用户提交 MapReduce 作业后,JobClient 会调用 InputFormat 的 getSplit方法 生成 InputSplit 的信息。
一个 MapReduce 任务可以有多个 Split,其用于分割用户的数据源,根据用户设定的切割大小把数据源切割成 InputSplit元数据和 InputSplit原始数据。
元数据的作用:被JobTracker使用,生成Task的本地行的数据结构。
原始数据的作用:被Map Task初始化时使用,用来获取要处理的数据。
以下开始对 class JobSplit 类进行分析:
一开始就加载meta的头信息,主要用于构成Task列表的HEAD信息
static { try { META_SPLIT_FILE_HEADER = "META-SPL".getBytes("UTF-8"); } catch (UnsupportedEncodingException u) { throw new RuntimeException(u); } }
2、New一个用于保存InputSplit元信息的数据结构
public static final TaskSplitMetaInfo EMPTY_TASK_SPLIT = new TaskSplitMetaInfo();
JobSplit 封装了读写InputSplit相关的基础类。
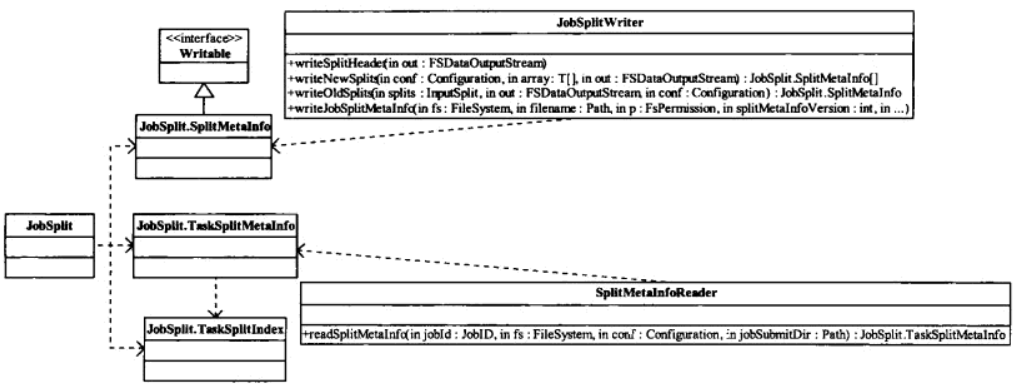
1、SplitMetaInfo
首先,对于一个Job任务来说,会有一个 job.split 文件保存所有被Split后的InputSplit 的 SplitMetaInfo 属性:
private long startOffset:该InputSplit在job.split文件中的偏移量 private long inputDataLength:该 InputSplit 的长度 private String[] locations:该 InputSplit 所在的host 列表
从这三个属性可以使TaskTracker知道从哪里读取对应的元数据并得到真正的原始数据来处理。
在 SplitMetaInfo 类中,两个比较重要的函数是 readFields(反序列化) 和 write(序列化) 。如下:
public void readFields(DataInput in) throws IOException { int len = WritableUtils.readVInt(in); locations = new String[len]; for (int i = 0; i < locations.length; i++) { locations[i] = Text.readString(in); } startOffset = WritableUtils.readVLong(in); inputDataLength = WritableUtils.readVLong(in); } public void write(DataOutput out) throws IOException { WritableUtils.writeVInt(out, locations.length); for (int i = 0; i < locations.length; i++) { Text.writeString(out, locations[i]); } WritableUtils.writeVLong(out, startOffset); WritableUtils.writeVLong(out, inputDataLength); }
在分析这两个函数之前,先简单复习序列化和反序列化的定义:
把对象转换为字节序列的过程称为对象的序列化;
把字节序列恢复为对象的过程称为对象的反序列化。
对象的序列化主要有两种用途:1)把对象的字节序列永久地存储在硬盘上,一般是文件。2)在网络上传送对象的字节序列。
接着通过查看源码,很容易会发现 public static class SplitMetaInfo implements Writable 继承了 Writable 接口,并且进入Writable 类查看得知,只要重写 Writable 就能我们自己自定义 Split 出 InputSplit的格式。
public interface Writable { /** * Serialize the fields of this object to <code>out</code>. * * @param out <code>DataOuput</code> to serialize this object into. * @throws IOException */ void write(DataOutput out) throws IOException; /** * Deserialize the fields of this object from <code>in</code>. * * <p>For efficiency, implementations should attempt to re-use storage in the * existing object where possible.</p> * * @param in <code>DataInput</code> to deseriablize this object from. * @throws IOException */ void readFields(DataInput in) throws IOException;
下面再来看看 WritableUtils (可写的工具类)这个类。
由图可以知道,这个类主要是一些IO输入输出处理的函数,有兴趣的童鞋请自行查看,在此略过了。总的来说,这两个函数主要是用于把数据序列化存储为文件永久保存在硬盘和读入数据时先把文件里的字节格式的数据先转换成对象格式。
2、TaskSplitMetaInfo
用于保存InputSplit元数据的数据结构。
其包括三个属性:
private TaskSplitIndex splitIndex:Split元信息在 jib.split 文件中的位置 private long inputDataLength:InputSplit的数据长度 private String[] locations:InputSplit所在的host列表
这三个信息是在作业初始化时,JobTracker从文件 job. splitmetainfo 文件获得的。其中,host列表信息是任务调度判断任务是否在本地的最重要因素。为什么需要这个?一切是为了提高效率,节省集群的资源开销。因为在集群中,为了容灾容错,数据一般是有多份备份的,每次TaskTracker要获取数据处理时,为了提高工作效率,都是尽可能的从本地获取数据,如果本地没有想要的数据备份时才会从本地机架的不同节点获取,再或者从不同机架的节点获取数据。
3、TaskSplitIndex
用于在JobTracker向TaskTracker分配新任务时, 指定新任务待处理数据位置信息在文件 jib.split中的索引。
其包括两个属性:
private String splitLocation:job.split文件的位置 private long startOffset:InputSplit在 job.split 文件中的位置
public void readFields(DataInput in) throws IOException { splitLocation = Text.readString(in); startOffset = WritableUtils.readVLong(in); } public void write(DataOutput out) throws IOException { Text.writeString(out, splitLocation); WritableUtils.writeVLong(out, startOffset); }
最后,JobSplit 包含的三个与Split相关的基础类,规定了如何Split出元数据和原始数据,并且构造了一个Task Split的存储列表供TaskTracker查询,因此知道从哪里得到数据来处理。
内容来源于网络如有侵权请私信删除
- 还没有人评论,欢迎说说您的想法!



 客服
客服


