
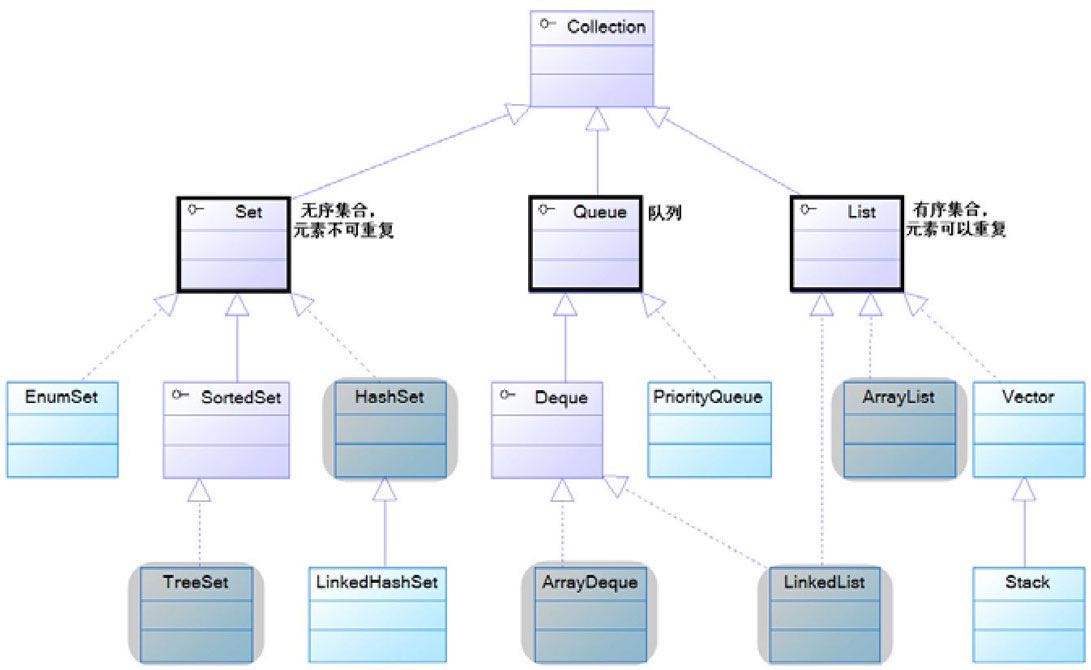
Collection集合体系继承关系

Map集合体系继承关系
1、线性表的性能分析
各种线性表的性能分析概览:

1.1、数组
以一块连续内存区来保存所有的数组元素,所以数组在随机访问时性能最好。所有的内部以数组作为底层实现的集合在随机访问时性能较好;而内部以链表作为底层实现的集合在执行插入、删除操作时有很好的性能;进行迭代操作时,以链表作为底层实现的集合比以数组作为底层实现的集合性能好。数组是所有能存储一组元素里最快的数据结构。数组可以包含多个元素,每个元素也有索引,如果需要访问某个数组元素,只需提供该元素的索引,该索引即指出了该元素在数组内存区里的存储位置。
1.2、List(interface)
是一种链表,有序可重复 List可以通过index指导元素的位置,允许重复元素。
1.2.1、LinkedList(双向链表结构)
LinkedList类是List接口的实现类-----这意味着它是一个List集合,可以根据索引来随机访问集合中的元素。除此之外,LinkedList还实现了Deque接口,因此它可以被当成双端队列来使用,自然也可以被当成“栈”来使用了。
LinkedList作为双端队列、栈的用法
public class LinkedListTest { public static void main(String[] args) { LinkedList books=new LinkedList(); //将字符串元素加入队列的尾部 books.offer("疯狂Java讲义"); //将一个字符串元素加入栈的顶部 books.push("轻量级Java EE企业应用实战"); //将字符串元素添加到队列的头部(相当于栈的顶部) books.offerFirst("疯狂Android讲义"); for (int i=0; i < books.size() ; i++ ) { System.out.println(books.get(i)); } //访问但不删除栈顶的元素 System.out.println(books.peekFirst()); //访问但不删除队列的最后一个元素 System.out.println(books.peekLast()); //将栈顶的元素弹出“栈” System.out.println(books.pop()); //下面输出将看到队列中第一个元素被删除 System.out.println(books); //访问并删除队列的最后一个元素 System.out.println(books.pollLast()); //下面输出将看到队列中只剩下中间一个元素: //轻量级Java EE企业应用实战 System.out.println(books); } }
1.2.2、ArrayList
和Vector类都是基于数组实现的List类,所以ArrayList和Vector类封装了一个动态的、允许再分配的Object[]数组。ArrayList或Vector对象使用initialCapacity参数来设置该数组的长度,当向ArrayList或Vector中添加元素超出了该数组的长度时,它们的initialCapacity会自动增加。
对于通常的编程场景,无须关心ArrayList或Vector的initialCapacity。但如果向ArrayList或Vector集合中添加大量元素时,可使用ensureCapacity(int minCapacity)方法一次性地增加initialCapacity。这可以减少重分配的次数,从而提高性能。如果开始就知道ArrayList或Vector集合需要保存多少个元素,则可以在创建它们时就指定initialCapacity大小。如果创建空的ArrayList或Vector集合时不指定initialCapacity参数,则Object[]数组的长度默认为10。
ArrayList(允许所有元素包括null)。
1.3、Queue
用于模拟队列这种数据结构,队列通常是指“先进先出”(FIFO)的容器。队列的头部保存在队列中存放时间最长的元素,队列的尾部保存在队列中存放时间最短的元素。新元素插入(offer)到队列的尾部,访问元素(poll)操作会返回队列头部的元素。通常,队列不允许随机访问队列中的元素。
1.3.1、PriorityQueue
Queue接口有一个PriorityQueue实现类。除此之外,Queue还有一个Deque接口,Deque代表一个“双端队列”,双端队列可以同时从两端来添加、删除元素,因此Deque的实现类既可当成队列使用,也可当成栈使用。Java为Deque提供了ArrayDeque和LinkedList两个实现类。
PriorityQueue是一个比较标准的队列实现类。之所以说它是比较标准的队列实现,而不是绝对标准的队列实现,是因为Prior ityQueue保存队列元素的顺序并不是按加入队列的顺序,而是按队列元素的大小进行重新排序。因此当调用peek()方法或者poll()方法取出队列中的元素时,并不是取出最先进入队列的元素,而是取出队列中最小的元素。从这个意义上来看,PriorityQueue已经违反了队列的最基本规则:先进先出(FIFO)。
1.3.2、Deque
接口是Queue接口的子接口,它代表一个双端队列。
ArrayList和ArrayDeque两个集合类的实现机制基本相似,它们的底层都采用一个动态的、可重分配的Object[]数组来存储集合元素,当集合元素超出了该数组的容量时,系统会在底层重新分配一个Object[]数组来存储集合元素。
2、Set(interface)
HashSet,LinkedHashSet,TreeSet可以实现set接口。Set是一种不包含重复元素的Collection,即任意两个元素e1和e2都是有e1.equals(e2)=false, set最多有一个null元素。因此set的构造函数有一个约束条件,传入的Collection参数不能包含重复元素。但是必须小心操作可变对像(Mutable Object).如果一个set的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
2.1、HashSet
(1)hash表里可以存储元素的位置被称为“桶(bucket)”,在通常情况下,单个“桶”里存储一个元素,此时有最好的性能:hash算法可以根据hashCode值计算出“桶”的存储位置,接着从“桶”中取出元素。但hash表的状态为open:在发生“hash冲突”的情况下,单个桶会存储多个元素,这些元素以链表形式存储,必须按顺序搜索。
(2)数据和hashSet的区别:
数组元素的索引是连续的,而且数组的长度是固定的,无法自由增加数组的长度。而HashSet就不一样了, HashSet采用每个元素的hashCode值来计算其索引,从而可以自由增加HashSet的长度,并可以根据元素的hashCode值来访问元素。因此,当从HashSet中访问元素时,HashSet先计算该元素的hashCode值(也就是调用该对象的hashCode()方法的返回值),然后直接到该hashCode值对应的位置去取出该元素——这就是HashSet速度很快的原因。
当把一个对象放入HashSet中时,如果需要重写该对象对应类的equals()方法,则也应该重写其hashCode()方法。其规则是:如果两个对象通过equals()方法比较返回true,这两个对象的hashCode值也应该相同。如果两个对象通过equals()方法比较返回true,但这两个对象的hashCode()方法返回不同的hashCode值时,这将导致HashSet会把这两个对象保存在Hash表的不同位置,从而使两个对象都可以添加成功,这就与Set集合的规则有些出入了。
如果两个对象的hashCode()方法返回的hashCode值相同,但它们通过equals()方法比较返回false时将更麻烦:因为两个对象的hashCode值相同,HashSet将试图把它们保存在同一个位置,但又不行(否则将只剩下一个对象),所以实际上会在这个位置用链式结构来保存多个对象;而HashSet访问集合元素时也是根据元素的hashCode值来快速定位的,如果HashSet中两个以上的元素具有相同的hashCode值,将会导致性能下降。
如果需要把某个类的对象保存到HashSet集合中,重写这个类的equals()方法和hashCode()方法时,应该尽量保证两个对象通过equals()方法比较返回true时,它们的hashCode()方法返回值也相等。
2.2、TreeSet
(1)当把一个对象加入TreeSet集合中时,TreeSet调用该对象的compareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树结构找到它的存储位置。如果两个对象通过compareTo(Objectobj)方法比较相等,新对象将无法添加到TreeSet集合中。
(2)补充
(2.1)红黑树的操作
红黑树是一种平衡二叉查找树,因此红黑树上的查找操作与普通二叉查找树上的查找操作相同。然而,在红黑树上进行插入操作和删除操作会导致不再符合红黑树的性质。恢复红黑树的属性需要少量(O(log n))的颜色变更(实际是非常快速的)和不超过三次树旋转(对于插入操作是两次)。 它是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。红黑树的高度近似 log2n,所以它是近似平衡,插入、删除、查找操作的时间复杂度都是 O(logn)。因为红黑树是一种性能非常稳定的二叉查找树,所以,在工程中,但凡是用到动态插入、删除、查找数据的场景,都可以用到它。不过,它实现起来比较复杂,如果自己写代码实现,难度会有些高,这个时候,我们其实更倾向用跳表来替代它。
(2.2)红黑树的优势
红黑树能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作。此外,任何不平衡都会在3次旋转之内解决。这一点是AVL(平衡二叉查找树)所不具备的。
2.3、LinkedHashSet类
HashSet还有一个子类LinkedHashSet,LinkedHashSet集合也是根据元素的hashCode值来决定元素的存储位置,但它同时使用链表维护元素的次序,这样使得元素看起来是以插入的顺序保存的。也就是说,当遍历LinkedHashSet集合里的元素时,LinkedHashSet将会按元素的添加顺序来访问集合里的元素。
LinkedHashSet需要维护元素的插入顺序,因此性能略低于HashSet的性能,但在迭代访问Set里的全部元素时将有很好的性能,因为它以链表来维护内部顺序。
3、Map接口:描述了从不重复的键到值的映射,键值对。
3.1、HashMap
散列表,基于哈希表实现,就是键值对的映射关系,元素顺序不固定,适合对元素插入删除定位等操作。
3.2、TreeMap
TreeMap就是一个红黑树数据结构,每个key-value对即作为红黑树的一个节点。TreeMap存储key-value对(节点)时,需要根据key对节点进行排序。TreeMap可以保证所有的key-value对处于有序状态。
TreeMap中判断两个key相等的标准是:两个key通过compareTo()方法返回0,TreeMap即认为这两个key是相等的。
3.3、HashTable类
继承Map接口,实现key-value的哈希表。HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
3.4、各Map实现类的性能分析
对于Map的常用实现类而言,HashMap和Hashtable的效率大致相同,因为它们的实现机制几乎完全一样;但HashMap通常比Hashtable要快一点,因为Hashtable需要额外的线程同步控制。
TreeMap通常比HashMap、Hashtable要慢(尤其在插入、删除key-value对时更慢),因为TreeMap底层采用红黑树来管理key-value对(红黑树的每个节点就是一个key-value对)。使用TreeMap有一个好处:TreeMap中的key-value对总是处于有序状态,无须专门进行排序操作。当TreeMap被填充之后,就可以调用keySet(),取得由key组成的Set,然后使用toArray()方法生成key的数组,接下来使用Arrays的binarySearch()方法在已排序的数组中快速地查询对象。对于一般的应用场景,程序应该多考虑使用HashMap,因为HashMap正是为快速查询设计的(HashMap底层其实也是采用数组来存储key-value对)。但如果程序需要一个总是排好序的Map时,则可以考虑使用TreeMap。
LinkedHashMap比HashMap慢一点,因为它需要维护链表来保持Map中key-value时的添加顺序。IdentityHashMap性能没有特别出色之处,因为它采用与HashMap基本相似的实现,只是它使用==而不是equals()方法来判断元素相等。EnumMap的性能最好,但它只能使用同一个枚举类的枚举值作为key。
4、Collection和Iterator接口
Iterator接口也是Java集合框架的成员,但它与Collection系列、Map系列的集合不一样:Collection系列集合、Map系列集合主要用于盛装其他对象,而Iterator则主要用于遍历(即迭代访问)Collection集合中的元素,Iterator对象也被称为迭代器。
Iterator必须依附于Collection对象,若有一个Iterator对象,则必然有一个与之关联的Collection对象。Iterator提供了两个方法来迭代访问Collection集合里的元素,并可通过remove()方法来删除集合中上一次next()方法返回的集合元素。
当使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有任何影响。当使用Iterator迭代访问Collection集合元素时,Collection集合里的元素不能被改变,只有通过Iterator的remove方法删除上一次next方法返回的集合元素才可以;否则将会引发java.util.Concurrent ModificationException异常。(对于HashSet以及后面的ArrayList等,迭代时删除元素都会导致异常——只有在删除集合中的某个特定元素时才不会抛出异常,这是由集合类的实现代码决定的,程序员不应该这么做。)
引申:foreach原理说明
与使用Iterator接口迭代访问集合元素类似的是,foreach循环中的迭代变量也不是集合元素本身,系统只是依次把集合元素的值赋给迭代变量,因此在foreach循环中修改迭代变量的值也没有任何实际意义。
同样,当使用foreach循环迭代访问集合元素时,该集合也不能被改变,否则将引发ConcurrentModificationException异常。
5、补充
(1)hash表的查询性能分析:
数组的特点是,寻址容易,插入和删除困难;链表的特点是,寻址困难,插入和删除容易。综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构就是哈希表,哈希表有多种不同的实现方法,最常用的一种方法——拉链法,可以理解为“链表的数组”。
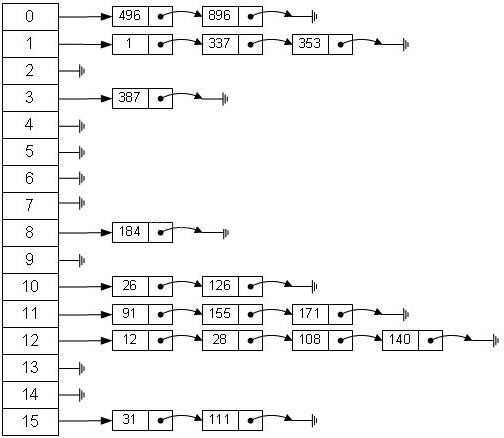
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表的头,当然这个链表可能为空,也可能元素很多。根据元素的一些特征把元素分配到不同的链表中去,也是根据这些特征,找到正确的链表,再从链表中找出这个元素。
(2)Hash的应用
1、Hash主要用于信息安全领域中加密算法,它把一些不同长度的信息转化成杂乱的128位的编码,这些编码值叫做Hash值. 也可以说,Hash就是找到一种数据内容和数据存放地址之间的映射关系。
2、查找:哈希表,又称为散列,是一种更加快捷的查找技术。哈希表是知道key值以后,直接计算出这个元素在集合中的位置,根本不需要一次又一次的查找!
(3)优缺点
优点:不论哈希表中有多少数据,查找、插入、删除只需要接近常量的时间即0(1)的时间级。哈希表的速度明显比树快,树的操作通常需要O(N)的时间级。如果不需要有序遍历数据,并且可以提前预测数据量的大小,那么哈希表在速度和易用性方面是无与伦比的。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中)。
(4)哈希表的性能分析
用平均查找长度(ASL)来度量查找表的查找效率;哈希表的性能就是看比较次数,而比较次数取决于冲突的多少,影响冲突的因素:
- 哈希函数是否均匀
- 处理冲突的方法
- 装填因子α
这里只考虑后两种因素,主要是一些理论上的结果
(4.1)线性探测法
可以证明,线性探测法的期望探测次数为:

当α=0.5时,ASLu=2.5次,ASLs=1.5次。
(4.2)平方探测法
可以证明,平方探测法的期望探测次数为:

当α=0.5时,ASLu=2次,ASLs=1.39次
(4.3)拉链法
把所有单链表的平均长度定义成装填因子α,α有可能超过1,可以证明,其平均期望探测次数p为:

当α=1时,ASLu=1.37次,ASLs=1.5次
(4.4)总结
- 选取合适的哈希函数h(key),查找效率的期望是O(1)
- 以较小的α为前提,实质是以空间换时间
- 哈希表对关键词是随机存储的,不便顺序查找
- 不适合范围查找、最大最小值查找
(5)哈希冲突的解决方法
(5.1)开放定址法
(5.2)线性探测法
是指从发生冲突的地方开始,依次探测下一个地址(表尾的下一个地址是表头),直到找到一个空闲的单元为止。表示为:d0=h(k) di=((di-1+1)) mod size
特点:操作简单。但有一个重大的缺陷是容易产生聚集现象,当一个发生冲突,后面紧接着的单元都会由于前面的堆积发生冲突。
(5.3)平方探测法
是指发生冲突时以±i2 进行探测,公式为:d0=h(k) di=((d0 ± i2)) mod size
特点:是一种较好的处理冲突的方法,其缺点是不一定能探测到哈希表上的所有单元,但至少能探测到一半单元。
理论表明,哈希表的长度为4k+3(k为整数)形式的素数,平方探测法可以探测到整个哈希表空间。
(5.4)其它方法还有伪随机序列法、双哈希函数法等 。
6、动态数据结构
动态数据结构就是动态的更新操作,里面存储的数据是时刻在变化的,不仅仅支持查询还支持插入、删除数据,而且这些操作都是非常高效的,像红黑树、散列表、跳表都是动态数据结构。
-
散列表:插入删除查找都是 O(1), 是最常用的,但其缺点是不能顺序遍历以及扩容缩容的性能损耗。适用于那些不需要顺序遍历,数据更新不那么频繁的。
-
跳表:插入删除查找都是 O(logn), 并且能顺序遍历。缺点是空间复杂度 O(n)。适用于不那么在意内存空间的,其顺序遍历和区间查找非常方便。
-
红黑树:插入删除查找都是 O(logn), 中序遍历即是顺序遍历,稳定。缺点是难以实现,查找不方便。其实跳表更佳,但红黑树已经用于很多地方了
二、线程安全集合类专题
1、Collections包装方法
Vector和HashTable被弃用后,它们被ArrayList和HashMap代替,但它们不是线程安全的,所以Collections工具类中提供了相应的包装方法把它们包装成线程安全的集合
List<E> synArrayList = Collections.synchronizedList(new ArrayList<E>());
Set<E> synHashSet = Collections.synchronizedSet(new HashSet<E>());
Map<K,V> synHashMap = Collections.synchronizedMap(new HashMap<K,V>());
Collections针对每种集合都声明了一个线程安全的包装类,在原集合的基础上添加了锁对象,集合中的每个方法都通过这个锁对象实现同步
2、java.util.concurrent包中的集合
如图所示:
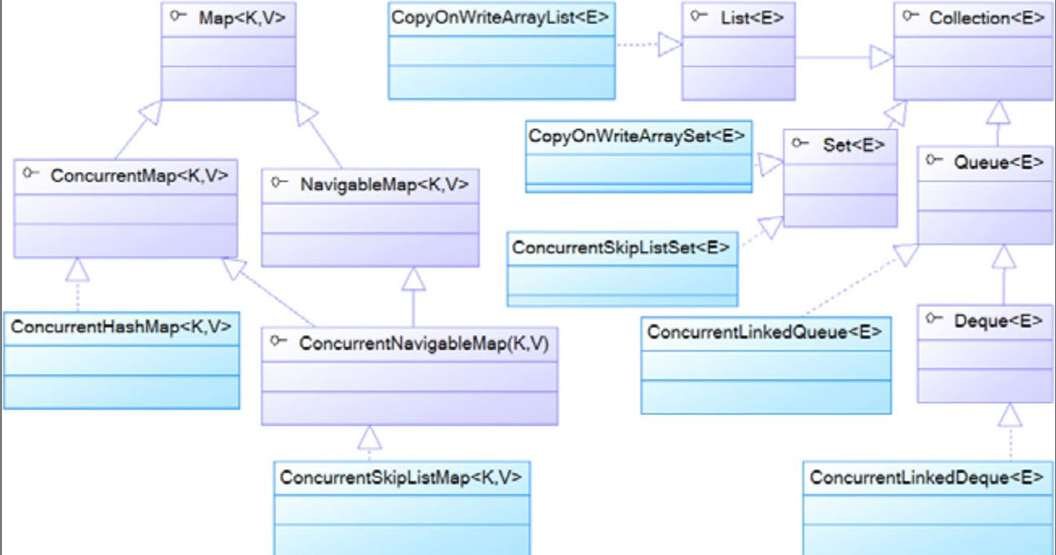
所示的类图可以看出,这些线程安全的集合类可分为如下两类:
- 以Concurrent开头的集合类,如ConcurrentHashMap、ConcurrentSkipListMap、ConcurrentSkipListSet、ConcurrentLinkedQueue和ConcurrentLinkedDeque。
- 以CopyOnWrite开头的集合类,如CopyOnWriteArrayList、CopyOnWriteArraySet。
在默认情况下,ConcurrentHashMap支持16个线程并发写入,当有超过16个线程并发向该Map中写入数据时,可能有一些线程需要等待。实际上,程序通过设置concurrencyLevel构造参数(默认值为16)来支持更多的并发写入线程。
(1).ConcurrentHashMap
ConcurrentHashMap和HashTable都是线程安全的集合,它们的不同主要是加锁粒度上的不同。HashTable的加锁方法是给每个方法加上synchronized关键字,这样锁住的是整个Table对象。而ConcurrentHashMap是更细粒度的加锁。在JDK1.8之前,ConcurrentHashMap加的是分段锁,也就是Segment锁,每个Segment含有整个table的一部分,这样不同分段之间的并发操作就互不影响;JDK1.8对此做了进一步的改进,它取消了Segment字段,直接在table元素上加锁,实现对每一行进行加锁,进一步减小了并发冲突的概率。
(2). ConcurrentSkipListMap、ConcurrentSkipListSet、ConcurrentLinkedQueue、ConcurrentLinkedDeque等,至于为什么没有ConcurrentArrayList,原因是无法设计一个通用的而且可以规避ArrayList的并发瓶颈的线程安全的集合类,只能锁住整个list,这用Collections里的包装类就能办到.
(3).CopyOnWriteArrayList和CopyOnWriteArraySet
由于CopyOnWriteArraySet的底层封装了CopyOnWriteArrayList,因此它的实现机制完全类似于CopyOnWriteArrayList集合。对于CopyOnWriteArrayList集合,它采用复制底层数组的方式来实现写操作。当线程对CopyOnWriteArrayList集合执行读取操作时,线程将会直接读取集合本身,无须加锁与阻塞。当线程对CopyOnWriteArrayList集合执行写入操作时(包括调用add()、remove()、set()等方法),该集合会在底层复制一份新的数组,接下来对新的数组执行写入操作。由于对CopyOnWriteArrayList集合的写入操作都是对数组的副本执行操作,因此它是线程安全的。需要指出的是,由于CopyOnWriteArrayList执行写入操作时需要频繁地复制数组,性能比较差,但由于读操作与写操作不是操作同一个数组,而且读操作也不需要加锁,因此读操作就很快、很安全。由此可见,CopyOnWriteArrayList适合用在读取操作远远大于写入操作的场景中,例如缓存等。
感谢阅读,借鉴了不少大佬资料,如需转载,请注明出处,谢谢!https://www.cnblogs.com/huyangshu-fs/p/11678717.html
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


