
在数据分析过程中,一般提取数据库里面的数据时候,拿着表格数据反复思索,希望能够根据自己所想立马生成一张数据可视化的图表来更直观的呈现数据。

但想要进行数据可视化的时候,往往需要调用很多的库与函数,还需要数据转换以及大量的代码处理编写。这都是十分繁琐的工作,确实只为了数据可视化我们不需要实现数据可视化的工程编程,这都是数据分析师以及拥有专业的报表工具来做的事情,日常分析的话我们根据自己的需求直接进行快速出图即可,而Pandas正好就带有这个功能,当然还是依赖matplotlib库的,只不过将代码压缩更容易实现。下面就让我们来了解一下如何快速出图。
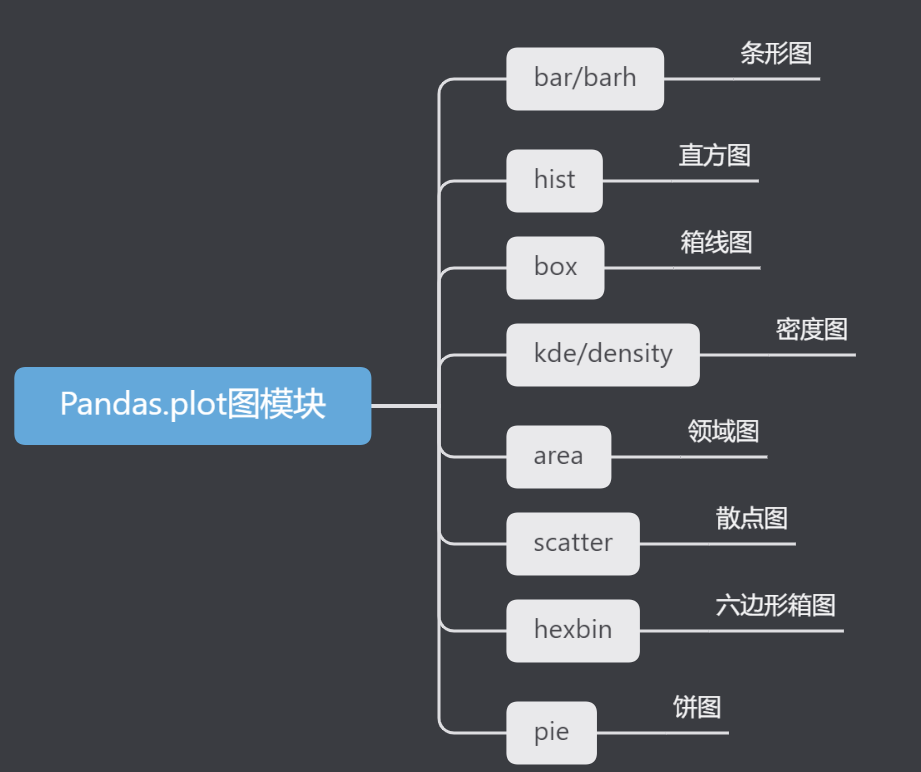
Series和DataFrame上的plot方法只是plt.plot()的简单包装,这里我们用一段实际数据来进行可视化展示:

这是一段真实地铁通行量特征数据,我们用此数据进行展示:
df_flow['客流量'].plot() # 小伙伴们在学习Python的过程中,有时候不知道怎么学,从哪里开始学。掌握了一些基本的知识或者做了一些案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。 # 那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及源代码! # 我都放在这个裙了 279199867 大家自取即可~
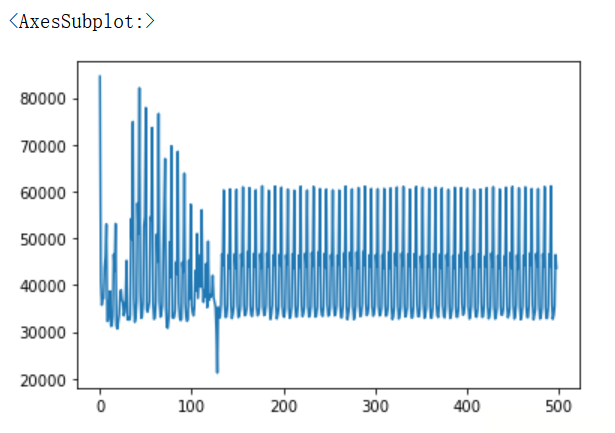
如果索引由日期组成,则调用gcf().autofmt_xdate()方法可以很好地格式化x轴。
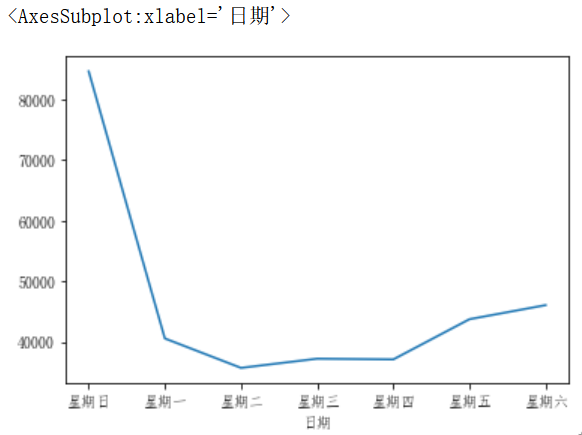
在DataFrame上,plot()可以方便地用标签绘制所有列:
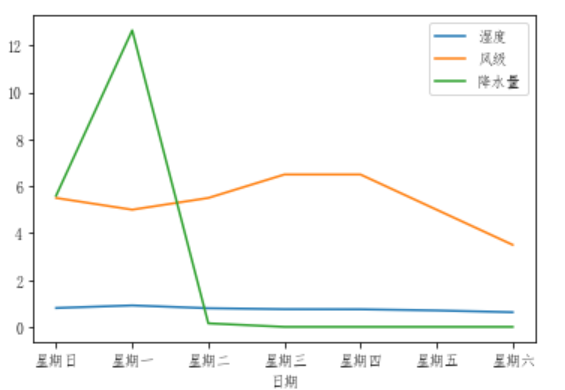
df_flow_mark[['湿度','风级','降水量']].plot()
可以使用plot()中的x和y关键字绘制一列与另一列的对比,比如我们想要使用星期六的客流量和星期日的客流量作对比:
df_flow_7=df_flow[df_flow['日期']=='星期日'].iloc[:7,:] df_flow_7.rename(columns={'客流量':'星期日客流量'},inplace=True) df_flow_6=df_flow[df_flow['日期']=='星期六'].iloc[:7,:] df_flow_6.rename(columns={'客流量':'星期六客流量'},inplace=True) df_compare=pd.concat([columns_convert_df(df_flow_7['星期日客流量']),columns_convert_df(df_flow_6['星期六客流量'])],axis=1) df_compare.plot(x='星期日客流量',y='星期六客流量')

根据Pandas包装后的kind关键字我们梳理一下底图种类:
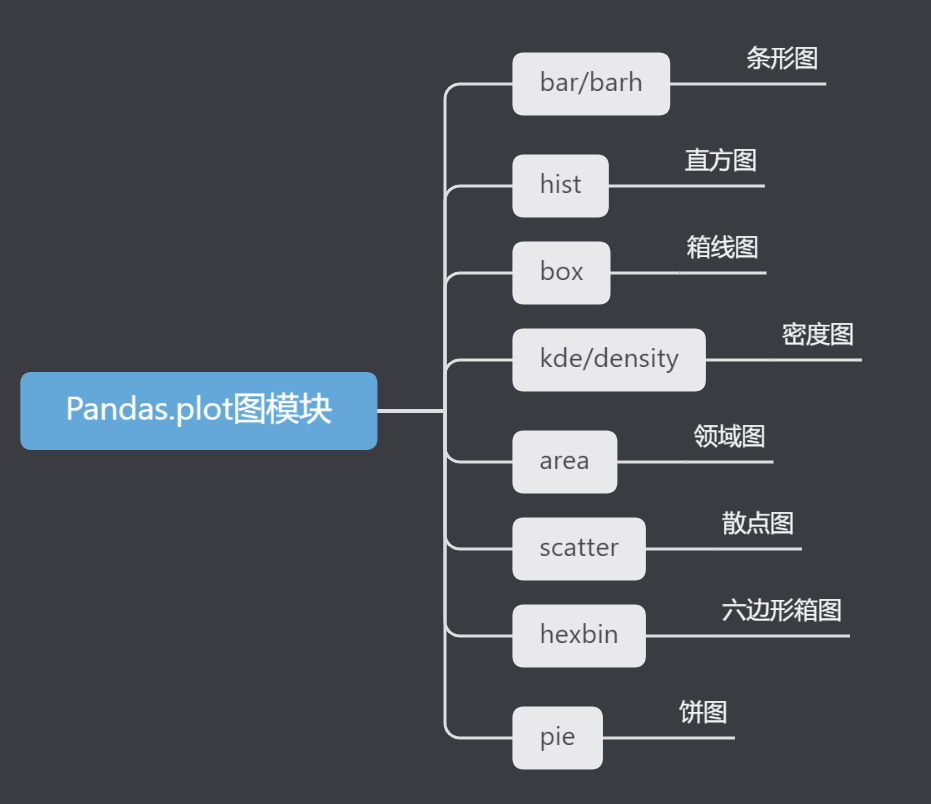
也可以使用DataFrame.plot方法创建这些其他绘图而不是提供kind关键字参数。这使得更容易发现绘图方法及其使用的特定参数:
df.plot.area df.plot.barh df.plot.density df.plot.hist df.plot.line df.plot.scatter
df.plot.bar df.plot.box df.plot.hexbin df.plot.kde df.plot.pie
除了这些类型,还有DataFrame.hist()和DataFrame.boxplot()方法,它们使用单独的接口。
最后,pandas中有几个绘图功能。以Series或DataFrame作为参数的绘图。其中包括:
-
Scatter Matrix
-
Andrews Curves
-
Parallel Coordinates
-
Lag Plot
-
Autocorrelation Plot
-
Bootstrap Plot
-
RadViz
分别是:
- 散射矩阵
- 安德鲁斯曲线
- 平行坐标
- 滞后图
- 自相关图
- 引导图
- 拉德维兹图
绘图也可以用错误条或表格进行装饰。
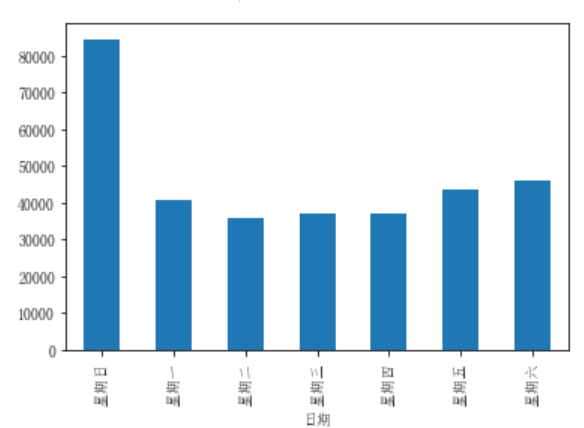
df_flow_mark['客流量'].plot(kind='bar') df_flow_mark['客流量'].plot.bar()
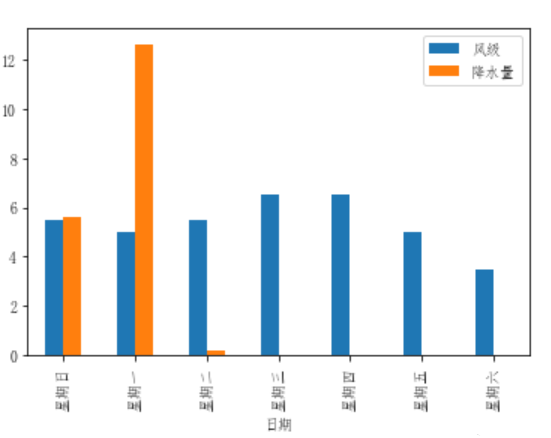
多个标签图表也可以一齐绘出:
df_flow_mark[['风级','降水量']].plot.bar()
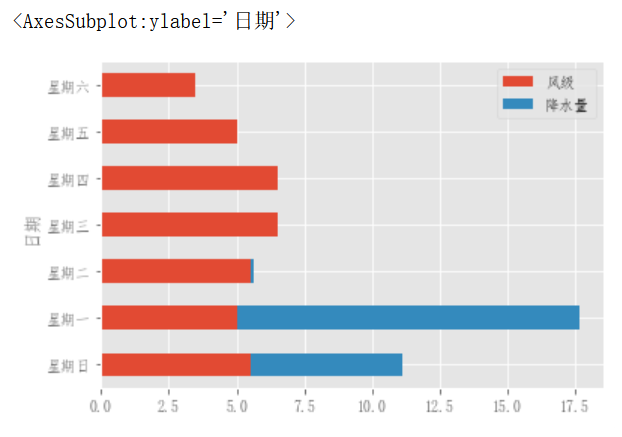
要生成堆叠条形图,传递stacked=True:
df_flow_mark[['风级','降水量']].plot.bar(stacked=True)

长久看这个maatplotlib的默认地图有点疲劳了,我这里换个主题,还是一样的效果不碍事。
要获得水平条形图可以使用barh方法:
df_flow_mark[['风级','降水量']].plot.barh(stacked=True)
可以使用DataFrame.plo.hist()和Series.plot.hist()方法绘制直方图.
df4 = pd.DataFrame( { "a": np.random.randn(1000) + 1, "b": np.random.randn(1000), "c": np.random.randn(1000) - 1, }, columns=["a", "b", "c"], ) plt.figure(); df4.plot.hist(alpha=0.5)
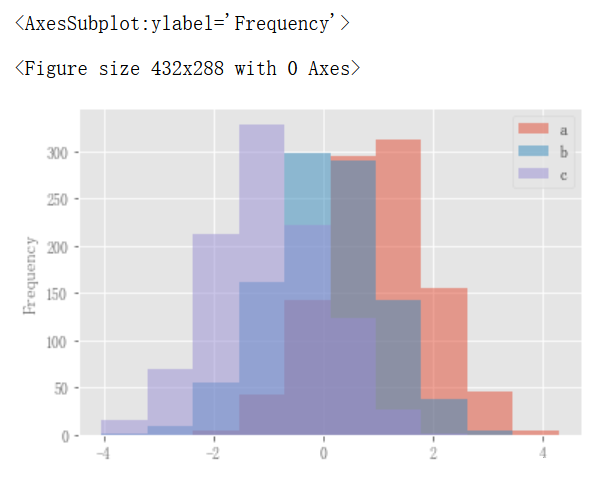
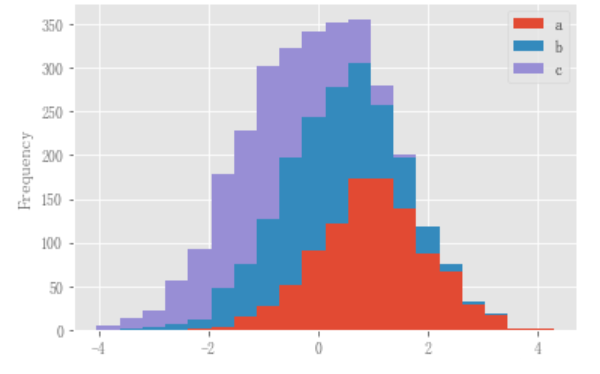
直方图可以使用stacked=True进行叠加。可以使用bins关键字更改bin大小。
df4.plot.hist(stacked=True, bins=20);
可以传递matplotlib hist支持的其他关键字。例如,水平和累积直方图可以通过orientation='horizontal’和cumulative=True绘制。
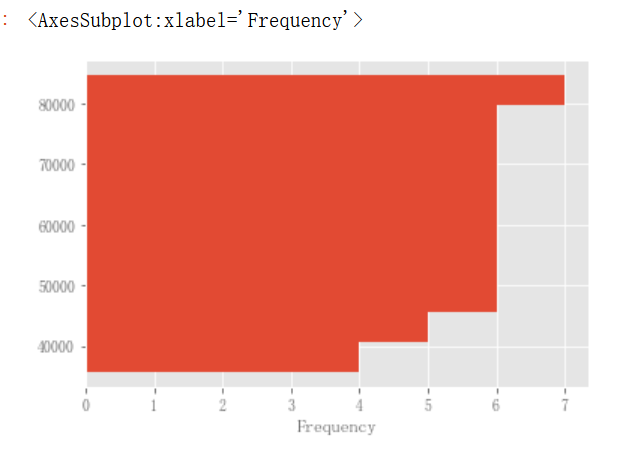
有关详细信息,可以参阅hist方法和matplotlib hist文档。
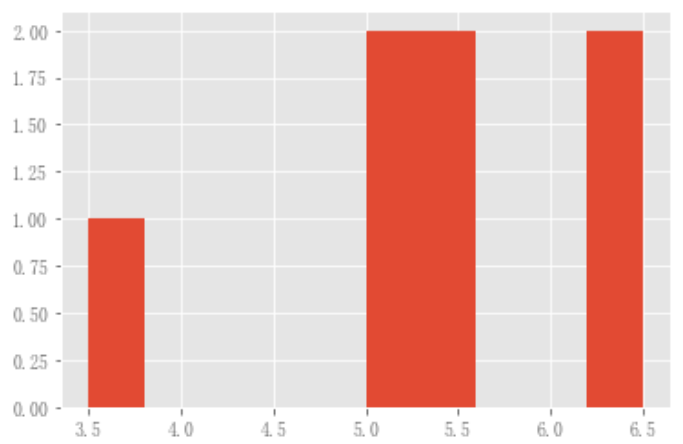
现有接口DataFrame.hist,但仍然可以使用hist绘制直方图
plt.figure(); df_flow_mark['风级'].hist();
DataFrame.hist()可以在多个子地块上绘制列的直方图:
plt.figure(); df_flow_mark[['风级','降水量']].diff().hist(color="k", alpha=0.5, bins=50);
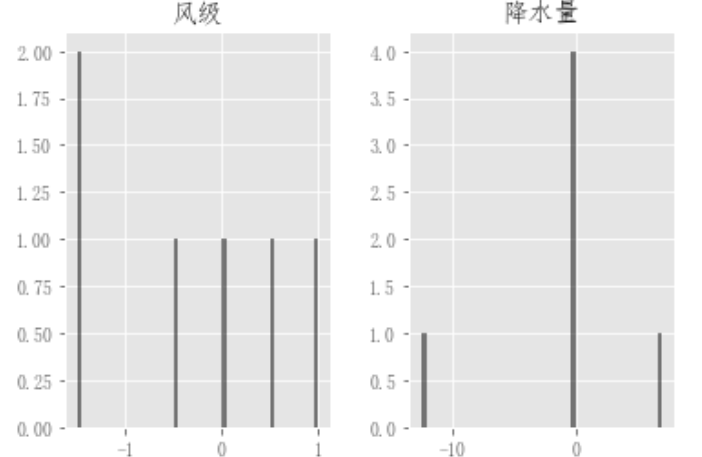
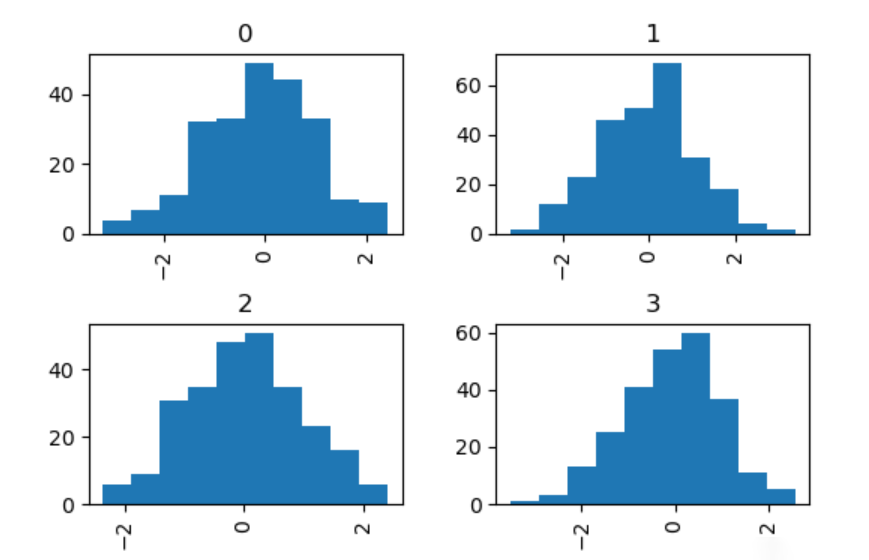
可以指定by关键字来绘制分组直方图:
data = pd.Series(np.random.randn(1000))
data.hist(by=np.random.randint(0, 4, 1000), figsize=(6, 4));
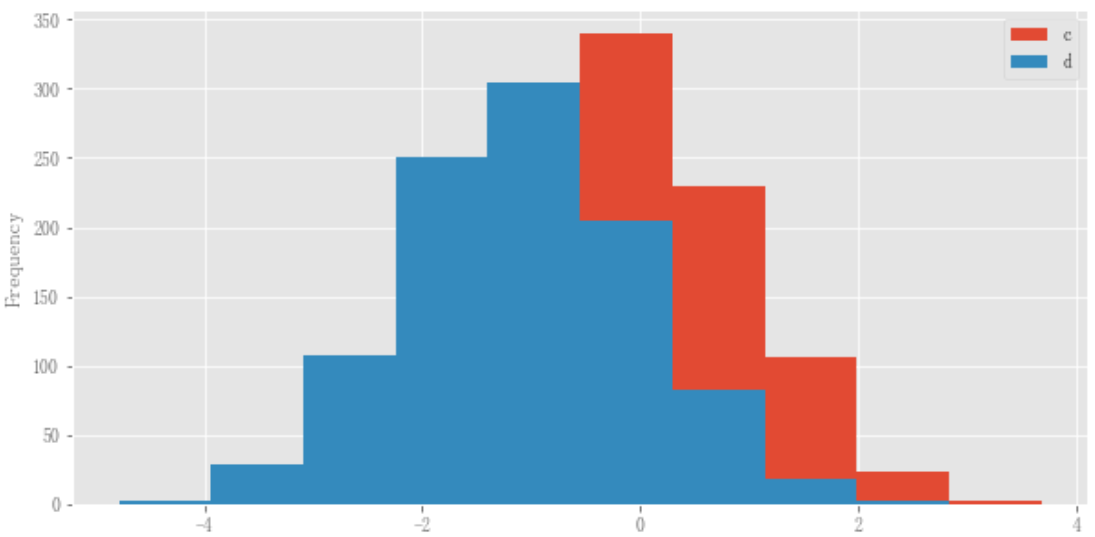
此外,还可以在DataFrame.plot.hist()中指定by关键字:
data = pd.DataFrame( { "a": np.random.choice(["x", "y", "z"], 1000), "b": np.random.choice(["e", "f", "g"], 1000), "c": np.random.randn(1000), "d": np.random.randn(1000) - 1 } ) data.plot.hist(by=["a", "b"], figsize=(10, 5));
调用
- Series.plot.box()
- DataFrame.plot.box()
- DataFrame.boxplot()
可以绘制箱线图可视化每个列中的值分布。
df_flow_mark[['风级','降水量']].plot.box()

可以通过传递color关键字对Boxplot进行着色。你可以传递一个字典dict,key关键字为boxes、whiskers,medians,caps。如果dict中缺少一些键,则会为相应的使用默认颜色。此外,箱线图还有sym关键字来指定传单样式。
color = { "boxes": "DarkGreen", "whiskers": "DarkOrange", "medians": "DarkBlue", "caps": "Gray", } df_flow_mark[['风级','降水量']].plot.box(color=color, sym="r+")
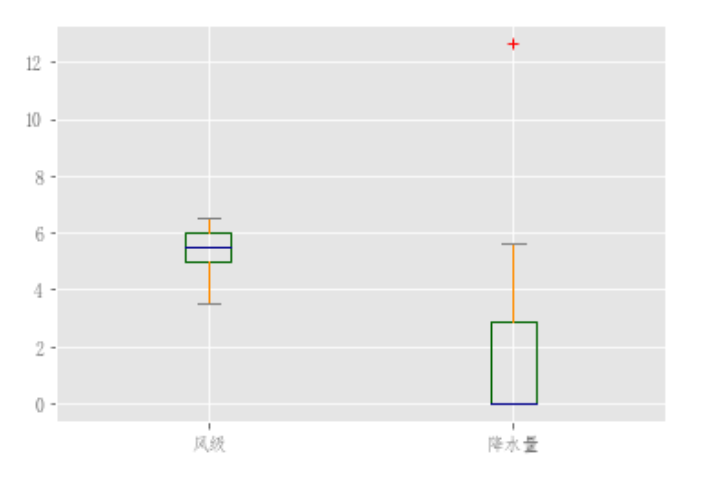
创建一个数据集展示更加明显:
df = pd.DataFrame(np.random.rand(10, 5), columns=["A", "B", "C", "D", "E"]) color = { "boxes": "DarkGreen", "whiskers": "DarkOrange", "medians": "DarkBlue", "caps": "Gray", } df.plot.box(color=color, sym="r+")
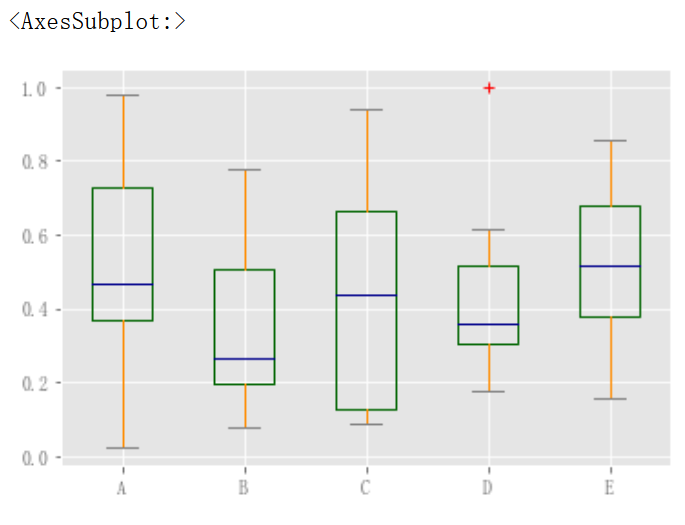
此外,还可以传递matplotlib箱线图支持的其他关键字。例如,可以通过vert=False和positions关键字绘制水平和自定义定位箱线图。
df.plot.box(vert=False, positions=[1, 4, 5, 6, 8])

现有接口仍然可以使用DataFrame.boxplot:
df.boxplot()

可以使用by关键字参数创建分层箱线图来创建分组。
例如
df = pd.DataFrame(np.random.rand(10, 2), columns=["Col1", "Col2"]) df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]) plt.figure(); bp = df.boxplot(by="X")
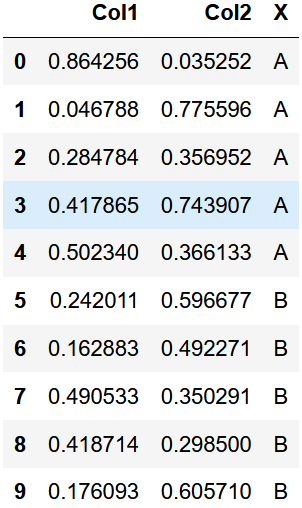

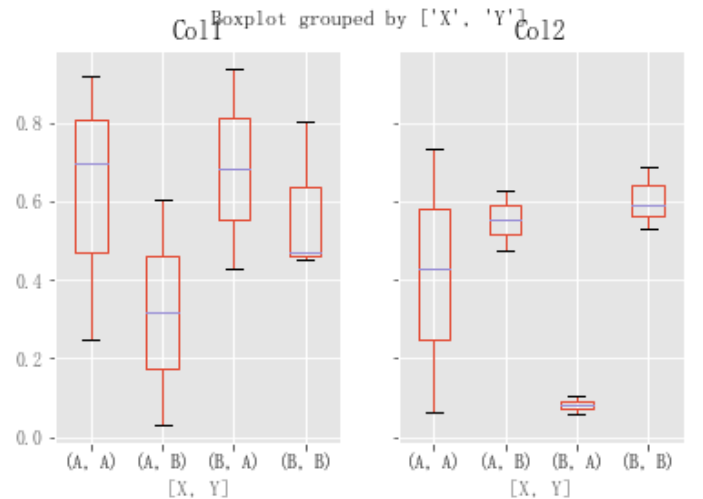
还可以传递要打印的列子集,以及按多个列分组:
df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"]) df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]) df["Y"] = pd.Series(["A", "B", "A", "B", "A", "B", "A", "B", "A", "B"]) plt.figure(); bp = df.boxplot(column=["Col1", "Col2"], by=["X", "Y"])
用DataFrame.plot.box()也是一样的:
df = pd.DataFrame(np.random.rand(10, 3), columns=["Col1", "Col2", "Col3"]) df["X"] = pd.Series(["A", "A", "A", "A", "A", "B", "B", "B", "B", "B"]) plt.figure() bp = df.plot.box(columns=["Col1", "Col2"], by="X")
在箱线图中,返回类型可以由return_type,关键字控制。有效选项是{“axes”、“dict”、“both”、“None}。镶嵌面,由DataFrame.boxplot创建by关键字的箱线图也会影响输出类型:
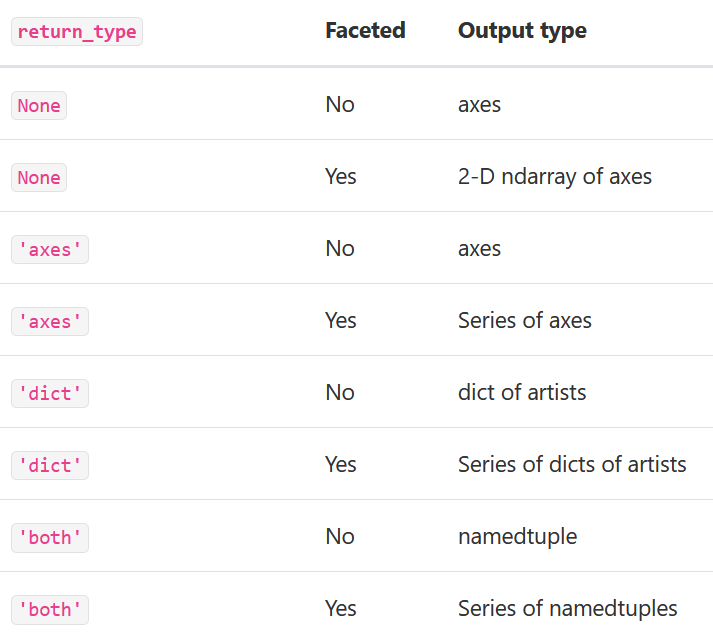
np.random.seed(1234) df_box = pd.DataFrame(np.random.randn(50, 2)) df_box["g"] = np.random.choice(["A", "B"], size=50) df_box.loc[df_box["g"] == "B", 1] += 3 bp = df_box.boxplot(by="g")

上面的子地块首先由数字列分割,然后由g列的值分割。下面的子地块首先由g值分割,然后由数字列分割。
bp = df_box.groupby("g").boxplot()
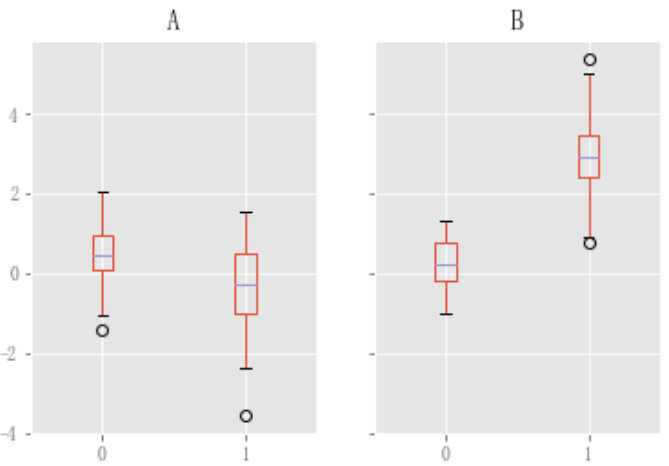
可以使用Series.plot.area()和DataFrame.plot.area()创建面积图。默认情况下,面积图是堆叠的。要生成堆叠面积图,每列必须全部为正值或全部为负值。
当输入数据包含NaN时,它将自动由0填充。如果要使用不同的值进行删除或填充,调用plot之前可以使用DataFrame.dropna()或DataFrame.fillna()。
代码如下(示例):
df = pd.DataFrame(np.random.rand(10, 4), columns=["a", "b", "c", "d"]) df.plot.area();
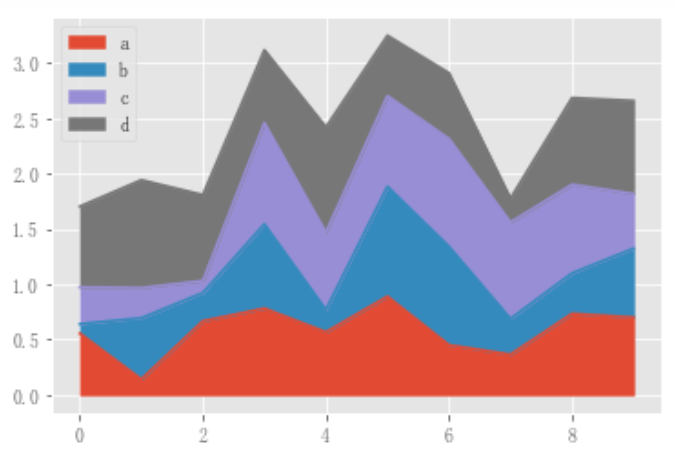
要生成未堆叠的绘图,请传递stacked=False。Alpha值设置为0.5。
df.plot.area(stacked=False);
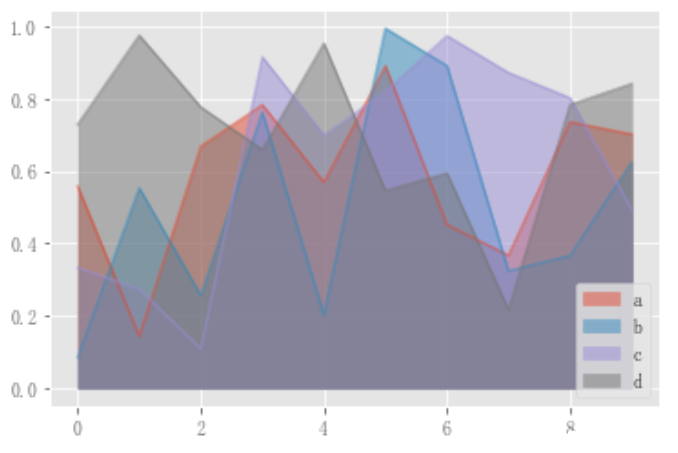
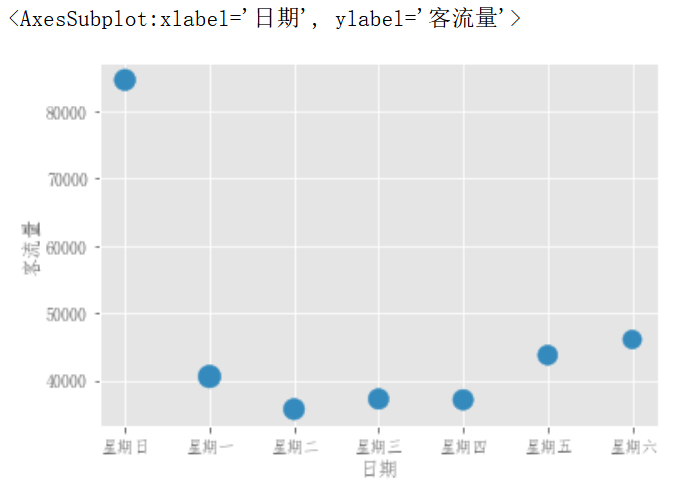
可以使用DataFrame.plot.scatter()方法绘制散点图,散点图需要x轴和y轴的数字列。这些可以由x和y关键字指定。
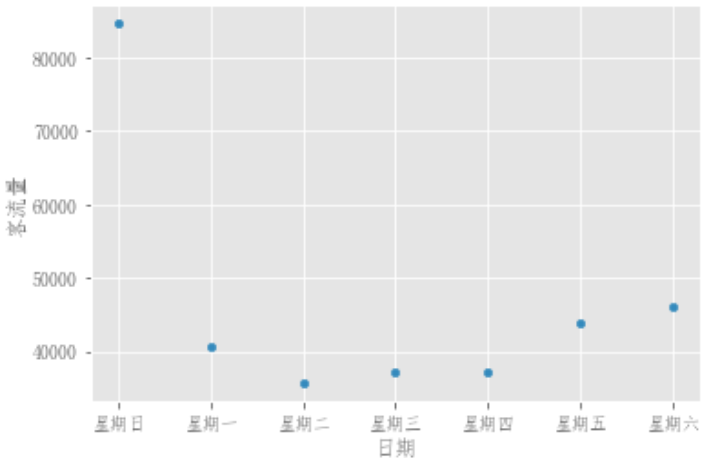
df_flow_mark.plot.scatter(x='日期',y='客流量')
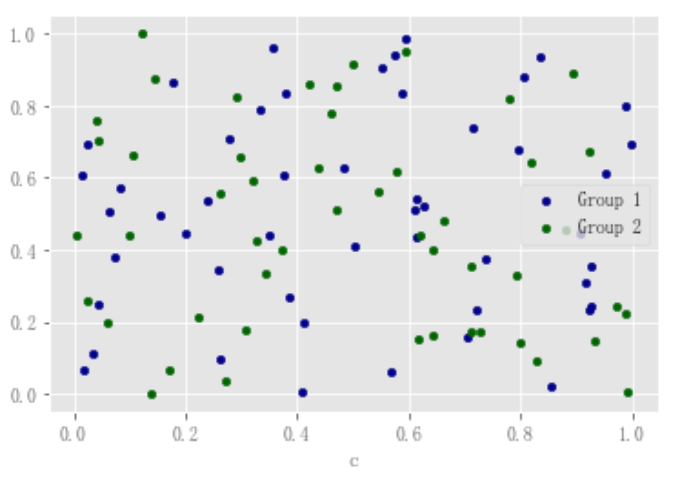
要在单个轴上绘制多个列组,可以重复指定目标轴的打印方法。建议指定颜色(color)和标签(label)关键字以区分每个组。
df = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"]) df["species"] = pd.Categorical( ["setosa"] * 20 + ["versicolor"] * 20 + ["virginica"] * 10 ) ax = df.plot.scatter(x="a", y="b", color="DarkBlue", label="Group 1") df.plot.scatter(x="c", y="d", color="DarkGreen", label="Group 2", ax=ax);
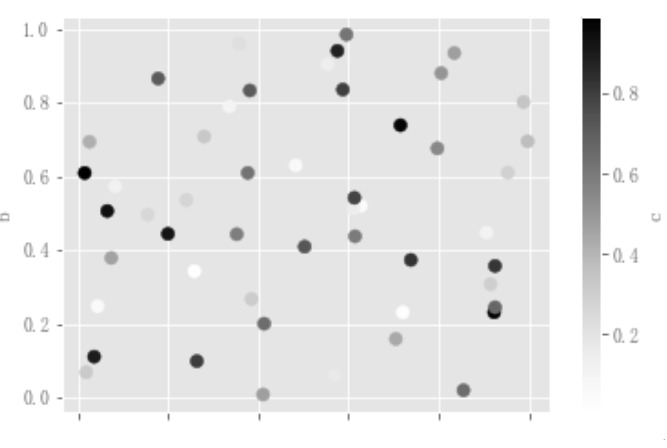
关键字c可以作为列的名称,为每个点提供颜色:
df.plot.scatter(x="a", y="b", c="c", s=50);
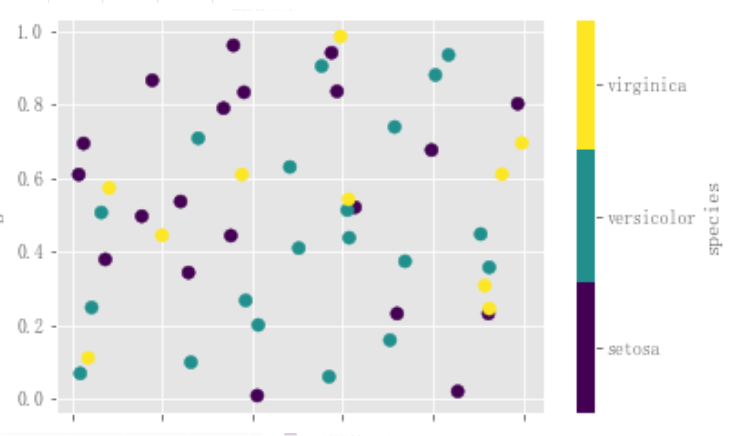
如果将分类列传递给c,则将生成一个离散的颜色条:
df.plot.scatter(x="a", y="b", c="species", cmap="viridis", s=50);
可以传递matplotlib.scatter支持的其他关键字。下面的示例显示了一个气泡图,它使用DataFrame的一列作为气泡大小。
df_flow_mark.plot.scatter(x='日期',y='客流量',s=df_flow_mark['湿度']*200)
最后给大家分享一套Python视频:Python实战100例
今天的分享就到这里结束辽~
大家下次再见!

文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


