集合
scala中的集合分为两种 ,可变集合和不可变集合, 不可变集合可以安全的并发的访问!
集合的类主要在一下两个包中
- 可变集合包 scala.collection.mutable
- 不可变集合包 scala.collection.immutable 默认的
Scala 不可变集合,就是指该集合对象不可修改,每次修改就会返回一个新对象,而不会对原对象进行修改。类似于 java 中的 String 对象
可变集合,就是这个集合可以直接对原对象进行修改,而不会返回新的对象。类似于 java 中 StringBuilder 对象
建议:在操作集合的时候,不可变用符号,可变用方法
scala默认使用的是不可变的集合 , 因此使用可变的集合需要导入可变集合的包
scala的集合主要分成三大类
- Seq 序列
- Set 不重复集
- Map 键值映射集
注意: 所有的集合都继承自Iterator迭代器这个特质
不可变集合继承图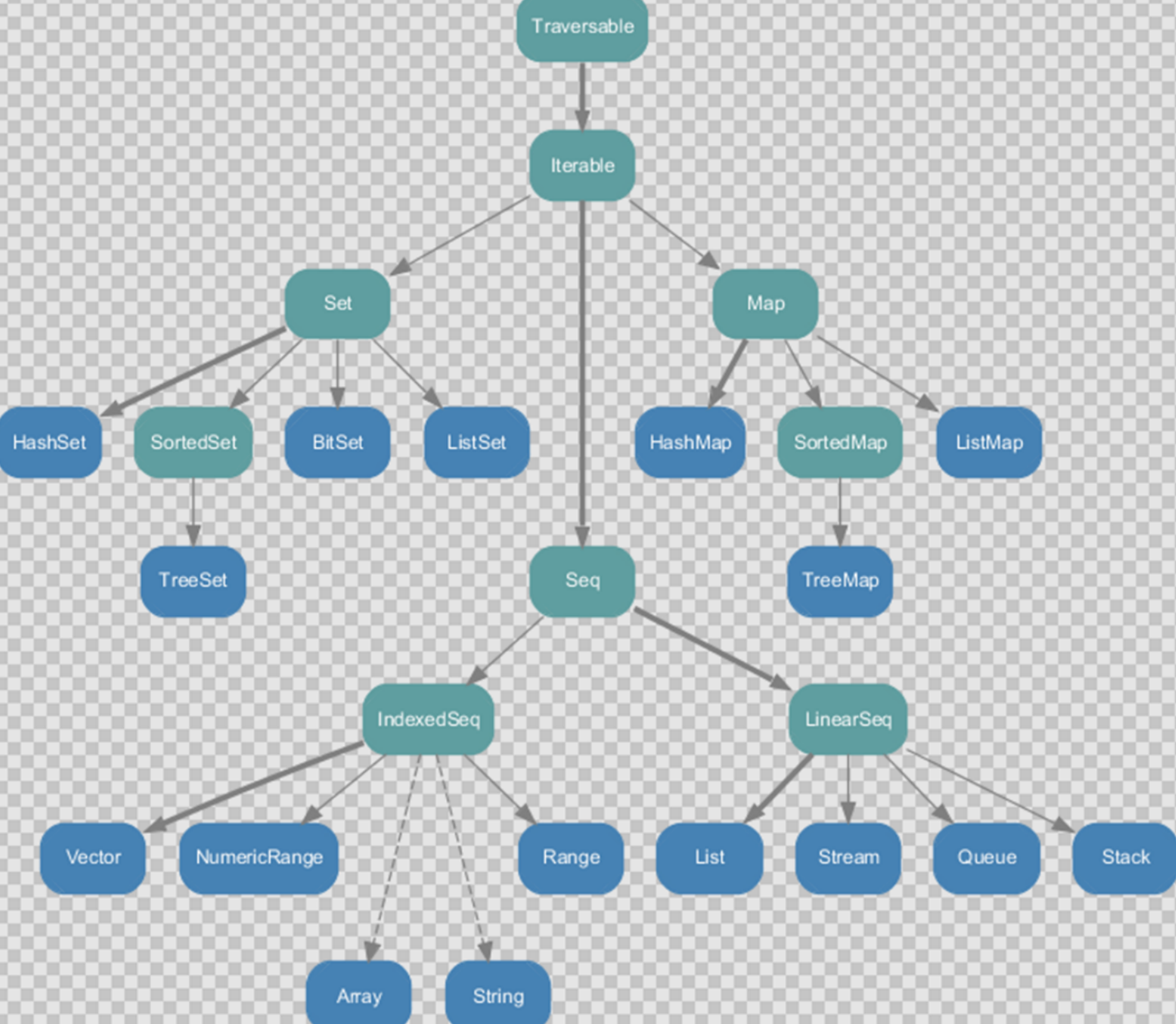
迭代器
java中的iterator
在java中用迭代器读取文件中的数据,每次返回一行数据
package com.doit;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Iterator;
class MyHero implements Iterator<String> {
BufferedReader buffer = null;
String line = null;
public MyHero() {
try {
buffer = new BufferedReader(new FileReader("data/hero.txt"));
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
@Override
public boolean hasNext() {
try {
line = buffer.readLine();
} catch (IOException e) {
e.printStackTrace();
}
return line != null;
}
@Override
public String next() {
return line;
}
}
public class MyIterator{
public static void main(String[] args) {
MyHero myHero = new MyHero();
while (myHero.hasNext()){
System.out.println(myHero.next());
}
}
}
在java中用迭代器读取mysql表中的数据,每次返回一行数据
package com.doit;
import java.sql.*;
import java.util.Iterator;
public class ReadTable implements Iterator<Login> {
ResultSet resultSet = null;
public ReadTable(){
try {
Class.forName("com.mysql.jdbc.Driver");
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
try {
Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/football", "root", "123456");
PreparedStatement pps = conn.prepareStatement("select * from login ");
resultSet = pps.executeQuery();
} catch (SQLException e) {
e.printStackTrace();
}
}
@Override
public boolean hasNext() {
boolean flag = false;
try {
flag = resultSet.next();
} catch (SQLException e) {
e.printStackTrace();
}
return flag;
}
@Override
public Login next() {
Login login = new Login();
try {
login.setId(resultSet.getInt(1));
login.setUser_id(resultSet.getInt(2));
login.setClient_id(resultSet.getInt(3));
login.setDate(resultSet.getString(4));
} catch (SQLException e) {
e.printStackTrace();
}
return login;
}
}
class Login {
private int id;
private int user_id;
private int client_id;
private String date;
public Login() {
}
public Login(int id, int user_id, int client_id, String date) {
this.id = id;
this.user_id = user_id;
this.client_id = client_id;
this.date = date;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public int getUser_id() {
return user_id;
}
public void setUser_id(int user_id) {
this.user_id = user_id;
}
public int getClient_id() {
return client_id;
}
public void setClient_id(int client_id) {
this.client_id = client_id;
}
public String getDate() {
return date;
}
public void setDate(String date) {
this.date = date;
}
@Override
public String toString() {
return "login{" +
"id=" + id +
", user_id=" + user_id +
", client_id=" + client_id +
", date='" + date + ''' +
'}';
}
}
java中的Iterable
代表可迭代的,返回的是一个迭代器
package com.doit;
import java.util.Iterator;
public class ReadTableIterable implements Iterable<Login>{
@Override
public Iterator iterator() {
return new ReadTable();
}
}
//测试
package com.doit;
import java.util.Iterator;
public class Test3 {
public static void main(String[] args) {
ReadTableIterable logins = new ReadTableIterable();
//可迭代的都会有一个迭代器对象,获取出来后用hasnext next获取数据
Iterator iterator = logins.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//可迭代的java底层都封装了增强for循环,也可以直接使用
for (Login login : logins) {
System.out.println(login);
}
}
}
scala中的 iterator
package com.doit.day01.day02
import scala.io.{BufferedSource, Source}
object MyIter {
def main(args: Array[String]): Unit = {
val iter: MyIter = new MyIter
while (iter.hasNext){
println(iter.next())
}
}
}
class MyIter extends Iterator[String]{
//读取数据
private val source: BufferedSource = Source.fromFile("data/hero.txt")
private val lines: Iterator[String] = source.getLines()
//用scala中返回迭代器中的hasNext方法直接判断
override def hasNext: Boolean = lines.hasNext
//用scala中返回迭代器中的next方法获取数据
override def next(): String = lines.next()
}
7.1.4scala中的Iterable
Scala
package com.doit.day01.day02
import scala.io.{BufferedSource, Source}
object MyIter {
def main(args: Array[String]): Unit = {
val iter: MyIter1 = new MyIter1
val iterator: Iterator[String] = iter.iterator
while (iterator.hasNext){
println(iterator.next())
}
for (elem <- iter) {
println(elem)
}
}
}
class MyIter1 extends Iterable[String]{
override def iterator: Iterator[String] = new MyIter
}
比较器
java中的比较器 Comparator
package com.doit;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Iterator;
public class Test3 {
public static void main(String[] args) {
Order or1 = new Order("001", 100, "2022-7-12");
Order or2 = new Order("002", 99, "2022-7-11");
Order or3 = new Order("003", 88, "2022-7-15");
Order or4 = new Order("004", 103, "2022-7-13");
Order or5 = new Order("005", 55, "2022-7-10");
ArrayList<Order> list = new ArrayList<>();
list.add(or1);
list.add(or2);
list.add(or3);
list.add(or4);
list.add(or5);
Collections.sort(list,new ComparatorDeme());
System.out.println(list);
Collections.sort(list,new ComparatorDeme1());
System.out.println(list);
}
}
class ComparatorDeme implements Comparator<Order>{
@Override
public int compare(Order o1, Order o2) {
return -o1.getOrderAmount() + o2.getOrderAmount();
}
}
class ComparatorDeme1 implements Comparator<Order>{
@Override
public int compare(Order o1, Order o2) {
return o1.getOrderTime().compareTo(o2.getOrderTime());
}
}
java中的比较器 Comparable
package com.doit;
//类实现Comparable 接口,重写里面的compareTo 方法
public class Order2 implements Comparable<Order2>{
private String orderId;
private int orderAmount;
private String orderTime;
public Order2() {
}
public Order2(String orderId, int orderAmount, String orderTime) {
this.orderId = orderId;
this.orderAmount = orderAmount;
this.orderTime = orderTime;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public int getOrderAmount() {
return orderAmount;
}
public void setOrderAmount(int orderAmount) {
this.orderAmount = orderAmount;
}
public String getOrderTime() {
return orderTime;
}
public void setOrderTime(String orderTime) {
this.orderTime = orderTime;
}
@Override
public String toString() {
return "Order{" +
"orderId='" + orderId + ''' +
", orderAmount=" + orderAmount +
", orderTime='" + orderTime + ''' +
'}';
}
@Override
public int compareTo(Order2 o) {
return this.orderAmount - o.orderAmount;
}
}
package com.doit;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Iterator;
public class Test3 {
public static void main(String[] args) {
// Order or1 = new Order("001", 100, "2022-7-12");
// Order or2 = new Order("002", 99, "2022-7-11");
// Order or3 = new Order("003", 88, "2022-7-15");
// Order or4 = new Order("004", 103, "2022-7-13");
// Order or5 = new Order("005", 55, "2022-7-10");
//
// ArrayList<Order> list = new ArrayList<>();
// list.add(or1);
// list.add(or2);
// list.add(or3);
// list.add(or4);
// list.add(or5);
// Collections.sort(list,new ComparatorDeme());
// System.out.println(list);
// Collections.sort(list,new ComparatorDeme1());
// System.out.println(list);
// System.out.println("===========华丽的分割线==========");
Order2 o1 = new Order2("001", 100, "2022-7-12");
Order2 o2 = new Order2("002", 99, "2022-7-11");
Order2 o3 = new Order2("003", 88, "2022-7-15");
Order2 o4 = new Order2("004", 103, "2022-7-13");
Order2 o5 = new Order2("005", 55, "2022-7-10");
ArrayList<Order2> list1 = new ArrayList<>();
list1.add(o1);
list1.add(o2);
list1.add(o3);
list1.add(o4);
list1.add(o5);
//这边就不需要再传入比较器了
Collections.sort(list1);
System.out.println(list1);
}
}
scala中的比较器 Ordering 类比于java中的Comparator
package com.doit.day01.day02
import scala.util.Sorting
object Demo_Ordering {
def main(args: Array[String]): Unit = {
val e1: Employee = new Employee(1, "涛哥", 10000)
val e2: Employee = new Employee(2, "星哥", 8000)
val e3: Employee = new Employee(3, "行哥", 5000)
val e4: Employee = new Employee(4, "源哥", 3500)
val e5: Employee = new Employee(5, "娜姐", 2000)
val list: Array[Employee] = List(e1, e2, e3, e4, e5).toArray
Sorting.quickSort(list)(MyOrdering())
println(list.mkString(","))
}
}
case class MyOrdering() extends Ordering[Employee] {
override def compare(x: Employee, y: Employee): Int = (x.salary - y.salary).toInt
}
class Employee(val id:Int,val name:String,val salary:Double){
override def toString = s"Employee(id=$id, name=$name, salary=$salary)"
}
scala中的比较器 Ordered 类比于java中的Comparable
package com.doit.day01.day02
import scala.util.Sorting
object Demo_Ordering {
def main(args: Array[String]): Unit = {
val e1: Employee = new Employee(1, "涛哥", 10000)
val e2: Employee = new Employee(2, "星哥", 8000)
val e3: Employee = new Employee(3, "行哥", 5000)
val e4: Employee = new Employee(4, "源哥", 3500)
val e5: Employee = new Employee(5, "娜姐", 2000)
val list: Array[Employee] = List(e1, e2, e3, e4, e5).toArray
Sorting.quickSort(list)
println(list.mkString(","))
}
}
class Employee(val id:Int,val name:String,val salary:Double) extends Ordered[Employee]{
override def toString = s"Employee(id=$id, name=$name, salary=$salary)"
override def compare(that: Employee): Int = (this.salary - that.salary).toInt
}
序列
许多数据结构是序列型的,也就是说,元素可以按特定的顺序访问,如:元素的插入顺
序或其他特定顺序。collection.Seq是一个trait,是所有可变或不可变序列类型的抽象,其子trait collection.mutable.Seq及collection.immutable.Seq分别对应可变和不可变序列。
从上面的图中可以看出Array,String ,List都属于序列
不可变数组
数组的基本操作 , scala中的数组和java中的不太一样 ,这里的数组类似于一个数组对象 .有自己的方法!!
数组的定义方式
方式一:创建一个长度固定的数组,后面再赋值
object TestArray{
def main(args: Array[String]): Unit = {
//(1)数组定义
val arr01 = new Array[Int](4)
println(arr01.length) // 4
//(2)数组赋值
//(2.1)修改某个元素的值
arr01(3) = 10
//(2.2)采用方法的形式给数组赋值
arr01.update(0,1)
//(3)遍历数组
//(3.1)查看数组
println(arr01.mkString(","))
//(3.2)普通遍历
for (i <- arr01) {
println(i)
}
//(3.3)简化遍历
def printx(elem:Int): Unit = {
println(elem)
}
arr01.foreach(printx)
// arr01.foreach((x)=>{println(x)})
// arr01.foreach(println(_))
arr01.foreach(println)
//(4)增加元素(由于创建的是不可变数组,增加元素,其实是产生新的数组)
println(arr01)
val ints: Array[Int] = arr01 :+ 5
println(ints)
}
}
方式二:使用 apply 方法创建数组对象,并且在定义数组的时候直接赋初始值
代码示例:
object TestArray{
def main(args: Array[String]): Unit = {
var arr02 = Array(1, 3, "bobo")
println(arr02.length)
for (i <- arr02) {
println(i)
}
}
}
数组中的方法:
Scala
val arr = Array(1,3,5,7,9,2,6,4)
// 数组中的最大和最小值
val min: Int = arr.min
val max: Int = arr.max
// 首个元素
val head: Int = arr.head
//最后一个元素
val last: Int = arr.last
// 去除首个元素的子数组
val arr11: Array[Int] = arr.tail
// 将数组转换成List集合
val list: List[Int] = arr.toList
// 获取和后面数组中不同的元素
val diff: Array[Int] = arr.diff(Array(1,111,222))
//求数组元素的和
val sum: Int = arr.sum
// 数组的长度
arr.length
//修改指定位置的元素
arr.update(1,100)
// 取出数组中的前n个元素
val arr3: Array[Int] = arr.take(3)
// 后面添加一个元素 生成 新的数组
val arr2: Array[Int] = arr.:+(11)
// 后面添加一个数组
val res = arr ++ arr3
// 统计符合条件的个数
val i: Int = arr.count(_>2)
// 数组反转
arr.reverse
// 将不可变数组转换成可变数组
val buffer: mutable.Buffer[Int] = arr.toBuffer
可变数组--> ArrayBuffer
导入可变数组 : import scala.collection.mutable.ArrayBuffer ,可以修改元素的数组为可变数组
定义:
定义变长数组
val arr01 = ArrayBuffer[Any](3, 2, 5)
(1)[Any]存放任意数据类型
(2)(3, 2, 5)初始化好的三个元素
(3)ArrayBuffer 需要引入 scala.collection.mutable.ArrayBuffer
实例操作:
import scala.collection.mutable.ArrayBuffer
object TestArrayBuffer {
def main(args: Array[String]): Unit = {
//(1)创建并初始赋值可变数组
val arr01 = ArrayBuffer[Any](1, 2, 3)
//(2)遍历数组
for (i <- arr01) {
println(i)
}
println(arr01.length) // 3
println("arr01.hash=" + arr01.hashCode())
//(3)增加元素
//(3.1)追加数据
arr01.+=(4)
//(3.2)向数组最后追加数据
arr01.append(5,6)
//(3.3)向指定的位置插入数据
arr01.insert(0,7,8)
println("arr01.hash=" + arr01.hashCode())
//(4)修改元素
arr01(1) = 9 //修改第 2 个元素的值
println("--------------------------")
for (i <- arr01) {
println(i)
}
println(arr01.length) // 5
}
}
不可变 List
说明:
(1)List 默认为不可变集合
(2)创建一个 List(数据有顺序,可重复)
(3)遍历 List
(4)List 增加数据
(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
(6)取指定数据
(7)空集合 Nil
示例:
object TestList {
def main(args: Array[String]): Unit = {
//(1)List 默认为不可变集合
//(2)创建一个 List(数据有顺序,可重复)
val list: List[Int] = List(1,2,3,4,3)
//(7)空集合 Nil
val list5 = 1::2::3::4::Nil
//(4)List 增加数据
//(4.1)::的运算规则从右向左
//val list1 = 5::list
val list1 = 7::6::5::list
//(4.2)添加到第一个元素位置
val list2 = list.+:(5)
//(5)集合间合并:将一个整体拆成一个一个的个体,称为扁平化
val list3 = List(8,9)
//val list4 = list3::list1
val list4 = list3:::list1
//(6)取指定数据
println(list(0))
//(3)遍历 List
//list.foreach(println)
//list1.foreach(println)
//list3.foreach(println)
//list4.foreach(println)
list5.foreach(println)
}
}
// 不可变的List集合 数据不允许被修改
private val ls1 = List("SCALA", "HDP", "SPARK" , 12 , 34)
// 向Nil空队列中添加元素组成新的队列
val ls2 = "HIVE" :: "MYSQL" :: "HBASE" :: Nil
// Nil 和 List.empty[Nothing]是等价的
private val ll = List.empty[Nothing]
ls1(0) // 获取指定位置元素
// 添加一个元素生成新的List
val ls3 = ls1 :+ "PYTHON"
//合并两个集合 生成新的集合
val ls4 = ls1 ++ ls2
ls1.foreach(println)
// 获取前两个元素 组成新的List
ls1.take(2)
println(ls1.take(2))
println(ls1.takeRight(2)) // 从右边取数据
// 遍历每个元素 参数是一个偏函数
ls1.collect({ case x: Int => x })
// 查找匹配的元素 仅仅返回一个元素
ls1.find(x=>x.toString.startsWith("S"))
// 判断是否为null集合
ls1.isEmpty
// 转换成可变List集合
ls1.toBuffer
可变List-->ListBuffer
说明:
(1)创建一个可变集合 ListBuffer
(2)向集合中添加数据
(3)打印集合数据
代码实现:
import scala.collection.mutable.ListBuffer
object TestList {
def main(args: Array[String]): Unit = {
//(1)创建一个可变集合
val buffer = ListBuffer(1,2,3,4)
//(2)向集合中添加数据
buffer.+=(5)
buffer.append(6)
buffer.insert(1,2)
//(3)打印集合数据
buffer.foreach(println)
//(4)修改数据
buffer(1) = 6
buffer.update(1,7)
//(5)删除数据
buffer.-(5)
buffer.-=(5)
buffer.remove(5)
}
}
set
Set和list的最大区别在于Set中不可以存储重复数据 ,通常使用Set来实现元素的去重!!
Set集合也分为可变Set和不可变的Set,使用包名来区分可变和不可变,需要引用scala.collection.mutable.Set 包
不可变set
说明:
(1)Set 默认是不可变集合,数据无序
(2)数据不可重复
(3)遍历集合
代码示例:
object TestSet {
def main(args: Array[String]): Unit = {
//(1)Set 默认是不可变集合,数据无序
val set = Set(1,2,3,4,5,6)
//(2)数据不可重复
val set1 = Set(1,2,3,4,5,6,3)
//(3)遍历集合
for(x<-set1){
println(x)
}
}
}
可变mutable.Set
说明:
(1)创建可变集合 mutable.Set
(2)打印集合
(3)集合添加元素
(4)向集合中添加元素,返回一个新的 Set
(5)删除数据
代码示例:
object TestSet {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val set = mutable.Set(1,2,3,4,5,6)
//(3)集合添加元素
set += 8
//(4)向集合中添加元素,返回一个新的 Set
val ints = set.+(9)
println(ints)
println("set2=" + set)
//(5)删除数据
set-=(5)
//(2)打印集合
set.foreach(println)
println(set.mkString(","))
}
}
Map映射
Scala 中的 Map 和 Java 类似,也是一个散列表,它存储的内容也是键值对(key-value)映射,同样分为可变Map和不可变Map , 使用包名来区分是可变Map还是不可变Map
不可变Map
说明:
(1)创建不可变集合 Map
(2)循环打印
(3)访问数据
(4)如果 key 不存在,返回 0
代码示例:
object TestMap {
def main(args: Array[String]): Unit = {
// Map
//(1)创建不可变集合 Map
val map = Map( "a"->1, "b"->2, "c"->3 )
//(3)访问数据
for (elem <- map.keys) {
// 使用 get 访问 map 集合的数据,会返回特殊类型 Option(选项):
有值(Some),无值(None)
println(elem + "=" + map.get(elem).get)
}
//(4)如果 key 不存在,返回 0
println(map.get("d").getOrElse(0))
println(map.getOrElse("d", 0))
//(2)循环打印
map.foreach((kv)=>{println(kv)})
}
}
可变 Map
说明
(1)创建可变集合
(2)打印集合
(3)向集合增加数据
(4)删除数据
(5)修改数据
代码示例:
object TestMap {
def main(args: Array[String]): Unit = {
//(1)创建可变集合
val map = mutable.Map( "a"->1, "b"->2, "c"->3 )
//(3)向集合增加数据
map.+=("d"->4)
// 将数值 4 添加到集合,并把集合中原值 1 返回
val maybeInt: Option[Int] = map.put("a", 4)
println(maybeInt.getOrElse(0))
//(4)删除数据
map.-=("b", "c")
//(5)修改数据
map.update("d",5)
map("d") = 5
//(2)打印集合
map.foreach((kv)=>{println(kv)})
}
}
元组
元组也是可以理解为一个容器,可以存放各种相同或不同类型的数据。说的简单点,就是将多个无关的数据封装为一个整体,称为元组。
注意:元组中最大只能有 22 个元素
示例内容:
(1)声明元组的方式:(元素 1,元素 2,元素 3)
(2)访问元组
(3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为对偶
代码实现:
object TestTuple {
def main(args: Array[String]): Unit = {
//(1)声明元组的方式:(元素 1,元素 2,元素 3)
val tuple: (Int, String, Boolean) = (40,"bobo",true)
//(2)访问元组
//(2.1)通过元素的顺序进行访问,调用方式:_顺序号
println(tuple._1)
println(tuple._2)
println(tuple._3)
//(2.2)通过索引访问数据
println(tuple.productElement(0))
//(2.3)通过迭代器访问数据
for (elem <- tuple.productIterator) {
println(elem)
}
//(3)Map 中的键值对其实就是元组,只不过元组的元素个数为 2,称之为对偶
val map = Map("a"->1, "b"->2, "c"->3)
val map1 = Map(("a",1), ("b",2), ("c",3))
map.foreach(tuple=>{println(tuple._1 + "=" + tuple._2)})
}
}
Option
Option(选项)类型用来表示一个值是可选的(有值或无值)
Option[T] 是一个类型为 T 的可选值的容器: 如果值存在, Option[T] 就是一个 Some[T] ,如果不存在, Option[T] 就是对象 None 。
Option 有两个子类别,一个是 Some,一个是 None,当他回传 Some 的时候,代表这个函式成功地给了你一个 String,而你可以通过 get() 这个函式拿到那个 String,如果他返回的是 None,则代表没有字符串可以给你。
代码示例:
val myMap: Map[String, String] = Map("key1" -> "value")
val value1: Option[String] = myMap.get("key1")
val value2: Option[String] = myMap.get("key2")
println(value1) // Some("value1")
println(value2) // None
复习:
package com.doit.day01.day02
import scala.collection.mutable
import scala.collection.parallel.immutable
object ListTest {
def main(args: Array[String]): Unit = {
//1.定义一个长度为10的int类型的数组,里面装10个整数
// val arr: Array[Int] = new Array[Int](10)
// arr(0) = 1
// arr.update(0,1)
//第二种遍历方式
val arr: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 0)
//2.打印数组的长度
// println(arr.length)
//3.遍历数组
//方式1:for循环
// for (elem <- arr) {println(elem)}
//方式二,foreach
// arr.foreach(println)
//4.查看数组中的元素,显示成1--2--3...这样的形式
// println(arr.mkString("--"))
//5.找到数组中的最大值
// println(arr.max)
//6.找到数组中的最小值
// println(arr.min)
//数组中的第一个元素
// println(arr.head)
//数组中的最后一个元素
// println(arr.last)
//数组中除了第一个元素的后面所有的元素
// println(arr.tail.mkString(","))
//数组中的前三个元素和后三个元素
// println(arr.take(3).mkString(","))//前三个
// println(arr.takeRight(3).mkString(","))
//计算数组中大于4的个数
// println(arr.count(_ > 4))
//将不可变数组转换成可变数组
val buffer: mutable.Buffer[Int] = arr.toBuffer
//在可变数组中添加一个元素10
// buffer.append(10)
// buffer.+=(10)
// buffer += 10
//在指定索引为1的位置插入11,12两个元素
// buffer.insert(1,11,12)
//删除一个指定的元素元素
// buffer.-=(1)
// buffer -= 1
//删除指定索引位置的元素
// buffer.remove(1)
//数组的反转
// buffer.reverse
val list: List[Int] = List(1, 2, 3, 4, 5, 6, 7)
// val list1: List[Int] = 1 :: 2 :: 3 :: 4 :: 5 :: Nil
//遍历list
// for (elem <- list) {}
// list.foreach(println)
list.head
list.tail
list.last
list.max
list.min
list.take(2)
// list ::: arr.toList 正常都用不到
//val ints: List[Int] = list.::(1) 加在最前面
// Set(1,2,2,6,3,4)
// val ints: mutable.Set[Int] = mutable.Set(1, 2, 3, 4, 5, 6, 7)
// for (elem <- ints) {}
//添加一个元素
// ints.+=(1)
//删除索引位置的元素
// ints.remove(1)
//删除指定的元素
// ints.-=(1)
// val map: Map[String, Int] = Map("hadoop" -> 1, "hive" -> 2, "hbase" -> 3)
// val tail: Map[String, Int] = map.tail
// val head: (String, Int) = map.head
// val i: Int = map.getOrElse("hadoop", 0)
// map.get("he").get //用这个的时候得注意报错,正常情况下用getOrElse
val map: mutable.Map[String, Int] = mutable.Map("hadoop" -> 1, "hive" -> 2, "hbase" -> 3)
// map.update("hadoop", 111)
// map.+=("he"->11)
// map.put("haha",11 )
// map.remove("hadoop")
// for (elem <- map) {}
// for (elem <- map) {}
// val tuple = (1,"sy",false,1.0)
// val tuple2: (Int, String) = Tuple2(1, "hh")
}
}
集合中的常用方法
forEach
迭代遍历集合中的每个元素,对每个元素进行处理 ,但是没有返回值 ,常用于打印结果数据 !
val ls = List(1,3,5,7,9)
ls.foreach(println) // 打印每个元素
ls.foreach(println(_))// 打印每个元素
ls.foreach(x=>println(x*10)) // 每个元素乘以10 打印结果
ls.foreach(x=>print(x+" "))// 打印每个元素 空格隔开
map
适用于任意集合
注意Map集合的用法:map函数遍历每个元素处理返回原集合类型的新集合 , 也可以不返回数据列表,数组,Map中都有map函数 元组中没有map函数
val arr = Array[String]("JAVA", "C++", "SCALA")
val ls = List(1, 3, 5, 7, 9)
val set = Set(1, 3, 5, 7)
val mp = Map[String, Int]("ZSS" -> 100, "LSS" -> 99)
// map函数遍历每个元素处理返回原集合类型的新集合
val new_arr: Array[String] = arr.map(x => x)
val new_list: List[Int] = ls.map(x => x)
val new_set: Set[Int] = set.map(x => x)
// Map集合使用map函数
val new_Map1: Map[String, Int] = mp.map({ case v: (String, Int) => (v._1, v._2 * 10) })
val new_Map2: Map[String, Int] = mp.map(e => (e._1, e._2 + 100))
// map函数也可以不返回数据
ls.map(println(_))
filter和filterNot
适用于: 数组 List Map
filter返回符合自己条件的新的集合,filterNot返回不符合自己条件的新的集合
val ls: List[Int] = List.range(1,10)
ls.filter(x=>x%2==0)
val new_list: List[Int] = ls.filter(_ % 2 == 0)// _ 代表每个元素
new_list .foreach(x=>print(x+" ")) // 2 4 6 8
ls.filterNot(_%2!=1).foreach(x=>print(x+" ")) 1 3 5 7 9
每个元素进行过滤
val set = Set("spark" , "scala" , "c++" , "java")
val new_set: Set[String] = set.filter(_.startsWith("s"))
set.filter(_.length>3)
多条件filter进行条件过滤
val ls = "spark":: "scala" :: "c++"::"java"::1::2::12.34::Nil
// 过滤出String类型的和Double类型的数据
ls.filter{
case i:String => true
case i:Int=>false
case i:Double=>true
}
连续使用多次filter进行条件过滤
// 连续使用多次filter进行条件过滤
val map = Map[String,Int](("zss" ,91),("zww",89),("zzx",92) , ("ww",23))
map.filter(_._1.startsWith("z")).filter(_._2>90)
collect
常用于: Array List Map
collect函数也可以遍历集合中的每个元素处理返回新的集合
def map[B](f: (A) ⇒ B): List[B]
def collect[B](pf: PartialFunction[A, B]): List[B]
主要支持偏函数
val ls = List(1,2,3,4,"hello")
// 主要支持偏函数
val new_list: List[Int] = ls.collect({case i:Int=>i*10})
new_list.foreach(x=>print(x+" "))//10 20 30 40
// collect实现filter和map特性
list.collect({ case i: Int => i * 10
case i: String => i.toUpperCase
}).foreach(println)
val new_list2: List[Int] = ls.map({case x:Int=>x*10})
new_list2.foreach(x=>print(x+" "))// 错误 hello (of class java.lang.String)
因为collect支持偏函数 , 所以我们可以使用collect实现filter和map的特性!!!
Scala
val res: List[Int] = List(1, 2, 3, 4, 5, 6,"hello").collect({case i:Int if i%2==0=>i*10})
res.foreach(println) // 40 60
min和max
适用于:数组 List Map
• 数组
val arr = Array(1,2,345,67,5)
arr.min
arr.max
arr.sum
• List
val ls = List(1,2,345,67,5)
ls.min
ls.max
ls.sum
• Set
val set = Set(1,2,345,67,5)
set.min
set.max
set.sum
• map 默认按照key排序获取最大和最小数据
val map = Map[String,Int]("a"->10, "b"->99 , "c"->88)
// map默认按照key排序获取最大和最小数据
map.min //(a,10)
map.max //(c,88)
minBy和maxBy
适用于: 数组 List Map
集合中的min和max可以获取任意集合中的最小和最大值 ,但是如果集合中存储的是用户自定义的类 , 或者是按照Map集合中的key, value规则排序的话就需要用户指定排序规则
• map按照value取最大最小
val map = Map[String,Int]("a"->10, "b"->99 , "c"->88)
// map默认按照key排序获取最大和最小数据
// 指定map排序 按照value排序
map.maxBy(x=>x._2) //(b,99)
map.minBy(x=>x._2) //(a,10)
• 集合中存储的是用户自定义的类型
class User(val name:String ,val age:Int) {}
隐式转换
implicit def ordersUser(user:User)={
new Ordered[User] {
override def compare(that: User) = {
user.age.compareTo(that.age)
}
}
}
val ls = List(new User("zs",22),new User("ww",18) ,new User("tq",34))
println(ls.max.name)
println(ls.min.name)
println(ls.maxBy(x => x.age).name)
sum
适用于 数组 List Set
求集合中的所有元素的和 ,下面三种集合类型常用
val arr = Array(1,2,345,67,5)
arr.sum
val ls = List(1,2,345,67,5)
ls.sum
val set = Set(1,2,345,67,5)
set.sum
count
适用于 数组 List Map
def count(p: ((A, B)) => Boolean): Int
计算满足指定条件的集合元素数量
val arr = Array(1,2,345,67,5)
arr.count(_>5) // array list set 统用
val ls = List("hello" , "hi" , "heihei" , "tom")
ls.count(_.startsWith("h"))
ls.count(_.equals("hello"))
ls.count(_ == "hello")
// 忽略大小写
ls.count(_.equalsIgnoreCase("HELLO"))
// 统计符合条件的map元素的数量
val map = Map[String,Int]("a"->10,"ab"->10, "b"->99 , "c"->88)
map.count(x=>x._1.startsWith("a"))
map.count(_._2>10)
find
适用于 数组 List Map
查找符合要求的元素 , 匹配到就反回数据 ,最多只返回一个
Option中的数据要么是Some(T) 要么是None标识没有找到
val arr = Array(1,2,345,67,5)
val e: Option[Int] = arr.find(x=>x>1)
val ls = List("hello" , "hi" , "heihei" , "tom")
val res: Option[String] = ls.find(_.contains("a"))
if(res.isDefined){
println(res) //Some(hello)
println(res.get) //hello
}
val map = Map[String,Int]("a"->10,"ab"->10, "b"->99 , "c"->88)
val res_map: Option[(String, Int)] = map.find(x=>x._2>20)
if(res_map.isEmpty){
"没有匹配到内容"
}else{
// 打印数据
println(res_map.get)
}
flatten
适用于 数组 List
压平 将一个集合展开 组成一个新的集合
val arr = Array(1,2,345,67,5.23)
//val res1: Array[Nothing] = arr.flatten I数值了类型的无法压平
val ls = List("hello" , "hi" , "heihei" , "tom")
val res2: Seq[Char] = ls.flatten // 压成单个字符 因为字符串属于序列集合的一种
val map = Map[String,Int]("a"->10,"ab"->10, "b"->99 , "c"->88)
// map无法直接压平
//val flatten: immutable.Iterable[Nothing] = map.flatten
// 压平存储Map集合的list 获取Map中每个元素
val ls1 = List[Map[String,Int]](Map[String,Int]("a"->10,"ab"->10) , Map[String,Int]("jim"->100,"cat"->99))
ls1.flatten // List((a,10), (ab,10), (jim,100), (cat,99))
val res: List[Int] = List(Array(1,2,3),Array(4,5,6)).flatten
// 错误 注意压平的数据的类型
val res4 = List(Array(1,2,3),Array("hel",5,6)).flatten
flatMap
适用于 数组 List
map+flatten方法的组合 ,先遍历集合中的每个元素 , 再按照指定的规则压平, 返回压平后的新的集合
val ls = List("today is my first day of my life" , "so I feel so happy")
// map处理每个元素 就是处理每句话
ls.map(x=>println(x))
// 获取集合中的每个元素 获取两句话 然后再扁平成字符
ls.flatMap(x=>x)
// 指定扁平化的规则 按照空格压平 压平的规则
ls.flatMap(x=>x.split(" ")).foreach(println) // 获取到每个单词
// 读取外部文件
val bs: BufferedSource = Source.fromFile("d://word.txt")
// 读取所有的数据行
val lines: Iterator[String] = bs.getLines()
// m遍历每行数据按照 \s+ 切割返回一个新的迭代器
val words: Iterator[String] = lines.flatMap(_.split("\s+"))
// 遍历迭代器 获取每个单词
words.foreach(println)
// 读取外部文件
val bs2: BufferedSource = Source.fromFile("d://word.txt")
// 获取所有的行数据
val lines2: Iterator[String] = bs2.getLines()
// 处理每行数据 切割单词后 每行返回一个数组 将所有的数组封装在迭代器中
val arrs: Iterator[Array[String]] = lines2.map(_.split("\s+"))
mapValues
适用于 Map
mapValues方法只对Map集合的value做处理!
sorted
适用于 数组 List Map
sorted 使用域简单的数字, 字符串等排序规则简答的集合进行排序 , 如果需要定制化排序建议使用sortBy 和 sortWith函数
List对数值
val list = List (1, 34 , 32 , 12 , 20 ,44 ,27)
// 返回排好序的list集合 默认从小到达排序
val sorted: List[Int] = list.sorted
对Array字符串
Scala
val arr = Array("jim" , "cat" , "jong" , "huba")
// 字符串默认按照先后排序
val sorted_arr: Array[String] = arr.sorted
对map
Scala
val map = Map[String , Int]("aeiqi"->4 , "qiaozhi"->2 , "baji"->34)
// map集合也没有sorted 函数 只有转换成List或者Array集合 默认按照key字典先后排序
val sorted_map: Seq[(String, Int)] = map.toList.sorted
sorted_map.foreach(println)
sortBy和sortWith
适用于 数组 List Map
var arr = Array(1, 11, 23, 45, 8, 56)
val arr1 = arr.sortBy(x => x) //ArraySeq(1, 8, 11, 23, 45, 56)
//按照数据倒序排列
val arr2 = arr.sortBy(x => -x) //(56, 45, 23, 11, 8, 1)
// 按照字典顺序排序
val arr3 = arr.sortBy(x => x.toString) //ArraySeq(1, 11, 23, 45, 56, 8)
// x 前面的元素 y 后面的元素
arr.sortWith((x, y) => x > y)
arr.sortWith((x, y) => x < y)
var list = List("hello", "cat", "happy", "feel")
// 字典顺序
list.sortBy(x => x)
// 执行排序
list.sortWith((x, y) => x > y)
list.sortWith((x, y) => x < y)
val map = Map("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
map.toList.sortBy(x => x._1) //List((baji,12), (jong,3), (peiqi,5))
map.toList.sortBy(x => x._2) //List((jong,3), (peiqi,5), (baji,12))
// 指定key排序
map.toArray.sortWith((x,y)=>x._1>y._1)
map.toArray.sortWith((x,y)=>x._1<y._1)
//指定value排序规则
map.toArray.sortWith((x,y)=>x._2>y._2)
map.toArray.sortWith((x,y)=>x._2<y._2)
自定义类型在集合中的排序
val u1 = new User("wuji", 34)
val u2 = new User("zhiruo", 24)
val u3 = new User("zhoamin", 44)
val u4 = new User("cuishan", 64)
var arr = Array(u1, u2, u3, u4)
// 按照姓名字典排序
arr.sortBy(user => user.name)
//年龄小到大
arr.sortBy(user => user.age)
//数值类型的排序可以直接使用- 来倒序排列 年龄大到小
arr.sortBy(user => -user.age)
// 年龄大到小
arr.sortWith((user1, user2) => user1.age > user2.age)
// 年龄小到大
arr.sortWith((user1, user2) => user1.age < user2.age)
// 姓名字典升序
arr.sortWith((user1, user2) => user1.name < user2.name)
//姓名字典降序
arr.sortWith((user1, user2) => user1.name > user2.name)
grouped
将集合中的元素按照指定的个数进行分组
val list1 = List(1,2,3,4,5,6,7,8,9)
val list2 = List("scala" , "is" , "option" , "fucntion")
val map = Map[String,Int]("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
// 两个元素分成一组 ,9个元素总共分成5组
val res: Iterator[List[Int]] = list1.grouped(2)
var i = 0
// 遍历每个元素
res.foreach(list=>{
i+=1
list.foreach(x=>println(x+"----"+i)) // 打印每个元素和它所对应的组
})
// 将map集合按照个数进行分组
val res2: Iterator[Map[String, Int]] = map.grouped(2)
res2.foreach(i=>i.foreach(x=>println((x._1,x._2))))
groupBy
将集合中的数据按照指定的规则进行分组
序列集合
val list1 = List(1,2,3,4,5,6,7,8,9)
val list2 = List("scala" , "is" , "option" , "fucntion")
// 对序列数据进行分组
val res1: Map[Boolean, List[Int]] = list1.groupBy(x=>x>3) //HashMap(false -> List(1, 2, 3), true -> List(4, 5, 6, 7, 8, 9))
val res2: Map[Boolean, List[Int]] = list1.groupBy(x=>x%2==0)//HashMap(false -> List(1, 3, 5, 7, 9), true -> List(2, 4, 6, 8))
list2.groupBy(x=>x.hashCode%2==0)
//HashMap(false -> List(is, option, fucntion), true -> List(scala))
val res: Map[Boolean, List[String]] = list2.groupBy(x=>x.startsWith("s"))
键值映射集合分组
val map = Map[String,Int]("peiqi" -> 5, "jong" -> 3, "baji" -> 12)
val arr = Array(("cat",21),("lucy",33),("book",22),("jack",34))
// 按照key和value的内容分组
println(map.groupBy(mp => mp._1))
println(map.groupBy(mp => mp._2))
// 根据key 或者 value 分成两组 满足条件的和不满足条件的
println(map.groupBy(mp => mp._1.hashCode%2==0))
println(map.groupBy(mp => mp._2>2))
// 对偶元组集合 和map的分组方式是一样的
arr.groupBy(arr=>arr._1)
arr.groupBy(arr=>arr._2)
reduce
底层调用的是reduceLeft , 从左边开始运算元素
val list = List(1,3,5,7,9)
// 每个元素累加 从左到右相加
val res1: Int = list.reduce(_+_) // 25
//1-3)-5)-7)-9
val res2: Int = list.reduce(_ - _) // -23
val arr = Array("haha", "heihei", "hehe")
// x 前面的元素 y 后面的元素 实现集合中字符串的拼接
val res3: String = arr.reduce((x, y) => x + " " + y) //haha heihei hehe
// 键值对元素的
val map = Map(("shaolin",88),("emei", 77),("wudang",99))
//(shaolin emei wudang,264) key value分别做归约操作
val res4: (String, Int) = map.reduce((m1,m2)=>(m1._1+" "+m2._1 , m1._2+ m2._2))
reduceLeft和reduceRight
val list = List(1, 3, 5, 7, 9)
val arr = Array("a", "b", "c","d","e")
val map = Map(("shaolin",88),("emei", 77),("wudang",99))
// 执行顺序是 1+3)+5)+7)+9
val res1: Int = list.reduceLeft(_+_)
// 1-3)-5)-7)-9
val res01: Int = list.reduceLeft(_-_)
val res2: String = arr.reduceLeft((a1, a2)=>a1+","+a2)
val res3: (String, Int) = map.reduceLeft((m1,m2)=>(m1._1+" "+m2._1 , m1._2+ m2._2))
println(res1) //25
println(res2) //a,b,c,d,e
println(res3)//(shaolin emei wudang,264)
val res11: Int = list.reduceRight(_+_) // 25
// 执行顺序是 a,(b,(c,(d,e))) a2 右边的最后一个元素
val res12: String = arr.reduceRight((a1, a2)=>a1+","+a2)//a,b,c,d,e
val res13: (String, Int) = map.reduceRight((m1,m2)=>(m1._1+" "+m2._1 , m1._2+ m2._2))//(shaolin emei wudang,264)
// 5-(7-9)-->5-(7-9)-->3-(5-(7-9))-->1-(3-(5-(7-9)))
val res14: Int = list.reduceRight(_-_)
println(res14) // 5
println(res11) //25
println(res12) //a,b,c,d,e
println(res13)//(shaolin emei wudang,264)
// 字符串的拼接
arr.reduce(_ ++ _)
// 字符串的拼接
println(arr.reduce(_ ++"."++ _))
fold,foldLeft 和foldRight
归约操作类似于reduce函数 ,但是fold函数中多出来一个初始值
val arr = Array("tom" , "cat" , "jim" , "rose")
// 遍历集合中的每个元素进行拼接 比reduce函数多出一个初始值
val res = arr.fold("hello")(_+" "+_)
val ls = List(1,3,5,7)
// 100+1)+3)+5)+7 底层调用的是 foldLeft
val res2 = ls.fold(100)(_+_) // 116
ls.foldLeft(100)(_+_) // 116
从右边开始运算 默认的值先参与运算进来
// 7-10)-->5-(-3)-->3-8 -->1-(-5)
val res01: Int = ls.foldRight(10)(_-_) //6
交集差集并集
val arr1 = Array(1, 3, 5, 7, 0)
val arr2 = Array(5, 7, 8, 9)
val res1: Array[Int] = arr1.intersect(arr2) // 交集 5 7
val res2: Array[Int] = arr1.diff(arr2) // 差集 1 3
// 单纯的合并两个元素中的数据
val res3: mutable.ArraySeq[Int] = arr1.union(arr2) // 1,3,5,7 ,5,7,8,9
// 去除重复数据
val res4: mutable.ArraySeq[Int] = res3.distinct //,3,5,7,8,9
distinct和distinctBy
去除集合中的重复的元素 ,可以去除简单类型的数据, 也可以除去自定义的类型(底层依然是hashcode和equals)
val arr1 = Array("a", "a","ab","cat" ,"hellocat" ,"hicat")
val newarr: Array[String] = arr1.distinct
newarr.foreach(println)
条件去重
val arr1 = Array(new User("ls",21),new User("ls",22),new User("zss",21))
// 去除重名的重复数据
val res: Array[User] = arr1.distinctBy(x=>x.age)
res.foreach(x=> println(x.name))
zip
实现拉链式拼接, 只要操作的集合是迭代集合就可以拼接
val list1 = List("a" , "b" , "c" , "d")
val arr1 = Array(1,2,3,4)
val map = Map[String,Int]("aa"->11,"cc"->22,"dd"->33)
// 以两个迭代集合中少的一方为基准对偶拼接List((a,1), (b,2), (c,3))
val res: List[(String, Int)] = list1.zip(arr1)
//ArraySeq((1,(aa,11)), (2,(cc,22)), (3,(dd,33)))
val res2: Array[(Int, (String, Int))] = arr1.zip(map)
zipWithIndex
简单理解为 遍历集合中的每个元素 , 将每个元素打上对应的索引值 , 组成元组(element , index) 返回新的集合 !
val list1 = List("a" , "b" , "c" , "d")
val arr1 = Array(1,2,3,4)
val map = Map[String,Int]("aa"->11,"cc"->22,"dd"->33)
// List(((a,1),0), ((b,2),1), ((c,3),2), ((d,4),3))
list1.zip(arr1).zipWithIndex
//List((a,0), (b,1), (c,2), (d,3))
list1.zipWithIndex
scan
一个初始值开始,从左向右遍历每个元素,进行积累的op操作
val arr = Array("cat" , "jim" , "tom")
// ArraySeq(hello, hello cat, hello cat jim, hello cat jim tom)
arr.scan("hello" )(_ +" "+ _)
val nums = List(1,2,3)
// List(10,10+1,10+1+2,10+1+2+3) = List(10,11,13,16)
val result = nums.scan(10)(_+_)
nums.foldLeft(10)(_+_) // 16
mkString
将集合中的每个元素拼接成字符串
val arr = Array("a", "b", "c")
val str = arr.mkString
arr.mkString(" ")
arr.reduce(_+_)
arr.reduce(_ + " " + _)
slice,sliding
slice(from: Int, until: Int): List[A] 提取列表中从位置from到位置until(不含该位置)的元素列表, 起始位置角标从0开始;
• slice
val arr = Array("a", "b", "c" ,"d","e","f")
arr.slice(0 ,2) // res0: Array[String] = ArraySeq(a, b)
• sliding
sliding(size: Int, step: Int): Iterator[List[A]] 将列表按照固定大小size进行分组,步进为step,step默认为1,返回结果为迭代器;
val nums = List(1,1,2,2,3,3,4,4)
// 参数一:子集的大小 参数二:步进
val res: Iterator[List[Int]] = nums.sliding(2,2)
res.toList // List(List(1, 1), List(2, 2), List(3, 3), List(4, 4))
take,takeRight,takeWhile
• take 默认从左边开始取
val arr = Array("a", "b", "c" ,"d","e","f")
// 从左边获取三个元素,组成新的数组集合
arr.take(3)
• takeRight 默认从右边开始取
val nums = List(1,1,1,1,4,4,4,4)
val right = nums.takeRight(4) // List(4,4,4,4)
• takeWhile
// 小于4 终止
nums.takeWhile(_ < 4)
val names = Array ("cat", "com","jim" , "scala" ,"spark")
// 从左到右遍历符合遇到不符合条件的终止,储存在新的集合中
names.takeWhile(_.startsWith("c"))
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


