
字体反爬虫开篇概述
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
在 CSS3 之前,Web 开发者必须使用用户计算机上已有的字体。但是在 CSS3 时代,开发者可以使用@font-face 为网页指定字体,对用户计算机字体的依赖。开发者可将心仪的字体文件放在 Web
服务器上,并在 CSS 样式中使用它。用户使用浏览器访问 Web 应用时,对应的字体会被浏览器下载到用户的计算机上。
在学习浏览器和页面渲染的相关知识时,我们了解到 CSS 的作用是修饰 HTML ,所以在页面渲染的时候不会改变 HTML 文档内容。由于字体的加载和映射工作是由 CSS 完成的,所以即使我们借助 Splash、Selenium 和 Puppeteer 工具也无法获得对应的文字内容。字体反爬虫正是利用了这个特点,将自定义字体应用到网页中重要的数据上,使得爬虫程序无法获得正确的数据。
6.4.1 字体反爬虫示例
示例 7:字体反爬虫示例。
网址:http://www.porters.vip/confusion/movie.html。
任务:爬取影片信息展示页中的影片评分、评价人数和票房数据,页面内容如图 6-32 所示。

图 6-32 示例 7 页面
在编写代码之前,我们需要确定目标数据的元素定位。定位时,我们在 HTML 中发现了一些奇怪的符号,HTML 代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<div class="movie-index">
<p class="movie-index-title">用户评分</p>
<div class="movie-index-content score normal-score">
<span class="index-left info-num ">
<span class="stonefont"> ☒.☒ </span>
</span>
<div class="index-right">
<div class="star-wrapper">
<div class="star-on" style="width:90%;"></div>
</div>
<span class="score-num"><span class="stonefont"> ☒☒. ☒☒ 万</span>人评分</span>
</div>
</div>
</div>
|
页面中重要的数据都是一些奇怪的字符,本应该显示“9.7”的地方在 HTML 中显示的是“☒.☒”,而本应该显示“56.83”的地方在 HTML 中显示的是“☒☒.☒☒”。与 6.3 节中的映射反爬虫不同,案例中的文字都被“☒”符号代替了,根本无法分辨。这就很奇怪了,“☒”能代表这么多种数字吗?
要注意的是,Chrome 开发者工具的元素面板中显示的内容不一定是相应正文的原文,要想知道“☒”符号是什么,还需要到网页源代码中确认。对应的网页源代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<div class="movie-index">
<p class="movie-index-title">用户评分</p>
<div class="movie-index-content score normal-score">
<span class="index-left info-num ">
<span class="stonefont">.</span>
</span>
<div class="index-right">
<div class="star-wrapper">
<div class="star-on" style="width:90%;"></div>
</div>
<span class="score-num"><span class="stonefont">.万</span>人评分</span>
</div>
</div>
</div>
|
从网页源代码中看到的并不是符号,而是由&#x 开头的一些字符,这与示例 6 中的 SVG 映射反爬虫非常相似。我们将页面显示的数字与网页源代码中的字符进行比较,映射关系如图 6-33 所示。

图 6-33 字符与数字的映射关系
字符与数字是一一对应的,我们只需要多找一些页面,将 0 ~ 9 数字对应的字符凑齐即可。但如果目标网站的字体是动态变化的呢?映射关系也是变化的呢?
根据 6.3 节的学习和分析,我们知道人为映射并不能解决这些问题,必须找到映射关系的规律,并使用 Python 代码实现映射算法才行。继续往下分析,难道字符映射是先异步加载数据再使用 JavaScript 渲染的?
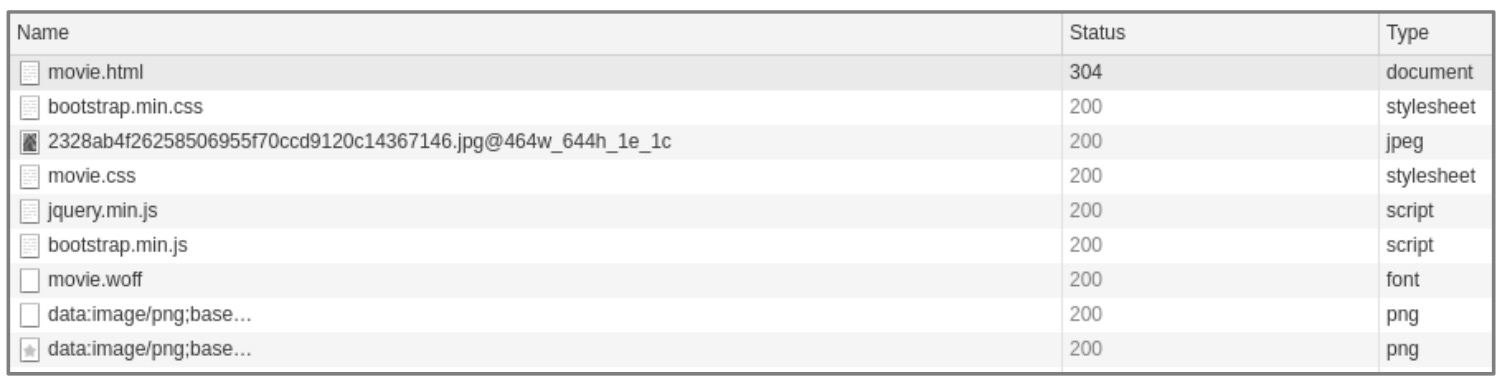
图 6-34 请求记录
网络请求记录如图 6-34 所示,请求记录中并没有发现异步请求,这个猜测并没有得到证实。CSS 样式方面有没有线索呢?页面中包裹符号的标签的 class 属性值都是 stonefont:
|
1
2
3
|
<span class="stonefont">.</span>
<span class="stonefont">. 万</span>
<span class="stonefont">.</span>
|
但对应的 CSS 样式中仅设置了字体:
|
1
2
3
|
.stonefont {
font-family: stonefont;
}
|
既然是自定义字体,就意味着会加载字体文件,我们可以在网络请求中找到加载的字体文件 movie.woff,并将其下载到本地,接着使用百度字体编辑器看一看里面的内容。
百度字体编辑器 FontEditor (详见 http://fontstore.baidu.com/static/editor/index.html)是一款在线字体编辑软件,能够打开本地或者远程的 ttf、woff、eot、otf 格式的字体文件,具备这些格式字体文件的导入和导出功能,并且提供字形编辑、轮廓编辑和字体实时预览功能,界面如图 6-35 所示。

图 6-35 百度字体编辑器界面
打开页面后,将 movie.woff 文件拖曳到百度字体编辑器的灰色区域即可,字体文件内容如图 6-36 所示。

图 6-36 字体文件 movie.woff 预览
该字体文件中共有 12 个字体块,其中包括 2 个空白字体块和 0 ~ 9 的数字字体块。我们可以大胆地猜测,评分数据和票房数据中使用的数字正是从此而来。
由此看来,我们还需要了解一些字体文件格式相关的知识,在了解文件格式和规律后,才能够找到更合理的解决办法。
6.4.2 字体文件 WOFF
WOFF(Web Open Font Format,Web 开放字体格式)是一种网页所采用的字体格式标准。本质上基于 SFNT 字体(如 TrueType),所以它具备 TrueType 的字体结构,我们只需要了解 TrueType 字体的相关知识即可。
TrueType 字体是苹果公司与微软公司联合开发的一种计算机轮廓字体,TrueType 字体中的每个字形由网格上的一系列点描述,点是字体中的最小单位,字形与点的关系如图 6-37 所示。
图 6-37 字形与点的关系
字体文件中不仅包含字形数据和点信息,还包括字符到字形映射、字体标题、命名和水平指标等,这些信息存在对应的表中,所以我们也可以认为 TrueType 字体文件由一系列的表组成,其中常用的表
及其作用如图 6-38 所示。

图 6-38 构成字体文件的常用表及其作用
如何查看这些表的结构和所包含的信息呢?我们可以借助第三方 Python 库 fonttools 将 WOFF 等字体文件转换成 XML 文件,这样就能查看字体文件的结构和表信息了。首先我们要安装 fonttools 库,
安装命令为:
|
1
|
$ pip install fonttools
|
安装完毕后就可以利用该库转换文件类型,对应的 Python 代码为:
|
1
2
3
|
from fontTools.ttLib import TTFont
font = TTFont('movie.woff') # 打开当前目录的 movie.woff 文件
font.saveXML('movie.xml') # 另存为 movie.xml
|
代码运行后就会在当前目录生成名为 movie 的 XML 文件。文件中字符到字形映射表 cmap 的内容如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x78" name="x"/>
<map code="0xe339" name="uniE339"/>
<map code="0xe624" name="uniE624"/>
<map code="0xe7df" name="uniE7DF"/>
<map code="0xe9c7" name="uniE9C7"/>
<map code="0xea16" name="uniEA16"/>
<map code="0xee76" name="uniEE76"/>
<map code="0xefd4" name="uniEFD4"/>
<map code="0xf19a" name="uniF19A"/>
<map code="0xf57b" name="uniF57B"/>
<map code="0xf593" name="uniF593"/>
</cmap_format_4>
|
map 标签中的 code 代表字符,name 代表字形名称,关系如图 6-39 所示。
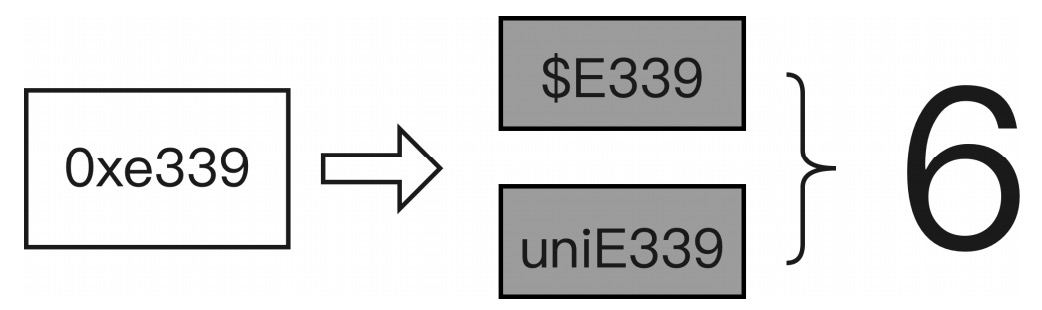
图 6-39 字符到字形映射关系示例
XML 中的字符 0xe339 与网页源代码中的字符 对应,这样我们就确定了 HTML 中的字符码与 movie.woff 字体文件中对应的字形关系。字形数据存储在 glyf 表中,每个字形的数据都是独立的,例如字形 uniE339 的字形数据如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
<TTGlyph name="uniE339" xMin="0" yMin="-12" xMax="510" yMax="719">
<contour>
<pt x="410" y="534" on="1"/>
<pt x="398" y="586" on="0"/>
<pt x="377" y="609" on="1"/>
<pt x="341" y="646" on="0"/>
<pt x="289" y="646" on="1"/>
...
</contour>
<contour>
<pt x="139" y="232" on="1"/>
<pt x="139" y="188" on="0"/>
<pt x="178" y="103" on="0"/>
...
</contour>
<instructions/>
</TTGlyph>
|
TTGlyph 标签中记录着字形的名称、x 轴坐标和 y 轴坐标(坐标也可以理解为字形的宽高)。contour 标签记录的是字形的轮廓信息,也就是多个点的坐标位置,正是这些点构成了如图 6-40 所示的字形。
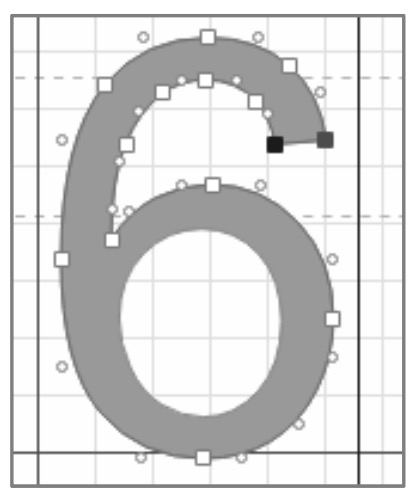
图 6-40 字形 uniE339 的轮廓
我们可以在百度字体编辑器中调整点的位置,然后保存字体文件并将新字体文件转换为 XML 格式,相同名称的字形数据如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<TTGlyph name="uniE339" xMin="115" yMin="6" xMax="430" yMax="495">
<contour>
<pt x="400" y="352" on="1"/>
<pt x="356" y="406" on="0"/>
<pt x="342" y="421" on="1"/>
<pt x="318" y="446" on="0"/>
<pt x="283" y="446" on="1"/>
...
</contour>
<instructions/>
</TTGlyph>
|
接着将调整前的字形数据和调整后的字形数据进行对比。
如图 6-41 所示,点的位置调整后,字形数据也会发生相应的变化,如 xMin、xMax、yMin、yMax 还有 pt 标签中的 x 坐标 y 坐标都与之前的不同了。
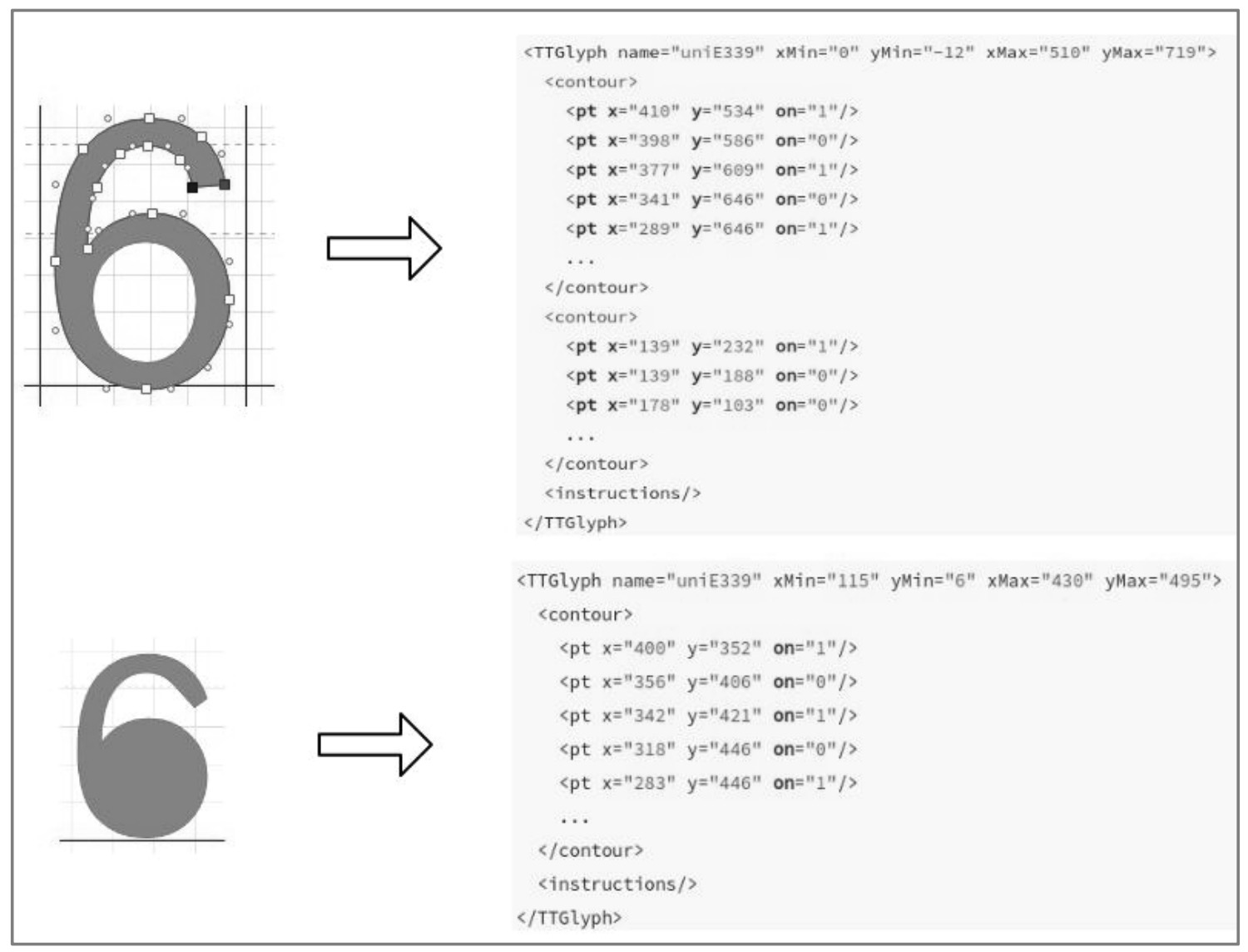
图 6-41 字形数据对比
XML 文件中记录的是字形坐标信息,实际上,我们没有办法直接通过字形数据获得文字,只能从其他方面想办法。虽然目标网站使用多套字体,但相同文字的字形也是相同的。比如现在有 movie.woff 和 food.woff 这两套字体,它们包含的字形如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# movie.woff
# 包含 10 个字形数据:[0123456789]
<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x78" name="x"/>
<map code="0xe339" name="uniE339"/> # 数字 6
<map code="0xe624" name="uniE624"/> # 数字 9
<map code="0xe7df" name="uniE7DF"/> # 数字 2
<map code="0xe9c7" name="uniE9C7"/> # 数字 7
<map code="0xea16" name="uniEA16"/> # 数字 5
<map code="0xee76" name="uniEE76"/> # 数字 0
<map code="0xefd4" name="uniEFD4"/> # 数字 8
<map code="0xf19a" name="uniF19A"/> # 数字 3
<map code="0xf57b" name="uniF57B"/> # 数字 1
<map code="0xf593" name="uniF593"/> # 数字 4
</cmap_format_4>
# food.woff
# 包含 3 个字形数据:[012]
<cmap_format_4 platformID="0" platEncID="3" language="0">
<map code="0x78" name="x"/>
<map code="0xe556" name="uniE556"/> # 数字 0
<map code="0xe667" name="uniE667"/> # 数字 1
<map code="0xe778" name="uniE778"/> # 数字 2
</cmap_format_4>
|
要实现自动识别文字,需要先准备参照字形,也就是人为地准备数字 0 ~ 9 的字形映射关系和字形数据,如:
|
1
2
3
4
5
6
|
# 0 和 7 与字形名称的映射伪代码,data 键对应的值是字形数据
font_mapping = [
{'name': 'uniE9C7', 'words': '7', 'data': 'uniE9C7_contour_pt'},
{'name': 'uniEE76', 'words': '0', 'data': 'uniEE76_countr_pt'},
]
|
当我们遇到目标网站上其他字体文件时,就可以使用参照字形中的字形数据与目标字形进行匹配,如果字形数据非常接近,就认为这两个字形描述的是相同的文字。字形数据包含记录字形名称和字形起止坐标的 TTGlyph 标签以及记录点坐标的 pt 标签,起止坐标代表的是字形在画布上的位置,点坐标代表字形中每个点在画布上的位置。在起止坐标中,x 轴差值代表字形宽度,y 轴差值代表字形高度。
如图 6-42 所示,两个字形的起止坐标和宽高都有很大的差别,但是却能够描述相同的文字,所以字形在画布中的位置并不会影响描述的文字,字形宽度和字形高度也不会影响描述的文字。

图 6-42 描述相同文字的两个字形
点坐标的数量和坐标值可以作为比较条件吗?
如图 6-43 所示,两个不同文字的字形数据是不一样的。虽然这两种字形的 name 都是 uniE9C7,但是字形数据中大部分 pt 标签 x 和 y 的差距都很大,所以我们可以判定这两个字形描述的并不是
同一个文字。你可能会想到点的数量也可以作为排除条件,也就是说如果点的数量不相同,那么这个
两个字形描述的就不是同一个文字。真的是这样吗?

图 6-43 描述不同文字的字形数据对比
在图 6-44 中,左侧描述文字 7 的字形有 17 个点,而右侧描述文字 7 的字形却有 20 个点。对应的字形信息如图 6-45 所示。
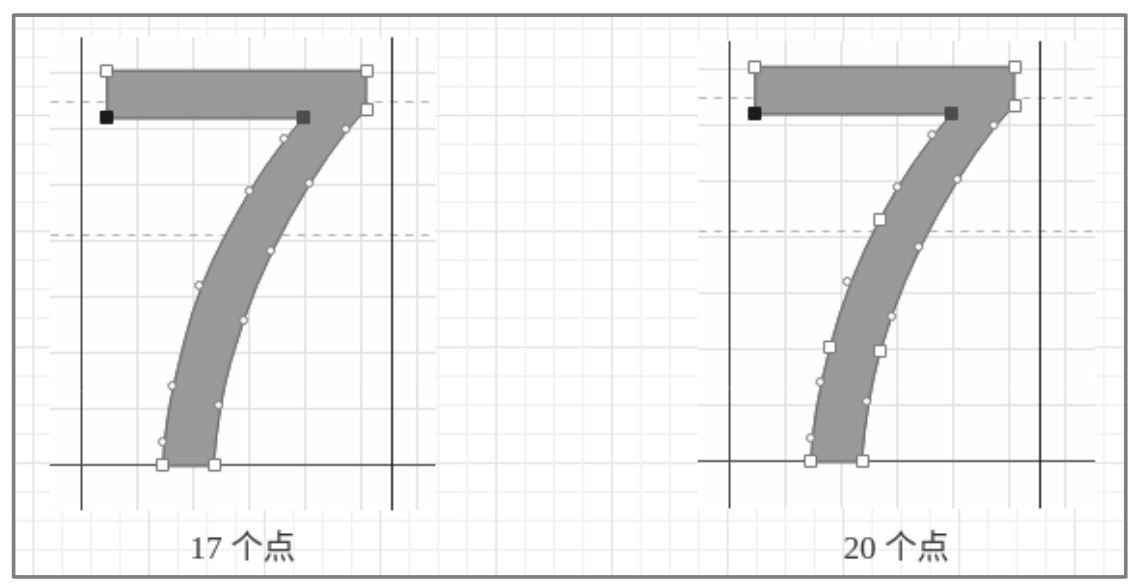
图 6-44 描述相同文字的字形

图 6-45 描述相同文字的字形信息
虽然点的数量不一样,但是它们的字形并没有太大的变化,也不会造成用户误读,所以点的数量并不能作为排除不同字形的条件。因此,只有起止坐标和点坐标数据完全相同的字形,描述的才是相同字符。
6.4.3 字体反爬虫绕过实战
要确定两组字形数据描述的是否为相同字符,我们必须取出 HTML 中对应的字形数据,然后将待确认的字形与我们准备好的基准字形数据进行对比。现在我们来整理一下这一系列工作的步骤。
(1) 准备基准字形描述信息。
(2) 访问目标网页。
(3) 从目标网页中读取字体编码字符。
(4) 下载 WOFF 文件并用 Python 代码打开。
(5) 根据字体编码字符找到 WOFF 文件中的字形轮廓信息。
(6) 将该字形轮廓信息与基准字形轮廓信息进行对比。
(7) 得出对比结果。
我们先完成前 4 个步骤的代码。下载 WOFF 文件并将其中字形描述的文字与人类认知的文字进行映射。由于字形数据比较庞大,所以我们可以将字形数据进行散列计算,这样得到的结果既简短又唯一,不会影响对比结果。这里以数字 0 ~ 9 为例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
base_font = {
"font": [{"name": "uniEE76", "value": "0", "hex": "fc170db1563e66547e9100cf7784951f"},
{"name": "uniF57B", "value": "1", "hex": "251357942c5160a003eec31c68a06f64"},
{"name": "uniE7DF", "value": "2", "hex": "8a3ab2e9ca7db2b13ce198521010bde4"},
{"name": "uniF19A", "value": "3", "hex": "712e4b5abd0ba2b09aff19be89e75146"},
{"name": "uniF593", "value": "4", "hex": "e5764c45cf9de7f0a4ada6b0370b81a1"},
{"name": "uniEA16", "value": "5", "hex": "c631abb5e408146eb1a17db4113f878f"},
{"name": "uniE339", "value": "6", "hex": "0833d3b4f61f02258217421b4e4bde24"},
{"name": "uniE9C7", "value": "7", "hex": "4aa5ac9a6741107dca4c5dd05176ec4c"},
{"name": "uniEFD4", "value": "8", "hex": "c37e95c05e0dd147b47f3cb1e5ac60d7"},
{"name": "uniE624", "value": "9", "hex": "704362b6e0feb6cd0b1303f10c000f95"}]
}
|
字典中的 name 代表该字形的名称,value 代表该字形描述的文字,hex 代表字形信息的 MD5 值。
考虑到网络请求记录中的字体文件路径有可能会变化,我们必须找到 CSS 中设定的字体文件路径,引入 CSS 的 HTML 代码为:
|
1
2
|
<link href="./css/movie.css" rel="stylesheet">
|
由引入代码得知该 CSS 文件的路径为 http://www.porters.vip/confusion/css/movie.css,文件中 @font-face 处就是设置字体的代码:
|
1
2
3
4
5
|
@font-face {
font-family: stonefont;
src:url('../font/movie.woff') format('woff');
}
|
字体文件路径为 http://www.porters.vip/confusion/font/movie.woff。找到文件后,我们就可以开始编写代码了,对应的 Python 代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
import re
from parsel import Selector
from urllib import parse
from fontTools.ttLib import TTFont
url = 'http://www.porters.vip/confusion/movie.html'
resp = requests.get(url)
sel = Selector(resp.text)
# 提取页面加载的所有 css 文件路径
css_path = sel.css('link[rel=stylesheet]::attr(href)').extract()
woffs = []
for c in css_path:
# 拼接正确的 css 文件路径
css_url = parse.urljoin(url, c)
# 向 css 文件发起请求
css_resp = requests.get(css_url)
# 匹配 css 文件中的 woff 文件路径
woff_path = re.findall("src:url('..(.*.woff)') format('woff');",
css_resp.text)
if woff_path:
# 如故路径存在则添加到 woffs 列表中
woffs += woff_path
woff_url = 'http://www.porters.vip/confusion' + woffs.pop()
woff = requests.get(woff_url)
filename = 'target.woff'
with open(filename, 'wb') as f:
# 将文件保存到本地
f.write(woff.content)
# 使用 TTFont 库打开刚才下载的 woff 文件
font = TTFont(filename)
|
因为 TTFont 可以直接读取 woff 文件的结构,所以这里不需要将 woff 保存为 XML 文件。接着以评分数据 9.7 对应的编码 #xe624.#xe9c7 进行测试,在原来的代码中引入基准字体数据 base_font,然后新增以下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
web_code = '.'
# 编码文字替换
woff_code = [i.upper().replace('&#X', 'uni') for i in web_code.split('.')]
import hashlib
result = []
for w in woff_code:
# 从字体文件中取出对应编码的字形信息
content = font['glyf'].glyphs.get(w).data
# 字形信息 MD5
glyph = hashlib.md5(content).hexdigest()
for b in base_font.get('font'):
# 与基准字形中的 MD5 值进行对比,如果相同则取出该字形描述的文字
if b.get('hex') == glyph:
result.append(b.get('value'))
break
# 打印映射结果
print(result)
|
以上代码运行结果为:
|
1
2
|
['9', '7']
|
运行结果说明能够正确映射字体文件中字形描述的文字。
6.4.4 小结
字体反爬能给爬虫工程师带来很大的麻烦。虽然爬虫工程师找到了应对方法,但这种方法依赖的条件比较严苛,如果开发者频繁改动字体文件或准备多套字体文件并随机切换,那真是一件令爬虫工程师头疼的事。不过,这些工作对于开发者来说也不是轻松的事。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


