也就是一秒大约440亿次浮点运算?
一般来说,现在的计算机,如果不是IO或网络瓶颈,你很难把一个接口整得很慢。
需求不说了,极致简化以后大概的性能瓶颈是,需要对两个list进行嵌套循环,伪代码
for (int i = 0; i < list2.size(); i++) {
for (int j = 0; j < list.size(); j++) {
list = list.stream().sorted(Comparator.comparing(e -> e.divide(BigDecimal.ONE))).collect(Collectors.toList());
// list.get(0)
}
}
1. list.sort()和list.strem().sorted()排序的差异
简单写了个demo
List<Test.Obj> list = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < 10000000; i++) {
Test.Obj obj = new Test.Obj();
obj.setNum(random.nextInt(10000) + 10);
list.add(obj);
}
Collections.shuffle(list);
long start = System.currentTimeMillis();
//
list.sort(Comparator.comparing(e -> e.getNum()/ 10));
long end = System.currentTimeMillis();
Collections.shuffle(list);
long start2 = System.currentTimeMillis();
//
list = list.stream().sorted(Comparator.comparing(e -> e.getNum()/ 10)).collect(Collectors.toList());
long end2 = System.currentTimeMillis();
System.out.println(" 第1种耗时: " + (end - start) + " 第2种耗时: " + (end2 - start2));
输出
第1种耗时: 3601 第2种耗时: 6503
大致可以得知list原生排序比stream()流效率要高。
通过JMH做一下基准测试,分别测试集合大小在100,10000,100000时两种排序方式的性能差异。
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.infra.Blackhole;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.*;
import java.util.concurrent.ThreadLocalRandom;
import java.util.concurrent.TimeUnit;
import java.util.stream.Collectors;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Warmup(iterations = 2, time = 1)
@Measurement(iterations = 5, time = 5)
@Fork(1)
@State(Scope.Thread)
public class SortBenchmark {
@Param(value = {"100", "10000", "100000"})
private int operationSize;
private static List<Integer> arrayList;
public static void main(String[] args) throws RunnerException {
// 启动基准测试
Options opt = new OptionsBuilder()
.include(SortBenchmark.class.getSimpleName())
.result("SortBenchmark.json")
.mode(Mode.All)
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(opt).run();
}
@Setup
public void init() {
arrayList = new ArrayList<>();
Random random = new Random();
for (int i = 0; i < operationSize; i++) {
arrayList.add(random.nextInt(10000));
}
}
@Benchmark
public void sort(Blackhole blackhole) {
arrayList.sort(Comparator.comparing(e -> e));
blackhole.consume(arrayList);
}
@Benchmark
public void streamSorted(Blackhole blackhole) {
arrayList = arrayList.stream().sorted(Comparator.comparing(e -> e)).collect(Collectors.toList());
blackhole.consume(arrayList);
}
}
性能测试结果:
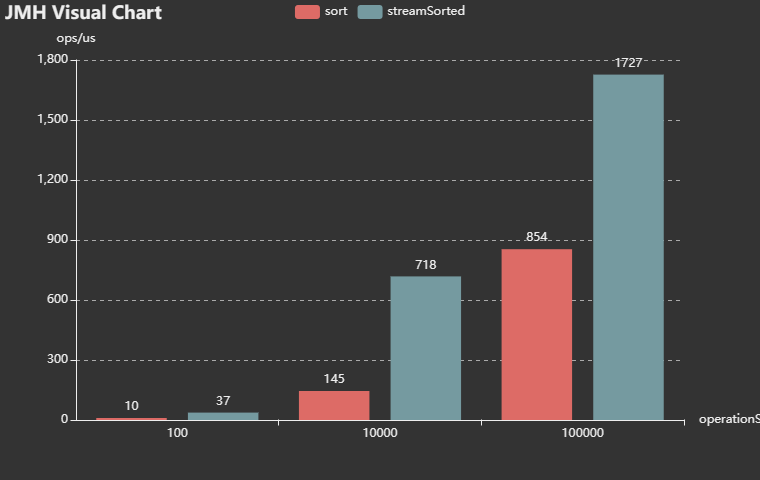
差异还是非常明显的。
还有一个非常大的问题在于,这里对list的排序仅仅只是为了获取排序字段最大值的那一列???
你别说,你还真别说!
好家伙,我直呼好家伙!
我差点就给饶进去了!
我们为什么不能只求极值? 求极值只需遍历。时间复杂度O(n)。
而java list sort排序使用的是归并排序,平均时间复杂度:O(nlogn),只有在list本身已经完全有序的情况下(有病吗),才能达到最佳时间复杂度O(n)。
优化方法:先统一使用list sort()排序,然后每次内部循环只求最大值所有列。
这两个小项改掉,响应时间直接砍半,来到了4-5秒。
2. 别在计算列上进行排序
以下代码分别对元素直接排序,和在排序时对元素进行计算并对结果排序。
List<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
arrayList.add(i + 100);
}
Collections.shuffle(arrayList);
long start = System.currentTimeMillis();
arrayList.sort(Comparator.comparing(e -> e));
System.out.println(System.currentTimeMillis() - start);
Collections.shuffle(arrayList);
long start2 = System.currentTimeMillis();
int divisor = 2;
arrayList.sort(Comparator.comparing(e -> e/divisor));
System.out.println(System.currentTimeMillis() - start2);
当divisor=2和1000时
分别输出
4897
6499
4797
3383
以下代码输出排序执行次数
List<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
arrayList.add(i + 100);
}
Collections.shuffle(arrayList);
long start2 = System.currentTimeMillis();
java.util.concurrent.atomic.AtomicInteger count = new AtomicInteger();
int divisor = 2;
arrayList.sort(Comparator.comparing(e -> {
int i = e/divisor;
count.getAndIncrement();
return i;
}));
System.out.println("count " + count.get());
当divisor=2和1000时
count分别输出
440496096
278856902
第一个输出440496096意味着e/divisor将被执行这么多次。其实它可以先遍历一次计算出来再排序,这样它就只需执行10000000次。
第二个输出278856902表示,除数越大,结果就有很多相同的数,这本身代表着部份有序性。这可以减少大量的排序。
优化方法:先统一将需要排序的值算出来,再进行排序。
3. BigDecimal的精度与效率
普通除法与BigDecimal除法的差异
int elementCount = 10000000;
List<Integer> arrayList = IntStream.rangeClosed(1, elementCount).boxed().collect(Collectors.toCollection(ArrayList::new));
Collections.shuffle(arrayList);
List<BigDecimal> list2 = new ArrayList<>(elementCount);
for (int i = 0; i < elementCount ; i++) {
list2.add(new BigDecimal(i));
}
Collections.shuffle(arrayList);
Collections.shuffle(list2);
long start = System.currentTimeMillis();
for (int num : arrayList) {
num = num / 10;
}
System.out.println(System.currentTimeMillis() - start);
long start2 = System.currentTimeMillis();
for (BigDecimal num : list2) {
num = num.divide(new BigDecimal(10), 2, RoundingMode.HALF_UP);
}
System.out.println(System.currentTimeMillis() - start2);
输出
101
497
可以看到,BigDecimal除法和double/int数据类型的除法,前者耗时是后者的5倍左右。
如果divide不设置精度num = num.divide(new BigDecimal(10))
差异更大。
99
3677
当然,这种生产环境肯定不会这样使用,除不尽会抛出异常。
优化方法:这里不需要获取高精准度,所以这里改用double进行除法。
小结
总之就是一些不起眼的小细节,在平常的时候其实无所谓。
比如,假设一个场景,人员表分页查询返回前端最多100来条了,需要根据身份证号码计算年龄并排序,考虑到直接在SQL里计算可能使身份证唯一索引失效,拿到代码中计算并排序。
userList = userList.stream().sorted(Comparator.comparing(e -> getAge(e.getIdcard()))).collect(Collectors.toList());
100来条的数据量根本不需要去考虑,list.sort()和stream().sorted()的性能差异。
以及是不是在排序列上进行了计算。
甚至于我可能需要在某个列上进行BigDecimal的四则运算。又怎样?
在这点数据量上又算得了什么呢?
但如果不注意这些细节,刚好遇上了开头所说的这个场景,那这些小细节可能就会产生非常巨大的性能差异。
通过以上3个改进点。一顿操作猛如虎,接口耗时从7-8秒稳定在了500-600毫秒。
此算法框架下,基本满足了要求。
更高的响应速度的话,基本就要从根上换一套算法了。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


