
引言
R2CNN全称Rotational Region CNN,是一个针对斜框文本检测的CNN模型,原型是Faster R-CNN,paper中的模型主要针对文本检测,调整后也可用于航拍图像的检测中去。在ICDAR数据集上进行benchmark。
相关工作
paper中介绍了很多相关的针对斜框类型的文本目标识别所使用的模型,例如TextBoxes(端到端的单个神经网络实现)、DeepText(使用Inception-RPN生成候选框,然后对每个候选框进行文本检测的打分:即判别其是否是文本的概率,我的看法是可能是Faster R-CNN在文本目标识别中的魔改,但没阅读过相关论文不下定论)、FCRN(全卷积回归网络利用合成图像训练模型)。以上的模型都是针对水平框的。
接着还介绍了几种其他实现思路的模型,如CTPN(检测固定宽度的垂直框,使用BLSTM捕捉顺序信息,然后链接垂直框以获得最终检测框)、FCN(使用text block FCN检测文本块,使用MSER检测多种朝向的文本候选,最后进行候选文本的分类)、RRPN(基于Faster R-CNN,使用倾斜角来描述多种朝向的候选框,这个在DOTA数据集那篇文章中有介绍具体的表达方法)、SegLink(通过检测段然后对段进行连接,在任意长度的文本检测中这种模型表现很好)、EAST(加快检测速度)、DMPNet(用于生成更加贴合的文本框)、Deep direct regression(用于多种朝向的文本检测)。
作者模型的目标是检测出任意朝向的文本,类似于RRPN的目标,但实现思路有所不同。(作者认为RPN在生成候选文本方面表现很好,所以模型的设计思路是基于RPN生成的候选文本信息来生成文本候选框,而不是类似原始的Faster R-CNN将两个目标分离开来)。
问题描述
有趣的是,本文作者使用了一种不同于((x_1, y_1, x_2, y_2, x_3, y_3, x_4, y_4))和((x_1, y_1, x_2, y_2, theta))的候选框表达方式,而是使用了((x_1, y_1, x_2, y_2, h))。
其中四个点的表达方式所表达出来的框当然是最精确的,但是四个点的回归使得任务很难。而使用(theta)角的表达方式会出现(90^0)和(-90^0)的歧义问题。所以作者使用了第三种表达方式:首先选定初始点,然后选定其顺时针方向的下一个点,最后使用矩形的高度来表达出候选框,这种方法也能达到不错的效果。
模型方法
R2CNN模型的略图如下所示,RPN用于生成文本候选框(这时的候选框是水平的),然后对于每一个候选框,经过ROI池化层生成三种大小的特征图(7X7、11X3、3X11),经过两个全连接层生成最终的结果(三种结果:文本和非文本的得分情况、水平框预测和斜框预测),然后使用NMS算法得到最后的结果。
-
RPN
使用RPN生成水平预测框是合理的。因为总是有一些物体本身就是水平的或者竖直的,再或者可以被证明使用水平框识别它是很好的选择(原论文中的说法)。而且由于较小的文本场景更多,所以R2CNN将Faster R-CNN中的RPN设定的三种anchor的尺寸增加了一种,即将(8,16,32)改为(4,8,16,32)。
-
多尺度的ROIPoolings
从Faster R-CNN的7X7尺寸特征图,改为了三种尺寸(7X7,11X3,3X11)。其中3X11用于检测纵横比更大的文本类型,11X3用于检测纵横比更小的文本类型。
-
结果预测
文本检测是一个多任务模型,最后生成的三种结果:text/non-text scores, axis-aligned boxes and inclined minimum area boxes。
之所以要加入水平框的预测结果,是因为理想和实际实验中证明加入水平框的预测损失可以改善模型的性能。(考虑这一点是因为水平框和最终要预测的斜框是有一定关系的,可以作为斜框的一种强特征来看)。
-
NMS(非最大抑制)
通过NMS对水平框和斜框进行最后的筛选,最后得出的一个结果如下图所示。可以看出斜框在这种场景下相比水平框有很大的优势。
-
损失计算
paper中的损失计算公式如下:
[L(p,t,v,v^*,u,u^*) = L_{cls}(p,t) + lambda_1tsum_{iin{x,y,w,h}}L_{reg}(v_i, v_{i}^{*}) + lambda_2tsum_{iin{x,y,w,h}}L_{reg}(u_i, u_{i}^{*}) ]其中第一项就是判别是否为文本的损失,输出类别只有两种(是否为文本),第二项为水平框的回归损失,第三项为斜框的回归损失。(lambda_1)和(lambda_2)为可调整的系数,用以控制各部分损失之间的比例关系。
其中对于候选框的两部分损失的计算,均采用SmoothL1的方式。即:
[L_{reg}(w, w^*) = smooth_{L1}(w - w^*)\ smooth_{L1}(x) = left{ begin{aligned} 0.5x^2 qquad ifquad|x| < 1\ |x| - 0.5qquad otherwise end{aligned} right. ]
实验部分
-
实现细节
- 训练数据包括2000张聚焦场景文本图像和1000张附带场景文本图像,选用训练数据时仅仅选用了容易识别的数据样本,即不包括识别不出来具体文本内容或识别为”XXX“的数据。
- 训练数据时将每个数据进行旋转以得到单张图像的多个输入样例,实验中采用了13中旋转角(-90, -75, -60, -45, -30, -15, 0, 15, 30, 45, 60, 75, 90),共计39000张图像。
- 训练细节:共进行20w次迭代,学习率在迭代期间动态调整(每经过5w次迭代就将学习率翻倍)。正则化项设置为0.0005, momentums设置为0.9。输入图像的尺寸为:高720、宽1280。
-
性能表现
实验中使用了精确率、召回率、F-score和时间作为模型的评估量。
通过对比基线模型Faster R-CNN以及调整自己模型的几个超参数,来对比模型之间的效果。其中在ICDAR 2015数据集上的效果对比如下图所示:
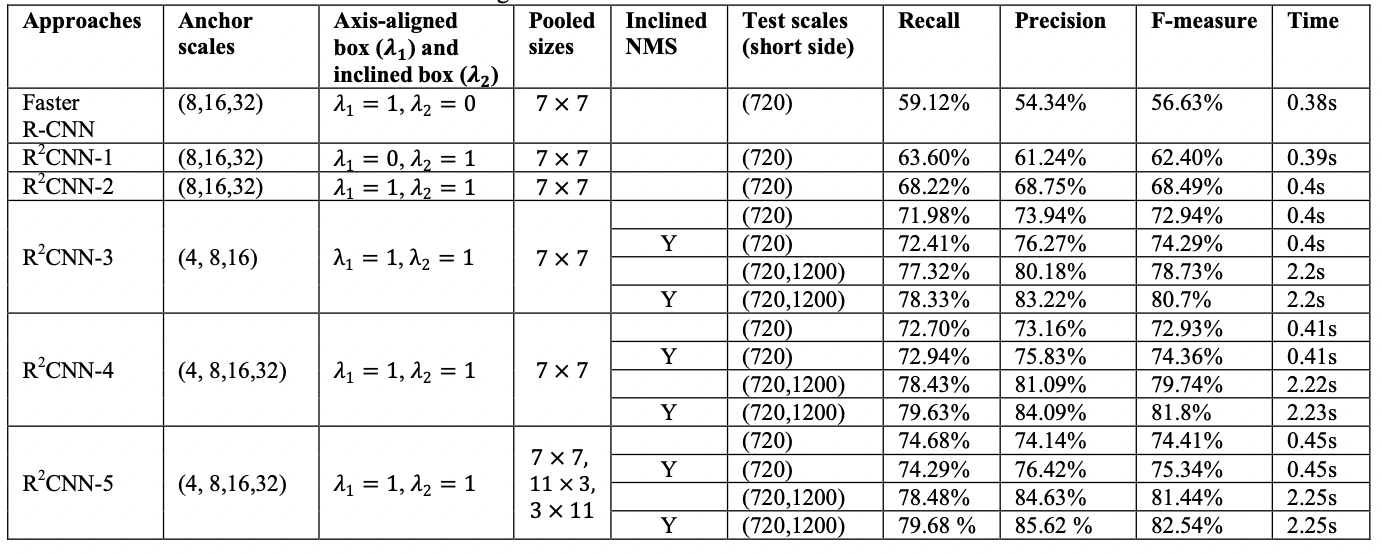
从表中可以看出,其中调整的超参数包括候选框大小(Anchor scales)、候选框的损失的比例系数(Axis-aligned box and incline box)、池化后的大小(Pooled sizes)、是否使用斜框NMS(Inclined NMS)、测试图的最短边大小范围(Test scales)
-
与其他模型之间的对比
在ICDAR 2015上达到了SOTA,在ICDAR 2013上与CTPN不相上下。
-
模型可以扩展用于YOLO和SSD
文章来源: 博客园
- 还没有人评论,欢迎说说您的想法!



 客服
客服


