在日常工作中,有时会遇到一次性往页面中插入大量数据的场景,在数栈的离线开发(以下简称离线)产品中,就有类似的场景。本文将通过分享一个实际场景中的前端开发思路,介绍当遇到大量数据时,如何实现高效的数据渲染,以达到提升页面性能和用户体验的目的。
渲染大数据量时遇到的问题
在离线的数据开发模块,用户可以在 SQL 编辑器中编写 SQL,再通过整段运行/分段运行来执行 SQL。在点击整段运行后,从运行成功日志打印后到展示结果的过程中,有一段时间页面会很卡顿,主要表现为编辑器编写卡顿。
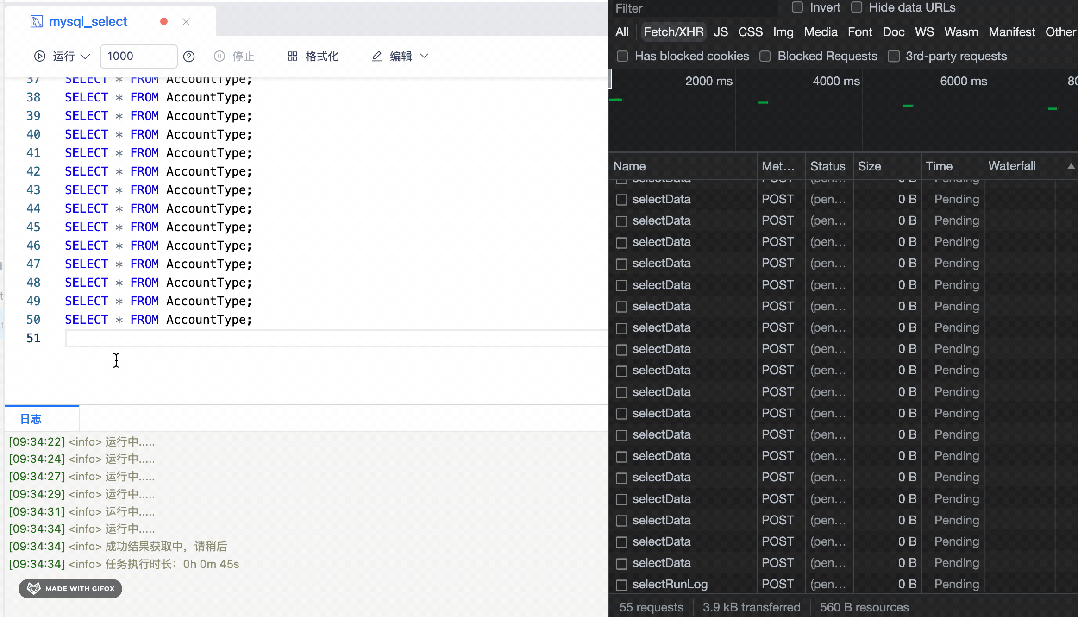
我们是在解决 SQL 最大运行行数问题时,发现了上述需要进行性能优化的场景。
先来梳理下当前代码的设计逻辑:
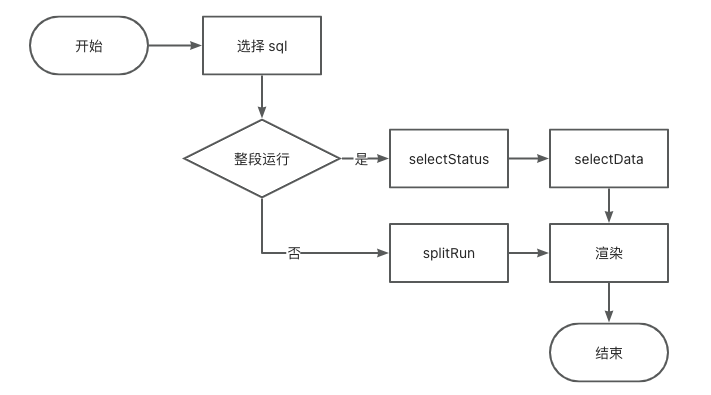
· 前端将选中的 SQL 传递给服务端,服务端返回一个调度运行的 jobId
· 前端接着以该 jobId 轮询服务端,查询任务的执行状态
· 当轮询到任务已完成时,选中的 SQL 中如果有查询语句,服务端则会按 select 语句的顺序返回一个 sqlId 的数组集合
· 前端基于n个 sqlId 的集合,并发 n个 selectData 的请求
· 所有的 selectData 请求完成后渲染数据
为了保证结果最终的展示顺序和 select 语句顺序一致,我们为单纯的 sqlIdList 循环方法加上了 Promise.allsettled 的方法,使得n个 selectData 的请求顺序和 select 语句顺序一致。
由上述逻辑可以看出,问题可能出现在如果选中的 SQL 中有大量 select 语句的话,会在「整段运行」完成后大批量请求 selectData 接口,再等待所有 selectData 请求完成后,集中进行渲染。此时,就会出现一次性往页面中插入大量数据的场景,导致卡顿。那么,我们怎么解决上述问题呢?
解决思路
可以看出,上述逻辑主要有两个问题:大批量请求 selectData 接口和集中性数据渲染。我们通过如下所示的解决思路去处理这些问题。
任务分组
依旧通过 Promise.allsettled 拿到所有 selectData 接口返回的结果,将原先集中渲染看作是一个大任务,我们将任务拆分成单个的 selectData 结果渲染任务。再根据实际情况,对单个任务进行分组,比如两个一组,渲染完一组再渲染下一组。
拆分完任务,就涉及到了任务的优先级问题,优先级决定了哪个任务先执行。这里采用最原始的“抢占式轮转”,按 sqlIdList 的顺序保留编辑器中的 SQL 顺序。
Promise.allSettled(promiseList).then((results = []) => {
const renderOnce = 2; // 每组渲染的结果 tab 数量
const loop = (idx) => {
if (promiseList.length <= idx) return;
results.slice(idx, idx + renderOnce).forEach((item, idx) => {
if (item.status === 'fulfilled') {
handleResultData(item?.value || {}, sqlIdList[idx]?.sqlId);
} else {
console.error(
'selectExecResultDataList Promise.allSettled rejected',
item.reason
);
}
});
setTimeout(() => {
loop(idx + renderOnce);
}, 100);
};
loop(0);
});
请求分组 + 任务分组
问题中的大批量请求 selectData 接口,也是一个突破点。我们可以将请求进行分组,每次以固定数量的 sqlId 去请求 selectData 接口,比如每组请求 6 个 sqlId 的结果,当前组的请求全部结束后再进行渲染。为了保证效果最优,这里也引入任务分组的思路。
const requestOnce = 6; // 每组请求的数量
// 将一维数组转换成二维数组
const sqlIdList2D = convertTo2DArray(sqlIdList, requestOnce);
const idx2D = 0; // sqlIdList2D 的索引
const requestLoop = (index) => {
if (!sqlIdList2D[index]) return;
const promiseList = sqlIdList2D[index].map((item) =>
selectExecResultData(item?.sqlId)
);
Promise.allSettled(promiseList)
.then((results = []) => {
const renderOnce = 2; // 每组渲染的结果 tab 数量
const loop = (idx) => {
if (promiseList.length <= idx) return;
results.slice(idx, idx + renderOnce).forEach((item, idx) => {
if (item.status === 'fulfilled') {
handleResultData(item?.value || {}, sqlIdList[idx]?.sqlId);
} else {
console.error(
'selectExecResultDataList Promise.allSettled rejected',
item.reason
);
}
});
setTimeout(() => {
loop(idx + renderOnce);
}, 100);
};
loop(0);
})
.finally(() => {
requestLoop(index + 1);
});
};
requestLoop(idx2D);
请求分组
上一种方案的代码相对来说又些难以理解,属于上午写,下午忘的逻辑,注释也不好写,不利于维护。基于实际情况,我们尝试下仅对请求作分组处理,看看效果。
const requestOnce = 3; // 每组请求的数量
// 将一维数组转换成二维数组
const sqlIdList2D = convertTo2DArray(sqlIdList, requestOnce);
const idx2D = 0; // sqlIdList2D 的索引
const requestLoop = (index) => {
if (!sqlIdList2D[index]) return;
const promiseList = sqlIdList2D[index].map((item) =>
selectExecResultData(item?.sqlId)
);
Promise.allSettled(promiseList)
.then((results = []) => {
results.forEach((item, idx) => {
if (item.status === 'fulfilled') {
handleResultData(item?.value || {}, sqlIdList[idx]?.sqlId);
} else {
console.error(
'selectExecResultDataList Promise.allSettled rejected',
item.reason
);
}
});
})
.finally(() => {
requestLoop(index + 1);
});
};
requestLoop(idx2D);
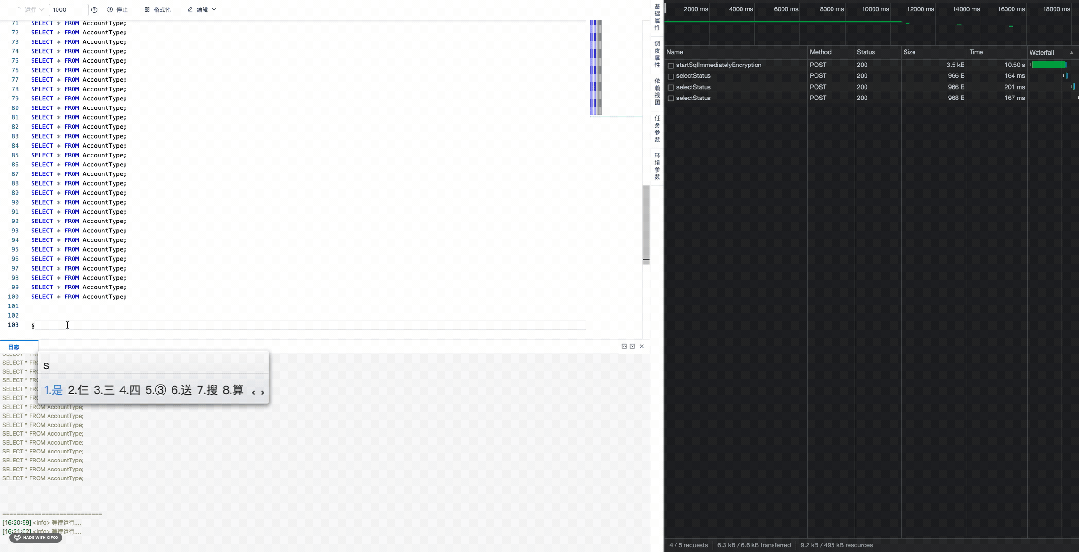
解决思路解析
· 解决大数据量渲染的问题,常见方法有:时间分片、虚拟列表等
· 解决同步阻塞的问题,常见方法有:任务分解、异步等
· 如果某个任务执行时间较长的话,从优化的角度,我们通常会考虑将该任务分解成一系列的子任务
在任务分组一节,我们将 setTimeout 的时间间隔设置为 100ms,也就是我认为最快在 100ms 内能完成渲染。但假设不到 100ms 就完成了渲染,那么就需要白白等待一段时间,这是没有必要的,这时可以考虑 window.requestAnimationFrame 方法。
- setTimeout(() => {
+ window.requestAnimationFrame(() => {
loop(idx + renderOnce);
- }, 100);
+ });
第三节的请求分组,实际上已经达到了渲染任务分组的效果。本文更多的是提供一个解决思路,上述方式也是基于对时间分片的理解实践。
在软件开发中,性能优化是一个重要的方面,但并不是唯一追求,往往还需要考虑多个因素,包括功能需求、可维护性、安全性等等。根据具体情况,综合使用多种技术和策略,找到最佳的解决方案,才是最终目的。
《数栈产品白皮书》:https://www.dtstack.com/resources/1004?src=szsm
《数据治理行业实践白皮书》下载地址:https://www.dtstack.com/resources/1001?src=szsm
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=szbky
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


