MQ系列1:消息中间件执行原理
MQ系列2:消息中间件的技术选型
1 背景
我们前面两篇对主流消息队列的基本构成和技术选型做了详细的分析。从本篇开始,我们会专注当下主流MQ之一的RocketMQ。
从他的如下的几个方面去讨论:
- 基础能力(如 组织构成、消息发送、消息存储(持久化)、消息通信、消息消费)
- 功能性方面(如消息堆积、消息回溯、消息追踪、消息过滤),
- 高可用性方面(如 消息顺序性保障、消息幂等性保障、消息安全性保障、消息事务性保障),
- 性能方面(如时效性,单机吞吐率)
1.1 RocketMQ是的基本组件构成
RocketMQ主要有四大核心组成部分:NameServer、Broker、Producer以及Consumer四部分。
- NameServer:Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步。NameServer 是整个 RocketMQ 的 "中央大脑 " ,它是 RocketMQ 的服务注册中心,所以 RocketMQ 需要先启动 NameServer 再启动 Rocket 中的 Broker。
- Broker: 消息服务器,作为Server提供消息核心服务, 它接收并存储Producer生产的消息,也提供消息给Consumer消费。Broker一般会分主从,Master 可读可写,Slave 只读。
- Producer: 消息生产者,消息的发送方,负责生产消息传输给broker。RocketMQ提供了发送:同步、异步和单向(one-way)的多种模式。
- Consumer: 消息消费者,消息的处理方,负责从broker获取消息并进行业务逻辑处理。
另外其他如 Topic、 Message,也是重要的组成部分:
- Topic:主题,发布/订阅模式下的消息统一汇集地,不同生产者向topic发送消息,由MQ服务器分发到不同的订阅者,实现消息的广播
- Message:消息体,根据不同通信协议定义的固定格式进行编码的数据包,来封装业务数据,实现消息的传输。
2 RocketMQ 消息架构的演进过程
2.1 简单的生产消费模式
根据我们前面所学的内容,消息队列很重要的一个工作就是对生产和消费者进行解耦的过程。有人负责生产,有人负责消费,两者没有直接交互,交给中介者去处理。
比如说系统A会交给系统B去处理一些事情,但是A不想直接跟B有关联,避免耦合太强,就可以通过在A,B中间加入消息队列,A将要任务的事情交给消息队列 ,B订阅消息队列来执行任务。
这种典型的模式是由两个线程和一个队列构成:
- 生产者线程:生产任务,并把任务推送到队列里。
- 消费者线程:从队列里面获取任务,并进行任务处理操作,这就是消费的过程。

目前这种还只是初级版本的 生产-消费者模式,构成了基本的消息队列 。另外为了消息队列的可用性,我们一般会把消费者,队列,生产者放到不同的服务机上,变成分布式消息队列,这样哪怕消费者所在的主机挂了,依旧不影响消息生产。
2.2 Topic模式对消息进行归类
主题(Topic)可以看做消息的归类,我们将消息进行类型划分,相同类型的消息称为一个 Topic。比如我们在淘宝或京东上购买商品的的过程,就可能产生:购物车消息、交易消息、物流消息等,1条消息必然归属于1个 Topic 。
1个 Topic可以有0 ~ n 个生产者向其发送消息;也可以被 0~n 个消费者订阅和处理,于是就有出现了生产者组和消费者组,如下图: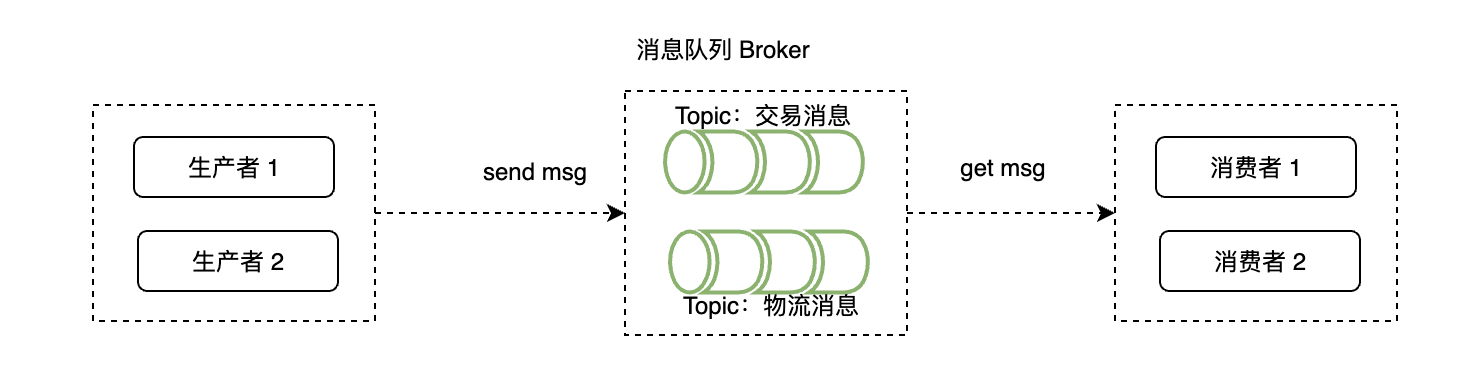
2.3 Broker 集群模式
随着生产者和消费者的不断扩大,原本单一的Broker数据处理的能力始终是有限的(无论是被写入、存储或者被消费),所以这个时候就需要对Broker进行scale out,来分担单机的压力。我们称之为 Broker 集群模式。在 微服务系列、MySQL系列、Redis系列 中,我们已经了解过很多Cluster模式的案例。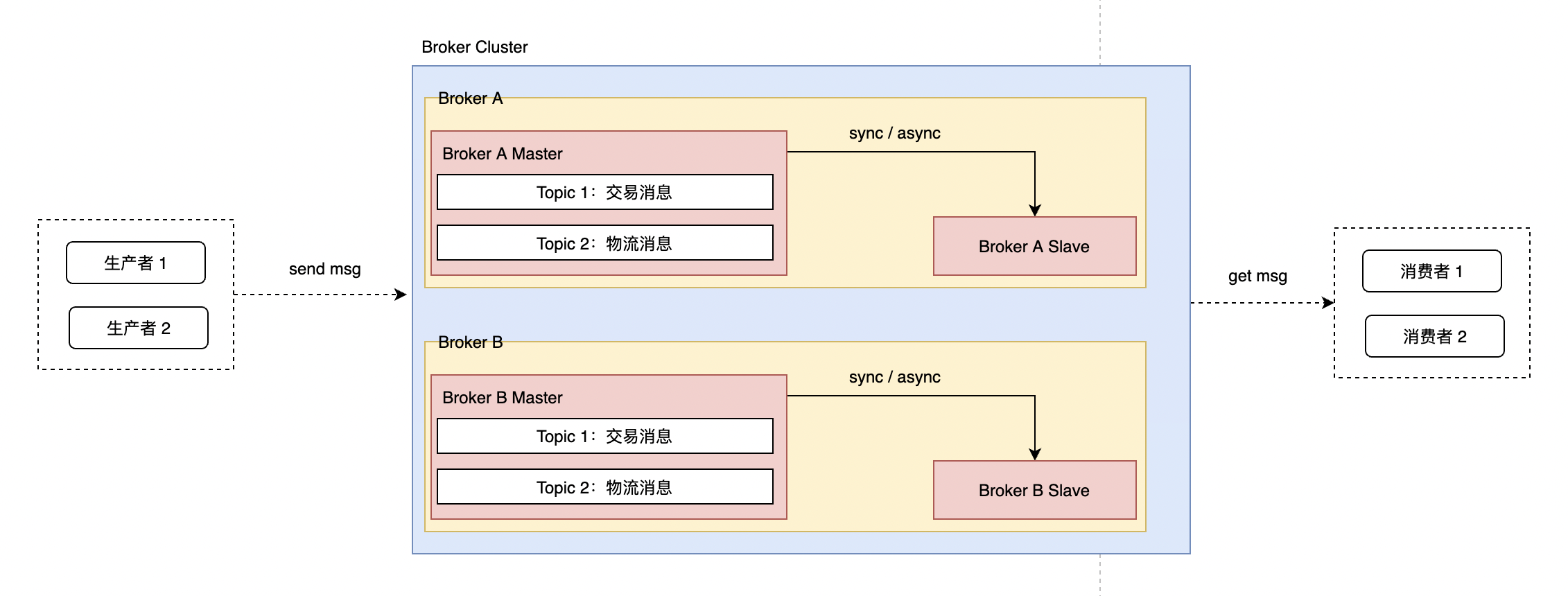
这边需要注意,每个Broker 可以包含1个 Broker Master 和 至少 1个Broker Slave ,所以它是主从结构,通过 Data Sync、Async 来进行数据同步。 Producer 只能将消息发送到 Broker Master,但是 Consumer 同时和Broker Master和 Broker Slave 建立长连接,既可以从 Master 订阅消息,也可以从 Slave 订阅消息。
- Broker Master:可以用于消息生产,也可以用于消息消费,并将消息数据 Sync / Async 到Slave。
- Broker Slave:只能用于消息消费。
2.4 使用 NameServer 来进行路由管理
我们既然使用了Broker Cluster模式,那么就会有多个Broker实例。这时候就有新的问题了,producer生产的消息需要发送到哪个Broker中,comsumer又要去哪个Broker里面去取数据,都需要梳理清楚,不然就很混乱。RocketMQ摒弃了业界常用的zookeeper作为注册中心(比如Kafka),而是使用自研的 NameServer 来管理 具有映射关系的路由信息。由它来告诉producer,某个 Topic 的消息可以发给哪些队列,同时告诉consumer可以从哪些队列里面获取你需要的消息。NameServer 也可以有很多个,组成 NameServer 集群。
总得来说,NameServer是一个功能完整的命名服务组件,提供轻量级的服务发现及完整路由信息记录能力,主要包含两个功能:
- Broker 管理,接收来自 Broker 集群的注册请求,提供心跳机制,检测 Broker 是否存活。
- 路由管理,每个 NameServer 持有全部有关 Broker 集群和客户端请求队列的路由信息。
详细运行流程可以参考如下: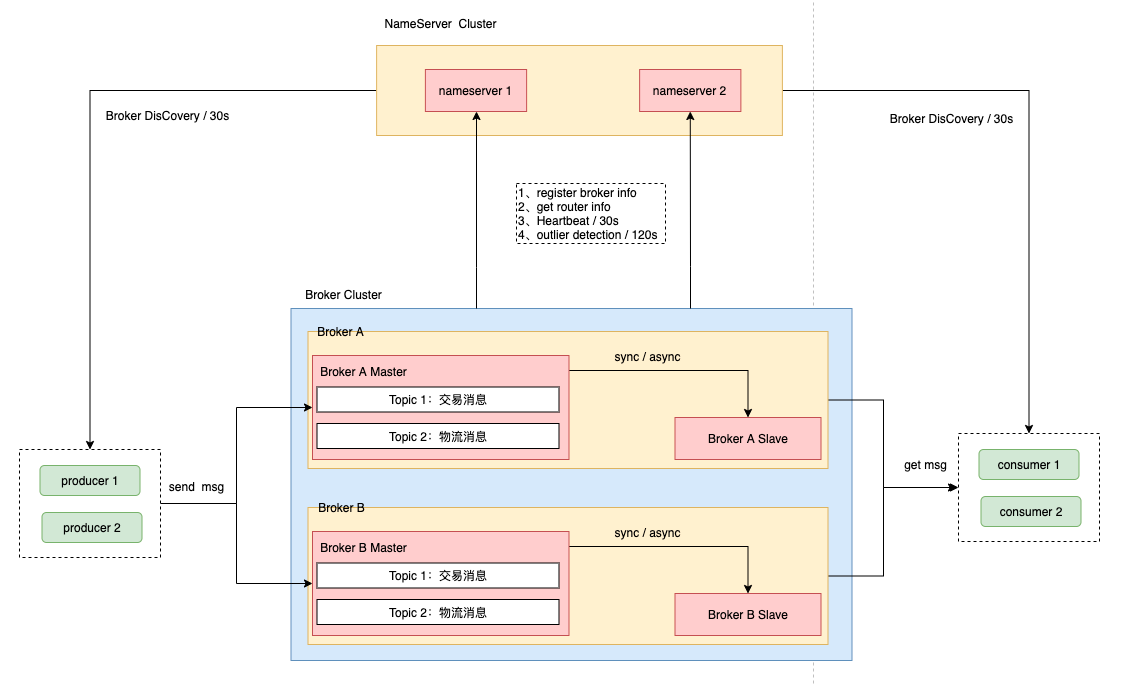
上述的流程图比较清晰的描述如下运转流程:
- NameServer 优先启动。NameServer 是整个 RocketMQ 的“中央大脑” ,作为 RocketMQ 的服务注册中心,所以 RocketMQ 需要先启动 NameServer 再启动 Rocket 中的 Broker。
- Broker 启动后,与 NameServer 保持长连接,每 30s 发送一次发送心跳包,来确保Broker是否存活。并将 Broker 信息 ( IP+、端口等信息)以及Broker中存储的Topic信息上报。注册成功后,NameServer 集群中就有 Topic 跟 Broker 的映射关系。
- NameServer 如果检测到Broker 宕机(因为使用心跳机制, 如果检测超120s(两分钟)无响应),则从路由注册表中将其移除。
- 生产者在发送某个主题的消息之前先从 NamerServer 获取 Broker 服务器地址列表(Broker可能是Cluster模式),然后根据负载均衡算法从列表中选择1台Broker ,建立连接通道,进行消息发送。
- 消费者在订阅某个topic的消息之前从 NamerServer 获取 Broker 服务器地址列表(Broker可能是Cluster模式),包括关联的全部Topic队列信息。进而获取当前订阅 Topic 存在哪些 Broker 上,然后直接跟 Broker 建立连接通道,开始消费数据。
- 生产者和消费者默认每30s 从 NamerServer 获取 Broker 服务器地址列表,以及关联的所有Topic队列信息,更新到Client本地。
3 总结
- Topic 主要是为了将消息进行归类,同一个业务中消息繁复,我们将消息按照特性进行划分,相同类型的消息称为一个 Topic。
- 当业务不断膨胀的时候,需要对Broker进行集群化,每个Broker实例包含1个 Broker Master 和 至少 1个Broker Slave ,通过 Data Sync、Async 来进行数据同步,这样达到生产和消费分离。
- 使用 NameServer 来进行 Broker 注册和管理,接收来自 Broker 集群的注册请求,提供心跳机制,检测 Broker 是否存活。
- NameServer 也用来进行路由管理,来保证 producer生产的消息需要发送到哪个Broker中,comsumer又要去哪个Broker里面去取数据。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


