
Python内置模块CSV
使用with可以不用close文件
读取CSV文件
import csv
# 读取csv方式1
csvFile = open('csvData.csv', 'r')
reader = csv.reader(csvFile) # 返回迭代类型
data = []
for item in reader:
print(item)
data.append(item)
print(data)
csvFile.close()
import csv
# 读取csv方式2
data=[]
with open('csvData.csv', 'r',encoding='utf-8') as csvfile:
reader2 = csv.reader(csvfile) # 返回迭代类型
for item2 in reader2:
print(item2)
data.append(item2)
print(data)
import csv
# 读取csv方式2
data=[]
with open('csvData.csv', 'r',encoding='utf-8') as csvfile:
reader2 = csv.reader(csvfile) # 返回迭代类型
for item2 in reader2:
print(item2)
data.append(item2)
print(data)
# 从列表写入csv文件
csvFile2=open('csvData2.csv', 'w',encoding='utf-8',newline='')
writer=csv.writer(csvFile2)
m=len(data)
for i in range(m):
writer.writerow(data[i])
csvFile2.close()
使用Excel进行数据驱动测试
环境准备
- 安装openpyxl
pip install openpyxl
- 测试数据准备
新建“测试数据.xlsx”,工作表名为“搜索数据表”的Excel文件内容如下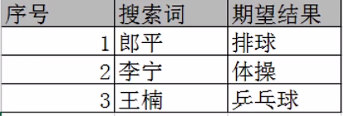
'''
Excel工具类
'''
from openpyxl import load_workbook
class ParseExcel(object):
def __init__(self, excelPath, sheetName):
# 读excel文件
self.wb = load_workbook(excelPath)
# 通过工作表名称获取一个工作表对象
self.sheet = self.wb[sheetName]
# 获取工作表中存在数据的区域的最大行号
self.maxRowNum = self.sheet.max_row
def getDataFromSheet(self):
# 存放从工作表中读取出来的数据
dataList = []
'''
1.因为工作表中的第一行是标题行,所以需要去掉
2.遍历工作表中数据区域的每一行
3.将每行各个单元的数据取出存于列表tmpList中
4.再将存放一行数据的列表添加到最终数据列表dataList中
'''
for line in self.sheet.rows:
tmpList = []
tmpList.append(line[1].value)
tmpList.append(line[2].value)
dataList.append(tmpList)
print(dataList[1:])
return dataList[1:]
if __name__ == '__main__':
excelPath = r'测试数据.xlsx'
sheetName = '搜索数据表'
excel = ParseExcel(excelPath=excelPath, sheetName=sheetName)
print(excel.getDataFromSheet())
import unittest, time, logging, ddt
import traceback # 异常类
from selenium import webdriver
from ExcelUtil import ParseExcel
from selenium.common.exceptions import NoSuchElementException
# 初始化日志对象
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(filename)s [line:%(lineno)d] %(name)s %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='d://report.log',
filemode='w' # 是否追加写入日志
)
excelPath = r'测试数据.xlsx'
sheetName = '搜索数据表'
excel = ParseExcel(excelPath=excelPath, sheetName=sheetName)
print(excel.getDataFromSheet())
@ddt.ddt
class TestDemo(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
@ddt.data(*excel.getDataFromSheet())
def test_dataDriverByFile(self, data):
# 强制将data改变为元组类型
print('tuple(data)', tuple(data))
testData, expectData = tuple(data)
print('testData', testData)
print('expectData', expectData)
time.sleep(3)
url = 'https://www.baidu.com'
self.driver.get(url)
self.driver.maximize_window()
self.driver.implicitly_wait(10)
try:
self.driver.find_element_by_id('kw').send_keys(testData)
self.driver.find_element_by_id('su').click()
time.sleep(2)
self.assertTrue(expectData in self.driver.page_source)
except NoSuchElementException:
# traceback.format_exc()是把异常栈以字符串的形式返回
logging.error('查找的页面元素不存在,异常信息:' + str(traceback.format_exc()))
except AssertionError as e:
logging.info("搜索-'%s',期望-'%s',-失败" % (testData, expectData))
except Exception as e:
logging.info('未知错误,错误信息:' + str(traceback.format_exc()))
else:
logging.info("搜索-'%s',期望-'%s',-通过" % (testData, expectData))
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main
内容来源于网络如有侵权请私信删除
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!
 客服
客服


