
Java生鲜电商平台-电商搜索引擎架构设计与大数据平台架构实践(小程序/APP)
说明:Java生鲜电商平台-电商搜索引擎架构设计与大数据平台架构实践,本文主要是讲解电商搜索引擎的设计以及大数据平台架构实战
电商搜索引擎,是帮助顾客快速找到需要购买的商品的工具,衡量一个电商搜索引擎是 否成功的标准是,顾客在一连串的搜索行为当中,是否越来越接近自己的真实需求。顾客越 快进入商品页面去浏览商品,越表明搜索引擎推荐的搜索结果越精确。电商搜索引擎,是传 统搜索引擎的一个垂直领域,为了更好地学习搜索引擎的相关知识,我们首先要看一个完整 的搜索引擎的技术架构。
一个完整的搜索引擎技术框架,如图 所示,搜索引擎的技术架构,分成 3 个部分
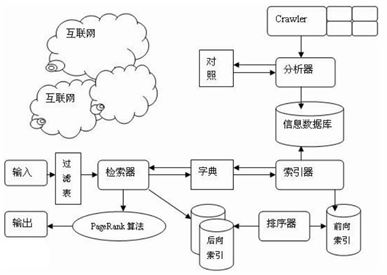
信息采集、建立索引库、提供检索服务,下面我们分别来探讨这 3 部分内容。
信息采集, 在互联网中发现、搜集信息和数据。通常, 这个步骤是通过爬虫
(Crawler/Spider)抓取网页来实现的。每个独立的搜索引擎都有自己的网页抓取程序爬虫。爬虫 Spider 顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页。被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
建立索引库,对收集到的信息进行提取和组织建立索引库。搜索引擎抓到网页后,还要 做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和 索引。根据应用场景的不同,其他可能的处理还包括去除重复网页、分词(中文)、判断网 页类型、分析超链接、计算网页的重要度/丰富度等。
提供检索服务,由检索器根据用户输入的查询关键字,提供检索服务。接受到关键词后, 系统在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序, 并将查询结果返回给用户。通常,为了用户便于判断,除了网页标题和 URL 外,还会提供一段来自网页的摘要及其他信息。
其实搜索已经是一项非常成熟的技术,这里不打算展开讨论了,只介绍几个在搜索技术 架构上比较重要的技术点:分布式索引、分布式搜索。
分布式索引,就是通过很多普通配置的硬件,同时进行索引建立的工作,最后进行索引 的合并操作。这样处理的好处在于,具备可扩展性,当数据增加的时候,无须增加单台机器的存储设备,而是通过水平扩展,增加配置普通的机器来解决。建立分布式索引,可采用
Hadoop 这类分布式系统进行构建,Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称 HDFS。HDFS 有高容错性的特点,并且设计用来部署在低廉的硬件上; 同时它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS 的上一层是 MapReduce 引擎,用于大规模数据集的并行运算。概念 Map(映射)和 Reduce(规约),和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。基于这些分布式特性,搜索索引建立可以非常容易地通过它来进行扩展。利用
Hadoop 的平台和 MapReduce 的机制,来实现建立分布式搜索索引,是非常好的实践。
分布式搜索,是将原来的单个索引文件划分成 n 个切片(shards)。搜索时,并行的搜索这 n 个切片,每个切片返回当前 shard 的 topK 命中结果;然后将 n 个切片的局部 topK 进行归并排序,得到全局的 topK 排序结果。分布式搜索的好处在于:更好的可扩展性,在用户访问次数和索引大小两个维度都具有水平扩展能力;更高的稳定性,容许部分失败,调用成功率显著提高;更灵活的全量更新策略,可针对不同类型的数据;更灵活的排序算法,可 以针对不同类目,做定制化的排序;更好的可维护性和通用性,支持不同类型的搜索。
大数据平台架构设计
近年来,大家对大数据的关注度和使用频率越来越高,软件产品中的各类数据都被记录 下来,以便更好地研究和分析。在电商企业中,每天系统记录下来的运营数据,达到几百
GB 增量的规模,为了保证所有数据能集中存储并且可随时访问,越来越多的企业把离线数据体系从商用的 Exadata 等解决方案,全面转向开放的 Hadoop 体系当中,以谋求成本与扩展性的平衡。
有一定技术实力的互联网公司,纷纷搭建自己的大数据平台,如图所示是一个典型
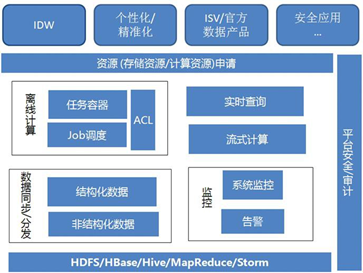
的大数据平台的技术架构,下面我们一起来学习。从图 可以看到,大数据平台是由数据存储、数据同步分发、监控、离线计算、平台安全、资源申请等部分构成的
数据存储,是整个大数据平台的基础,包含如:HDFS、HBase、Hive、MapReduce、
Storm 等等。下面,我们对其中的主要框架做些介绍,详细资料大家可以到搜索引擎中获取。
HDFS,分布式文件系统,Hadoop 的核心组成部分。
MapReduce,分布式数据处理,Hadoop 核心之一。
HBase,一个分布式的,列存储数据库,使用 HDFS 作为底层存储,同时支持 MapReduce
的批量式计算和点查询。
Zookeeper,一个分布式的,高可用的协调服务。提供分布式锁之类的基本服务,用于构建分布式应用。
Hive,分布式数据仓库,Hive 管理 HDFS 中存储的数据,并提供基于 SQL 的查询语言用以查询数据。
Hama,建立在 Hadoop 上的分布式并行计算框架,基于 Map/Reduce 和Bulk Synchronous
的实现框架,运行环境需要关联 Zookeeper、HBase、HDFS 组件。
Mahout,一个基于 MapReduce 的机器学习算法库,运行在 Hadoop 集群上。
Cassandra,一种混合的非关系型数据库,类似于 Google 的 BigTable。
以上就是数据存储层中,用到的一些开源数据框架,我们继续看大数据平台的其他组成 部分。
数据同步分发,这个组件对数据同步和分发做统一管理,可实现异步、分布式的数据同 步和分发。
监控,指的是对大数据平台的服务和资源,进行监控和预警,包括数据存储的可用性、 性能、系统负载、资源请求的响应时效等。
离线计算,处理离线计算任务的模块,包括任务容器、任务调度定时器、异常捕获等模 块,确保离线计算任务能够在资源容许的情况下,按计划运行。
平台安全,主要包括对数据访问权限的管理,把数据划分成不同的安全等级进行管理, 当访问某些安全级别高的数据时,会触发一个审批流程,经过主管审批后才能访问。
资源申请,指的是对大数据平台的计算或存储资源发起一个使用请求,这里会记录每一 个数据操作访问,以供日后审计。
结语
复盘与总结.
总结:
做Java生鲜电商平台的互联网应用,无论是生鲜小程序还是APP,电商搜索引擎架构设计与大数据平台架构实践是非常重要的,本文只是起一个抛砖引玉的作用,
希望用生鲜小程序的搭建电商搜索引擎架构设计与大数据平台架构实践实战经验告诉大家一些实际的项目经验,希望对大家有用.
QQ:137071249
共同学习QQ群:793305035
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


