
RUBi: Reducing Unimodal Biasesfor Visual Question Answering
Abstract
视觉问答(VQA)是回答有关图片的问题的任务。一些VQA模型通常利用单峰偏差来提供正确的答案,而不使用图像信息。因此,当对训练集分布之外的数据进行评估时,它们的性能会受到很大的影响,这一关键问题使它们不适合于现实世界的设置。
我们提出了一种新的学习策略RUBi来减少任何VQA模型中的偏差,它降低了最有偏差的例子的重要性,即不看图像就可以正确分类的例子。它隐隐地迫使vqa模型使用两种输入模式,而不是依赖于问题和答案之间的统计规律。我们利用一个纯问题模型,通过识别何时使用这些不需要的规则来捕捉语言偏见。它阻止了基线VQA模型通过影响其预测来学习它们。这导致动态调整损耗以补偿偏差。我们通过超过VQA-CP v2上的最新结果来验证我们的贡献。这个数据集是专门设计用来评估VQA模型的稳健性,当在测试时暴露于不同的问题偏见,而不是在训练中看到的。
Introduction
最近深度学习在计算机视觉和自然语言理解方面的成功使研究人员能够处理结合视觉和文本模态的多模态任务。在这些任务中,视觉问答 (VQA) 吸引了越来越多的关注。 VQA 任务的目标是回答有关图像的问题。 它需要对视觉场景和问题有高层次的理解,还需要在图像中建立文本概念并充分使用这两种模式。 解决 VQA 任务可能对现实世界的应用程序产生巨大影响,例如帮助视障用户了解他们的现实和网络环境,通过自然语言界面搜索大量视觉数据,甚至使用更高效、更直观的界面与机器人进行通信。
最近出现了几个大型真实图像 VQA 数据集。 它们中的每一个都针对 VQA 模型在实际环境中需要使用的特定能力,例如细粒度识别、对象检测、计数、活动识别、常识推理等。当前的端到端 VQA 模型在大多数这些基准测试中取得了令人印象深刻的结果甚至能够超越人类在特定基准上的准确度来解释成分推理。然而,已经表明他们倾向于利用答案出现和问题中的某些模式之间的统计规律 。 虽然它们旨在合并来自两种模态的信息,但在实践中,它们通常在不考虑图像模态的情况下进行回答。 当大多数香蕉是黄色的时候,模型不需要学习正确的行为来达到关于香蕉颜色的问题的高精度。 与查看图像、检测香蕉并评估其颜色相比,从将单词what、color 和bananas 与出现次数最多的答案yellow 联系起来的统计快捷方式中学习要容易得多。
量化每种模态的统计捷径数量的一种方法是训练单模态模型。 例如,在广泛使用的 VQA v2 数据集上训练的仅问题模型在测试集上大约 44% 的时间预测正确答案。 不鼓励 VQA 模型从问题模式中利用这些统计捷径,因为它们的训练集通常与它们的测试集遵循相同的分布。 然而,当在显示不同统计规律的测试集上进行评估时,它们的准确率通常会显着下降。不幸的是,这些统计规律在收集真实数据集时很难避免。 如下图所示,迫切需要开发新策略来减少来自问题模式的偏见数量,以便学习更好的行为。
我们的 RUBi 方法旨在减少训练期间 aVQA 模型学习到的单峰偏差量。 如图所示,当前的 VQA 模型通常依赖于问题和答案之间不需要的统计相关性,而不是同时使用这两种模式。
我们提出RUBi,一种训练策略来减少VQA模型学习到的偏差。我们的策略降低了最有偏见的例子的重要性,也就是说,不看图像模式就可以正确分类的例子。它隐含地迫使VQA模型使用两种输入模式,而不是依赖于问题和答案之间的统计规律。我们只在培训期间在基本VQA模型的上面添加了一个纯问题分支。该分支影响VQA模型,动态调整损耗以补偿偏差。结果是,通过VQA模型反向传播的梯度在大多数偏倚的例子中减小,而在偏倚较小的例子中增加。在培训结束时,我们只需删除“仅问题”分支。
我们在VQA-cpv2上进行了大量的实验,并证明RUBi在很大程度上超过了当前最先进的结果。该数据集专门设计用于评估VQA模型对问题模式偏差的鲁棒性。我们展示了我们的RUBi学习框架在几种VQA体系结构上的应用,如堆叠式注意网络和自顶向下自底向上注意。我们还表明,与减少模式偏差的方法相比,rubi在标准VQA v2数据集上具有竞争力。
Related work
真实世界的数据集由于其收集过程而显示出某种形式的固有偏差。 因此,机器学习模型往往会反映这些偏差,因为它们通常会捕捉到输入和真实注释之间不受欢迎的相关性。 现有程序可以识别某些类型的偏见并减少它们。 例如,一些方法侧重于性别偏见,其他一些方法侧重于人类报告偏见,以及实验室策划的数据和现实世界数据之间分布的变化 。 在语言和视觉环境中,一些作品评估单峰基线或利用语言先验。 下面,我们讨论评估和减少 VQA 模型学习的单峰偏差的相关工作。
评估数据集和模型中的单峰偏差
尽管VQA模型被设计用于合并两种输入模式,但已经发现VQA模型通常依赖于一种模式的输入和答案之间的表面相关性,而不考虑另一种模式。量化VQA模型可能学习到的单峰偏差量的有趣方法在于只使用两种模型中的一种来训练模型。仅问题模型是一个特别强大的基线,因为可以从问题模式中利用大量的统计规律。通过RUBi学习策略,我们利用这个基线模型来防止VQA模型学习问题偏差。
不幸的是,从一种模式中利用统计捷径的有偏模型通常在大多数当前基准上都能达到不错的准确性。 VQA-CP v2 和 VQA-CP v1最近被引入作为诊断数据集,其中包含训练和测试拆分之间每个问题类型的不同答案分布。 因此,偏向于问题模态的模型在这些基准上失败了。 我们广泛使用更具挑战性的 VQA-CP v2 数据集,以展示我们的方法减少来自问题模态的偏差学习的能力。
平衡数据集以避免单峰偏差
一旦确定了单峰偏差,克服这些偏差的一种方法是创建更平衡的数据集。 例如,VQA的合成数据集通过相关问题系列中的拒绝抽样来最小化问题条件偏差,以避免获得正确答案的简单捷径。
由于注释的成本,在真实的 VQA 数据集中进行拒绝采样通常是不可能的。 另一种解决方案是收集补充示例以增加任务的难度。 例如,引入了 VQA v2,通过识别互补图像来削弱 VQA v1 数据集中的语言先验。 对于给定的 VQA v1 问题,VQA v2 还包含对同一问题具有不同答案的相似图像。 然而,即使有了这种额外的平衡,问题中的统计偏差仍然存在并且可以利用。 这就是为什么我们提出一种方法来减少训练期间的单峰偏差。 它旨在从有偏见的数据集中学习无偏见的模型。 我们的学习策略会动态修改损失值以减少问题的偏差。 通过这样做,我们降低了某些示例的重要性,类似于拒绝采样方法,同时增加了已经在训练集中的补充示例的重要性。
减少单峰偏差的架构和学习策略
在这些先前关于平衡数据集的工作的同时,已经进行了一项重要的工作来设计VQA模型,以克服数据集的偏差 提出了一个手工设计的架构,称为接地VQAmodel(GVQA)。它将VQA的任务分解为第一步,即定位和识别回答问题所需的视觉区域,第二步,即基于纯问题分支确定合理答案的空间。这种方法需要分别训练多个子模型。相反,我们的学习策略是端到端的。他们复杂的设计并不能直接应用于不同的架构,而我们的方法是模型无关的。当我们只依赖一个问题branch时,我们会在培训结束时删除它。
在方法方面与我们最相关的工作是。 作者提出了一种学习策略来克服 VQA 模型中的语言先验。 他们首先引入了一个对抗性的 question-only 分支。它将来自 VQA 模型的问题编码作为输入并产生一个 question-only 损失。 他们使用此损失的梯度否定来阻止问题编码器捕获可能被 VQA 模型利用的不需要的偏差。 他们还基于 VQA 模型和仅问题分支输出分布之间的熵差异提出了一个损失。 这两个损失仅反向传播到问题编码器。 相比之下,我们的学习策略针对完整的 VQAmodel 参数,以更有效地减少不需要的偏差的影响。 我们不依赖这两个额外的损失,而是使用仅问题分支来动态调整分类损失的值,以减少 VQA 模型中偏差的学习。
Reducing Unimodal Biases Approach
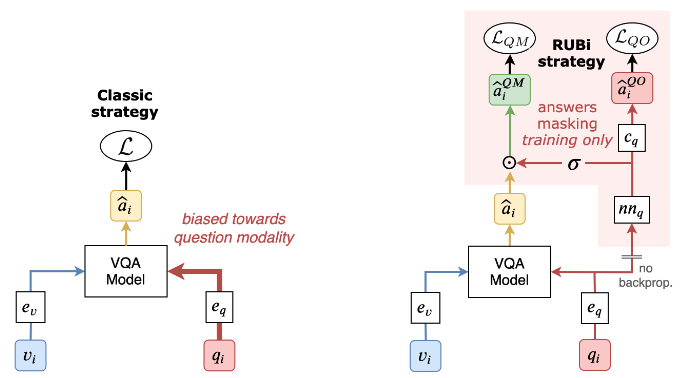
作者在本文中使用一个纯问题网络和一个主网络。
纯问题网络表示为:
其中(e_q())为问题的encoder,(nn_q())为纯问题的神经网络,(c_q())为分类层。(q_i)为问题输入。
主网络表示为:
其中(v_i)为图像特征输入,(q_i)为问题输入,(e_v())为图像特征的encoder,(e_q())为问题特征的encoder,(m())为多模态的融合(包括注意力机制),(c())为分类层。
主网络的损失函数可以表示为:
通过掩蔽预测防止偏差:
其中使用使用(f_{QM}(v_i,q_i))对主网络和(nn_q)进行反向传播,而使用(L_{QO}(theta_{QO};D))对纯问题网络中的去除问题encoder部分进行反向传播。
RUBi的损失函数分为两部分:
RUBi可以使得可以用偏见能够答出来的数据将损失变小,不能使用偏见打出来的数据的损失变大。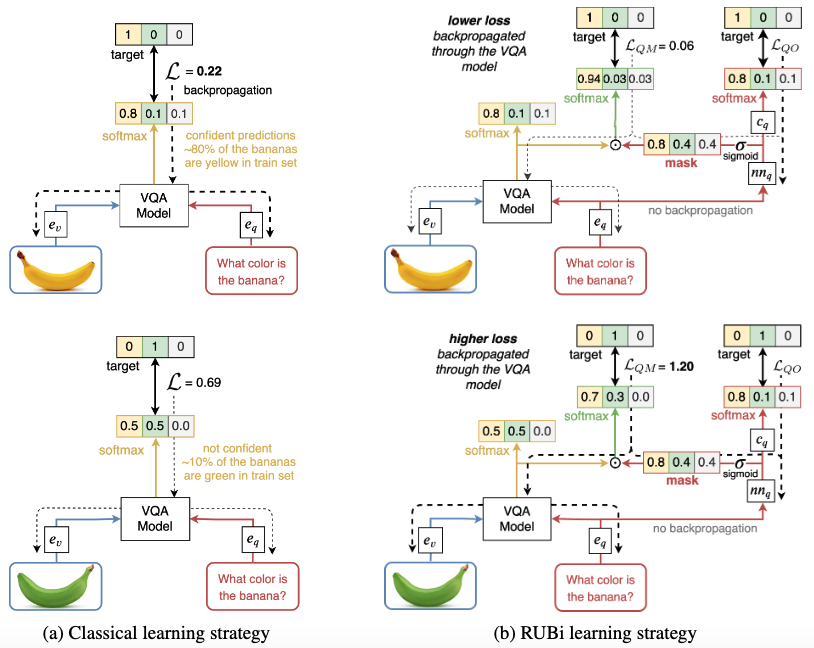
Experiments
作者通过比较最新的消除偏见模型在VQA-CP V2数据集上表现出有竞争力。
整合进入最新的其他VQA模型均能在VQA-CP v2数据集上有较大的提升。
以及在VQA v2数据集上并没有降低过多的性能。
并进行了定性分析。
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


