
论文地址:FLGCNN:一种新颖的全卷积神经网络,用于基于话语的目标函数的端到端单耳语音增强
论文代码:https://github.com/LXP-Never/FLGCCRN(非官方复现)
引用格式:Zhu Y, Xu X, Ye Z. FLGCNN: A novel fully convolutional neural network for end-to-end monaural speech enhancement with utterance-based objective functions[J]. Applied Acoustics, 2020, 170: 107511.
摘要
提出了一种新的全卷积神经网络(FCN),称为FLGCNN,用于解决时域端到端语音增强问题。提出的FLGCNN主要建立在编码器和译码器上,同时增加了额外的基于卷积的短时傅立叶变换(CSTFT)层和逆STFT(CISTFT)层来模拟正、逆STFT运算。这些层次的目的是将频域知识集成到所提出的模型中,因为语音的潜在语音信息用时频(T-F)表示更清楚地表示出来。此外,编码器和解码器由门控卷积层构成,因此所提出的模型可以更好地控制层次结构中传递的信息。此外,在流行的时间卷积神经网络(TCNN)的启发下,在编码器和解码器之间插入了时间卷积模块(TCM),该模块能够有效地模拟语音信号的长期相关性。由于整个框架可以实现端到端的语音增强,我们还利用不同的基于发音的目标函数对所提模型进行了优化,以挖掘损失函数对性能的影响。实验结果表明,与其他好胜语音增强方法相比,该模型具有更好的性能改善。
关键字:端到端语音增强、门控卷积、二维卷积、CSTFT/ CISTFT层、基于话语的目标函数
1 引言
语音增强算法在助听器、说话人/语音识别、免提通信等领域有着广泛的应用。由于干净的语音信号通常容易受到背景噪声的干扰,因此通常需要增强语音来提高整体语音质量和/或清晰度,而不会对期望的语音信号造成太多的失真。传统的单耳语音增强算法包括统计方法[2 4]和基于稀疏模型的方法[5 8]。但这些算法通常依赖于一些明确的假设,很容易在增强语音中引入额外的干扰。
在过去的几年里,基于深度神经网络(DNNs)的监督方法已经成为语音增强和分离的主流方法。DNN是一种功能强大的模型,可以从大量数据中学习复杂的非线性映射,因此当提供足够的数据时,DNN通常会优于传统算法。目前最流行的语音增强深度学习方法是基于掩模的方法和基于映射的方法。这两类通常采用短时傅里叶变换(STFT)将噪声信号转换为时频(T-F)表示,训练目标也由T-F表示构造。最常用的训练目标有理想比率掩模(IRM)、理想二值掩模(IBM)[10]和目标语音[11]的对数功率谱。
尽管使用T-F表示是最流行的方法,但它仍然有一些局限性。首先,STFT是否是语音增强信号的最佳变换还不清楚(即使假设它依赖的参数是最优的,如音频帧的大小和重叠、窗口类型等)。更重要的是,在这些方法中经常出现不一致的谱图或无效的STFT问题。STFT X只有满足下面条件时才一致
$$公式1:X=zeta [zeta ^{-1}(X)]$$
其中$X=zeta[x(t)]$和$x(t)$是实值时域信号。$zeta$和$zeta^{-1}[·]$表示正向和反向STFT运算符。但是在频域语音增强中,常用的方法包括T-F掩蔽[10]和谱映射[11],一般侧重于处理STFT幅度而忽略相位信息,只利用噪声信号的STFT相位进行时域信号重构。因此,增强的幅度和噪声相位之间的不匹配很可能导致无效的短时傅立叶变换和不一致的谱图[12]。显然,这种无效的STFT问题会在合成信号中造成不希望看到的伪影和令人不快的信号失真。
作为克服上述问题的一种方法,最近的一些研究探索了用于时域频谱增强的深度学习。例如,生成性对抗网络(GAN)[13,14]和WaveNet[15]随后被应用于语音增强任务。但这些方法大多以带噪语音的时间框架作为输入,并不能以话语的方式进行语音增强。为了解决这一问题,一些研究人员将全卷积神经网络(FCN)应用于语音增强[16,17],因为FCN模型只由卷积层组成[18],卷积运算中的滤波器可以接受长度可变的输入,但是语音信号的潜在特征在T-F域比在时域更能与背景噪声区分开来。因此,我们认为将频域知识集成到时域神经网络中可以有助于语音增强的核心任务。[19]也证明了用频域损耗代替时域损耗可以提高时域增强性能。
基于上述考虑,我们提出了一种新颖有效的基于傅立叶层的门控卷积神经网络(FLGCNN),用于端到端的单声道频谱增强。该模型框架可以看作是时间卷积神经网络(TCNN)[17]的扩展,它主要由编码器、解码器和时间卷积模块(TCM)[20]组成。编码器创建输入噪声信号的低维表示,而解码器的目标是重构增强的语音信号。在编码器和解码器之间插入TCM,以帮助网络更好地学习过去的远程依赖关系。但与TCNN不同的是,为了在神经网络中模拟STFT和ISTFT,在编码器和解码器中分别增加了基于卷积的STFT(CSTFT)层和逆STFT(CISTFT)层。因此,频域知识可以集成到时域框架中,同时避免了无效的STFT问题。此外,我们还应用门控线性单元(GLU)来构造编码器和解码器的门控卷积层和反卷积层。与LSTM(Long-Short-Term Memory)模型类似,GLU扮演着控制信息在层次中传递的角色,这种特殊的门控机制允许通过加深层次来有效捕获长期上下文依赖,而不会出现梯度消失问题。
基于此处理结构,我们进一步利用均方误差(MSE)、比例不变源失真比(SI-SDR)和短时目标可解性(STOI)定义的三种不同的基于话语的目标函数对模型进行优化。众所周知,增强算法中最常用的损失函数是均方误差损失(MSE loss),但对于基于深度学习的语音增强系统来说,模型优化与评估准则之间恰恰存在不匹配的问题。没有将评价指标作为目标函数的原因可能是,实现这些指标通常需要整个干净/增强的语音表达。然而,传统的基于频域的方法通常对幅度谱图进行处理,并需要进行大量的预处理和后处理,如分帧、短时傅立叶变换、重叠叠加法等。其他波形增强算法,包括GAN和WaveNet仍然以帧为基础的方式处理噪声波形。相反,基于FCN的端到端增强方法使得直接优化评估指标成为可能,因此我们也使用另外两个基于指标的目标函数对所提模型进行训练,以探讨其对增强性能的影响。
本文的其余部分组织如下。我们在第二节介绍单耳语音增强问题。在第3节中,我们描述了相关的模块,然后详细介绍了所提出的模型。基于话语的训练目标在第4节给出。实验和比较在第5节中提供。最后,第六节总结了本文。
2 问题表述
3 系统描述
在这项工作中,我们提出了一个全卷积神经网络,它由一系列门控卷积层和TCM组成,在时域增强语音。我们首先简要回顾TCM的体系结构和门控机制。进一步,我们介绍了设计的CSTFT层和CSTFT层,并展示了所提出的模型FLGCNN的细节。
3.1 时间卷积模块(TCM)
在序列建模任务[20]中,首先提出时间卷积网络(TCN)替代循环神经网络(RNN),将因果和扩张卷积层(如图1所示)以及残差连接[22]整合在一起。因果卷积保证了信息不会从未来泄露到过去,而扩张卷积有助于增加感受野。
受时间序列网络的启发,文献[17]提出了类似的由所示的残差块叠加而成的调制方式。每个残差block由3个卷积组成:输入1*1卷积、深度(depthwise)卷积和输出1*1卷积。输入卷积用于使输入通道数增加一倍,输出卷积的目的是使输入通道数恢复到原来的通道数,从而使输入和输出的相加能够兼容。为进一步减少参数个数,采用深度可分离卷积和逐点1*1卷积相结合的方法代替标准卷积。此外,输入卷积和中间卷积之后是PReLU[23]非线性激活函数和批量归一化[24]。

图2 残差时间卷积模块的结构
3.2 门控线性单元
门控机制的设计首次是为了促进RNN[25]中信息随时间的流动,其中引入了输入门和遗忘门[26],以允许长期记忆。在没有这些门的情况下,信息很容易在每个时间步[27]的变换中消失,从而产生消失或爆炸梯度问题。出于这些动机,卷积模型中考虑了输出门,以帮助控制哪些信息应该通过层次结构传播。在[28]中,Oord等人展示了一种LSTM风格的机制对图像卷积建模的有效性:
$$公式3:begin{aligned}
mathbf{y} &=tanh left(mathbf{x} * mathbf{W}_{1}+mathbf{b}_{1}right) odot sigmaleft(mathbf{x} * mathbf{W}_{2}+mathbf{b}_{2}right) \
&=tanh left(mathbf{v}_{1}right) odot sigmaleft(mathbf{v}_{2}right)
end{aligned}$$
其中$v_1=x*W_1+b_1$,$v_2=x*W_2+b_2$。$*$表示卷积算子。$sigma $表示sigmoid函数,$odot $表示逐元素乘法。如式(3)所示,门控切分单元(GTU)的梯度为
$$公式4:begin{aligned}
nablaleft[tanh left(mathbf{v}_{1}right) odot sigmaleft(mathbf{v}_{2}right)right]=& tanh ^{prime}left(mathbf{v}_{1}right) nabla mathbf{v}_{1} odot sigmaleft(mathbf{v}_{2}right) \
&+sigma^{prime}left(mathbf{v}_{2}right) nabla mathbf{v}_{2} odot tanh left(mathbf{v}_{1}right)
end{aligned}$$
其中$tanh'(v_1),sigma'(v_2)in (0,1)$和素数符号表示微分。然而,由于降尺度因子$tanh'(v_1)$和$sigma(v_2)$的存在,梯度在分层过程中逐渐消失。为了跟踪这一问题,提出了一种简化的门控机制GLUs
$$公式5:begin{aligned}
mathbf{y} &=left(mathbf{x} * mathbf{W}_{1}+mathbf{b}_{1}right) odot sigmaleft(mathbf{x} * mathbf{W}_{2}+mathbf{b}_{2}right) \
&=mathbf{v}_{1} odot sigmaleft(mathbf{v}_{2}right)
end{aligned}$$
而GLU的梯度包含了一条路径$bigtriangledown v_1odot sigma (v_2)$,没有降尺度(downscaling):
$$公式6:nablaleft[mathbf{v}_{1} odot sigmaleft(mathbf{v}_{2}right)right]=nabla mathbf{v}_{1} odot sigmaleft(mathbf{v}_{2}right)+sigma^{prime}left(mathbf{v}_{2}right) nabla mathbf{v}_{2} odot mathbf{v}_{1}$$
由GLU构造的门控卷积层结构如图3所示,其主要不同于普通卷积层的是输出门$sigma (v_2)$来控制所传递的信息。通过堆叠门控卷积层,门控卷积神经网络(GCNN)已被证明在构建层次表示和捕获长程依赖关系[21]方面是有效的。本文采用二维门控卷积层(GConv2d)来构建编码器和解码器的主要框架。
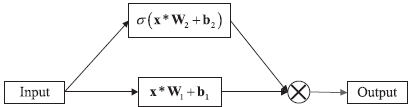
图3 门控(gate)卷积层的结构
3.3 基于卷积的STFT/ISTFT
如第1节所述,我们设计CSTFT/CISTFT层来执行伪STFT和伪ISTFT,从而将频率信息引入到基于时域的增强算法中。实际上,STFT和ISTFT操作是线性变换,通过将框架信号与复值离散傅里叶变换(DFT)矩阵D相乘,如下所示
$$公式7:x_f=Dx_t$$
其中$x_f$是有框信号$x_t$的DFT。由于$x_t$为实值,故式(7)中的关系可以改写为
$$公式8: mathbf{x}_{f}=left(mathbf{D}_{r}+j mathbf{D}_{i}right) mathbf{x}_{t}=mathbf{D}_{r} mathbf{x}_{t}+j mathbf{D}_{i} mathbf{x}_{t}$$
其中$D_r$和$D_i$是实值矩阵,由取D的实部和虚部形成,j表示虚单位。在Eq.(8)的激励下,CSTFT层由两个一维卷积实现,每个卷积的权值分别用STFT核的实部和虚部初始化,CSTFT层与此相似。这些模块是在正常的卷积层上构造的,因此很容易将这些模块集成到神经网络中。但应该注意的是,这些层并不等同于STFT/ISTFT操作。实际上,这些层优于STFT/ISTFT,因为权值通过反向传播是可学习的,而STFT/ISTFT的参数是固定的。
由于CSTFT/CISTFT层都是在卷积层上构造的,我们的模型可以通过从频域到时域的映射任务进行优化。在时域上,目标仍然是干净的语音信号,因此不会出现无效的短时傅立叶变换问题。
3.4 提出的模型
遵循上述方法和原则,我们设计了一个端到端的语音增强模型,该模型由编码器、解码器、TCM和CSTFT/CISTFT层组成,如图4所示。首先,CSTFT层的输入是噪声信号序列,其维数为1*L,其中L是采样点的数目。CSTFT层输出大小为2*T*257的伪STFT表示作为编码器的输入,其中T为帧数。
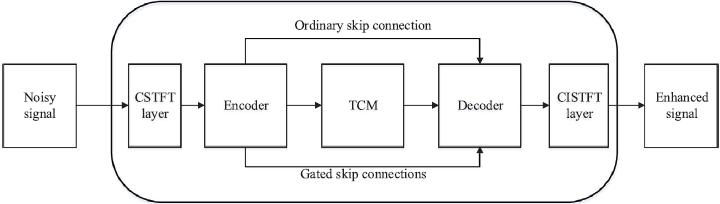
图4 提出的端到端语音增强模型的框架框图
编码器的第一层将通道数从2个增加到16个,第一层之后的输出尺寸为16*T*257。接下来堆叠的六个门控卷积层使用卷积相继减小沿频率维度的大小,并且编码器的最终输出为64*T*4。网络中的层都不修改沿时间维度的大小,使得输出具有与输入相同的帧数。编码器中的每一层都经过批归一化和PReLU((Parametric Rectified Linear Unit))非线性处理。
TCM对大小为256*T的编码器输出进行运算,并产生相同大小的输出。TCM有三个扩张块(dilation blocks)堆叠在一起。dilation blocks是由6个膨胀率呈指数增长的残差块叠加而成的。在dilation blocks中,残余块体的逐次扩张率分别为1、2、4、8、16和32。
解码器是编码器的镜像,由七个堆叠的门控转置反卷积层组成。与普通卷积层不同的是,门控卷积层有两个数据流。因此,不同于[17]中的跳过连接,我们的自动编码器有两种跳过连接:一种是与[17]中相同的普通连接,另一种是门控跳跃连接。在训练时,每2层应用0.2的dropout率。解码器中的每一层都经过批归一化和PReLU(Parametric Rectified Linear Unit)非线性处理。
表1给出了对网络参数的更详细的描述。编码器和解码器的超参数在filterHeight * filterWidth中指定(stride along frame, stride along frequency)。对于TCM,超参数的格式为filter_Height、dilation_Rate、output_channels,用小括号括起来的条目表示残留块。
与TCNN相比,本模型的优点有两方面。首先,CSTFT/ CISTFT层引入频域信息,帮助神经网络更好地增强语音,而TCNN仅利用时域样本。众所周知,语音信号的结构通常用短时傅立叶变换谱图来表示,而不是用时域的采样点来表示。频率bin的值也可以反映出相应频率分量的能量。其次,叠置的门控卷积层和编解码器中的两个数据流可以更好地控制在层次中传递的信息,学习长程上下文依赖关系,而TCNN的编解码器仅由普通的卷积层构造。
表1 提出的模型结构

4 基于话语的训练目标
端到端算法的一个好处是能够以话语方式优化模型。因此,目标函数可以为整个话语设计,而许多基于短时傅里叶变换的方法中的损失函数不能直接适用。在本节中,我们将介绍三个基于话语的训练目标。一种是均方误差损失,另一种是基于度量的损失函数。
4.1 MSE 损失
基于模型的语音增强方法的共同目标可以被认为是最小化以下目标函数:
$$公式9:O=||hat{s}-s||^{beta}$$
其中$beta $是一个可调参数,用于缩放距离。其中一种损失定义为干净语音和增强语音之间的MSE损失的平均值
$$公式10:O=frac{1}{L}|hat{mathbf{s}}-mathbf{s}|^{2}$$
其中$hat{s}in R^{1*L}$和$sin R^{1*L}$分别为估计的清洁源和原始清洁源。
然而,事实上,基于mse的目标函数只是简单地比较干净语音和增强语音之间的相似性。事实上,MSE与增强语音的评价标准之间存在着不一致性。例如,MSE值与人类听觉感知之间的关系仍然不是一个单调函数。原始信号、负信号和幅值偏移信号之间的均方误差(MSE)非常大,但这三个信号对人类听起来几乎是一样的。因此,有必要寻找与语音信号性能评价关系较强的损失函数。
4.2 SI-SDR损失
SI-SDR是由SDR指标发展而来的目标函数之一,它表征了增强语音[29]的整体失真。SDR值越高,说明增强语音的失真成分越少。SI-SDR定义为
$$公式11:left{begin{array}{l}
mathbf{s}_{text {target }}:=frac{langlehat{mathbf{s}}, mathbf{s}rangle mathbf{s}}{|boldsymbol{s}|^{2}} \
mathbf{e}_{text {noise }}:=hat{mathbf{s}}-mathbf{s}_{text {target }} \
mathrm{SI}-mathrm{SDR}:=10 log _{10} frac{left|boldsymbol{s}_{text {target }}right|^{2}}{left|mathbf{e}_{text {noise }}right|^{2}}
end{array}right.$$
其中$||s||^2=<s,s>$为信号功率。通过在计算之前将$hat{s}$和$s$归一化到零均值来保证尺度不变性。
4.3 基于感知损失
语音质量感知评估(PESQ)和STOI分数都是预测噪声或处理后语音可理解性的常用方法[32,33]。STOI值和PESQ值越高,说明语音清晰度和语音质量越好。但与PESQ相比,STOI计算中的大多数函数都是连续的,STOI比PESQ更能提高错误率[30,31]。所以在本文中,我们重点优化STOI测度,并简要描述了计算STOI的4个主要步骤:
1)T-F表示:将STFT应用于有噪声信号和干净信号,以获得相应的T-F表示,这些表示是类似于听觉系统的变换特性的简化内部表示。信号首先被分割成长度为256个样本的50%重叠的汉宁窗帧,然后执行傅立叶变换。注意到已通过排除相对于该最大清洁语音能量帧的清洁语音能量低于40dB的帧来去除无声区域。
2)三分之一倍频程频带分析:这是通过将短时傅立叶变换系数能量相加来近似的。设$S(k,m)$表示纯净语音第$m$帧的第$k$个T-F bin,则我们得到
$$公式12:S_{j}(m)=sqrt{sum_{k in C B_{j}}|S(k, m)|^{2}}, quad j=1,2, ldots, J$$
其中,j是三分之一倍频程指数,J通常设置为15。CBj表示与第j个三分之一倍频程频带相关的STFT系数的索引组。最低中心频率设置为150 Hz,最高中心频率为4.3 kHz左右。通过对频段进行分组,可以得到短时谱图向量
$$公式13:mathbf{s}_{j, m}=left[S_{j}(m-N+1), S_{j}(m-N+2), ldots, S_{j}(m)right]^{T}$$
通常,参数$N$被设置为30,其等于384 ms的分析长度。类似地,$hat{s}_{j,m}$表示增强语音的短时语谱图矢量。
3)归一化与裁剪:首先对$hat{s}_{j,m}$进行归一化处理,以补偿全局水平的差异;其次,将归一化后的$hat{s}_{j,m}$修剪为SDR的下界,使$hat{s}_{j,m}$表示归一化后修剪后的短时谱图向量。
4)清晰度度量:中间清晰度指数定义为两个时间包络之间的光谱相关系数。
$$公式14:d_{j, m}=frac{left(mathbf{s}_{j, m}-mu_{mathrm{s}_{j, m}}right)^{T}left(check{mathbf{s}}_{j, m}-mu_{tilde{s}_{j, m}}right)}{left|mathbf{s}_{j, m}-mu_{mathbf{s}_{j, m}}right|_{2}left|_{mathbf{j}, m}-mu_{tilde{s}_{j, m}}right|_{2}}$$
式中,$||·||_2$表示$L_2$范数,$mu _{(·)}$表示相应向量的样本量。最后,最终的STOI值简单地由所有帧和频段的中间可理解性指数的平均值给出:
$$公式15:mathrm{STOI}=frac{1}{J M} sum_{j, m} d_{j, m}$$
虽然STOI的计算有些复杂,但大部分计算是可微的,因此它可以作为我们的发音优化的目标函数,如下面的方程式所表示的:
$$公式16:O=-frac{1}{B} sum_{b} operatorname{stoi}left(hat{mathbf{s}}_{b}, mathbf{s}_{b}right)$$
其中,$hat{s}_b$和$s_b$分别是一批中的第b个估计话语和干净话语,而B是训练话语的批量大小。STOI是在给定干净的噪声/增强阻抗的情况下计算噪声/增强阻抗的STOI值的函数。在这项工作中,我们提出了一种综合了SI-SDR和STOI的客观函数,该函数可以由
$$公式17:O=-frac{1}{B} sum_{b}left(alpha cdot 10 log _{10} frac{left|mathbf{s}_{text {target }}right|^{2}}{left|mathbf{e}_{text {noise }}right|^{2}}-operatorname{stoi}left(hat{mathbf{s}}_{b}, mathbf{s}_{b}right)right)$$
其中,$alpha$是权重因子,它被简单地设置为一个小数字,以平衡两个目标的比例。由于$alpha$*SI-SDR值对最终损失函数的贡献远小于STOI值,我们认为具有Eq.(17)的训练模型主要还是为了提高STOI分数,所以我们将此损失函数命名为S-STOI。
5 实验
本节给出了一些实验结果和讨论。首先,考虑了实验中使用的数据和性能指标。其次,给出了不同增强模型和目标函数的比较结果。此外,给出了频谱图和波形供进一步分析。最后报告听力测试结果。
5.1 数据准备和评估指标
在本工作中,我们使用的所有干净的语音和噪声数据都来自华尔街日报(wsj)语料库[34]和Musan数据集[35]。从WSJ0训练集si_tr_s中随机选取7000个话语和2000个话语,生成包含40 h噪声信号和3.3 h验证数据的训练集。请注意,训练型演讲者与验证型演讲者是不同的。从Musan地区800种噪声中随机选取-6 dB、-3 dB、0 dB、3 dB三个信噪比等级的7种噪声对每个训练话语进行处理。类似地,每个验证话语都混合了从Musan的90个噪声中随机选择的2种类型的噪声。从si_dt_05和si_et_05中随机抽取1000个说话人的话语,从Musan数据集的其他39个不同信噪比的噪声中构建其中一种类型的测试集。所有干净的语音和噪声波形都被降至16khz。
在我们的实验中,我们使用STOI、PESQ和SDR分数来比较模型,这些分数都代表语音增强的标准指标[29,32,33]。STOI的典型取值范围为0 ~ 1,而PESQ的取值范围为-0.5 ~ 4.5。
5.2 训练细节
初始学习速率为1e-3或1e-4,这取决于模型的配置,如果连续3个阶段验证集的精度没有提高,初始学习速率将减半。Adam被用作优化器。为避免过度适应,最多可进行60个训练阶段。我们使用一个早期停止准则,即如果在10个阶段的验证集中没有损失改进,则停止训练。
5.3 实验结果
1)不同网络架构的比较:为了说明所提模型的有效性,实验将我们提出的模型(FLGCNN)与原始的TCNN[17]、TCNN与CSTFT层以及CSTFT层(FLTCNN)进行了比较。将这三种时域模型用于SI-SDR损失训练进行比较。结果如表2所示(为方便起见,我们在表2中略去了SDR单位dB)。
此外,我们还使用[19]中提出的频域损耗(TCNN-MAE)训练TCNN,其中损耗被定义为使用L2范数估计的STFT震级和干净的STFT震级之间的平均绝对误差(MAE)。然而,基于表2的结果,这种方法在端到端增强框架中不能很好地工作,特别是在信噪比较低的情况下,如-3 dB。
从表2中,我们可以看到TCNN和FLTCNN在这三个指标上都有很大的性能差距。如[17]所示,TCNN只是直接处理样本点。但是语音信号在T-F域中所表现出来的特征比在时域中更容易区分。FLTCNN得到的较好的结果表明,CSTFT层引入的频域信息确实有利于从噪声信号中提取语音成分。接下来,我们发现在三次测量中,FLGCNN的结果普遍优于FLTCNN的结果。由于FLGCNN和FLTCNN之间的关键区别是编码器和解码器中的门控卷积层,这意味着门控机制确实有助于语音增强。与其他网络相比,所提出的FLGCNN在SDR、STOI和PESQ测试数据集上得到了最显著的改进,表明FLGCNN体系结构在时域语音增强方面优于FLTCNN和TCNN。例如,在信噪比为-3 dB的情况下,与测试集中未处理的混合物相比,FLGCNN提高了SDR分数16.610,STOI分数0.218和PESQ分数1.059。
2)不同目标函数的比较:在这一部分中,我们将针对不同的目标函数,包括均方误差损失、SI-SDR损失和STOI损失,对所提出的模型进行实验。但在STOI缺失训练过程中,我们发现增强语音中出现了一些未知干扰成分,噪声没有得到很好的抑制。我们分析了这一现象有三个原因。首先,在STOI分数计算中不考虑非言语区域。其次,该模型的最高中心频率约为4.3 kHz,因此优化的STOI损耗使得模型忽略了较高频率区域。此外,由于STOI是由清晰语音和增强语音之间的相关系数定义的,因此最大化STOI值的解决方案不是唯一的。所以在这个实验中,我们使用S-STOI损失函数代替。表3中的结果也与我们的分析一致(为方便起见,我们省略了表3中的SDR单位dB)。
从表3中我们可以看出,采用SISDR目标函数训练的FLGCNN具有较高的SDR得分,较低的PESQ和STOI得分。但将目标函数由SI-SDR改为S-STOI时,增强语音的STOI和PESQ值均有较大提高,SDR值略有降低。众所周知,提高语音清晰度通常比提高更具挑战性的质量在较低信噪比条件下,即6 dB, 3 dB信噪比,但该模型优化结果S-STOI仍令人鼓舞:PESQ得分为1.18高于噪声信号,STOI分数为0.244高于噪声信号。通常,在所有信噪比条件下,具有MSE损失函数的增强语音的测量分数最低,这表明基于度量的损失函数比仅最小化干净语音和增强语音之间的MSE对提高测量分数有更显著的影响。
3)声谱图和波形对比:为了更好地说明,我们绘制了干净的WSJ0讲话的声谱图和波形图,以及在信噪比为-3 dB时被钟形噪声破坏的同样的讲话,如图4和图5(d)所示。图5(b)为经过SI-SDR丢失训练的FLGCNN增强语音的频谱图。此外,为了通过CSTFT和CISTFT层来证明准STFT和准ISTFT与正常的STFT和ISTFT是不同的,我们在FLGCNN中提取解码器的输出,并应用正常的ISTFT得到时域增强语音。相应的谱图如图5(e)所示。换句话说,我们用两种不同的方法处理相同的解码器输出:一种是通过CISTFT层的准ISTFT,另一种是原始的ISTFT。对比图5(e)和图5(e),我们发现CISTFT层不仅起到了ISTFT的作用,而且有效地去除了背景噪声,验证了CISTFT层的权值优于普通的基于学习和反向传播的ISTFT核。
对于感知优化的语音,我们分别使用原始STOI和S-STOI作为目标函数来训练我们提出的模型。从图5(e)和图5(f)中我们可以很容易地发现,与图5(f)中低频和中频成分的语音模式相比,高频成分的语音模式是无法识别的。这是因为在STOI计算中,1 / 3倍频带的最高中心频率约为4.3 kHz,这使得训练后的模型不关注高频区域,只是移动了大部分分量。此外,由于STOI计算中相关系数的解不是唯一的,所以得到的增强语音通常不是我们想要的。因此,使用S-STOI训练的FLGCNN增强语音的三项指标得分都高于仅使用STOI丢失函数训练的FLGCNN。
与图5(b)相比,我们可以看到图5(c)中安静区域存在更多的残差噪声。原因是,在计算STOI值之前,没有显示出语言活动的区域被删除了。所以在训练过程中,模型忽略了这些噪声实际存在的区域。因此,图5(c)所示的增强语音比图5(b)所示的SDR得分更低。在图5中绘制了相应的波形图和频谱图。虽然信号的特征在波形上不太容易区分,但我们仍然可以发现这些波形之间的差异。正如第一个红色块所标记的,所提出的技术(图5(b)和(c))比其他方法(图5(e))和(f)重建更好的语音结构。从图5(f)中第二个红色方块可以看出,在波形的末端仍然存在残余噪声。因此,时域波形的这些差异也验证了所提出的FLGCNN的优点。
4)主观评价:在这一部分中,我们通过主观测试来评价所提出的FLGCNN在语音增强任务中的性能。15名听力正常的受试者(9名男性和6名女性)参加了听力测试。实验是在一个安静的环境中进行的,刺激被播放在一个舒适的听力水平。每个被试共参与8个测试条件,每个条件包含7个句子:1个信噪比等级* 1噪声类型* 7种增强方法,即:noisy、TCNN- mae、TCNN、FLTCNN、FLGCNN(SISNR)、FLGCNN(MSE)、FLGCNN(S-STOI)。由于人类的听觉系统对0 dB和3 dB以下的噪声是鲁棒的,我们只选择较低的信噪比(-6 dB和-3 dB)。这些条件的顺序是随机为每个受试者选择的。听者被允许重复刺激两次,然后用电脑键盘上的字母和数字键做出回应。在每个测试条件下,基于正确识别的单词数与总单词数的比值,计算单词正确率(WCR)来评价语音清晰度。为了评估演讲质量,研究人员要求受试者用李克特五分制量表(1:差,2:差,3:一般,4:好,5:极好)对演讲质量进行评分。
图6为听力测试MOS平均成绩和WCR平均成绩。我们可以观察到,与噪声语音相比,所提出的FLGCNN增强语音的质量和清晰度有了很大的提高。此外,S-STOI和SI-SDR优化的FLGCNN获得了更高的MOS和WCR分数,这表明这两种测量方法确实有助于提高语音质量和可理解性。
6 结论
本文提出了一种基于FCN体系结构的端到端单耳语音增强模型。该框架可以看作是TCNN的一个改进版本,但同时解决了几个问题。1)通过设计CSTFT和CSTFT层,将频域信息集成到端到端模型中,有助于模型更好地从噪声信号中探索语音特征。2)编码器和解码器设计在门控卷积上,以更好地控制在层次结构中传递的信息。此外,所提出的编码器-解码器比一般的自动编码器多了一个门控跳跃连接。3)基于话语的语音增强模型可以解决优化目标函数与评价测度之间的不匹配问题。因此,我们使用基于话语丢失的训练模型,并对三个不同的目标函数进行比较。表2的实验结果验证了CSTFT/CISTFT层和门控卷积的有效性,表3的结果证明了基于度量的损失函数可以大大提高度量分数。进一步的研究方向是探索如何将所提出的模型应用于实时任务。
信用作者贡献声明
朱媛媛:概念化、方法学、软件、验证、形式分析、调查、资源、数据整理、写作——初稿、写作——回顾编辑。
徐徐:写作——初稿,写作——复习编辑、形式分析。
叶中富:写作-初稿,监督,项目管理,资金获取。
竞争利益声明
作者声明,他们没有已知的可能影响本文报告的工作的竞争财务利益或个人关系
感谢
基金资助:国家自然科学基金资助项目(No. 61671418)。
参考文献
[1] Loizou PC. Speech enhancement: theory and practice. Boca Raton, FL, USA: CRC; 2013.
[2] Boll SF. Suppression of acoustic noise in speech using spectral subtraction. IEEE Trans Acoust Speech Signal Process 1979;27(2):113 20.
[3] Lim JS, Oppenhenlim AV. Enhancement and bandwidth compression of noisy speech. Proc IEEE 2005;67(12):1586 604.
[4] Ephraim Y, Malah D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans Acoust Speech Signal Process 1984;32(6):1109 21.
[5] Sigg CD, Dikk T, Buhmann JM. Speech enhancement using generative dictionary learning. IEEE Trans Audio Speech Lang Process 2012;20 (6):1698 712.
[6] Luo Y, Bao G, Ye Z. Supervised monaural speech enhancement using complementary joint sparse representations. IEEE Signal Process Lett Feb. 2016;23(2):237 41.
[7] Fu J, Zhang L, Ye Z. Supervised monaural speech enhancement using two-level complementary joint sparse representations. Appl Acoust Mar. 2018;132:1 7.
[8] Kwon K, Shin JW, Kim NS. NMF-based speech enhancement using bases update. IEEE Signal Process Lett Apr. 2015;22(4):450 4. [9] Wang D, Chen J. Supervised speech separation based on deep learning: an overview. IEEE/ACM Trans Audio Speech Lang Process 2018;26:1702 26.
[10] Wang Y, Narayanan A, Wang D. On training targets for supervised speech separation. IEEE/ACM Trans Audio Speech Lang Process 2014;22(12):1849 58.
[11] Xu Y, Du J, Dai L, Lee C. An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process Lett Jan. 2014;21(1):65 8.
[12] Gerkmann T, Krawczyk-Becker M, Roux JL. Phase processing for single-channel speech enhancement: history and recent advances. IEEE Signal Process Mag Mar. 2015;32(2):55 66.
[13] Pascual S, Bonafonte A, Serra J. Segan: speech enhancement generative adversarial network, arXiv preprint arXiv: 1703. 09452, 2017..
[14] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks, arXiv preprint arXiv:1406.2661, 2014..
[15] Rethage D, Pons J, Serra X. A Wavenet for speech denoising, arXiv preprint arXiv:1706.07162, 2018..
[16] Fu S, Tsao Y, Lu X, Kawai H. Raw waveform-based speech enhancement by fully convolutional networks. In: Proc Asia, Pac. signal inf. process. assoc. annu. summit conf.; 2017. p. 6 12..
[17] Pandey A, Wang D. TCNN: temporal convolutional neural network for realtime speech enhancement in the time domain. In: IEEE int. conf. acoustics speech and signal processing (ICASSP); 2019. Brighton, United Kingdom, 2019, pp. 6875 6879..
[18] Long J, Shelhamer E., Darrell T. Fully convolutional networks for semantic segmentation. In: Proc. IEEE conf. comput. vision pattern recogn; 2015. pp. 3431 3440..
[19] Pandey A, Wang D. A new framework for CNN-based speech enhancement in the time domain. IEEE/ACM Trans Audio Speech Lang Process 27:7;2019. 1179 1188.
[20] Bai S, Kolter JZ, Koltun V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling, arXiv preprint arXiv:1803.01271, 2018..
[21] Dauphin YN, Fan A, Auli M, Grangier D. Language modeling with gated convolutional networks, arXiv preprint arXiv:1612.08083, 2017..
[22] He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition, arXiv preprint, arXiv:1512.03385, 2015..
[23] He K, Zhang X, Ren S, Sun J. Delving deep into rectifiers: surpassing humanlevel performance on Imagenet classification. In: Proc. int. conf. computer vision; 2015. p. 1026 1034.
[24] Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariance shift. In Int. conf. mach. learn.; 2015. p. 448-456.
[25] Horeiter S, Schmidhuber J. Long short-term memory. Neural Comput 1997;9 (8):1735 80. [26] Gers FA, Schmidhuber J, Cummins F. Learning to forget: continual prediction with LSTM. Neural Comput 12:10;2000. p. 2451 2471.
[27] Pascanu R, Mikolov T, Bengio Y. On the difficulty of training recurrent neural networks. In: Proc. int. conf. mach. learn.; 2013. p. 1310 1318.
[28] van den Oord A, et al. Conditional image generation with pixelcnn decoders. In: Proc. adv. neural inf. process. syst.; 2016. p. 4790 4798.
[29] Vincent E, Gribonval R, Fevotte C. Performance measurement in blind audio source separation. IEEE Trans Audio Speech Lang Process 2006;14(4):1462 9.
[30] Moore A, Parada PP, Naylor P. Speech enhancement for robust automatic speech recognition: evaluation using a baseline system and instrumental measures. Comput Speech Lang Nov. 2016;46:574 84.
[31] Thomsen DA, Andersen CE. Speech enhancement and noise-robust automatic speech recognition. Aalborg, Denmark: Aalborg Univ; 2015.
[32] Perceptual evaluation for speech quality (PESQ), and objective method for endto- end speech quality assessment of narrowband telephone networks and speech codesc, ITU, ITU-T Rec. P. 862, 2000.
[33] Taal CH, Hendriks RC, Heusdens R, Jensen J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans Audio Speech Lang Process 2011;19(7):2125 36.
[34] Hershey JR, Chen Z, Le Roux J, Watanabe S. Deep clustering: discriminative embeddings for segmentation and separation. IEEE int. conf. acoustics speech and signal processing (ICASSP) 2016:31 5.
[35] Snyder D, Chen G, Povey D. Musan: a music, speech, and noise corpus, arXiv preprint arXiv:1510.08484, 2015..
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


