alias grun='java -classpath .:/System/Volumes/Data/sdk/compilers/antlr4-4.8/antlr-4.8-complete.jar org.antlr.v4.gui.TestRig'
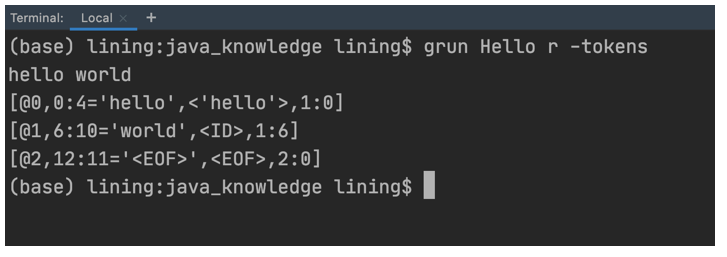
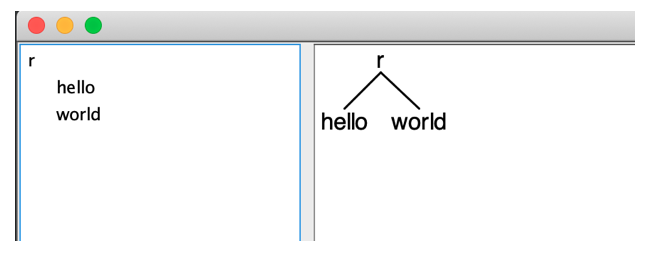
现在就可以使用grun测试我们的程序了。
首先要说明一点,grun测试的是.class文件,不是.java文件,所以在测试之前,要在终端中切换到.class文件所在的目录。Intellij IDEA CE默认的.class目录是out/production目录,如下图所示。在一开始,前面生成的.java文件并没有编译,读者可以随便找个Java程序运行下,这时Intellij IDEA CE会编译所有还没有编译的.java文件,我们会发现,刚才生成的所有.java文件都生成了同名的.class文件。
读者可以直接在操作系统的终端进入.class所在的目录,或者通过Intellij IDEA CE下方的Terminal也可以输入命令行,如下图所示。
grammar Calc;
// 下面是语法
prog: stat+ ;
stat: expr ';' # printExpr
| ID '=' expr ';' # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
// 下面是词法
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // 匹配标识符
INT : [0-9]+ ; // 匹配整数
WS : [ t]+ -> skip ; // 忽略空白符
NEWLINE:'r'? 'n' ; // 空行
现在生成Calc.g4 的相关文件。先看一下生成的CalcVisitor.java文件,代码如下:
import org.antlr.v4.runtime.tree.ParseTreeVisitor;
publicinterface CalcVisitor<T> extends ParseTreeVisitor<T> {
T visitProg(CalcParser.ProgContext ctx);
T visitPrintExpr(CalcParser.PrintExprContext ctx);
T visitAssign(CalcParser.AssignContext ctx);
T visitBlank(CalcParser.BlankContext ctx);
T visitParens(CalcParser.ParensContext ctx);
T visitMulDiv(CalcParser.MulDivContext ctx);
T visitAddSub(CalcParser.AddSubContext ctx);
T visitId(CalcParser.IdContext ctx);
T visitInt(CalcParser.IntContext ctx);
}
import java.util.HashMap;
import java.util.Map;
publicclass EvalVisitor extends CalcBaseVisitor<Integer> {
/** "memory" for our calculator; variable/value pairs go here */
Map<String, Integer> memory = new HashMap<String, Integer>();
boolean error = false;
/** ID '=' expr NEWLINE */// 初始化变量的操作(赋值操作) @Override
public Integer visitAssign(CalcParser.AssignContext ctx) {
String id = ctx.ID().getText(); // id is left-hand side of '='int value = visit(ctx.expr()); // compute value of expression on right
memory.put(id, value); // store it in our memoryreturn value;
}
/** expr NEWLINE */// 输出表达式的计算结果 @Override
public Integer visitPrintExpr(CalcParser.PrintExprContext ctx) {
Integer value = visit(ctx.expr()); // evaluate the expr child
System.out.println(value); // print the resultreturn 0; // return dummy value }
/** INT */// 将字符串形式的整数转换为整数类型 @Override
public Integer visitInt(CalcParser.IntContext ctx) {
return Integer.valueOf(ctx.INT().getText());
}
/** ID */
@Override
public Integer visitId(CalcParser.IdContext ctx) {
String id = ctx.ID().getText();
// 从Map中获取变量的值 if ( memory.containsKey(id) ) {
return memory.get(id);
} else {
// 引用了不存在的变量,输出错误信息
System.err.println(String.format("变量<%s> 不存在!",id));
error = true;
}
return 0;
}
/** expr op=('*'|'/') expr */// 计算乘法和除法 @Override
public Integer visitMulDiv(CalcParser.MulDivContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpressionint right = visit(ctx.expr(1)); // get value of right subexpressionif ( ctx.op.getType() == CalcParser.MUL ) return left * right;
return left / right; // must be DIV }
// 计算加法和减法/** expr op=('+'|'-') expr */
@Override
public Integer visitAddSub(CalcParser.AddSubContext ctx) {
int left = visit(ctx.expr(0)); // get value of left subexpressionint right = visit(ctx.expr(1)); // get value of right subexpressionif ( ctx.op.getType() == CalcParser.ADD ) return left + right;
return left - right; // must be SUB }
/** '(' expr ')' */// 处理括号表达式 @Override
public Integer visitParens(CalcParser.ParensContext ctx) {
return visit(ctx.expr()); // return child expr's value }
}
最后看一下主程序(MarvelCalc)的源代码。
import org.antlr.v4.runtime.ANTLRInputStream;
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import org.antlr.v4.runtime.tree.ParseTree;
import java.io.FileInputStream;
import java.io.InputStream;
publicclass MarvelCalc {
publicstaticvoid main(String[] args) throws Exception {
// 从文件读取源代码
String inputFile = null;
if ( args.length>0 ) {
inputFile = args[0];
} else {
System.out.println("语法格式:MarvelCalc inputfile");
return;
}
InputStream is = System.in;
if ( inputFile!=null ) is = new FileInputStream(inputFile);
CharStream input = CharStreams.fromStream(is);
CalcLexer lexer = new CalcLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
CalcParser parser = new CalcParser(tokens);
ParseTree tree = parser.prog(); // 分析源代码
EvalVisitor eval = new EvalVisitor();
eval.visit(tree);
}
}
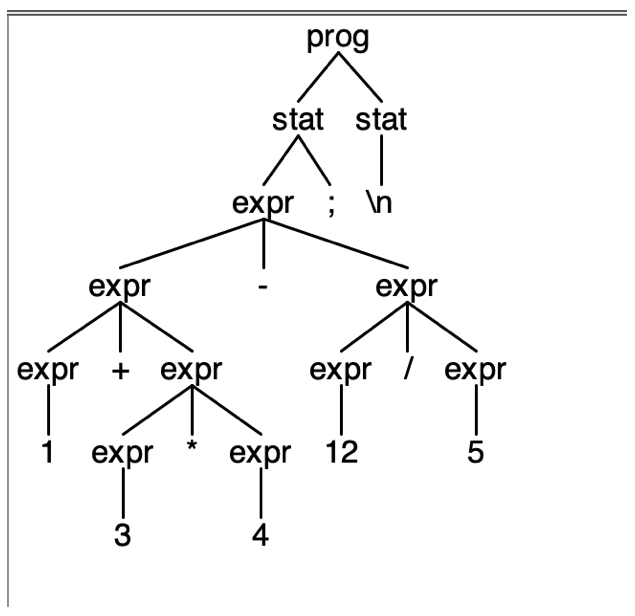
在expr.calc文件中输入下面的内容:
1+3 * 4 - 12 /6;
x = 40;
y = 13;
x * y + 20 - 42/6;
z = 12;
x + 5 * z - y;





 客服
客服


