
前两章我们分别介绍了NER的基线模型Bert-Bilstm-crf, 以及多任务和对抗学习在解决词边界和跨领域迁移的解决方案。这一章我们就词汇增强这个中文NER的核心问题之一来看看都有哪些解决方案。以下预测结果和代码详见Github-DSXiangLi/ChineseNER
第一章提到过中文NER的普遍使用字符粒度的输入,从而避免分词错误/分词粒度和NER粒度不一致限制模型表现的天花板,以及词输入OOV的问题。但是字符输入会有两个问题
- 缺失了字符在词汇中的语义表达
- 丢失了词边界信息
有人说不要担心我们有Bert!可以直接用预训练语言模型去提取通用的包含上下文的文本信息,但使用Bert还是几个问题
- infer速度在部分场景不满足要求,因此部分场景使用词汇增强是为了在保证推理延时的前提下,去逼近bert的性能
- Bert在部分垂直领域的表现一般,因此需要领域内的词汇信息加持
- Bert的信息提取更加全局,NER的识别需要局部信息,因此依旧会存在边界识别错误的问题
词汇增强的方法主要分为两种
- Embedding增强:包括softword, Ex-softword, 以及去年的新贵SoftLexicon,它们对模型结构无任何要求只通过引入带有词汇/分词信息的Embedding达到词汇增强的目的,更灵活且SoftLexicon的效果拔群
- 特殊模型结构类:Lattice-LSTM出发的各种改良,例如用CNN替换LSTM结构的LR-CNN,改造transformer positional encoding的FLAT等等。
Embedding增强
Softword
最简单引入词边界信息的方案,就是直接引入分词B/M/E/S的标签。这里我直接用了jieba,当然如果有用目标数据集训练的Segmentator更好,对句子进行分词,根据分词结果对字符分别标注是一个单词的开始(B),中间(M),结束(E)还是单个字符(S),如下

然后在模型输入侧,把分词的label encoding进行向量表达,用相加或者拼接的方式,加入到已有的token embedding上。
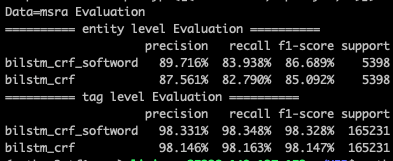
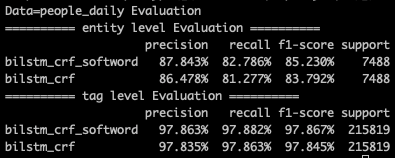
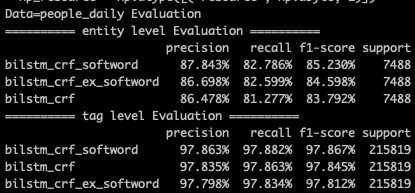
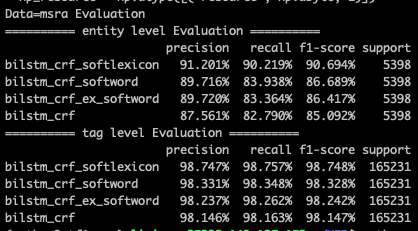
这种方式最简单粗暴,但问题就是其一B/M/E/S基本只引入了词边界信息,对于词本身语义信息的表达有限,其二单一分词器的会因为自身的准确率以及粒度问题引入噪音。在MSRA/People Daily的数据集上,softword对tag级别的预测基本没啥增益,但是对entity级别的预测有1个多点左右的提升,对于样本更小的people daily数据集提升更大。
Ex-softword
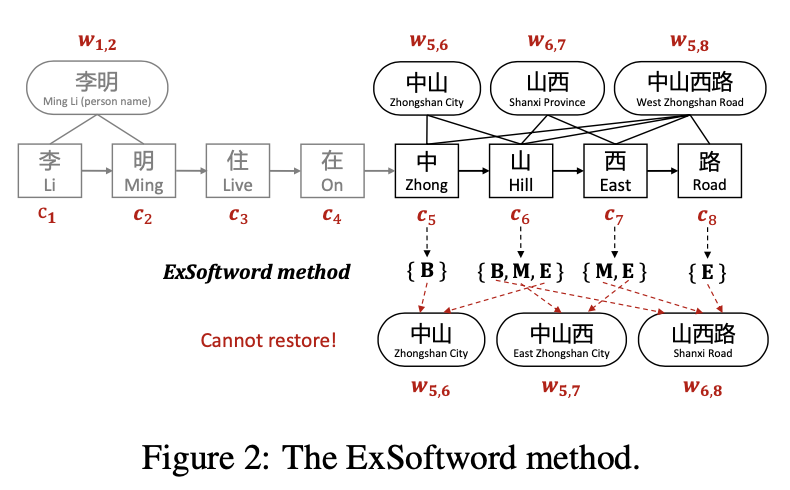
既然softword有单一分词器的问题,那如果不考虑分词,直接把该字符在上下文中所有能匹配上词汇信息都加入进来会不会更好呢? 如下所示每个字符会遍历词表,拿到所有包含这个字且满足前后文本的所有分词tag。整个遍历是O(NK)的复杂度其中N是句子长度,K是最长词搜索长度我取了10,Exsoftword的结果如下
Ex-softword通过引入更多的分词信息,来模糊单一分词器可能的分词错误问题,不过它并没有对引入的信息相关性/重要性进行区分,虽然引入更多信息,但同时引入了更多噪音,效果相较softword并没啥提升。
Softlexicon
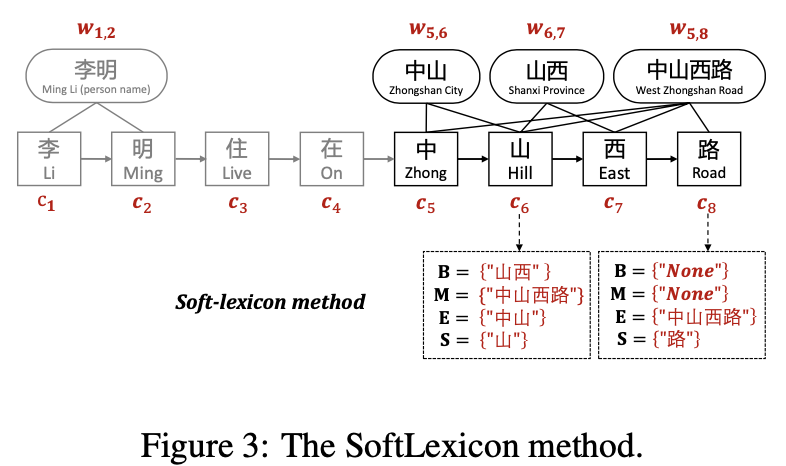
softlexicon是在Ex-softword的基础上把只使用B/M/E/S的分词tag,变成直接使用所有匹配上的单词。每个字符都得到该字符作为B/M/E/S所能匹配上的所有单词,这样在引入词边界信息的同时也引入词汇本身信息。
default = {'B' : set(), 'M' : set(), 'E' : set(), 'S' :set()}
soft_lexicon = [deepcopy(default) for i in range(len(sentence))]
for i in range(len(sentence)):
for j in range(i, min(i+MaxWordLen, len(sentence))):
word = sentence[i:(j + 1)]
if word in Vocab2IDX:
if j-i==0:
soft_lexicon[i]['S'].add(word)
elif j-i==1:
soft_lexicon[i]['B'].add(word)
soft_lexicon[i+1]['E'].add(word)
else:
soft_lexicon[i]['B'].add(word)
soft_lexicon[j]['E'].add(word)
for k in range(i+1, j):
soft_lexicon[k]['M'].add(word)
for key, val in soft_lexicon[i].items():
if not val:
soft_lexicon[i][key].add(NONE_TOKEN)
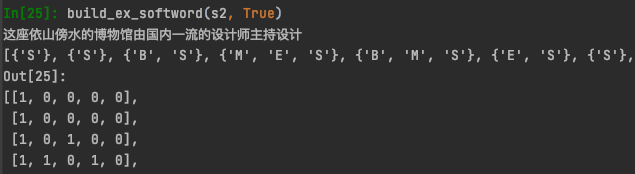
以上build_softlexicon会得到以下输出
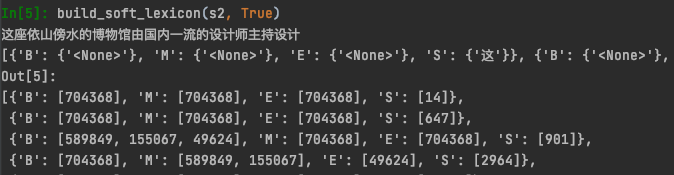
作者尝试了对匹配上的单词取对应预训练Embedding然后对B/M/E/S分别算average embedding再concat在一起,但是效果并不好。这种做法和以上Ex-softword相同,没有对词汇的重要性进行区分会引入较多噪音。于是作者是直接在训练集+验证集上统计了匹配上的word count (z(w)) 作为该词的embeding权重,在代码里我默认使用了预训练glove的词频,毕竟实际标注数据往往较少,直接在训练集上统计词频OOV问题会比较严重。
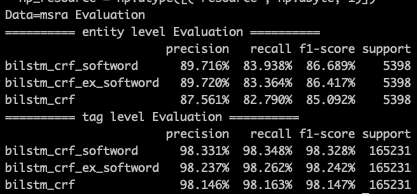
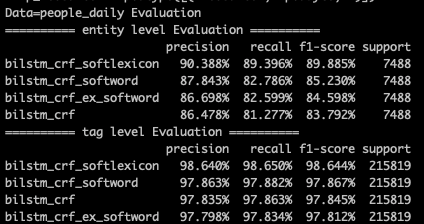
在效果上softLexicon还是比较厉害的,相较bilstm_crf有近6个点的提升【这里MSRA的样本split和paper有差异,bilstm_crf就低了3个点左右,不过相对提升和paper中近似】。在paper的样本划分中,MSRA数据集上softlexicon的效果只比bert差1个多点,在Weibo/OneNote上要差的多些,毕竟词频统计在测试集上的适配程度是训练集越大好的,不过和以下Lattice增强的各种模型相比表现是不相上下的!
对比我们马上要聊的Lattice家族,SoftLexicon可以说是简单粗暴又好使!且因为只比bilstm多了一层O(NK)的词表匹配,infer speed比bert要快一倍多,比lattice快5倍,可以说是十分优秀了!
Lattice Family
词汇增强的另一种实现方式就是借助特殊的模型结构引入词信息,这一块没有代码复现更多只是了解下模型,毕竟结构的限制在使用上没有上面的Embedding方案灵活。
Lattice-LSTM
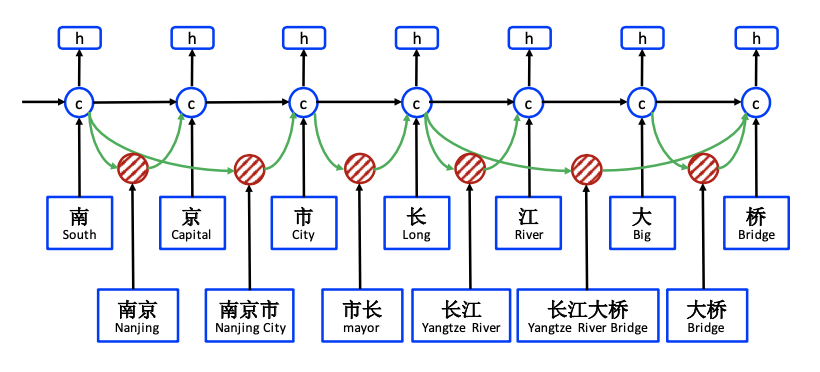
Lattice引入词信息的方式是通过加入一条额外词信息传递路径,把该路径的信息补充到字符路径的隐藏层,一同计算输出h。词信息的传递需要解决两个问题,其一词信息的向前传递如何计算,其二一个字符可能对应词库中的多个词,例如'长江大桥'中的桥字,会对应‘大桥’,以及长江大桥这两个词,也就是会有两条向前传递的信息,这两个信息如何加权。
首先,我们看下词信息如何向前传递。在上图南京市的例子中,‘市’字可以引入‘南京市’这个词汇信息,于是会产生一条额外的向前传递路径。作者用下标b,e表示词的开始位置和结束位置,用上标w,c分别表示词汇和字符对应的LSTM路径。于是‘市’对应的t-1隐藏层是‘南’字字符路径的输出层,输入(x_{b,e}^w)是‘南京市’这个词对应的词向量,输出的t隐藏层是位置在‘市’字的(c_{b,e}^w)。如下计算词路径的LSTM。输出gate被省略,因为输出层只有一个就是字符路径对应的输出层,词路径只需要隐藏层。
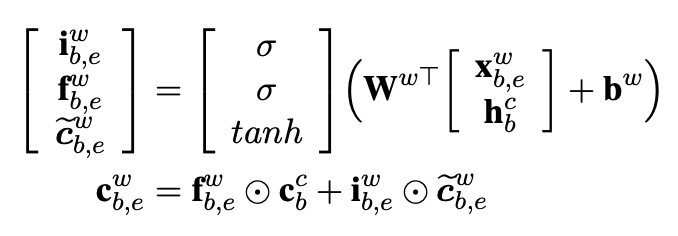
要完成以上计算,需要记录每个字符所能匹配到的所有单词(用来取词embedding),以及每个单词的长度(用来计算上一个hidden state的位置)因为每个输入序列的词位置不同,所以每个序列的LSTM向前传递的方式都不同限制了Lattice-LSTM的batch_size只能为1。Ref2是做了优化的支持batch_size>1的类lattice-LSTM实现,感兴趣的同学可以自己看下~
其次,一个字符可能对应多个匹配词,也就是一个(c_j^c)可能存在多个以上(c_{b,j}^w)。 以下作者引入额外的input gate来衡量不同词汇路径隐藏层和当前字符向量的相关性,相关性越高该词汇路径权重越高。
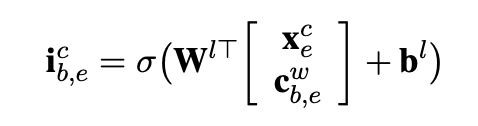
词汇路径input gate和字符路径的input gate权重进行归一化得到(a_{b,j}^c)和(a_j^c),归一化保证了多词/单一/无词汇匹配的词汇增强信息可比。得到词汇增强的字符隐藏层后,(o_j^c cdot tanh(c_j^c))得到输出信息.
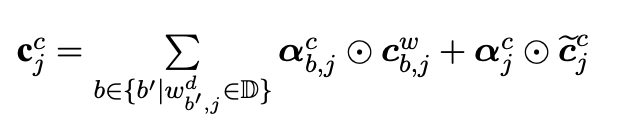
LR-CNN
以上Lattice LSTM最明显的问题就是运行效率,LSTM无法并行已经够慢了,Lattice还要限制batch_size=1。还有一个问题就是词向量信息的权重计算只用到了和字符的相关性,并没有考虑上下文语义,可能会导致错误词汇的权重过大引入噪音。例如下图,对‘长’字的判断可能因为错误引入‘市长’这个错误词信息而导致无法识别B-GPE这个label。针对这两个问题我们看下LR-CNN是如何解决的
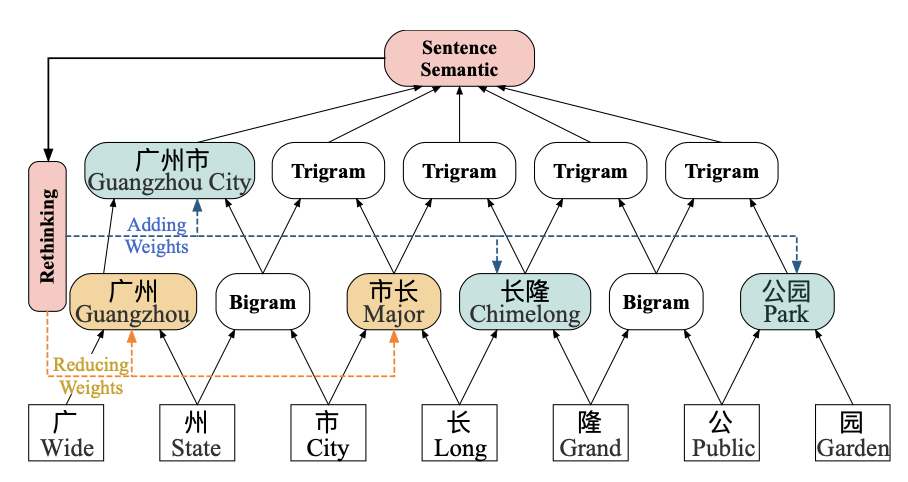
针对LSTM的运行效率问题,最常见的解法就是用CNN替换LSTM。想让CNN提取到更长距离的文本信息,可能会采用stack或者不同window size拼接的CNN cell。这里作者采用了window_size=2的stack CNN来捕捉n-gram信息,在MSRA数据集上用了50层,filter=300的模型结构。
词汇信息的加入是按照长度分层加入的,长度为2的单词在第二层加入和CNN提取的bigram特征加权,长度为3的在第三层加入和trigram加权。以下(C_m^l)是基于字符特征stack CNN在l层m位置输出的l-gram特征,(w_m^l)是对应m位置l长度的词embedding特征,加权方式和Lattice相同,都是用词向量和当前CNN层n-gram向量的相似度分别计算input_gate (i_1)和forget_gate (f_1),正则化后加权得到l层m位置的特征向量。

以上向前传递的CNN,依旧无法解决词汇冲突的问题,因为词向量权重还是用当前的n-gram信息和词的相似度计算的。我们需要引入更全局包含上下文的语义特征来调整词向量的权重。LR-CNN把stack CNN的top层作为全局语义信息的表达。以上stack CNN向前传递到L层之后,需要用L层的输出对1~L-1层的特征输出进行调整,也就是所谓的Rethinking。调整方式就是在以上的attention计算中加入包含全局信息的顶层CNN特征向量(X_m^L),计算考虑全局语义的局部词汇重要性。
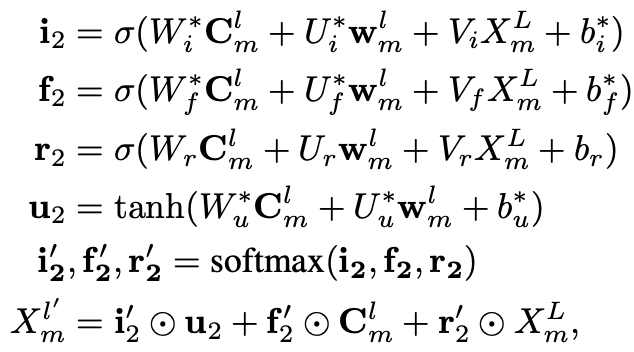
以上会得到1~L层每个位置调整后的(X_m^1,...X_m^L),然后用Multi-scale Feature Attention对每个位置1~L层的特征进行加权得到m位置的输出特征进入CRF进行解码预测。简单解释下(s_m^l),就是l层m位置的Conv Block计算得到的k个filter进行求和得到scaler,把这个scaler作为该位置Conv Block特征重要性的度量,细节详见Ref4
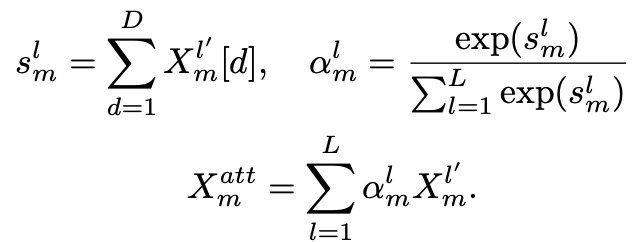
LR-CNN在不损失Lattice-LSTM效果的前提下比Lattice要快3倍左右,不过还是比SoftLexicon慢一倍多。那词汇增强我们先说这么多,基于transformer的TENER和FLAT放到后面和玄妙的positional encoding一起再说咯~
Reference
- [Lattice-LSTM]Chinese NER using lattice LSTM, 2018
- [Batch Lattice] An Encoding Strategy Based Word-Character LSTM for Chinese NER
- [LR-CNN]LR-CNN:CNN-Based Chinese NER with Lexicon Rethinking, 2019
- [Mutli-scale Feature Attention]Densely Connected CNN with Multi-scale Feature Attention for Text Classification
- [softword]Unsupervised Segmentatino Helps Supervised Learning of Character Taggering for Word Segmentation and Named Entity Recognition
- [Positional Embedding]Named Entity Recognition for Chinese Social Media with Jointly Trained Embeddings
- [Soft-Lexicon] Simple-Lexicon:Simplify the Usage of Lexicon in Chinese NER
- https://zhuanlan.zhihu.com/p/77788495
- https://zhuanlan.zhihu.com/p/142615620
- https://zhuanlan.zhihu.com/p/166496466
- https://www.paperweekly.site/papers/notes/623
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


