一、延迟计算
RDD 代表的是分布式数据形态,因此,RDD 到 RDD 之间的转换,本质上是数据形态上的转换(Transformations)
在 RDD 的编程模型中,一共有两种算子,Transformations 类算子和 Actions 类算子。开发者需要使用 Transformations 类算子,定义并描述数据形态的转换过程,然后调用 Actions 类算子,将计算结果收集起来、或是物化到磁盘。
在这样的编程模型下,Spark 在运行时的计算被划分为两个环节。
- 基于不同数据形态之间的转换,构建计算流图(DAG,Directed Acyclic Graph)
- 通过 Actions 类算子,以回溯的方式去触发执行这个计算流图
换句话说,开发者调用的各类 Transformations 算子,并不立即执行计算,当且仅当开发者调用 Actions 算子时,之前调用的转换算子才会付诸执行。在业内,这样的计算模式有个专门的术语,叫作“延迟计算”(Lazy Evaluation)。
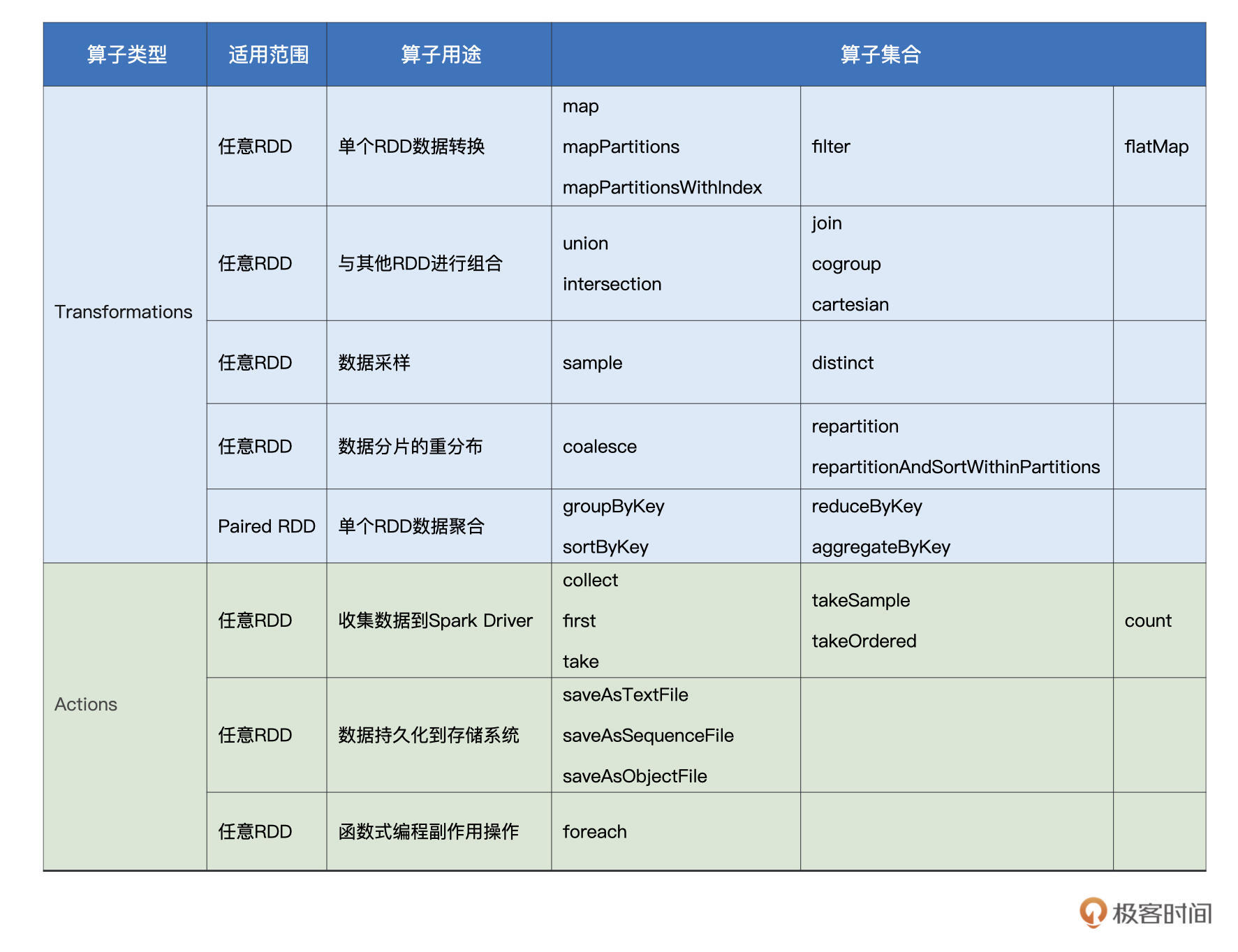
二、Spark算子分类
在 RDD 的开发框架下,哪些算子属于 Transformations 算子,哪些算子是 Actions 算子呢?
这里给出一张自己在极客看的课程中的图
三、Transform算子执行流程(源码)
Map转换算是 RDD 的经典转换操作之一了.就以它开头.Map的源码如下:

1. sc.clean(f)
首先掉了一个sc.clean(f) , 我们进到clean函数里看下:
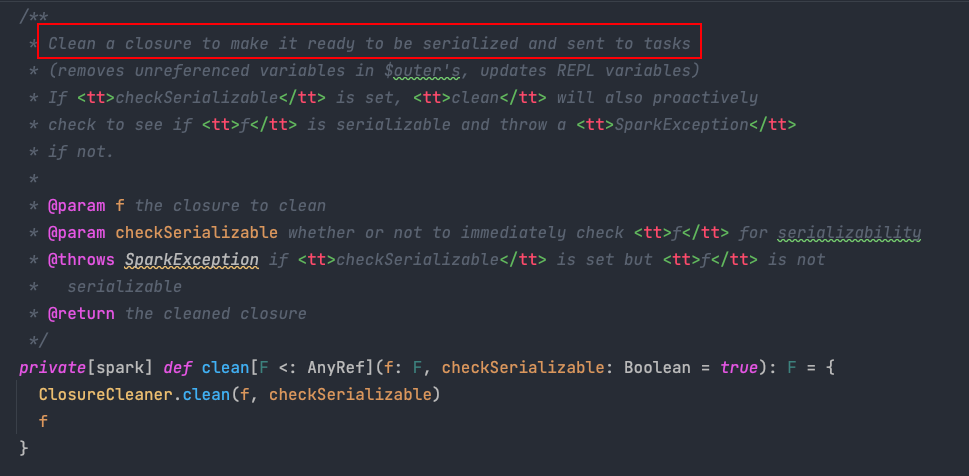
注释中明确提到了这个函数的功能:clean 整理一个闭包,使其可以序列化并发送到任务.
这里的代码有些多,大概知道这个函数的功能是这样就ok了,闭包的问题会在另一篇文章里仔细介绍
2. MapPartitionsRDD
进入到函数后源码如下:
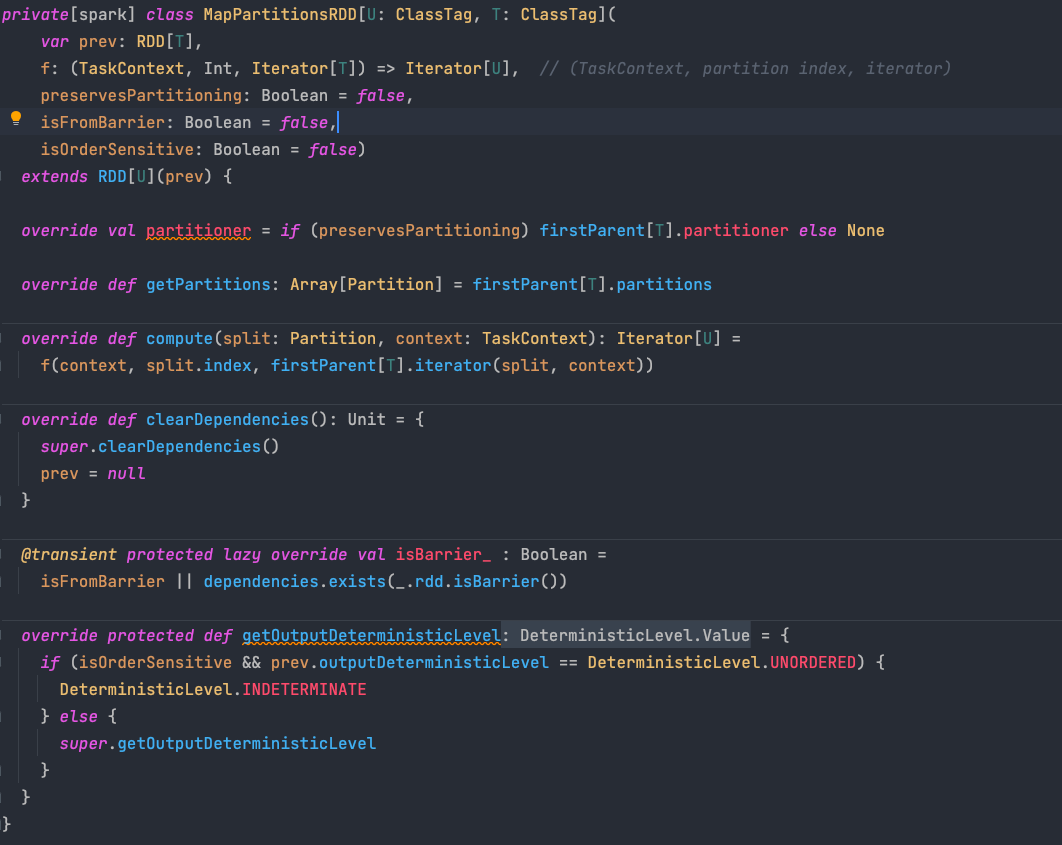
这是一个MapPartitionsRDD。我们仔细看它的构成,从而来理解它是如何描述MapPartitionsRDD的.
2.1 var prev:RDD[T]
这里的 prev 就是父RDD,f 则是Map中传入的处理函数,除了这两个就没有了,也就是说明 RDD中没有存储具体的数据本身
这再次印证了转换不会产生任何数据.它只是单纯了记录父RDD以及如何转换的过程就完了,不会在转换阶段产生任何数据集
2.2 preservesPartitioning
preservesPartitioning 表示是否保持父RDD的分区信息.
如果为false(默认为false),则会对结果重新分区.也就是Map系默认都会分区
如果为true,保留分区. 则按照 firstParent 保留分区

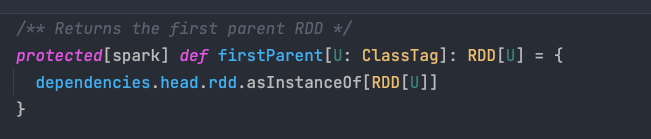
可以看到根据 dependencies 找到其第一个父 RDD
2.3 compute 计算逻辑
2.3.1 compute方法
RDD 抽象类要求其所有子类都必须实现 compute 方法,该方法接受的参数之一是一个Partition 对象,目的是计算该分区中的数据。
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
可以看到,compute 方法调用当前 RDD 内的第一个父 RDD 的 iterator 方法,该方的目的是拉取父 RDD 对应分区内的数据。
iterator 方法会返回一个迭代器对象,迭代器内部存储的每个元素即父 RDD 对应分区内已经计算完毕的数据记录。得到的迭代器作为 f 方法的一个参数。f 在 RDD 类的 map 方法中指定,即实际的转换函数。
compute 方法会将迭代器中的记录一一输入 f 方法,得到的新迭代器即为所求分区中的数据。
其他 RDD 子类的 compute 方法与之类似,在需要用到父 RDD 的分区数据时候,就会调用 iterator 方法,然后根据需求在得到的数据之上执行粗粒度的操作。换句话说,compute 函数负责的是父 RDD 分区数据到子 RDD 分区数据的变换逻辑。
2.3.2 iterator方法
此方法的实现在 RDD 这个抽象类中
/**
* Internal method to this RDD; will read from cache if applicable, or otherwise compute it.
* This should ''not'' be called by users directly, but is available for implementers of custom
* subclasses of RDD.
*/
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
interator首先检查 存储级别 storageLevel:此处可参考RDD持久化
如果存储级别不是NONE, 说明分区的数据说明分区的数据要么已经存储在文件系统当中,要么当前 RDD 曾经执行过 cache、 persise 等持久化操作,此时需要从存储空间读取分区数据,调用 getOrCompute 方法
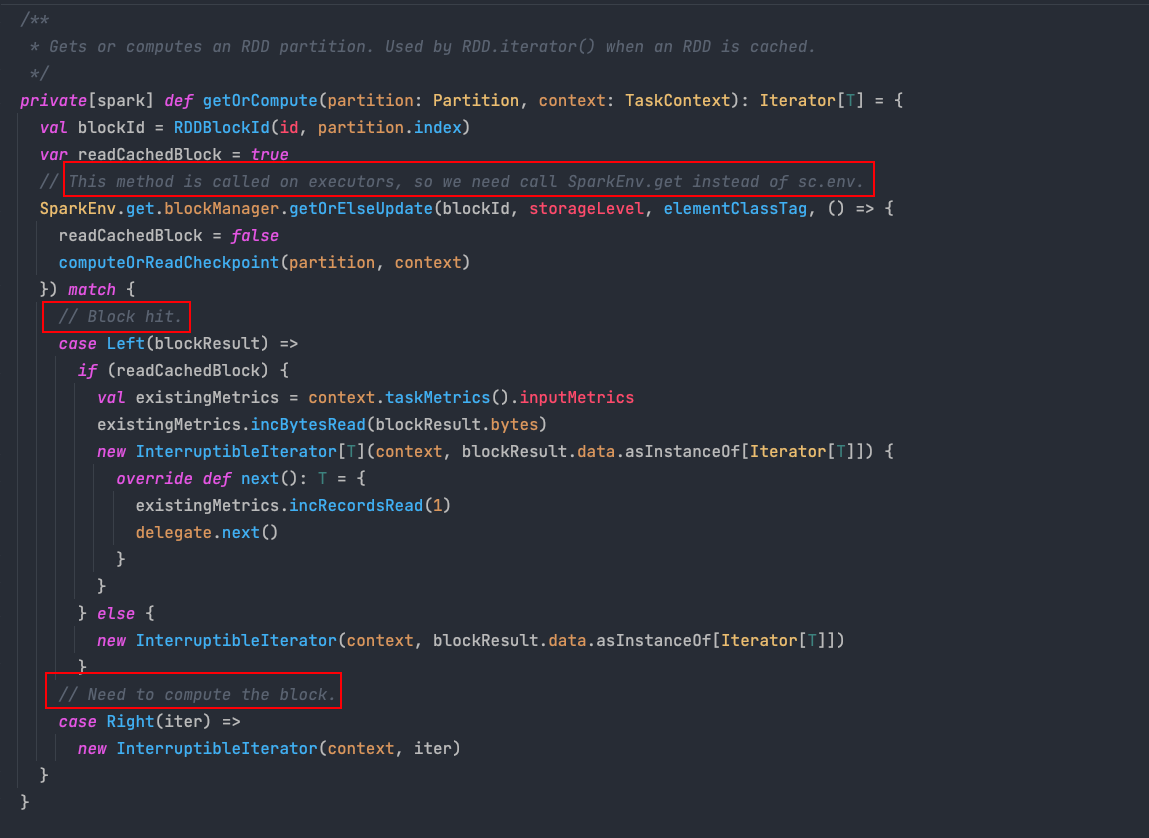
getOrCompute 方法会根据 RDD 编号:id 与 分区编号:partition.index 计算得到当前分区在存储层对应的块编号:blockId,通过存储层提供的数据读取接口提取出块的数据。
代码中的这几句注释给的非常到位,大致的判断顺序如下:
- 块命中的情况:也就是数据之前已经成功存储到介质中,这其中可能是数据本身就在存储介质中(比如通过读取HDFS创建的RDD),也可能是 RDD 在经过持久化操作并且经历了一次计算过程,这个时候我们就能成功读取数据并将其返回
- 块未命中的情况:可能是数据已经丢失,或者 RDD 经过持久化操作,但是是当前分区数据是第一次被计算,因此会出现拉取得到数据为
None的情况。这就意味着我们需要计算分区数据,继续调用RDD类computeOrReadCheckpoint方法来计算数据,并将计算得到的数据缓存到存储介质中,下次就无需再重复计算。
如果当前RDD的存储级别为 None,说明为未经持久化的 RDD,需要重新计算 RDD 内的数据,这时候调用 RDD 类的 computeOrReadCheckpoint 方法,该方法也在持久化 RDD 的分区获取数据失败时被调用。
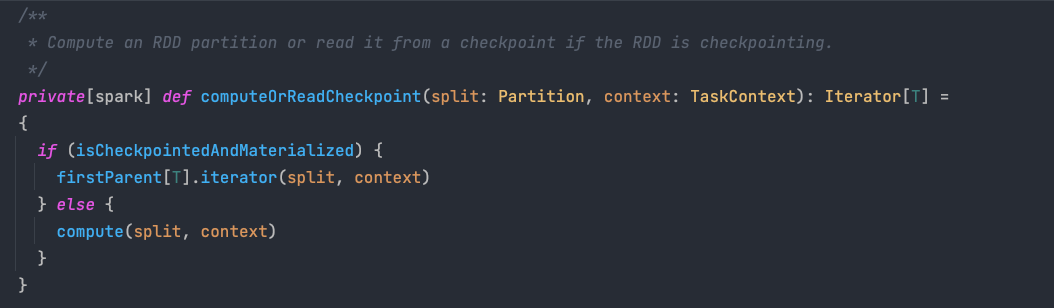
computeOrReadCheckpoint 方法会检查当前 RDD 是否已经被标记成检查点,如果未被标记成检查点,则执行自身的 compute 方法来计算分区数据,否则就直接拉取父 RDD 分区内的数据。
需要注意的是,对于标记成检查点的情况,当前 RDD 的父 RDD 不再是原先转换操作中提供数据的父 RDD,而是被 Apache Spark 替换成一个 CheckpointRDD 对象,该对象中的数据存放在文件系统中,因此最终该对象会从文件系统中读取数据并返回给 computeOrReadCheckpoint 方法
参考文章:
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


