
一、prometheus和grafana 简介
prometheus最早是由谷歌研发的一款开源的监控软件,主要开发语言为go,代码目前已经贡献给了apache 基金会托管,受欢迎的程度非常高,github地址为:https://github.com/prometheus/。
监控通常可以分为白盒监控和黑盒监控。
- 白盒监控:一般是指通过监控应用程序内部的运行状态及相应的指标来判断可能会发生的问题,从而提前做出预判或者对应用程序进行相关优化。
- 黑盒监控:监控系统或服务的运行状态,比如报错、超时等,在发生异常时做出相应处理措施。
prometheus的优势:
- 易于管理,通俗易懂,prometheus在使用时只有一个二进制的执行文件,安装非常简单,不依赖于任何别的应用。
- 能够轻易获取服务内部状态,比如jvm等。
- 高效灵活的查询语句,每秒可以处理百万级的监控指标
- 支持本地和远程存储,支持时序数据库
- 采用http协议,默认pull模式拉取数据,也可以通过中间网关push数据(需要安装push gateway)
- 支持自动发现(通过服务的方式进行自动发现待监控的目标,可以通过Consul实现服务发现)
- 可扩展,支持用户自定义开发
- 易集成,可以和grafana 快速集成。
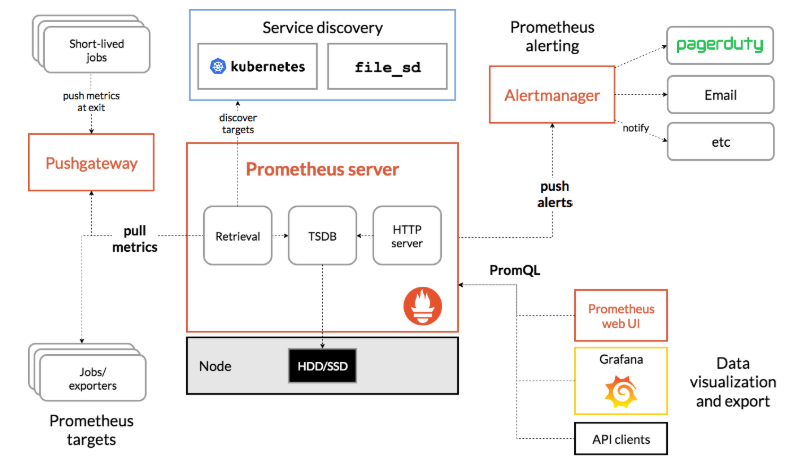
备注:此架构图摘自prometheus官方网站
prometheus根据配置定时可以去拉取各个节点的数据,默认使用的拉取方式是pull,当然也可以支持使用pushgateway提供的push方式去获取各个监控节点的数据。将获取到的数据存入TSDB(时序型数据库),pushgateway 就是 外部的应用可以将监控的数据主动推送给pushgateway,然后prometheus 自动从pushgateway进行拉取。此时prometheus已经获取到了监控数据,可以使用内置的PromQL进行查询。它的报警功能使用Alertmanager提供,Alertmanager是prometheus的告警管理和发送报警的一个组件。prometheus原生的图标功能由于过于简单,尤其是可视化的界面比较简单,因此建议将prometheus数据接入grafana,由grafana进行统一管理。
Grafana是开源的可视化监控、数据分析利器,支持多种数据库类型和丰富的套件,目前已支持超过50多个数据源,50多个面板,17个应用程序和1700多个不同的仪表图。(本文作者:张永清,转载请注明来源博客园:https://www.cnblogs.com/laoqing/p/14538635.html)
- 拥有快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方提供的库中包含了丰富的仪表盘插件,比如甘特图、热图、折线图、各种图表等多种展示方式。
- 支持许多不同的时间序列数据(数据源)存储后端。每个数据源都有一个特定查询编辑器。官方支持数据源:Graphite、infloxdb、opensdb、prometheus、elasticsearch、cloudwatch,mysql ,zabbix等。每个数据源的查询语言和功能有较大差异。可以将来自多个数据源的数据组合到一个仪表板上,但每个面板都要绑定到指定的数据源中,如下图所示。

- 告警允许将规则附加到仪表板面板上。保存仪表板时会将警报规则提取到单独的警报规则存储中,并安排它们进行评估。报警消息还能支持钉钉、邮箱等推送至移动端。
- 支持集成丰富多样的插件,也可以支持自定义的插件开发。
二、incubator-dolphinscheduler 简介
incubator-dolphinscheduler是一个由国内公司发起的大数据领域的开源调度项目,incubator-dolphinscheduler 能够支撑非常多的应用场景,包括:
- 以DAG图的方式将Task按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态
- 支持丰富的任务类型:Shell、MR、Spark、SQL(mysql、postgresql、hive、sparksql),Python,Sub_Process、Procedure,flink,datax,sqoop,http等
- 支持工作流定时调度、依赖调度、手动调度、手动暂停/停止/恢复,同时支持失败重试/告警、从指定节点恢复失败、Kill任务等操作
- 支持工作流优先级、任务优先级及任务的故障转移及任务超时告警/失败
- 支持工作流全局参数及节点自定义参数设置
- 支持资源文件的在线上传/下载,管理等,支持在线文件创建、编辑
- 支持任务日志在线查看及滚动、在线下载日志等
- 实现集群HA,通过Zookeeper实现Master集群和Worker集群去中心化
- 支持对
Master/Workercpu load,memory,cpu在线查看 - 支持工作流运行历史树形/甘特图展示、支持任务状态统计、流程状态统计
- 支持补数
- 支持多租户
- 支持国际化
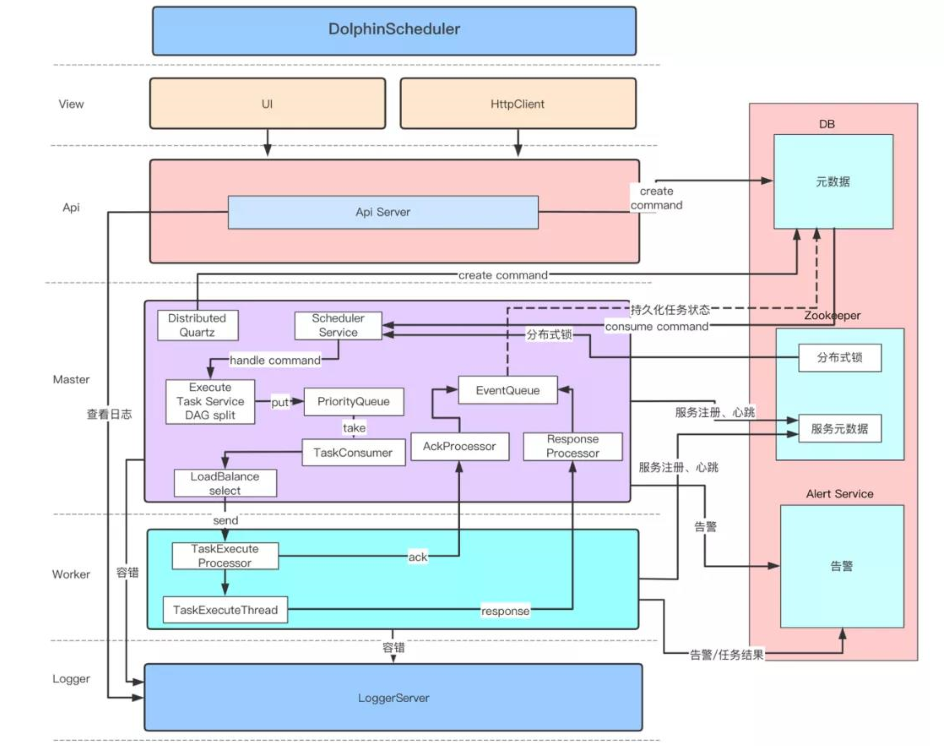
备注:此架构图摘自社区官方网站
三、incubator-dolphinscheduler 如何快速接入到prometheus和grafana 中进行监控
1、通过prometheus中push gateway的方式采集监控指标数据。
需要借助push gateway一起,然后将数据发送到push gateway 地址中,比如地址为http://10.25x.xx.xx:8085,那么就可以写一个shell 脚本,通过crontab调度或者incubator-dolphinscheduler调度,定期运行shell脚本,来发送指标数据到prometheus中。
#!/bin/bash failedTaskCounts=`mysql -h 10.25x.xx.xx -u username -ppassword -e "select 'failed' as failTotal ,count(distinct(process_definition_id)) as failCounts from dolphinscheduler.t_ds_process_instance where state=6 and start_time>='${datetimestr} 00:00:00'" |grep "failed"|awk -F " " '{print $2}'` echo "failedTaskCounts:${failedTaskCounts}" job_name="Scheduling_system" instance_name="dolphinscheduler" cat <<EOF | curl --data-binary @- http://10.25x.xx.xx:8085/metrics/job/$job_name/instance/$instance_name failedSchedulingTaskCounts $failedTaskCounts EOF
这段脚本中failedSchedulingTaskCounts 就是定义的prometheus中的一个指标。脚本通过sql语句查询出失败的任务数,然后发送到prometheus中。
然后在grafana 中就可以选择数据源为prometheus,并且选择对应的指标。
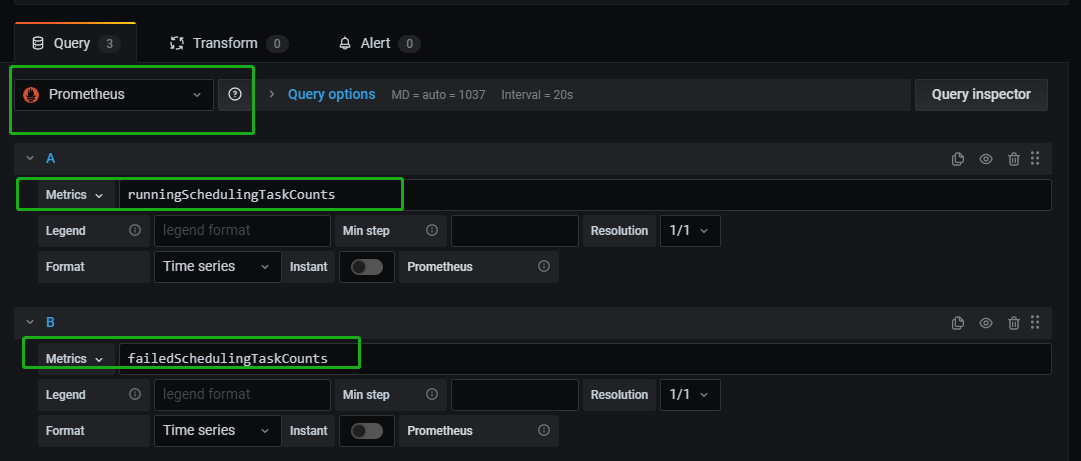
比如可以通过如下shell 脚本采集正在运行的任务数,然后通过push gateway 发送到prometheus中。(本文作者:张永清,转载请注明来源博客园:https://www.cnblogs.com/laoqing/p/14538635.html)
#!/bin/bash runningTaskCounts=`mysql -h 10.25x.xx.xx -u username -ppassword -e "select 'running' as runTotal ,count(distinct(process_definition_id)) as runCounts from dolphinscheduler.t_ds_process_instance where state=1" |grep "running"|awk -F " " '{print $2}'` echo "runningTaskCounts:${runningTaskCounts}"
job_name="Scheduling_system"
instance_name="dolphinscheduler" if [ "${runningTaskCounts}yy" == "yy" ];then runningTaskCounts=0 fi cat <<EOF | curl --data-binary @- http://10.25x.xx.xx:8085/metrics/job/$job_name/instance/$instance_name runningSchedulingTaskCounts $runningTaskCounts EOF
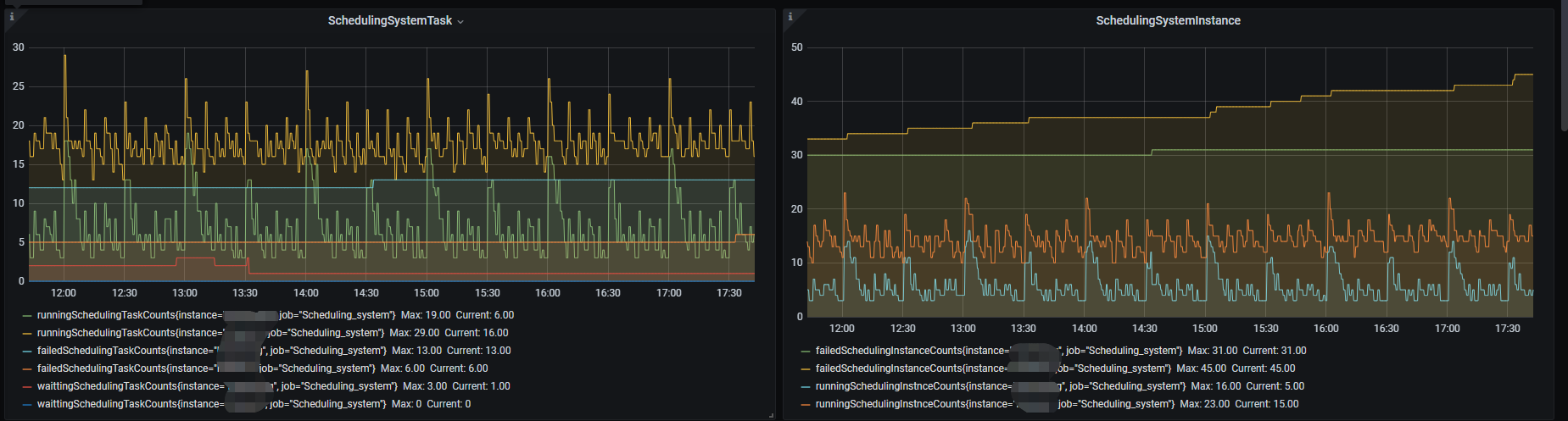
采集好了后,就可以达到如下的效果了,从这个图就可以看出每个采集到的指标随着时间的变化趋势了。
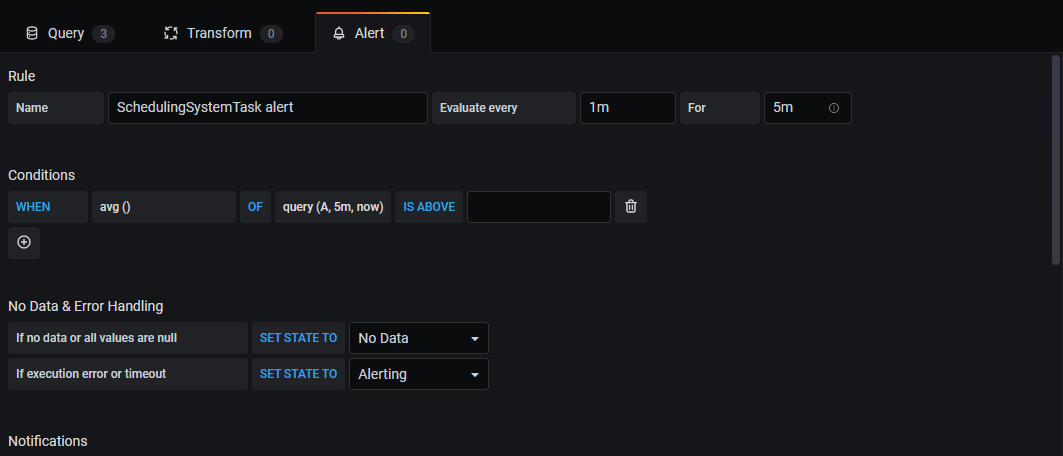
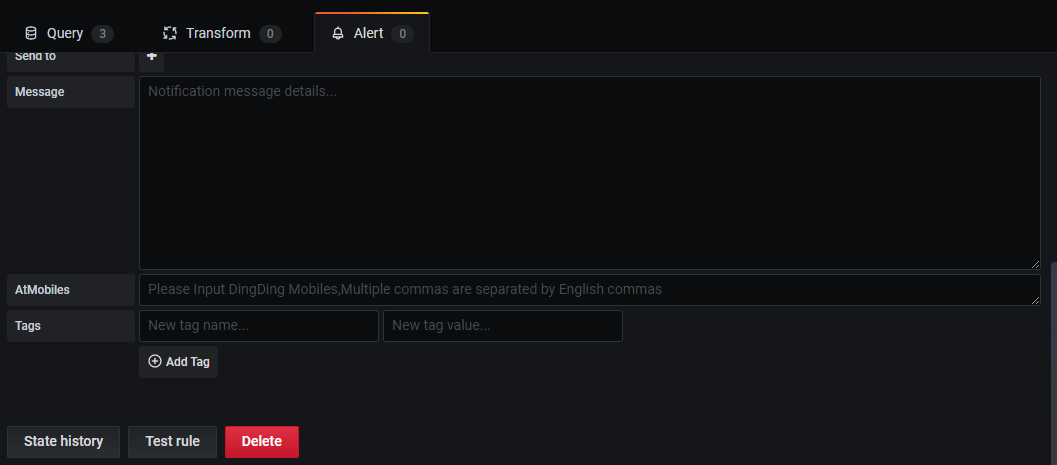
在配置好指标后,还可以配置该指标的告警,如下图所示,点击Create Alert 按钮,按照页面提示,即可以配置告警通知。
2、通过grafana 直接查询dolphinscheduler自身 的Mysql数据库(也可以是别的数据库)
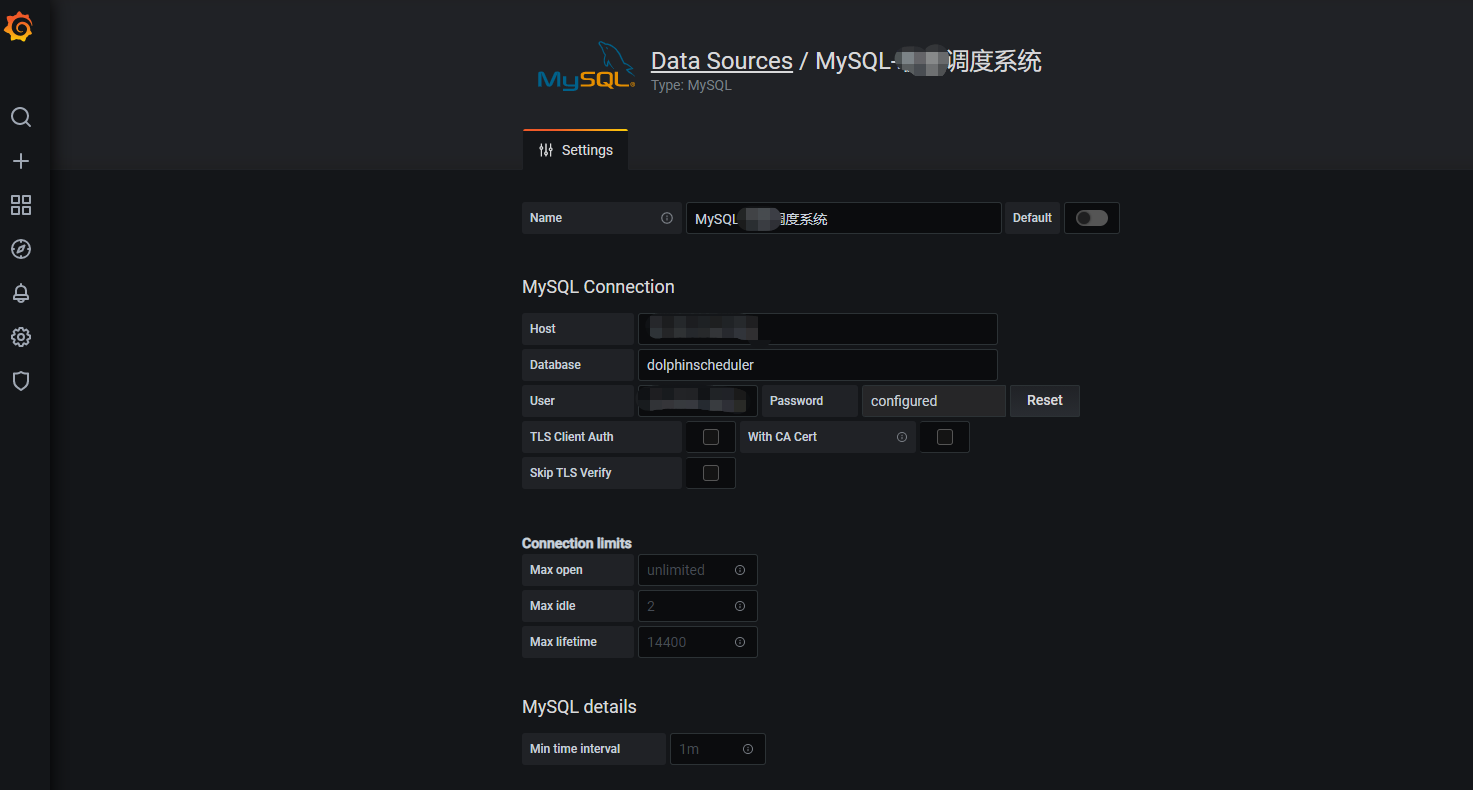
首先需要在grafana 中定义一个数据源,这个数据源就是dolphinscheduler自身 的Mysql数据库。
然后在grafana 中选择这个数据源,Format as 格式选择table,输入对应的sql语句。(本文作者:张永清,转载请注明来源博客园:https://www.cnblogs.com/laoqing/p/14538635.html)
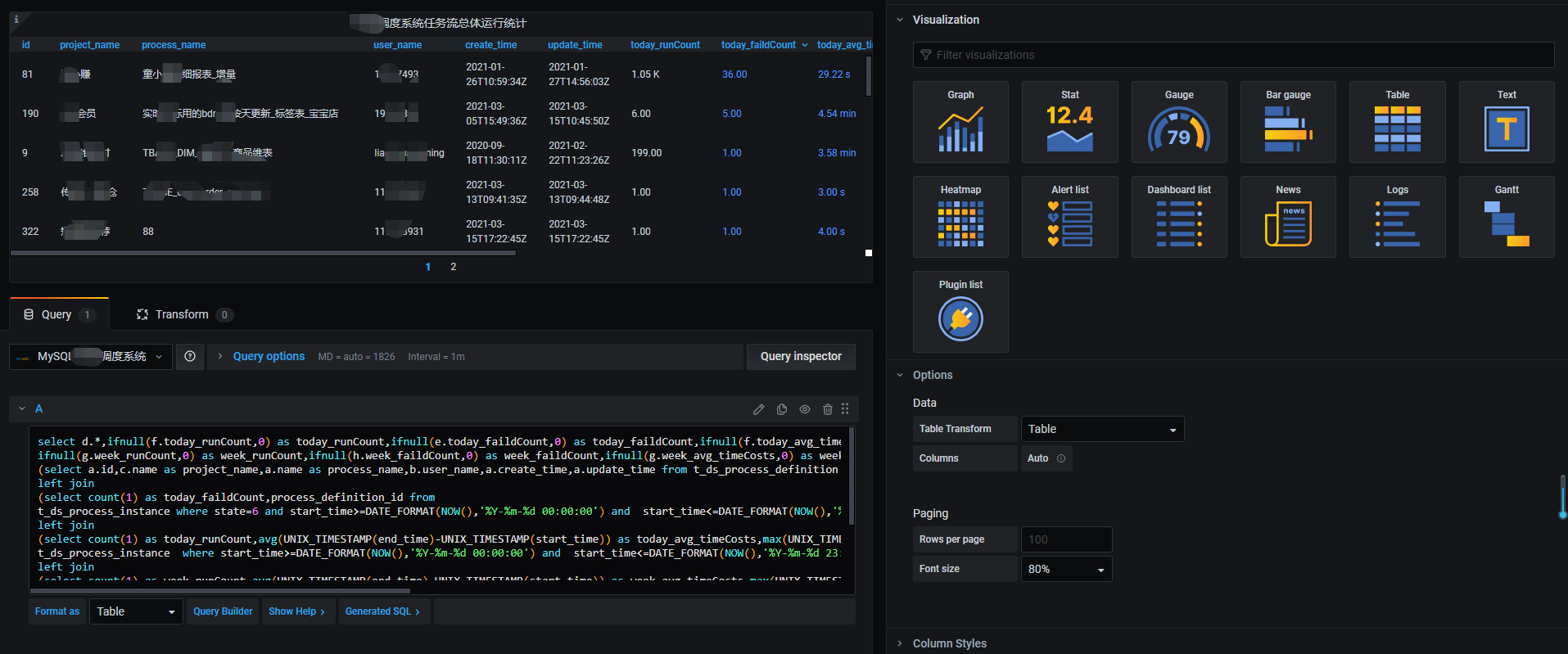
比如如下sql,统计本周以及当日正在运行的调度任务的情况。
select d.*,ifnull(f.today_runCount,0) as today_runCount,ifnull(e.today_faildCount,0) as today_faildCount,ifnull(f.today_avg_timeCosts,0) as today_avg_timeCosts,ifnull(f.today_max_timeCosts,0) as today_max_timeCosts, ifnull(g.week_runCount,0) as week_runCount,ifnull(h.week_faildCount,0) as week_faildCount,ifnull(g.week_avg_timeCosts,0) as week_avg_timeCosts,ifnull(g.week_max_timeCosts,0) as week_max_timeCosts from (select a.id,c.name as project_name,a.name as process_name,b.user_name,a.create_time,a.update_time from t_ds_process_definition a,t_ds_user b, t_ds_project c where a.user_id=b.id and c.id=a.project_id and a.release_state=$status) d left join (select count(1) as today_faildCount,process_definition_id from t_ds_process_instance where state=6 and start_time>=DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') group by process_definition_id ) e on d.id=e.process_definition_id left join (select count(1) as today_runCount,avg(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as today_avg_timeCosts,max(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as today_max_timeCosts,process_definition_id from t_ds_process_instance where start_time>=DATE_FORMAT(NOW(),'%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT(NOW(),'%Y-%m-%d 23:59:59') group by process_definition_id ) f on d.id=f.process_definition_id left join (select count(1) as week_runCount,avg(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as week_avg_timeCosts,max(UNIX_TIMESTAMP(end_time)-UNIX_TIMESTAMP(start_time)) as week_max_timeCosts,process_definition_id from t_ds_process_instance where start_time>=DATE_FORMAT(SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-1), '%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT(SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-7), '%Y-%m-%d 23:59:59') group by process_definition_id ) g on d.id=g.process_definition_id left join (select count(1) as week_faildCount,process_definition_id from t_ds_process_instance where state=6 and start_time>=DATE_FORMAT(SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-1), '%Y-%m-%d 00:00:00') and start_time<=DATE_FORMAT( SUBDATE(CURDATE(),DATE_FORMAT(CURDATE(),'%w')-7), '%Y-%m-%d 23:59:59') group by process_definition_id ) h on d.id=h.process_definition_id
这些配置完后,保存就可以得到如下的表格:(本文作者:张永清,转载请注明来源博客园:https://www.cnblogs.com/laoqing/p/14538635.html)
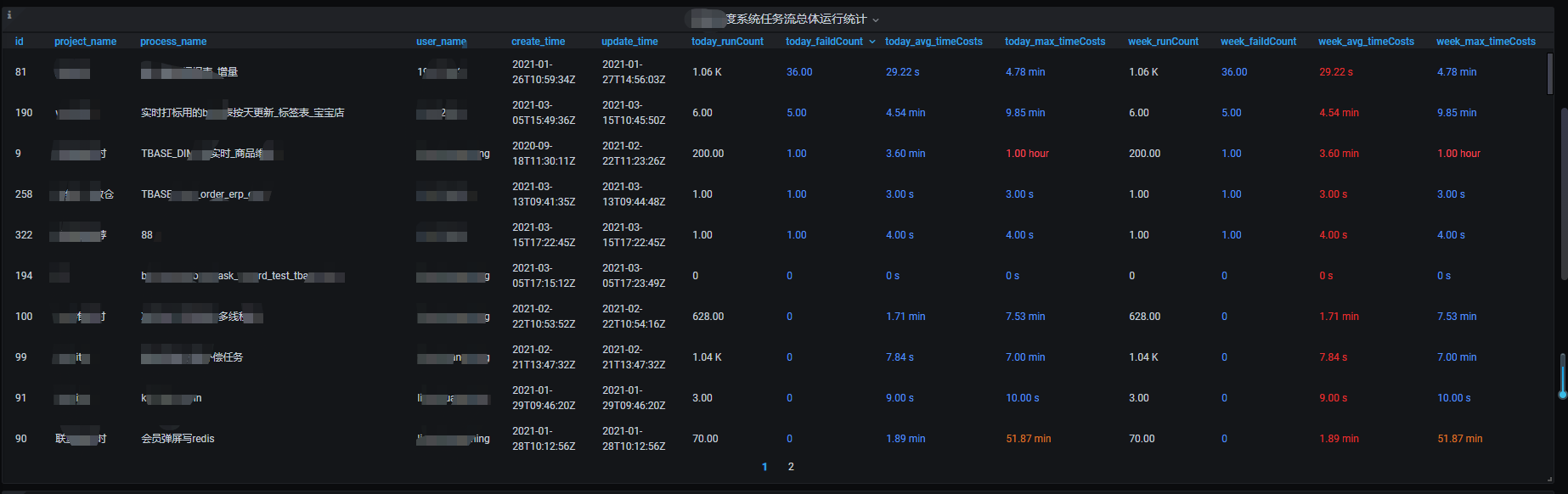
还可以支持甘特图等多种图,此处不再一一介绍了。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


